Recognition: unknown
A framework for analyzing concept representations in neural models
Pith reviewed 2026-05-09 14:44 UTC · model grok-4.3
The pith
Different estimators produce concept subspaces with varying containment and disentanglement in neural models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a unified framework to study these subspaces along two axes: containment, which tests if a concept is fully represented in a subspace but not outside it, and disentanglement, which tests for isolation from other concepts. In experiments on both text and speech models, we first highlight that concept subspaces may not be uniquely determined, and discuss the implications for concept subspace analysis. Then, we compare properties of concept subspaces estimated using five estimators, proposed in different communities. We find that the choice of estimator impacts the containment and disentanglement properties; the state-of-the-art concept erasure method, LEACE, performs well on both,
What carries the argument
Containment and disentanglement tests applied to linear concept subspaces recovered by five different estimators.
If this is right
- Subspaces recovered by different estimators exhibit measurably different containment and disentanglement scores.
- LEACE achieves strong scores on both axes yet does not fully generalize to unseen examples.
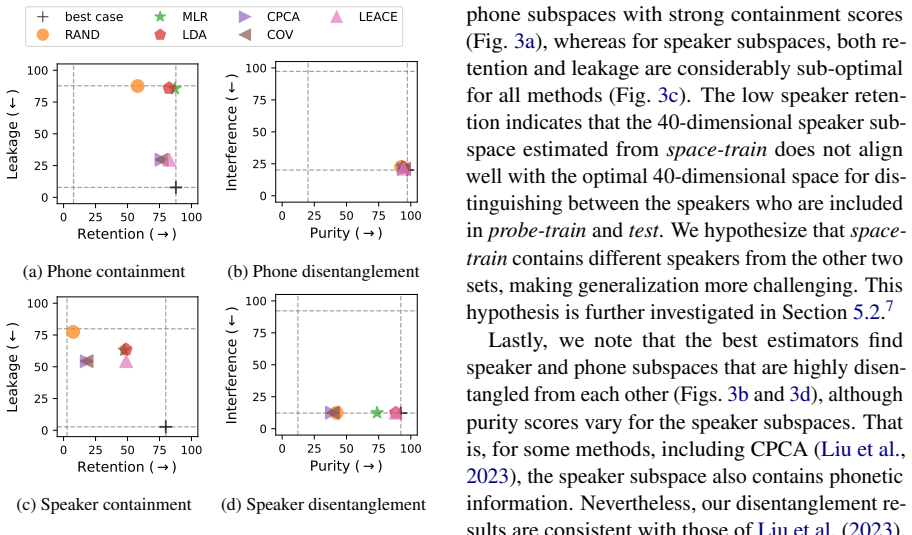
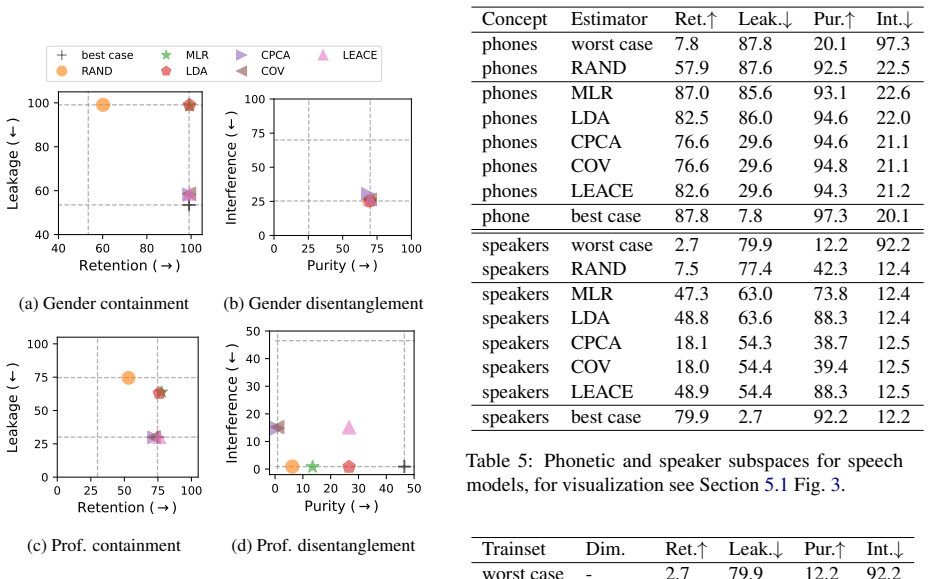
- Phone information in HuBERT is both contained inside a compact subspace and disentangled from speaker information.
- Speaker information in HuBERT remains disentangled from phones but cannot be contained in a comparably compact subspace.
- Concept subspaces are not uniquely fixed by the underlying data and model.
Where Pith is reading between the lines
- The framework could be used to select estimators that best support downstream tasks such as targeted concept removal.
- The observed generalization gap for LEACE points to the need for estimators that explicitly optimize out-of-distribution behavior.
- The contrast between phone and speaker containment in HuBERT suggests that some concepts are encoded more diffusely than others in speech models.
- Applying the same tests to nonlinear subspaces or additional modalities would test whether the linear-assumption results extend.
Load-bearing premise
The containment and disentanglement tests correctly measure whether a concept is fully represented inside a subspace and isolated from others, and the five estimators identify comparable underlying linear subspaces.
What would settle it
Finding that a concept can still be linearly recovered from activations outside the estimated subspace, or that LEACE-erased models continue to predict the concept on held-out data despite passing the tests on training data.
Figures





read the original abstract
Understanding how neural models represent human-interpretable concepts is challenging. Prior work has explored linear concept subspaces from diverse perspectives, such as probing and concept erasure. We introduce a unified framework to study these subspaces along two axes: \textit{containment}, which tests if a concept is fully represented in a subspace but not outside it, and \textit{disentanglement}, which tests for isolation from other concepts. In experiments on both text and speech models, we first highlight that concept subspaces may not be uniquely determined, and discuss the implications for concept subspace analysis. Then, we compare properties of concept subspaces estimated using five estimators, proposed in different communities. We find that (1) the choice of estimator impacts the containment and disentanglement properties; (2) the state-of-the-art concept erasure method, LEACE, performs well on both testing axes, but still struggles to generalize to unseen data; and (3) in HuBERT speech representations, phone information is both contained and disentangled from speaker information, while speaker information is hard to contain in a compact subspace, despite being disentangled from phones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified framework for analyzing concept subspaces in neural models along two axes: containment (testing if a concept is fully represented inside a subspace but not outside it) and disentanglement (testing isolation from other concepts). Experiments on text and speech models compare five estimators, finding that estimator choice affects these properties, that LEACE performs well on both axes but struggles to generalize to unseen data, and that HuBERT shows phone information as both contained and disentangled from speaker information while speaker information is hard to contain in a compact subspace despite being disentangled.
Significance. If the containment and disentanglement tests are robust, the framework usefully unifies perspectives from probing and concept erasure, with the explicit discussion of non-unique subspaces and cross-modal results on HuBERT providing practical value for interpretability. The empirical comparison of estimators and the generalization observation for LEACE are strengths when properly verified.
major comments (3)
- [§2] §2 (Framework): The definitions of the containment and disentanglement axes are presented at a high level without precise mathematical formulations or proofs that they correctly isolate intrinsic properties; given the abstract's note that subspaces 'may not be uniquely determined,' it is unclear how the tests handle multiple possible subspaces or ensure exhaustive 'outside' probes, risking that estimator differences reflect approximation artifacts rather than stable facts.
- [§4] §4 (Experiments): The claim that LEACE generalizes poorly to unseen data is load-bearing for the second main finding, but the manuscript provides no details on data splits, held-out sets, or statistical tests; this makes it difficult to distinguish a robust failure from post-hoc observation and weakens the comparative claims across estimators.
- [§4.3] §4.3 (HuBERT results): The asymmetric conclusion for phone vs. speaker information depends on the tests measuring full containment and isolation; without explicit verification that the five estimators recover comparable linear subspaces (as opposed to different approximations), the domain-specific interpretation remains at risk of being estimator-dependent.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief table or list explicitly naming the five estimators and their originating communities for immediate clarity.
- [§3] Notation for subspaces and probes should be standardized across sections to avoid ambiguity when comparing containment scores.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address each of the major comments point by point below, providing clarifications and indicating revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [§2] §2 (Framework): The definitions of the containment and disentanglement axes are presented at a high level without precise mathematical formulations or proofs that they correctly isolate intrinsic properties; given the abstract's note that subspaces 'may not be uniquely determined,' it is unclear how the tests handle multiple possible subspaces or ensure exhaustive 'outside' probes, risking that estimator differences reflect approximation artifacts rather than stable facts.
Authors: We agree that more precise formulations would strengthen the framework section. In the revised manuscript, we include detailed mathematical definitions of the containment and disentanglement axes, specifying how they are operationalized with linear probes and erasure techniques. To address non-uniqueness, we emphasize that our tests are designed to evaluate properties that are robust across different possible subspaces by reporting results from multiple estimators and noting consistencies. We have expanded the discussion on handling multiple subspaces and ensured the 'outside' probes are described as using a comprehensive set of complementary methods to minimize the risk of missing representations. This approach helps mitigate concerns about approximation artifacts by highlighting where properties are stable versus estimator-specific. revision: yes
-
Referee: [§4] §4 (Experiments): The claim that LEACE generalizes poorly to unseen data is load-bearing for the second main finding, but the manuscript provides no details on data splits, held-out sets, or statistical tests; this makes it difficult to distinguish a robust failure from post-hoc observation and weakens the comparative claims across estimators.
Authors: This comment highlights an important omission. We have revised §4 to provide full details on the data splits, including training, validation, and held-out test sets used for evaluating generalization. We also report the statistical tests (e.g., paired t-tests or bootstrap confidence intervals) used to confirm the significance of LEACE's generalization performance relative to other estimators. These additions demonstrate that the observed poor generalization is a consistent and statistically supported finding. revision: yes
-
Referee: [§4.3] §4.3 (HuBERT results): The asymmetric conclusion for phone vs. speaker information depends on the tests measuring full containment and isolation; without explicit verification that the five estimators recover comparable linear subspaces (as opposed to different approximations), the domain-specific interpretation remains at risk of being estimator-dependent.
Authors: We recognize the importance of verifying subspace comparability. In the updated manuscript, we have added a subsection analyzing the similarity of the linear subspaces recovered by the five estimators, using measures such as the cosine similarity of basis vectors and the overlap in explained variance. The analysis reveals that while the exact subspaces vary, the containment and disentanglement properties for phone and speaker information exhibit the same asymmetric pattern across all estimators. We discuss this as evidence that the interpretation is not overly estimator-dependent, though we acknowledge the inherent limitations of linear methods in capturing all aspects of the representations. revision: yes
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-interpretable concepts are represented as linear subspaces within neural model activations
invented entities (2)
-
containment axis
no independent evidence
-
disentanglement axis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sparse autoencoders find highly interpretable features in language models
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee. Sparse autoencoders find highly interpretable features in language models
-
[2]
A concept-based explainability framework for large multimodal models
Parekh, Jayneel and Khayatan, Pegah and Shukor, Mustafa and Newson, Alasdair and Cord, Matthieu. A concept-based explainability framework for large multimodal models. arXiv:2406.08074
-
[3]
Ravfogel, Shauli and Elazar, Yanai and Gonen, Hila and Twiton, Michael and Goldberg, Yoav. Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection. 2020. doi:10.18653/v1/2020.acl-main.647
-
[4]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J Zi...
work page internal anchor Pith review arXiv
-
[5]
SUPERB : Speech processing Universal PERformance Benchmark
Yang, Shu-Wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and Huang, Tzu-Hsien and Tseng, Wei-Cheng and Lee, Ko-Tik and Liu, Da-Rong and Huang, Zili and Dong, Shuyan and Li, Shang-Wen and Watanabe, Shinji and Mohamed, Abdelrahman and...
-
[6]
Librispeech: An ASR corpus based on public domain audio books
Panayotov, Vassil and Chen, Guouo and Povey, Daniel and Khudanpur, Sanjeev. Librispeech: An ASR corpus based on public domain audio books
-
[7]
BERT : Pre-training of deep bidirectional Transformers for language understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of deep bidirectional Transformers for language understanding
-
[8]
Self-supervised predictive coding models encode speaker and phonetic information in orthogonal subspaces
Liu, Oli and Tang, Hao and Goldwater, Sharon. Self-supervised predictive coding models encode speaker and phonetic information in orthogonal subspaces
-
[9]
Causal Representation Learning Workshop at NeurIPS 2023 , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Causal Representation Learning Workshop at NeurIPS 2023 , year=
2023
-
[10]
The geometry of multilingual language model representations
Chang, Tyler A and Tu, Zhuowen and Bergen, Benjamin K. The geometry of multilingual language model representations
-
[11]
Recurrent neural networks learn to store and generate sequences using non-linear representations
Csordás, Róbert and Potts, Christopher and Manning, Christopher D and Geiger, Atticus. Recurrent neural networks learn to store and generate sequences using non-linear representations. BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP
-
[12]
2025 , url=
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author=. 2025 , url=
2025
-
[13]
HuBERT : Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
Hsu, Wei-Ning and Bolte, Benjamin and Tsai, Yao-Hung Hubert and Lakhotia, Kushal and Salakhutdinov, Ruslan and Mohamed, Abdelrahman. HuBERT : Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
-
[14]
WavLM : Large-scale self-supervised pre-training for full stack speech processing
Chen, Sanyuan and Wang, Chengyi and Chen, Zhengyang and Wu, Yu and Liu, Shujie and Chen, Zhuo and Li, Jinyu and Kanda, Naoyuki and Yoshioka, Takuya and Xiao, Xiong and Wu, Jian and Zhou, Long and Ren, Shuo and Qian, Yanmin and Qian, Yao and Wu, Jian and Zeng, Michael and Yu, Xiangzhan and Wei, Furu. WavLM : Large-scale self-supervised pre-training for ful...
-
[15]
What do self-supervised speech and speaker models learn? New findings from a cross model layer-wise analysis
Ashihara, Takanori and Delcroix, Marc and Moriya, Takafumi and Matsuura, Kohei and Asami, Taichi and Ijima, Yusuke. What do self-supervised speech and speaker models learn? New findings from a cross model layer-wise analysis
-
[16]
Representation surgery: Theory and practice of affine steering
Singh, Shashwat and Ravfogel, Shauli and Herzig, Jonathan and Aharoni, Roee and Cotterell, Ryan and Kumaraguru, Ponnurangam. Representation surgery: Theory and practice of affine steering
-
[17]
ML-SUPERB: Multilingual speech Universal PERformance Benchmark
Shi, Jiatong and Berrebbi, Dan and Chen, William and Chung, Ho-Lam and Hu, En-Pei and Huang, Wei Ping and Chang, Xuankai and Li, Shang-Wen and Mohamed, Abdelrahman and Lee, Hung-Yi and Watanabe, Shinji. ML-SUPERB: Multilingual speech Universal PERformance Benchmark
-
[18]
Multi-dimensional concept discovery (
Johanna Vielhaben and Stefan Bluecher and Nils Strodthoff , journal=. Multi-dimensional concept discovery (. 2023 , url=
2023
-
[19]
Removing spurious concepts from neural network representations via joint subspace estimation
Holstege, Floris and Wouters, Bram and van Giersbergen, Noud and Diks, Cees. Removing spurious concepts from neural network representations via joint subspace estimation
-
[20]
LEACE: Perfect linear concept erasure in closed form
Belrose, Nora and Schneider-Joseph, David and Ravfogel, Shauli and Cotterell, Ryan and Raff, Edward and Biderman, Stella. LEACE: Perfect linear concept erasure in closed form
-
[21]
Linear adversarial concept erasure
Ravfogel, Shauli and Twiton, Michael and Goldberg, Yoav and Cotterell, Ryan. Linear adversarial concept erasure
-
[22]
Orthogonality and isotropy of speaker and phonetic information in self-supervised speech representations
Mohamed, Mukhtar and Liu, Oli Danyi and Tang, Hao and Goldwater, Sharon. Orthogonality and isotropy of speaker and phonetic information in self-supervised speech representations
-
[23]
Log-linear guardedness and its implications
Ravfogel, Shauli and Goldberg, Yoav and Cotterell, Ryan. Log-linear guardedness and its implications
-
[24]
Measuring disentanglement: A review of metrics
Carbonneau, Marc-André and Zaidi, Julian and Boilard, Jonathan and Gagnon, Ghyslain. Measuring disentanglement: A review of metrics. IEEE Trans. Neural Netw. Learn. Syst
-
[25]
Shao, Shun and Ziser, Yftah and Cohen, Shay B. Gold Doesn ' t Always Glitter: Spectral Removal of Linear and Nonlinear Guarded Attribute Information. European Chapter of the Association for Computational Linguistics (EACL). 2023. doi:10.18653/v1/2023.eacl-main.118
-
[26]
Challenging common assumptions in the unsupervised learning of disentangled representations
Locatello, Francesco and Bauer, Stefan and Lucic, Mario and Rätsch, Gunnar and Gelly, Sylvain and Schölkopf, Bernhard and Bachem, Olivier. Challenging common assumptions in the unsupervised learning of disentangled representations. ICML
-
[27]
The low-dimensional linear geometry of contextualized word representations
Hernandez, Evan and Andreas, Jacob. The low-dimensional linear geometry of contextualized word representations. CoNLL
-
[28]
2020 , url=
A Theory of Usable Information under Computational Constraints , author=. 2020 , url=
2020
-
[29]
Probing Classifiers: Promises, Shortcomings, and Advances
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics
-
[30]
A Framework for the Quantitative Evaluation of Disentangled Representations
Eastwood, Cian and Williams, Christopher K I. A Framework for the Quantitative Evaluation of Disentangled Representations. International Conference on Learning Representations
-
[31]
Towards a Definition of Disentangled Representations
Higgins, Irina and Amos, David and Pfau, David and Racaniere, Sebastien and Matthey, Loic and Rezende, Danilo and Lerchner, Alexander. Towards a definition of disentangled representations. arXiv:1812.02230
-
[32]
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)
Kim, Been and Wattenberg, Martin and Gilmer, Justin and Cai, Carrie and Wexler, James and Viegas, Fernanda and Sayres, Rory. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)
-
[33]
Now you see me (CME): Concept-based model extraction
Kazhdan, Dmitry and Dimanov, Botty and Jamnik, Mateja and Liò, Pietro and Weller, Adrian. Now you see me (CME): Concept-based model extraction. arXiv:2010.13233
-
[34]
M. Subspace Chronicles: How Linguistic Information Emerges, Shifts and Interacts during Language Model Training. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.879
-
[35]
Parts of speech-grounded subspaces in vision-language models
Oldfield, James and Tzelepis, Christos and Panagakis, Yannis and Nicolaou, Mihalis A and Patras, Ioannis. Parts of speech-grounded subspaces in vision-language models. arXiv [cs.CV]
-
[36]
Not all language model features are one-dimensionally linear
Engels, Joshua and Michaud, Eric J and Liao, Isaac and Gurnee, Wes and Tegmark, Max. Not all language model features are one-dimensionally linear. arXiv [cs.LG]
-
[37]
Krishnan, Aravind and Abdullah, Badr M and Klakow, Dietrich. On the
-
[38]
Mechanistic interpretability for AI safety -- A review
Bereska, Leonard and Gavves, Efstratios. Mechanistic interpretability for AI safety -- A review. arXiv [cs.AI]
-
[39]
Concept-based explainable artificial intelligence: Metrics and benchmarks
Aysel, Halil Ibrahim and Cai, Xiaohao and Prugel-Bennett, Adam. Concept-based explainable artificial intelligence: Metrics and benchmarks. arXiv [cs.AI]
-
[40]
Exploring internal representation of self-supervised networks: few-shot learning abilities and comparison with human semantics and recognition of objects
-
[41]
Language Models are Unsupervised Multitask Learners
Radford, Alec and Wu, Jeff and Child, R and Luan, D and Amodei, Dario and Sutskever, I. Language Models are Unsupervised Multitask Learners. storage.prod.researchhub.com
-
[42]
Interpretability of language models via task spaces
Weber, Lucas and Jumelet, Jaap and Bruni, Elia and Hupkes, Dieuwke. Interpretability of language models via task spaces
-
[43]
Toward transparent AI: A survey on interpreting the inner structures of deep neural networks
Räuker, Tilman and Ho, Anson and Casper, Stephen and Hadfield-Menell, Dylan. Toward transparent AI: A survey on interpreting the inner structures of deep neural networks. arXiv [cs.LG]
-
[44]
Visualizing and measuring the geometry of BERT , year =
Coenen, Andy and Reif, Emily and Yuan, Ann and Kim, Been and Pearce, Adam and Vi\'. Visualizing and measuring the geometry of BERT , year =
-
[45]
Efficiently identifying task groupings for multi-task learning
Fifty, Christopher and Amid, Ehsan and Zhao, Zhe and Yu, Tianhe and Anil, Rohan and Finn, Chelsea. Efficiently identifying task groupings for multi-task learning. arXiv [cs.LG]
-
[46]
Editing models with task arithmetic
Ilharco, Gabriel and Ribeiro, Marco Tulio and Wortsman, Mitchell and Gururangan, Suchin and Schmidt, Ludwig and Hajishirzi, Hannaneh and Farhadi, Ali. Editing models with task arithmetic. arXiv [cs.LG]
-
[47]
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting
De-Arteaga, Maria and Romanov, Alexey and Wallach, Hanna and Chayes, Jennifer and Borgs, Christian and Chouldechova, Alexandra and Geyik, Sahin and Kenthapadi, Krishnaram and Kalai, Adam Tauman , title =. 2019 , isbn =. doi:10.1145/3287560.3287572 , booktitle =
-
[48]
Deep learning face attributes in the wild
Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou. Deep learning face attributes in the wild. arXiv [cs.CV]
-
[49]
iBOT: Image BERT Pre-Training with Online Tokenizer
Zhou, Jinghao and Wei, Chen and Wang, Huiyu and Shen, Wei and Xie, Cihang and Yuille, Alan and Kong, Tao. iBOT: Image BERT Pre-Training with Online Tokenizer. arXiv [cs.CV]
-
[50]
The big book of concepts
Murphy, Gregory L. The big book of concepts
-
[51]
BERT Rediscovers the Classical NLP Pipeline
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie. BERT Rediscovers the Classical NLP Pipeline. 2019. doi:10.18653/v1/P19-1452
-
[52]
A Structural Probe for Finding Syntax in Word Representations
Hewitt, John and Manning, Christopher D. A Structural Probe for Finding Syntax in Word Representations. Proceedings of the 2019 Conference of the North
2019
-
[53]
LinearVC: Linear transformations of self-supervised features through the lens of voice conversion
Kamper, Herman and van Niekerk, Benjamin and Zaïdi, Julian and Carbonneau, Marc-André. LinearVC: Linear transformations of self-supervised features through the lens of voice conversion. arXiv [eess.AS]
-
[54]
First Conference on Language Modeling , year=
Inspecting and Editing Knowledge Representations in Language Models , author=. First Conference on Language Modeling , year=
-
[55]
What’s in a Name?
Romanov, Alexey and De-Arteaga, Maria and Wallach, Hanna and Chayes, Jennifer and Borgs, Christian and Chouldechova, Alexandra and Geyik, Sahin and Kenthapadi, Krishnaram and Rumshisky, Anna and Kalai, Adam. What’s in a Name?. Proceedings of the 2019 Conference of the North
2019
-
[56]
Efficient Estimation of Word Representations in Vector Space. 2013
2013
-
[57]
What you can cram into a single \ &!\#* vector:
Conneau, Alexis and Kruszewski, German and Lample, Guillaume and Barrault, Lo. What you can cram into a single \ & ! \# * vector: Probing sentence embeddings for linguistic properties. 2018. doi:10.18653/v1/P18-1198
-
[58]
DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability
Eastwood, Cian and Nicolicioiu, Andrei Liviu and Von Kügelgen, Julius and Kekić, Armin and Träuble, Frederik and Dittadi, Andrea and Schölkopf, Bernhard. DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability
-
[59]
Analyzing the relationships between pretraining language, phonetic, tonal, and speaker information in self-supervised speech models , author=. arXiv:2506.10855 , url =
-
[60]
Dalvi, Fahim and Khan, Abdul Rafae and Alam, Firoj and Durrani, Nadir and Xu, Jia and Sajjad, Hassan , booktitle=iclr, year=
-
[61]
Geiger, Atticus and Wu, Zhengxuan and Potts, Christopher and Icard, Thomas and Goodman, Noah , month = mar, year =. Finding. Proceedings of the
-
[62]
Representation learning: a review and new perspectives
Representation. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2013 , keywords =. doi:10.1109/TPAMI.2013.50 , number =
-
[63]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
Disentangled. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2024 , keywords =. doi:10.1109/TPAMI.2024.3420937 , number =
-
[64]
Ravfogel, Shauli and Goldberg, Yoav and Cotterell, Ryan , year =. Log-linear. Proceedings of the 61st. doi:10.18653/v1/2023.acl-long.523 , abstract =
-
[65]
Saillenfest, Antoine and Lemberger, Pirmin , year =. Nonlinear. European Chapter of the Association for Computational Linguistics (EACL). doi:10.48550/ARXIV.2507.12341 , abstract =
-
[66]
Huben, Robert and Cunningham, Hoagy and Smith, Logan Riggs and Ewart, Aidan and Sharkey, Lee , year =. Sparse
-
[67]
Gur-Arieh, Yoav and Suslik, Clara and Hong, Yihuai and Barez, Fazl and Geva, Mor , year =. Precise. doi:10.48550/ARXIV.2505.22586 , abstract =
-
[68]
and Risser, Laurent and Asher, Nicholas , month = dec, year =
Jourdan, Fanny and B'ethune, Louis and Picard, A. and Risser, Laurent and Asher, Nicholas , month = dec, year =
-
[69]
Chintam, Abhijith and Beloch, Rahel and Zuidema, Willem and Hanna, Michael and van der Wal, Oskar , year =. Identifying and. doi:10.48550/ARXIV.2310.12611 , abstract =
-
[70]
Dalvi, Fahim and Khan, Abdul Rafae and Alam, Firoj and Durrani, Nadir and Xu, Jia and Sajjad, Hassan , month = may, year =. Discovering. doi:10.48550/arXiv.2205.07237 , abstract =
-
[71]
Evaluating
Fan, Yimin and Dalvi, Fahim and Durrani, Nadir and Sajjad, Hassan , editor =. Evaluating. Advances in. 2023 , pages =
2023
-
[72]
Visualizing and
Reif, Emily and Yuan, Ann and Wattenberg, Martin and Viegas, Fernanda B and Coenen, Andy and Pearce, Adam and Kim, Been , editor =. Visualizing and. Advances in
-
[73]
Coenen, Andy and Reif, Emily and Yuan, Ann and Kim, Been and Pearce, Adam and Viégas, Fernanda and Wattenberg, Martin , month = oct, year =. Visualizing and. doi:10.48550/arXiv.1906.02715 , abstract =
-
[74]
Most. Open Mind , author =. 2025 , pages =. doi:10.1162/OPMI.a.320 , abstract =
-
[75]
Eastwood, Cian and Nicolicioiu, Andrei Liviu and Kügelgen, Julius Von and Kekić, Armin and Träuble, Frederik and Dittadi, Andrea and Schölkopf, Bernhard , month = sep, year =
-
[76]
Gauthier, Jon and Breiss, Canaan and Leonard, Matthew and Chang, Edward F. , month = sep, year =. Emergent morpho-phonological representations in self-supervised speech models , url =. doi:10.48550/arXiv.2509.22973 , abstract =
-
[77]
Lampinen, Andrew Kyle and Chan, Stephanie C. Y. and Li, Yuxuan and Hermann, Katherine , month = aug, year =. Representation biases: will we achieve complete understanding by analyzing representations? , shorttitle =. doi:10.48550/arXiv.2507.22216 , abstract =
-
[78]
and Jain, Shailee and Huth, Alexander , month = jun, year =
Vaidya, Aditya R. and Jain, Shailee and Huth, Alexander , month = jun, year =. Self-. Proceedings of the 39th
-
[80]
Proceedings of
Effective. Proceedings of
-
[81]
Asaad, Ihab and Jacquelin, Maxime and Perrotin, Olivier and Girin, Laurent and Hueber, Thomas , month = may, year =. Fill in the. doi:10.48550/arXiv.2405.20101 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.