Recognition: unknown
Evaluating LLMs on Large-Scale Graph Property Estimation via Random Walks
Pith reviewed 2026-05-09 15:06 UTC · model grok-4.3
The pith
Random walk sampling enables LLMs to estimate properties of graphs with up to millions of nodes
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
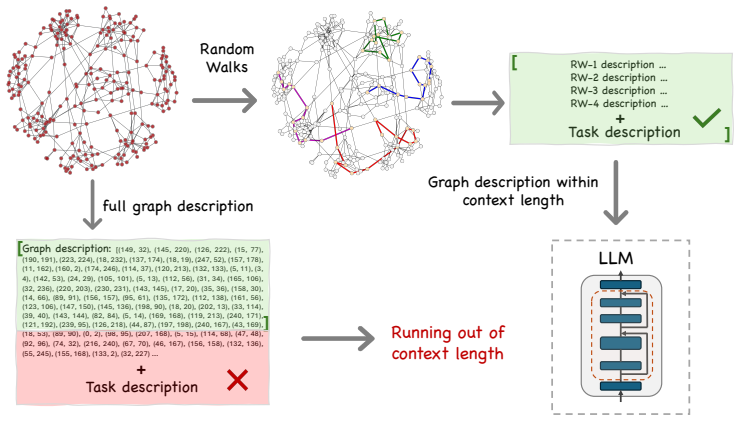
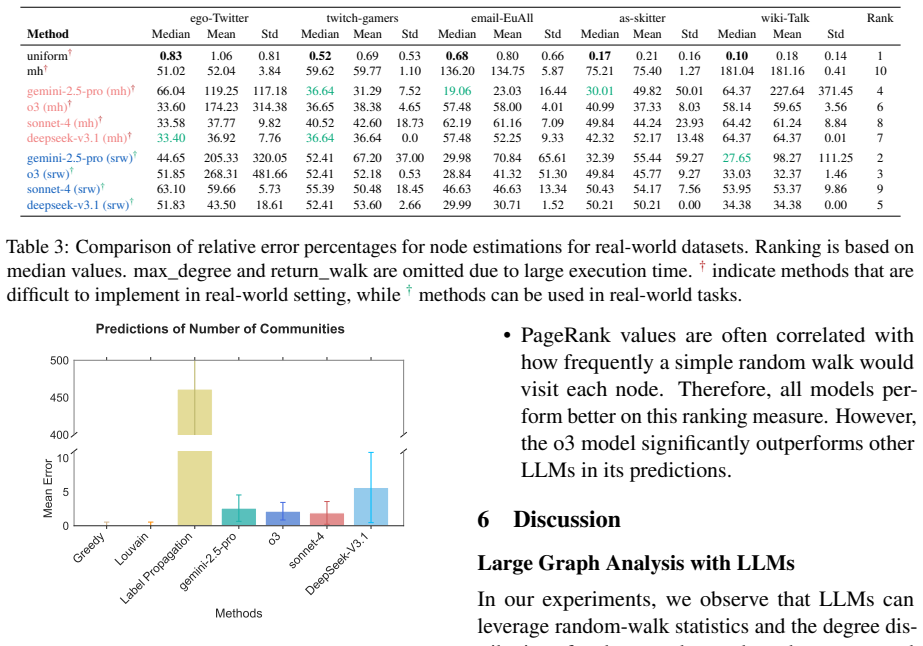
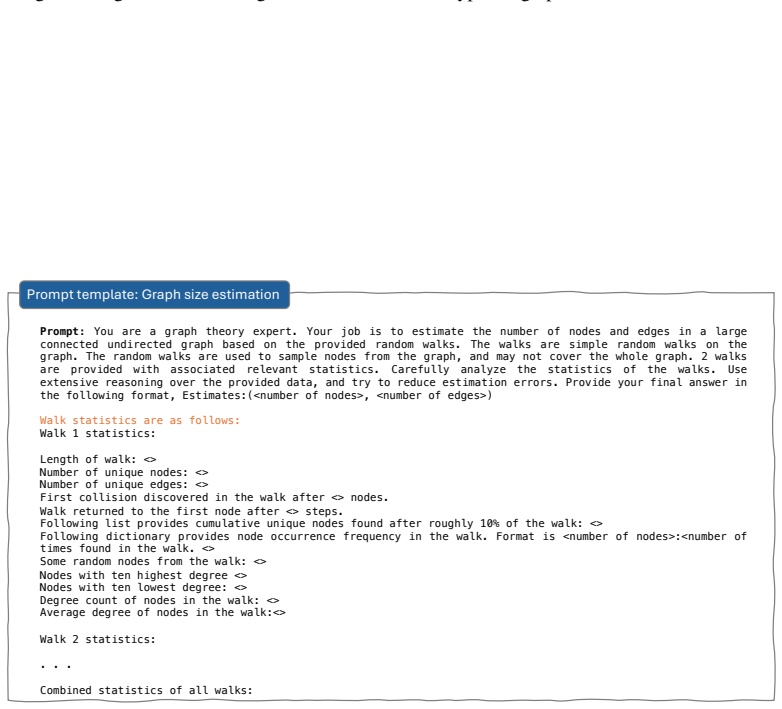
We propose a large graph benchmark dataset, EstGraph, and introduce four distinct tasks designed to estimate large graph properties. We evaluate the reasoning abilities of LLMs on these tasks using a wide variety of graph datasets. In addition, we provide task-specific prompt constructions based on random walk sampling of large graphs (up to millions of nodes) that effectively convey sufficient information to LLMs within the limits of context length.
What carries the argument
task-specific prompt constructions based on random walk sampling of large graphs to generate inputs that fit in LLM context windows
If this is right
- The EstGraph dataset enables systematic evaluation of LLM graph reasoning at realistic scales beyond tiny toy graphs.
- Random walk prompts allow property estimation tasks on graphs with millions of nodes without requiring the full structure in context.
- LLMs can be tested on graph problems drawn from real-world data where only partial access is feasible.
- Task-specific prompt designs make large-graph reasoning feasible within current model constraints.
Where Pith is reading between the lines
- This sampling approach could be tested on other graph properties or domains such as social networks and biological interaction graphs not covered in the initial benchmark.
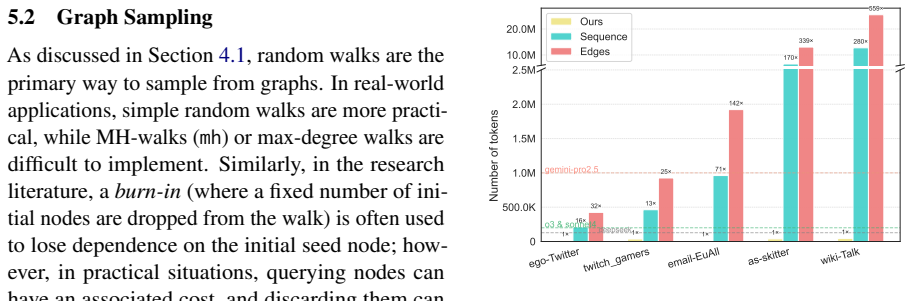
- Accuracy of estimates may vary with graph density or the choice of random walk length, suggesting targeted experiments on those parameters.
- The method opens the possibility of using LLMs for approximate analysis of massive graphs where exact computation is too expensive.
- Comparisons across different LLM families would reveal whether the random-walk prompting generalizes or depends on model scale.
Load-bearing premise
Random walk sampling of large graphs can effectively convey sufficient information to LLMs within the limits of context length for accurate property estimation.
What would settle it
If LLMs given these random walk prompts produce property estimates that consistently differ from the true values computed directly on the full graphs, the effectiveness claim would be falsified.
Figures











read the original abstract
With the rapidly improving reasoning abilities of Large Language Models (LLMs), there is also a rising demand to use them in a wide variety of domains. This brings about the need to carefully evaluate the limits of the capabilities of these models with various tests and benchmarks. Graph structures are ubiquitous in real-world data, and are often used to represent and analyze relationship patterns within data. Many benchmarks have already been proposed in the graph literature to test the reasoning ability of LLMs to follow and execute graph algorithms. However, due to the limited context length of LLMs, these benchmarks consist of very small graphs. In real-world data, the size of graphs can be significantly larger, and in many cases, not fully accessible. In this paper, we examine a class of problems that arises with very large graphs having limited accessibility. We propose a large graph benchmark dataset, EstGraph, and introduce four distinct tasks designed to estimate large graph properties. We evaluate the reasoning abilities of LLMs on these tasks using a wide variety of graph datasets. In addition, we provide task-specific prompt constructions based on random walk sampling of large graphs (up to millions of nodes) that effectively convey sufficient information to LLMs within the limits of context length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EstGraph, a new benchmark dataset for evaluating LLMs on estimating properties of large graphs (up to millions of nodes) that cannot be fully provided due to context limits. It defines four distinct tasks for this estimation, constructs task-specific prompts via random walk sampling, and reports LLM performance across a variety of graph datasets.
Significance. If the random-walk prompts enable accurate property estimation, the benchmark would usefully extend LLM graph-reasoning evaluation beyond the small graphs used in prior work. The proposal of four tasks and use of real-world-scale datasets are concrete strengths that could support reproducible follow-up studies.
major comments (2)
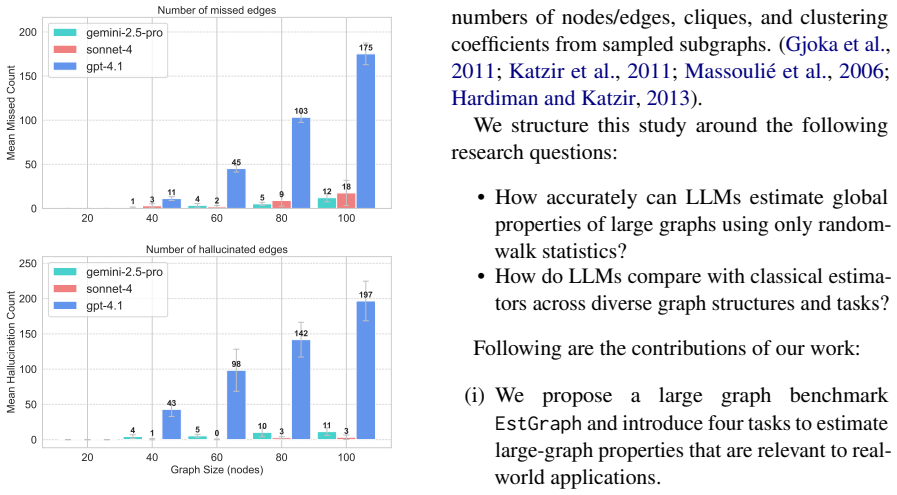
- The central claim that random-walk sampling 'effectively convey[s] sufficient information to LLMs within the limits of context length' for accurate global-property estimation is load-bearing yet unsupported by any reported validation. Random walks are local and degree-biased; without explicit debiasing, variance reduction, or side-by-side comparison to exact values on medium-sized graphs (where full computation is feasible), systematic errors in quantities such as diameter, effective diameter, or betweenness cannot be ruled out even if the LLM reasons correctly over the supplied walks.
- No task definitions, metrics, baselines, or quantitative results appear in the abstract, and the manuscript provides no indication of controls that would confirm the sampling strategy supports the evaluation claims. This absence prevents assessment of whether the four tasks actually test the intended reasoning abilities or merely reflect sampling artifacts.
minor comments (2)
- The abstract would benefit from a single sentence listing the four tasks and the specific graph properties being estimated.
- Notation for the random-walk prompt templates should be introduced with an explicit example in the main text rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of validation and presentation. We address each major comment below and outline revisions to strengthen the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: The central claim that random-walk sampling 'effectively convey[s] sufficient information to LLMs within the limits of context length' for accurate global-property estimation is load-bearing yet unsupported by any reported validation. Random walks are local and degree-biased; without explicit debiasing, variance reduction, or side-by-side comparison to exact values on medium-sized graphs (where full computation is feasible), systematic errors in quantities such as diameter, effective diameter, or betweenness cannot be ruled out even if the LLM reasons correctly over the supplied walks.
Authors: We agree that the claim regarding the informativeness of random-walk samples is central and would benefit from stronger empirical support. The manuscript's core contribution is the evaluation of LLM reasoning over the sampled data for the proposed tasks, but we did not include direct comparisons of random-walk estimates against exact ground-truth values on medium-sized graphs. In the revision, we will add such validation experiments on graphs of intermediate size (where full computation is tractable), including analysis of bias, variance, and any systematic errors for properties like diameter and betweenness. This will be presented in a new subsection on sampling fidelity. revision: yes
-
Referee: No task definitions, metrics, baselines, or quantitative results appear in the abstract, and the manuscript provides no indication of controls that would confirm the sampling strategy supports the evaluation claims. This absence prevents assessment of whether the four tasks actually test the intended reasoning abilities or merely reflect sampling artifacts.
Authors: The abstract is kept concise per standard practice, but the full manuscript defines the four tasks in Section 3, specifies metrics and baselines in Section 4, and reports quantitative results in Section 5 across multiple datasets and models. On controls for sampling artifacts, the current version relies on results from diverse real-world graphs to demonstrate consistency, but does not explicitly discuss or ablate potential biases. We will revise the abstract to briefly summarize the tasks, metrics, and key findings, and add a dedicated discussion of sampling controls and potential artifacts in the methods section to better substantiate the evaluation claims. revision: partial
Circularity Check
No circularity: benchmark proposal without derivation or fitted inputs
full rationale
The paper proposes EstGraph as a new benchmark dataset along with four tasks for LLM-based estimation of large-graph properties via random-walk prompts. No equations, parameter fitting, or mathematical derivations are present in the provided text. The random-walk sampling method is introduced directly as a practical prompt-construction technique rather than derived from prior results or self-citations. The central claims rest on the novelty of the tasks and the empirical evaluation, which remain independent of any self-referential reduction. This is a standard benchmark paper whose methodology does not collapse to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fatemi, Bahare and Halcrow, Jonathan and Perozzi, Bryan , year =. Talk like a. doi:10.48550/ARXIV.2310.04560 , abstract =
-
[2]
, month = apr, year =
Finkelshtein, Ben and Cucerzan, Silviu and Jauhar, Sujay Kumar and White, Ryen W. , month = apr, year =. Actions
-
[3]
Graph-based
Nakagawa, Hiromi and Iwasawa, Yusuke and Matsuo, Yutaka , year =. Graph-based. International
-
[4]
In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Ver- berne, S
Zeng, Xueqiang and Fu, Guangcheng and Chen, Haofei and Peng, Qiyun and Wang, Mingwen , month = jul, year =. Interactive. Proceedings of the 48th. doi:10.1145/3726302.3730214 , abstract =
-
[5]
Qin, Yang and Zhu, Xinning and Tang, Xiaosheng and Zhang, Chunhong and Wu, Kunbao and Chang, Fengjie and Diao, Jianzhou and Hu, Zheng , month = jul, year =. Interpretable. Proceedings of the 48th. doi:10.1145/3726302.3730012 , abstract =
-
[6]
Huang, Zhiwei and Liu, Zitao , month = jul, year =. Artificial. doi:10.1007/978-3-031-98420-4_20 , abstract =
-
[7]
Im, Yoonjin and Choi, Eunseong and Kook, Heejin and Lee, Jongwuk , month = oct, year =. Forgetting-aware. Proceedings of the 32nd. doi:10.1145/3583780.3615191 , abstract =
-
[8]
A survey of deep learning based knowledge tracing from cognitive processing perspective , volume =. Neurocomputing , author =. 2026 , keywords =. doi:10.1016/j.neucom.2025.131879 , abstract =
-
[9]
John YH Bai, Olaf Zawacki-Richter, and Wolfgang Muskens
Knowledge. ACM Comput. Surv. , author =. 2023 , pages =. doi:10.1145/3569576 , abstract =
-
[10]
ACM Trans. Inf. Syst. , author =. 2024 , pages =. doi:10.1145/3638350 , abstract =
-
[11]
Guo, Xiaopeng and Huang, Zhijie and Gao, Jie and Shang, Mingyu and Shu, Maojing and Sun, Jun , month = oct, year =. Enhancing. Proceedings of the 29th. doi:10.1145/3474085.3475554 , abstract =
-
[12]
Addressing two problems in deep knowledge tracing via prediction-consistent regularization , isbn =
Yeung, Chun-Kit and Yeung, Dit-Yan , month = jun, year =. Addressing two problems in deep knowledge tracing via prediction-consistent regularization , isbn =. Proceedings of the. doi:10.1145/3231644.3231647 , abstract =
-
[13]
Piech, Chris and Bassen, Jonathan and Huang, Jonathan and Ganguli, Surya and Sahami, Mehran and Guibas, Leonidas J and Sohl-Dickstein, Jascha , year =. Deep. Advances in
-
[14]
In: Proceedings of The Web Conference 2019 (WWW’19)
Nagatani, Koki and Zhang, Qian and Sato, Masahiro and Chen, Yan-Ying and Chen, Francine and Ohkuma, Tomoko , month = may, year =. Augmenting. The. doi:10.1145/3308558.3313565 , abstract =
-
[15]
User Modeling and User-Adapted Interaction , author =
Knowledge tracing:. User Modeling and User-Adapted Interaction , author =. 1994 , keywords =. doi:10.1007/BF01099821 , abstract =
-
[16]
Squeeze-and-Excitation Networks
Hu, Jie and Shen, Li and Sun, Gang , month = jun, year =. Squeeze-and-. 2018. doi:10.1109/CVPR.2018.00745 , abstract =
-
[17]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, Qilong and Wu, Banggu and Zhu, Pengfei and Li, Peihua and Zuo, Wangmeng and Hu, Qinghua , month = jun, year =. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , publisher =. doi:10.1109/CVPR42600.2020.01155 , abstract =
-
[18]
ArXiv , author =
How. ArXiv , author =
-
[19]
Veisi, Ali and Amirzadeh, Hamidreza and Mansourian, Amir M. , editor =. Context-aware. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.emnlp-main.1545 , abstract =
-
[20]
ArXiv , author =
Train. ArXiv , author =
-
[21]
EAGER: two-stream generative recommender with behavior-semantic collaboration
Cheng, Ke and Peng, Linzhi and Wang, Pengyang and Ye, Junchen and Sun, Leilei and Du, Bowen , month = aug, year =. Proceedings of the 30th. doi:10.1145/3637528.3671773 , abstract =
-
[22]
Proceedings of the 36th
Liu, Zitao and Chen, Jiahao and Liu, Qiongqiong and Huang, Shuyan and Tang, Jiliang and Luo, Weiqi , month = nov, year =. Proceedings of the 36th
-
[23]
doi:10.48550/arXiv.2512.18709 , abstract =
Li, Zhifei and Chen, Lifan and Yi, Jiali and Hou, Xiaoju and Zhao, Yue and Huang, Wenxin and Zhang, Miao and Xiao, Kui and Yang, Bing , month = dec, year =. doi:10.48550/arXiv.2512.18709 , abstract =
-
[24]
Uncertainty-aware knowledge tracing , volume =
Cheng, Weihua and Du, Hanwen and Li, Chunxiao and Ni, Ersheng and Tan, Liangdi and Xu, Tianqi and Ni, Yongxin , month = feb, year =. Uncertainty-aware knowledge tracing , volume =. Proceedings of the. doi:10.1609/aaai.v39i27.35007 , abstract =
-
[25]
Guo, Teng and Qin, Yu and Xia, Yubin and Hou, Mingliang and Liu, Zitao and Xia, Feng and Luo, Weiqi , month = apr, year =. Enhancing. Proceedings of the. doi:10.1145/3696410.3714486 , abstract =
-
[26]
Ghosh, Aritra and Heffernan, Neil and Lan, Andrew S. , month = aug, year =. Context-. Proceedings of the 26th. doi:10.1145/3394486.3403282 , abstract =
-
[27]
Pandey, Shalini and Karypis, George , month = jul, year =. A. doi:10.48550/arXiv.1907.06837 , abstract =
-
[28]
simplekt: a simple but tough-to-beat baseline for knowledge tracing.arXiv preprint arXiv:2302.06881,
Liu, Zitao and Liu, Qiongqiong and Chen, Jiahao and Huang, Shuyan and Luo, Weiqi , month = feb, year =. doi:10.48550/arXiv.2302.06881 , abstract =
-
[29]
Cheng, Weihua and Du, Hanwen and Li, Chunxiao and Ni, Ersheng and Tan, Liangdi and Xu, Tianqi and Ni, Yongxin , month = jan, year =. Uncertainty-aware. doi:10.48550/arXiv.2501.05415 , abstract =
-
[30]
Ivanov, Sergey and Burnaev, Evgeny , month = jun, year =. Anonymous. doi:10.48550/arXiv.1805.11921 , abstract =
-
[31]
Bisnik, Nabhendra and Abouzeid, Alhussein , month = jul, year =. Modeling and. Proceedings of the. doi:10.1109/HOT-P2P.2005.13 , abstract =
-
[32]
Böckling, Martin and Paulheim, Heiko and Iana, Andreea , month = may, year =. Walk&. doi:10.48550/arXiv.2505.16849 , abstract =
-
[33]
Revisiting random walks for learning on graphs.arXiv preprint arXiv:2407.01214,
Kim, Jinwoo and Zaghen, Olga and Suleymanzade, Ayhan and Ryou, Youngmin and Hong, Seunghoon , month = mar, year =. Revisiting. doi:10.48550/arXiv.2407.01214 , abstract =
-
[34]
The anatomy of a large-scale hypertextual. Computer Networks and ISDN Systems , author =. 1998 , keywords =. doi:10.1016/S0169-7552(98)00110-X , abstract =
-
[35]
Angriman, Eugenio and van der Grinten, Alexander and Hamann, Michael and Meyerhenke, Henning and Penschuck, Manuel , editor =. Algorithms for. Algorithms for. 2022 , keywords =. doi:10.1007/978-3-031-21534-6_1 , abstract =
-
[36]
Planetary-scale views on a large instant-messaging network , isbn =
Leskovec, Jure and Horvitz, Eric , month = apr, year =. Planetary-scale views on a large instant-messaging network , isbn =. Proceedings of the 17th international conference on. doi:10.1145/1367497.1367620 , abstract =
-
[37]
Efficient routing on complex networks , volume =
Yan, Gang and Zhou, Tao and Hu, Bo and Fu, Zhong-Qian and Wang, Bing-Hong , month = apr, year =. Efficient routing on complex networks , volume =. Physical Review E , publisher =. doi:10.1103/PhysRevE.73.046108 , abstract =
-
[38]
ACM Trans. Intell. Syst. Technol. , author =. 2016 , pages =. doi:10.1145/2898361 , abstract =
-
[39]
Maps of random walks on complex networks reveal community structure
Rosvall, Martin and Bergstrom, Carl T. , month = jan, year =. Maps of random walks on complex networks reveal community structure , volume =. Proceedings of the National Academy of Sciences , publisher =. doi:10.1073/pnas.0706851105 , abstract =
-
[40]
Dai, Xinnan and Qu, Haohao and Shen, Yifen and Zhang, Bohang and Wen, Qihao and Fan, Wenqi and Li, Dongsheng and Tang, Jiliang and Shan, Caihua , month = apr, year =. How. doi:10.48550/arXiv.2410.05298 , abstract =
-
[41]
Cao, Yixin and Hong, Shibo and Li, Xinze and Ying, Jiahao and Ma, Yubo and Liang, Haiyuan and Liu, Yantao and Yao, Zijun and Wang, Xiaozhi and Huang, Dan and Zhang, Wenxuan and Huang, Lifu and Chen, Muhao and Hou, Lei and Sun, Qianru and Ma, Xingjun and Wu, Zuxuan and Kan, Min-Yen and Lo, David and Zhang, Qi and Ji, Heng and Jiang, Jing and Li, Juanzi and...
-
[42]
Community detection via semi-synchronous label propagation algorithms , url =
Cordasco, Gennaro and Gargano, Luisa , month = dec, year =. Community detection via semi-synchronous label propagation algorithms , url =. 2010. doi:10.1109/BASNA.2010.5730298 , abstract =
-
[43]
Fast Unfolding of Communities in Large Networks
Fast unfolding of communities in large networks , volume =. Journal of Statistical Mechanics: Theory and Experiment , author =. 2008 , pages =. doi:10.1088/1742-5468/2008/10/P10008 , abstract =
-
[44]
Clauset, Aaron and Newman, M. E. J. and Moore, Cristopher , month = dec, year =. Finding community structure in very large networks , volume =. Physical Review E , publisher =. doi:10.1103/PhysRevE.70.066111 , abstract =
-
[45]
Benchmark graphs for testing community detection algorithms , volume =
Lancichinetti, Andrea and Fortunato, Santo and Radicchi, Filippo , month = oct, year =. Benchmark graphs for testing community detection algorithms , volume =. Physical Review E , publisher =. doi:10.1103/PhysRevE.78.046110 , abstract =
-
[46]
Peer counting and sampling in overlay networks: random walk methods , isbn =
Massoulié, Laurent and Le Merrer, Erwan and Kermarrec, Anne-Marie and Ganesh, Ayalvadi , month = jul, year =. Peer counting and sampling in overlay networks: random walk methods , isbn =. Proceedings of the twenty-fifth annual. doi:10.1145/1146381.1146402 , abstract =
-
[47]
Cooper, Colin and Radzik, Tomasz and Siantos, Yiannis , month = jul, year =. Fast. Internet Mathematics , publisher =. doi:10.1080/15427951.2016.1164100 , abstract =
-
[48]
Approximating
Bar-Yossef, Ziv and Berg, Alexander and Chien, Steve and Fakcharoenphol, Jittat and Weitz, Dror , month = sep, year =. Approximating. Proceedings of the 26th
-
[49]
The Journal of Chemical Physics21(6), 1087–1092 (1953) https://doi.org/10.1063/1.1699114
Equation of. The Journal of Chemical Physics , author =. 1953 , pages =. doi:10.1063/1.1699114 , abstract =
-
[50]
The. Computer Networks , author =. 2015 , keywords =. doi:10.1016/j.comnet.2015.07.013 , abstract =
-
[51]
Data Mining and Knowledge Discovery , author =
Sampling online social networks by random walk with indirect jumps , volume =. Data Mining and Knowledge Discovery , author =. 2019 , keywords =. doi:10.1007/s10618-018-0587-5 , abstract =
-
[52]
Chiericetti, Flavio and Dasgupta, Anirban and Kumar, Ravi and Lattanzi, Silvio and Sarlós, Tamás , month = apr, year =. On. Proceedings of the 25th. doi:10.1145/2872427.2883045 , abstract =
-
[53]
Pons, Pascal and Latapy, Matthieu , editor =. Computing. Computer and. 2005 , keywords =. doi:10.1007/11569596_31 , abstract =
-
[54]
Random sampling from a search engine's index , volume =. J. ACM , author =. 2008 , pages =. doi:10.1145/1411509.1411514 , abstract =
-
[55]
On random walk based graph sampling , issn =
Li, Rong-Hua and Yu, Jeffrey Xu and Qin, Lu and Mao, Rui and Jin, Tan , month = apr, year =. On random walk based graph sampling , issn =. 2015. doi:10.1109/ICDE.2015.7113345 , abstract =
-
[56]
IEEE Journal on Selected Areas in Communications , author =
Practical. IEEE Journal on Selected Areas in Communications , author =. 2011 , keywords =. doi:10.1109/JSAC.2011.111011 , abstract =
-
[57]
Measuring the mixing time of social graphs , isbn =
Mohaisen, Abedelaziz and Yun, Aaram and Kim, Yongdae , month = nov, year =. Measuring the mixing time of social graphs , isbn =. Proceedings of the 10th. doi:10.1145/1879141.1879191 , abstract =
-
[58]
Distributed. J. ACM , author =. 2013 , pages =. doi:10.1145/2432622.2432624 , abstract =
-
[59]
A correction to ``The individual ergodic theorem of information theory''
Goodman, Leo A. , month = mar, year =. Snowball. The Annals of Mathematical Statistics , publisher =. doi:10.1214/aoms/1177705148 , abstract =
-
[60]
Walk, not wait: faster sampling over online social networks , volume =. Proc. VLDB Endow. , author =. 2015 , pages =. doi:10.14778/2735703.2735707 , abstract =
-
[61]
Estimating network properties from snowball sampled data , volume =. Social Networks , author =. 2012 , keywords =. doi:10.1016/j.socnet.2012.09.001 , abstract =
-
[62]
and Katzir, Liran , month = may, year =
Hardiman, Stephen J. and Katzir, Liran , month = may, year =. Estimating clustering coefficients and size of social networks via random walk , isbn =. Proceedings of the 22nd international conference on. doi:10.1145/2488388.2488436 , abstract =
-
[63]
Estimating sizes of social networks via biased sampling , isbn =
Katzir, Liran and Liberty, Edo and Somekh, Oren , month = mar, year =. Estimating sizes of social networks via biased sampling , isbn =. Proceedings of the 20th international conference on. doi:10.1145/1963405.1963489 , abstract =
-
[64]
Estimating the. IEEE Access , author =. 2022 , keywords =. doi:10.1109/ACCESS.2022.3149887 , abstract =
-
[65]
and Markopoulou, Athina , month = mar, year =
Gjoka, Minas and Kurant, Maciej and Butts, Carter T. and Markopoulou, Athina , month = mar, year =. Walking in. 2010. doi:10.1109/INFCOM.2010.5462078 , abstract =
-
[66]
Structure and evolution of online social networks
Leskovec, Jure and Faloutsos, Christos , month = aug, year =. Sampling from large graphs , isbn =. Proceedings of the 12th. doi:10.1145/1150402.1150479 , abstract =
-
[67]
Wang, Tianyi and Chen, Yang and Zhang, Zengbin and Xu, Tianyin and Jin, Long and Hui, Pan and Deng, Beixing and Li, Xing , month = jun, year =. Understanding. 2011 31st. doi:10.1109/ICDCSW.2011.34 , abstract =
-
[68]
Estimating
Bawa, Mayank and Garcia-Molina, Hector and Gionis, Aristides and Motwani, Rajeev , month = apr, year =. Estimating
-
[69]
Advances in Neural Information Processing Systems , author =
Microstructures and. Advances in Neural Information Processing Systems , author =. 2024 , pages =
2024
-
[70]
IEEE Transactions on Knowledge and Data Engineering , author =
Large. IEEE Transactions on Knowledge and Data Engineering , author =. 2024 , pages =. doi:10.1109/TKDE.2024.3469578 , abstract =
-
[71]
doi:10.48550/ARXIV.2407.07457 , abstract =
Li, Yuhan and Wang, Peisong and Zhu, Xiao and Chen, Aochuan and Jiang, Haiyun and Cai, Deng and Chan, Victor Wai Kin and Li, Jia , year =. doi:10.48550/ARXIV.2407.07457 , abstract =
-
[72]
Chen, Nuo and Li, Yuhan and Tang, Jianheng and Li, Jia , month = aug, year =. Proceedings of the 30th. doi:10.1145/3637528.3672010 , abstract =
-
[73]
and Zhang, Yu , month = feb, year =
Wei, Yanbin and Fu, Shuai and Jiang, Weisen and Kwok, James T. and Zhang, Yu , month = feb, year =
-
[74]
Li, Xin Sky and Chen, Weize and Chu, Qizhi and Li, Haopeng and Sun, Zhaojun and Li, Ran and Qian, Chen and Wei, Yiwei and Liu, Zhiyuan and Shi, Chuan and Sun, Maosong and Yang, Cheng , month = feb, year =. Can. doi:10.48550/arXiv.2409.19667 , abstract =
-
[75]
Sanford, Clayton and Fatemi, Bahare and Hall, Ethan and Tsitsulin, Anton and Kazemi, Mehran and Halcrow, Jonathan and Perozzi, Bryan and Mirrokni, Vahab , month = may, year =. Understanding. doi:10.48550/arXiv.2405.18512 , abstract =
-
[76]
Grapharena: Evaluating and exploring large language models on graph computation,
Tang, Jianheng and Zhang, Qifan and Li, Yuhan and Chen, Nuo and Li, Jia , month = feb, year =. doi:10.48550/arXiv.2407.00379 , abstract =
-
[77]
Can language models solve graph problems in natural language? , abstract =
Wang, Heng and Feng, Shangbin and He, Tianxing and Tan, Zhaoxuan and Han, Xiaochuang and Tsvetkov, Yulia , month = dec, year =. Can language models solve graph problems in natural language? , abstract =. Proceedings of the 37th
-
[78]
and Mihail, M
Gkantsidis, C. and Mihail, M. and Zegura, E. , year =. The
-
[79]
Abboud, Ralph and Dimitrov, Radoslav and Ceylan, İsmail İlkan , month = nov, year =. Shortest. doi:10.48550/arXiv.2206.01003 , abstract =
-
[80]
Yun, Seongjun and Jeong, Minbyul and Kim, Raehyun and Kang, Jaewoo and Kim, Hyunwoo J. , month = feb, year =. Graph. doi:10.48550/arXiv.1911.06455 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.