Recognition: unknown
Registration-Free Learnable Multi-View Capture of Faces in Dense Semantic Correspondence
Pith reviewed 2026-05-09 15:04 UTC · model grok-4.3
The pith
MOCHI reconstructs 3D face meshes in dense semantic correspondence from multi-view images without any registered training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
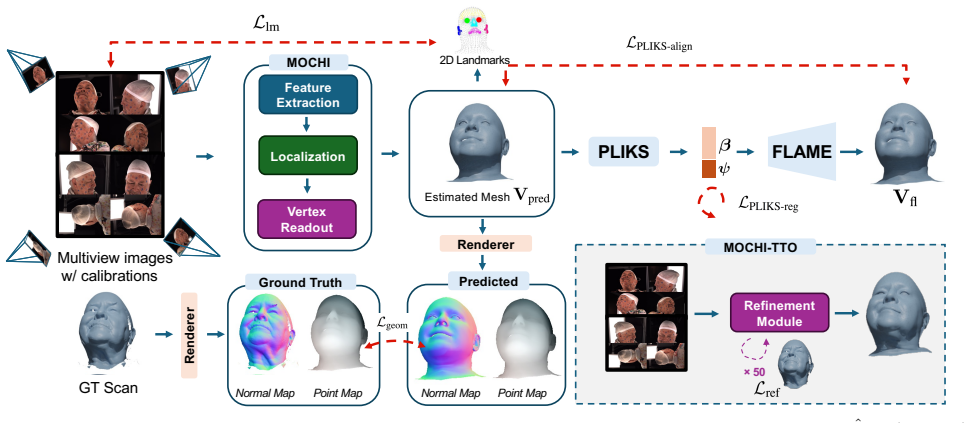
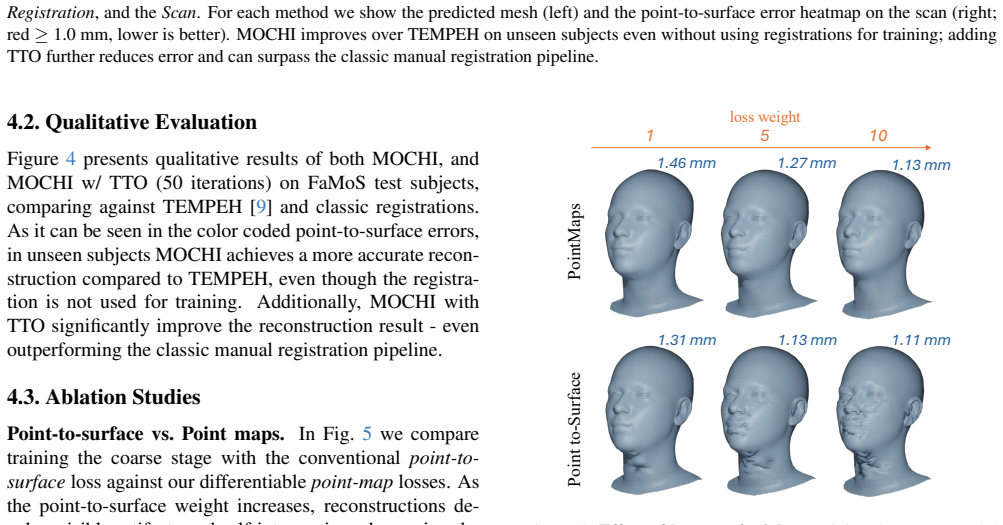
MOCHI eliminates the registration data dependency by enforcing topological consistency through a pseudo-linear inverse kinematic solver. Semantic alignment is guided by dense keypoints from a 2D landmark predictor trained exclusively on synthetic data. Standard point-to-surface distances are shown to induce training instabilities in registration-free settings, so pointmap- and normal-based losses are used instead. A test-time optimization scheme then refines the network over a few dozen iterations, allowing the method to surpass traditional registration pipelines in both reconstruction accuracy and visual quality.
What carries the argument
The pseudo-linear inverse kinematic solver that enforces topological consistency on predicted meshes, guided by dense keypoints from a synthetic-data-trained 2D landmark model, together with pointmap- and normal-based losses that supply stable gradients.
Load-bearing premise
Dense keypoints predicted by a 2D landmark model trained only on synthetic data will give reliable semantic guidance for real multi-view face images, and the pseudo-linear inverse kinematic solver will enforce sufficient topological consistency without new artifacts.
What would settle it
Running MOCHI on a held-out set of real unregistered multi-view face images and observing either frequent topological inconsistencies in the output meshes or semantic misalignments that deviate from ground-truth registered models would disprove the central claims.
Figures














read the original abstract
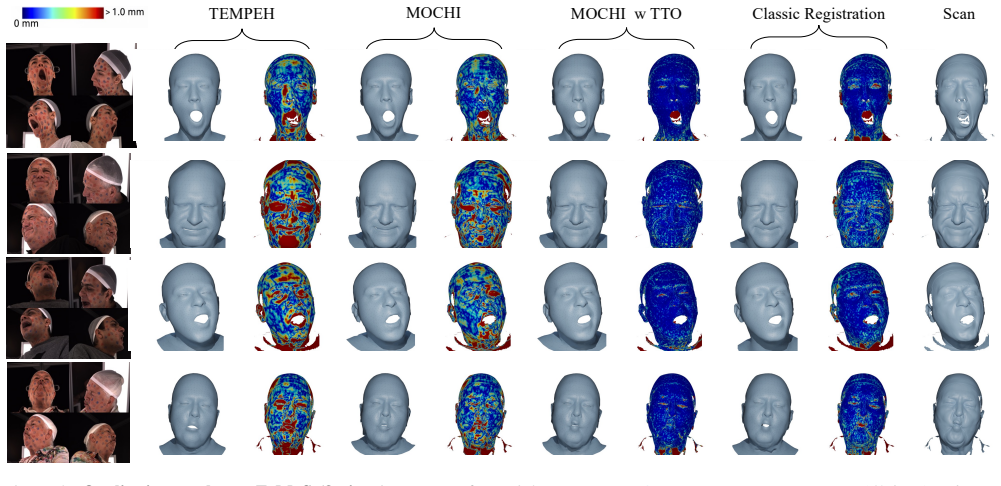
Recent frameworks like ToFu and TEMPEH provide an automated alternative to classical registration pipelines by predicting 3D meshes in dense semantic correspondence directly from calibrated multi-view images. However, these learning-based methods rely on the slow, manual registration pipelines they aim to replace for their training supervision. We overcome this limitation with MOCHI (Multi-view Optimizable Correspondence of Heads from Images), a multi-view 3D face prediction framework trained without requiring registered training data. MOCHI eliminates the registration data dependency by enforcing topological consistency through a pseudo-linear inverse kinematic solver. Semantic alignment is guided by dense keypoints from a 2D landmark predictor trained exclusively on synthetic data. Our analysis further reveals that standard point-to-surface distances induce training instabilities and visual artifacts in registration-free settings. We propose pointmap- and normal-based losses instead, which provide smoother gradients and superior reconstruction fidelity. Finally, we introduce a test-time optimization scheme that refines network weights over a few dozen iterations. This approach bridges the gap between feed-forward efficiency and iterative optimization precision, allowing MOCHI to outperform traditional labor-intensive pipelines in both reconstruction accuracy and visual quality. Code and model are public at: https://filby89.github.io/mochi.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MOCHI, a multi-view 3D face mesh prediction framework that achieves dense semantic correspondence without registered training data. It enforces topological consistency via a pseudo-linear inverse kinematic solver, guides semantic alignment using dense keypoints from a 2D landmark predictor trained exclusively on synthetic data, replaces unstable point-to-surface losses with pointmap- and normal-based losses, and adds a test-time optimization scheme over a few dozen iterations. The authors claim this allows MOCHI to outperform traditional labor-intensive registration pipelines in reconstruction accuracy and visual quality, with public code and models released.
Significance. If the central claims hold—particularly effective synthetic-to-real transfer for keypoints and stable training via the new losses and solver—MOCHI would be a meaningful advance in 3D face capture by removing the registration data bottleneck that limits scalability of prior learning-based methods like ToFu and TEMPEH. The public code release supports reproducibility and is a clear strength.
major comments (2)
- [Abstract] The registration-free claim rests on the 2D landmark predictor (trained only on synthetic data) supplying reliable dense semantic guidance for real multi-view images. No quantitative keypoint error metrics on real data, domain-shift analysis, or ablation removing the synthetic predictor are referenced in the abstract, leaving the superiority over registered pipelines conditional on an unverified generalization assumption.
- [Abstract] The pseudo-linear inverse kinematic solver is presented as the mechanism for enforcing topological consistency without registration, yet the abstract provides no equations, algorithm, or comparison to standard IK methods. This makes it impossible to assess whether it avoids new artifacts or simply shifts instabilities, which is load-bearing for the central contribution.
minor comments (1)
- [Abstract] The abstract states that 'standard point-to-surface distances induce training instabilities' and proposes alternatives, but does not indicate in which section the supporting analysis or gradient visualizations appear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the abstract accordingly to better substantiate the key claims while respecting length constraints.
read point-by-point responses
-
Referee: [Abstract] The registration-free claim rests on the 2D landmark predictor (trained only on synthetic data) supplying reliable dense semantic guidance for real multi-view images. No quantitative keypoint error metrics on real data, domain-shift analysis, or ablation removing the synthetic predictor are referenced in the abstract, leaving the superiority over registered pipelines conditional on an unverified generalization assumption.
Authors: We agree that the abstract would benefit from explicitly referencing the supporting evidence for the synthetic-to-real transfer. The full manuscript contains quantitative keypoint error metrics on real data, domain-shift analysis, and ablations that remove the synthetic predictor to demonstrate its contribution. We will revise the abstract to include a concise reference to these results, thereby strengthening the registration-free claim without altering the manuscript's technical content. revision: yes
-
Referee: [Abstract] The pseudo-linear inverse kinematic solver is presented as the mechanism for enforcing topological consistency without registration, yet the abstract provides no equations, algorithm, or comparison to standard IK methods. This makes it impossible to assess whether it avoids new artifacts or simply shifts instabilities, which is load-bearing for the central contribution.
Authors: The abstract serves as a high-level overview, while the methods section provides the full equations, algorithmic details, and comparisons to standard IK solvers that demonstrate how the pseudo-linear formulation avoids instabilities and artifacts. To address the concern, we will update the abstract with a brief phrase highlighting the solver's stability properties and its role in registration-free training. revision: yes
Circularity Check
No significant circularity; derivation relies on external components and new proposed elements
full rationale
The paper's core derivation introduces MOCHI as a registration-free framework that enforces topological consistency via a newly described pseudo-linear inverse kinematic solver and guides semantic alignment using dense keypoints from a separately trained 2D landmark predictor on synthetic data only. It further proposes pointmap- and normal-based losses to replace point-to-surface distances and adds test-time optimization. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described chain; the landmark predictor and solver are presented as independent inputs rather than derived from the target multi-view data. The central performance claims rest on these external and novel elements rather than reducing to the inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dense keypoints from a 2D landmark predictor trained exclusively on synthetic data provide sufficient semantic alignment for real multi-view face images.
invented entities (1)
-
pseudo-linear inverse kinematic solver
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ex- pression invariant 3d face recognition with a morphable model.2008 8th IEEE International Conference on Auto- matic Face & Gesture Recognition, pages 1–6, 2008
Brian Amberg, Reinhard Knothe, and Thomas Vetter. Ex- pression invariant 3d face recognition with a morphable model.2008 8th IEEE International Conference on Auto- matic Face & Gesture Recognition, pages 1–6, 2008. 2
2008
-
[2]
Scaffoldavatar: High-fidelity gaussian avatars with patch expressions.CoRR, abs/2507.10542, 2025
Shivangi Aneja, Sebastian Weiss, Irene Baeza, Prashanth Chandran, Gaspard Zoss, Matthias Nießner, and Derek Bradley. Scaffoldavatar: High-fidelity gaussian avatars with patch expressions.CoRR, abs/2507.10542, 2025. 3
-
[3]
Bronstein, and Stefanos Zafeiriou
Mehdi Bahri, Eimear O’ Sullivan, Shunwang Gong, Feng Liu, Xiaoming Liu, Michael M. Bronstein, and Stefanos Zafeiriou. Shape my face: Registering 3d face scans by surface-to-surface translation.Int. J. Comput. Vision, 129 (9):2680–2713, 2021. 2
2021
-
[4]
High-quality single-shot capture of facial geometry.ACM Trans
Thabo Beeler, Bernd Bickel, Paul Beardsley, Bob Sumner, and Markus Gross. High-quality single-shot capture of facial geometry.ACM Trans. Graph., 29(4), 2010. 2
2010
-
[5]
Sumner, and Markus Gross
Thabo Beeler, Fabian Hahn, Derek Bradley, Bernd Bickel, Paul Beardsley, Craig Gotsman, Robert W. Sumner, and Markus Gross. High-quality passive facial performance cap- ture using anchor frames.ACM Trans. Graph., 30(4), 2011. 2
2011
-
[6]
Besl and Neil D
Paul J. Besl and Neil D. McKay. A method for registration of 3-d shapes.IEEE Trans. Pattern Anal. Mach. Intell., 14 (2):239–256, 1992. 2
1992
-
[7]
A morphable model for the synthesis of 3d faces
V olker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. InProceedings of SIGGRAPH, 1999. 2, 3
1999
-
[8]
Face identification across different poses and illuminations with a 3D morphable model
V olker Blanz, Sami Romdhani, and Thomas Vetter. Face identification across different poses and illuminations with a 3D morphable model. InIEEE International Conference on Automatic Face and Gesture Recognition, pages 202–207,
-
[9]
Timo Bolkart, Tianye Li, and Michael J. Black. Instant multi-view head capture through learnable registration. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2023. 2, 3, 4, 5, 6, 7, 13, 14, 15
2023
-
[10]
James Booth, Anastasios Roussos, Stefanos Zafeiriou, Al- lan Ponniah, and David J. Dunaway. A 3d morphable model learnt from 10, 000 faces. In2016 IEEE Conference on Com- puter Vision and Pattern Recognition, CVPR 2016, Las Ve- gas, NV , USA, June 27-30, 2016, pages 5543–5552. IEEE Computer Society, 2016. 2
2016
-
[11]
3d morphable models: Past, present, and future.arXiv preprint arXiv:1803.09725,
James Booth, Anastasios Roussos, Arun Ponniah, David Dunaway, and Stefanos Zafeiriou. 3d morphable models: Past, present, and future.arXiv preprint arXiv:1803.09725,
-
[12]
Dunaway, and Stefanos Zafeiriou
James Booth, Anastasios Roussos, Allan Ponniah, David J. Dunaway, and Stefanos Zafeiriou. Large scale 3d morphable models.Int. J. Comput. Vis., 126(2-4):233–254, 2018. 2
2018
-
[13]
High resolution passive facial performance capture
Derek Bradley, Wolfgang Heidrich, Tiberiu Popa, and Alla Sheffer. High resolution passive facial performance capture. ACM Trans. Graph., 29(4), 2010. 2
2010
-
[14]
Real-time 3d face tracking in the wild with a single rgb camera
Chen Cao, Yanlin Weng, Steve Lin Zhou, Yiying Tong, and Kun Zhou. Real-time 3d face tracking in the wild with a single rgb camera. InACM Transactions on Graphics (TOG),
-
[15]
Facewarehouse: A 3d facial expression database for visual computing.IEEE TVCG, 20(3):413–425, 2014
Chen Cao, Yanlin Weng, Shun Zhou, Yiying Tong, and Kun Zhou. Facewarehouse: A 3d facial expression database for visual computing.IEEE TVCG, 20(3):413–425, 2014. 2
2014
-
[16]
Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018
Blender Online Community.Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018. 18
2018
-
[17]
Black, and Timo Bolkart
Radek Dane ˇcek, Michael J. Black, and Timo Bolkart. Emoca: Emotion driven monocular face capture and anima- tion. InCVPR, pages 20279–20290, 2022. 3
2022
-
[18]
RetinaFace: Single-shot multi-level face localisation in the wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. RetinaFace: Single-shot multi-level face localisation in the wild. InCVPR, pages 5202–5211,
-
[19]
An image is worth 16x16 words: Trans- formers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. InInternational Con- ference on Learning Representations (ICLR), 2021. 19
2021
-
[20]
End-to-end 3D face reconstruction with deep neural net- works
Pengfei Dou, Shishir K Shah, and Ioannis A Kakadiaris. End-to-end 3D face reconstruction with deep neural net- works. InCVPR, pages 5908–5917, 2017. 3
2017
-
[21]
Bernhard Egger, William A. P. Smith, Ayush Tewari, Ste- fanie Wuhrer, Michael Zollh ¨ofer, Thabo Beeler, Florian Bernard, Timo Bolkart, Adam Kortylewski, Sami Romdhani, Christian Theobalt, V olker Blanz, and Thomas Vetter. 3d morphable face models - past, present, and future.ACM Trans. Graph., 39(5):157:1–157:38, 2020. 2, 3
2020
-
[22]
Silhouette and stereo fusion for 3d object modeling.Computer Vision and Image Understanding, 96(3):367–392, 2004
Carlos Hern ´andez Esteban and Francis Schmitt. Silhouette and stereo fusion for 3d object modeling.Computer Vision and Image Understanding, 96(3):367–392, 2004. 2
2004
-
[23]
Joint 3D face reconstruction and dense alignment with position map regression network
Yao Feng, Fan Wu, Xiaohu Shao, Yanfeng Wang, and Xi Zhou. Joint 3D face reconstruction and dense alignment with position map regression network. InECCV, pages 534–551,
-
[24]
Black, and Timo Bolkart
Yao Feng, Haiwen Feng, Michael J. Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the-wild images.ACM TOG, 40(4):88:1–88:13, 2021. 3
2021
-
[25]
Panagiotis P. Filntisis, George Retsinas, Foivos Paraperas- Papantoniou, Athanasios Katsamanis, Anastasios Roussos, and Petros Maragos. Visual speech-aware perceptual 3d fa- cial expression reconstruction from videos.arXiv preprint arXiv:2207.11094, 2022. 3
-
[26]
Accurate, dense, and robust multi-view stereopsis
Yasutaka Furukawa and Jean Ponce. Accurate, dense, and robust multi-view stereopsis. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2010. 2
2010
-
[27]
Multi- view stereo on consistent face topology.Comput
Graham Fyffe, Koki Nagano, Loc Huynh, Shunsuke Saito, Jay Busch, Andrew Jones, Hao Li, and Paul Debevec. Multi- view stereo on consistent face topology.Comput. Graph. Forum, 36(2):295–309, 2017. 2
2017
-
[28]
Reconstructing person- alized semantic facial nerf models from monocular video
Xuan Gao, Chenglai Zhong, Jun Xiang, Yang Hong, Yudong Guo, and Juyong Zhang. Reconstructing person- alized semantic facial nerf models from monocular video. ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia), 41(6), 2022. 3
2022
-
[29]
Statistical methods for tomographic image restoration.Bull
Stuart Geman. Statistical methods for tomographic image restoration.Bull. Internat. Statist. Inst., 52:5–21, 1987. 4
1987
-
[30]
Morphable face models-an open framework
Thomas Gerig, Andreas Morel-Forster, Clemens Blumer, Bernhard Egger, Marcel Luthi, Sandro Sch ¨onborn, and Thomas Vetter. Morphable face models-an open framework. InIEEE International Conference on Automatic Face and Gesture Recognition, pages 75–82, 2018. 2
2018
-
[31]
Multiview face cap- ture using polarized spherical gradient illumination
Abhijeet Ghosh, Graham Fyffe, Ben Tunwattanapong, Jay Busch, Xueming Yu, and Paul Debevec. Multiview face cap- ture using polarized spherical gradient illumination. InACM Transactions on Graphics (TOG), 2011. 2
2011
-
[32]
Learning neural parametric head models
Simon Giebenhain, Tobias Kirschstein, Markos Georgopou- los, Martin R ¨unz, Lourdes Agapito, and Matthias Nießner. Learning neural parametric head models. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
-
[33]
Npga: Neural paramet- ric gaussian avatars
Simon Giebenhain, Tobias Kirschstein, Martin R ¨unz, Lour- des Agapito, and Matthias Nießner. Npga: Neural paramet- ric gaussian avatars. InSIGGRAPH Asia 2024 Conference Papers (SA Conference Papers ’24), December 3-6, Tokyo, Japan, 2024. 3
2024
-
[34]
Goesele, B
M. Goesele, B. Curless, and S.M. Seitz. Multi-view stereo revisited. In2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), pages 2402–2409, 2006. 2
2006
-
[35]
DenseReg: Fully convolutional dense shape regression in-the-wild
Riza Alp G ¨uler, George Trigeorgis, Epameinondas Anton- akos, Patrick Snape, Stefanos Zafeiriou, and Iasonas Kokki- nos. DenseReg: Fully convolutional dense shape regression in-the-wild. InCVPR, pages 6799–6808, 2017. 3
2017
-
[36]
Towards fast, accurate and stable 3D dense face alignment
Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei, and Stan Z Li. Towards fast, accurate and stable 3D dense face alignment. InECCV, pages 152–168, 2020. 3
2020
-
[37]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations (ICLR),
-
[38]
Dpsnet: End-to-end deep plane sweep stereo
Sunghoon Im, Hae-Gon Jeon, Stephen Lin, and In So Kweon. Dpsnet: End-to-end deep plane sweep stereo. InIn- ternational Conference on Learning Representations (ICLR),
-
[39]
Large pose 3D face reconstruction from a single image via direct volumetric CNN regression
Aaron S Jackson, Adrian Bulat, Vasileios Argyriou, and Georgios Tzimiropoulos. Large pose 3D face reconstruction from a single image via direct volumetric CNN regression. InICCV, pages 1031–1039, 2017. 3
2017
-
[40]
Krishna Murthy Jatavallabhula, Edward Smith, Jean- Francois Lafleche, Clement Fuji Tsang, Artem Rozantsev, Wenzheng Chen, Tommy Xiang, Rev Lebaredian, and Sanja Fidler. Kaolin: A pytorch library for accelerating 3d deep learning research.arXiv preprint arXiv:1911.05063, 2019. 8
-
[41]
Learning free-form deformation for 3D face reconstruction from in-the-wild images
Harim Jung, Myeong-Seok Oh, and Seong-Whan Lee. Learning free-form deformation for 3D face reconstruction from in-the-wild images. InIEEE International Conference on Systems, Man, and Cybernetics (SMC), pages 2737–2742,
-
[42]
Learn- ing a multi-view stereo machine
Abhishek Kar, Christian H ¨ane, and Jitendra Malik. Learn- ing a multi-view stereo machine. InAdvances in Neural Information Processing Systems (NeurIPS), pages 365–376,
-
[43]
Multi-camera scene reconstruction via graph cuts
Vladimir Kolmogorov and Ramin Zabih. Multi-camera scene reconstruction via graph cuts. InEuropean Conference on Computer Vision (ECCV), pages 82–96. Springer, 2002. 2
2002
-
[44]
The digital michelangelo project: 3d scanning of large statues
Marc Levoy, Kari Pulli, Brian Curless, Szymon Rusinkiewicz, David Koller, Lucas Pereira, Matt Ginz- ton, Sean Anderson, James Davis, Jeremy Ginsberg, Jonathan Shade, and Duane Fulk. The digital michelangelo project: 3d scanning of large statues. InProceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, page 131–144, USA,...
2000
-
[45]
Guibas, and Mark Pauly
Hao Li, Bart Adams, Leonidas J. Guibas, and Mark Pauly. Robust single-view geometry and motion reconstruction. ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2009), 28(5), 2009. 2
2009
-
[46]
Grape: Generaliz- able and robust multi-view facial capture.arXiv preprint arXiv:2407.10193, 2024
Jing Li, Di Kang, and Zhenyu He. Grape: Generaliz- able and robust multi-view facial capture.arXiv preprint arXiv:2407.10193, 2024. 2, 3, 6, 14
-
[47]
Learn- ing formation of physically-based face attributes
Ruilong Li, Karl Bladin, Yajie Zhao, Chinmay Chinara, Owen Ingraham, Pengda Xiang, Xinglei Ren, Pratusha Prasad, Bipin Kishore, Jun Xing, and Hao Li. Learn- ing formation of physically-based face attributes. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 3407–3416. Computer Visio...
2020
-
[48]
Black, Hao Li, and Javier Romero
Tianye Li, Timo Bolkart, Michael J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and expres- sion from 4d scans. InACM SIGGRAPH Asia 2017, 2017. 2, 3, 5, 6, 13
2017
-
[49]
Topologically consistent multi-view face inference using volumetric sampling
Tianye Li, Shichen Liu, Timo Bolkart, Jiayi Liu, Hao Li, and Yajie Zhao. Topologically consistent multi-view face inference using volumetric sampling. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 2, 3
2021
-
[50]
3d face modeling from diverse raw scan data.2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9407–9417,
Feng Liu, Luan Tran, and Xiaoming Liu. 3d face modeling from diverse raw scan data.2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9407–9417,
2019
-
[51]
Rapid face asset acquisition with recurrent fea- ture alignment.ACM TOG, 41(6):214:1–214:17, 2022
Shichen Liu, Yunxuan Cai, Haiwei Chen, Yichao Zhou, and Yajie Zhao. Rapid face asset acquisition with recurrent fea- ture alignment.ACM TOG, 41(6):214:1–214:17, 2022. 3
2022
-
[52]
Neural vol- umes: Learning dynamic renderable volumes from images
Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. Neural vol- umes: Learning dynamic renderable volumes from images. ACM Trans. Graph., 38(4):65:1–65:14, 2019. 3
2019
-
[53]
Mix- ture of volumetric primitives for efficient neural rendering
Stephen Lombardi, Tomas Simon, Gabriel Schwartz, Michael Zollhoefer, Yaser Sheikh, and Jason Saragih. Mix- ture of volumetric primitives for efficient neural rendering. ACM Trans. Graph., 40(4), 2021. 3
2021
-
[54]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations (ICLR), 2019. 19
2019
-
[55]
Saragih, Dawei Wang, Yuecheng Li, Fernando De la Torre, and Yaser Sheikh
Shugao Ma, Tomas Simon, Jason M. Saragih, Dawei Wang, Yuecheng Li, Fernando De la Torre, and Yaser Sheikh. Pixel codec avatars.2021 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 64–73, 2021. 3
2021
-
[56]
Rapid acquisition of specular and diffuse normal maps from polarized spher- ical gradient illumination
Wan-Chun Ma, Tim Hawkins, Pieter Peers, Charles-Felix Chabert, Malte Weiss, and Paul Debevec. Rapid acquisition of specular and diffuse normal maps from polarized spher- ical gradient illumination. InEurographics conference on Rendering Techniques, page 183–194, Goslar, DEU, 2007. Eurographics Association. 2
2007
-
[57]
Newcombe, and Steven Lovegrove
Jeong Joon Park, Peter Florence, Julian Straub, Richard A. Newcombe, and Steven Lovegrove. DeepSDF: Learning continuous signed distance functions for shape representa- tion. InCVPR, pages 165–174, 2019. 3
2019
-
[58]
Kakadiaris
Georgios Passalis, Panagiotis Perakis, Theoharis Theoharis, and Ioannis A. Kakadiaris. Using facial symmetry to han- dle pose variations in real-world 3d face recognition.IEEE Trans. Pattern Anal. Mach. Intell., 33(10):1938–1951, 2011. 2
1938
-
[59]
A 3d face model for pose and illumination invariant face recognition
Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami Romdhani, and Thomas Vetter. A 3d face model for pose and illumination invariant face recognition. InIEEE Inter- national Conference on Advanced Video and Signal Based Surveillance (AVSS), 2009. 2
2009
-
[60]
Pears, William A
Stylianos Ploumpis, Evangelos Ververas, Eimear O’ Sulli- van, Stylianos Moschoglou, Haoyang Wang, Nick E. Pears, William A. P. Smith, Baris Gecer, and Stefanos Zafeiriou. Towards a complete 3D morphable model of the human head. IEEE TPAMI, 43(11):4142–4160, 2021. 3
2021
-
[61]
Anurag Ranjan, Timo Bolkart, Soubhik Sanyal, and Michael J. Black. Generating 3d faces using convolutional mesh autoencoders. InComputer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part III, pages 725–741. Springer, 2018. 6
2018
-
[62]
Filntisis, Radek Dane ˇcek, Victoria F
George Retsinas, Panagiotis P. Filntisis, Radek Dane ˇcek, Victoria F. Abrevaya, Anastasios Roussos, Timo Bolkart, and Petros Maragos. 3d facial expressions through analysis- by-neural-synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[63]
Single-shot high-quality facial geometry and skin appearance capture.ACM Transactions on Graphics, 39, 2020
Jeremy Riviere, Paulo Gotardo, Derek Bradley, Abhijeet Ghosh, and Thabo Beeler. Single-shot high-quality facial geometry and skin appearance capture.ACM Transactions on Graphics, 39, 2020. 2
2020
-
[64]
SADRNet: Self-aligned dual face regres- sion networks for robust 3D dense face alignment and recon- struction.Transactions on Image Processing, 30:5793–5806,
Zeyu Ruan, Changqing Zou, Longhai Wu, Gangshan Wu, and Limin Wang. SADRNet: Self-aligned dual face regres- sion networks for robust 3D dense face alignment and recon- struction.Transactions on Image Processing, 30:5793–5806,
-
[65]
Fully automatic expression-invariant face correspondence.Machine Vision and Applications, 25: 859 – 879, 2013
Augusto Salazar, Stefanie Wuhrer, Chang Shu, and Flavio Augusto Prieto. Fully automatic expression-invariant face correspondence.Machine Vision and Applications, 25: 859 – 879, 2013. 2
2013
-
[66]
Learning to regress 3d face shape and expression from an image without 3d supervision
Soubhik Sanyal, Timo Bolkart, Haiwen Feng, and Michael Black. Learning to regress 3d face shape and expression from an image without 3d supervision. InProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019. 3
2019
-
[67]
Sch ¨onberger and Jan-Michael Frahm
Johannes L. Sch ¨onberger and Jan-Michael Frahm. Structure- from-motion revisited. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 2
2016
-
[68]
Unre- stricted facial geometry reconstruction using image-to-image translation
Matan Sela, Elad Richardson, and Ron Kimmel. Unre- stricted facial geometry reconstruction using image-to-image translation. InICCV, pages 1576–1585, 2017. 3
2017
-
[69]
Self-supervised monocular 3d face reconstruction by occlusion-aware multi- view geometry consistency
Jiaxiang Shang, Tianwei Shen, Shiwei Li, Lei Zhou, Ming- min Zhen, Tian Fang, and Long Quan. Self-supervised monocular 3d face reconstruction by occlusion-aware multi- view geometry consistency. InComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XV, pages 53–70. Springer,
2020
-
[70]
Pliks: A pseudo-linear inverse kinematic solver for 3d hu- man body estimation
Karthik Shetty, Annette Birkhold, Srikrishna Jaganathan, Norbert Strobel, Markus Kowarschik, and Bernhard Egger. Pliks: A pseudo-linear inverse kinematic solver for 3d hu- man body estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2, 3, 5
2023
-
[71]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Black, and Justus Thies
Vanessa Sklyarova, Egor Zakharov, Otmar Hilliges, Michael J. Black, and Justus Thies. Text-conditioned gen- erative model of 3d strand-based human hairstyles. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4703–4712, 2024. 4, 17
2024
-
[73]
Unsuper- vised generative 3D shape learning from natural images
Attila Szab ´o, Givi Meishvili, and Paolo Favaro. Unsuper- vised generative 3D shape learning from natural images. CoRR, abs/1910.00287, 2019. 3
-
[74]
3D face tracking from 2D video through iterative dense UV to image flow
Felix Taubner, Prashant Raina, Mathieu Tuli, Eu Wern Teh, Chul Lee, and Jinmiao Huang. 3D face tracking from 2D video through iterative dense UV to image flow. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1227–1237, 2024. 3
2024
-
[75]
Mofa: Model-based deep convolutional face au- toencoder for unsupervised monocular reconstruction
Ayush Tewari, Michael Zollh ¨ofer, Hyeongwoo Kim, Pablo Garrido, Florian Bernard, Patrick P ´erez, and Christian Theobalt. Mofa: Model-based deep convolutional face au- toencoder for unsupervised monocular reconstruction. In IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 3735–3744. IEEE Computer Soci...
2017
-
[76]
Self-supervised multi-level face model learn- ing for monocular reconstruction at over 250 hz
Ayush Tewari, Michael Zollh ¨ofer, Pablo Garrido, Florian Bernard, Hyeongwoo Kim, Patrick P ´erez, and Christian Theobalt. Self-supervised multi-level face model learn- ing for monocular reconstruction at over 250 hz. In2018 IEEE Conference on Computer Vision and Pattern Recog- nition, CVPR 2018, Salt Lake City, UT, USA, June 18- 22, 2018, pages 2549–2559...
2018
-
[77]
Tewari, O
A. Tewari, O. Fried, J. Thies, V . Sitzmann, S. Lombardi, K. Sunkavalli, R. Martin-Brualla, T. Simon, J. Saragih, M. Nießner, R. Pandey, S. Fanello, G. Wetzstein, J.-Y . Zhu, C. Theobalt, M. Agrawala, E. Shechtman, D. B. Goldman, and M. Zollh¨ofer. State of the art on neural rendering.EG, 2020. 2, 3
2020
-
[78]
Thies, M
J. Thies, M. Zollh ¨ofer, M. Stamminger, C. Theobalt, and M. Nießner. Face2Face: Real-time Face Capture and Reenact- ment of RGB Videos. InProc. Computer Vision and Pattern Recognition (CVPR), IEEE, pages 2387–2395, 2016. 3
2016
-
[79]
Vetter and V
T. Vetter and V . Blanz. Estimating coloured 3D face models from single images: An example based approach. InECCV,
-
[80]
George V ogiatzis, Philip H. S. Torr, and Roberto Cipolla. Multi-view stereo via volumetric graph-cuts. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 391–398. IEEE, 2005. 2
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.