Recognition: unknown
Towards Visual Query Localization in the 3D World
Pith reviewed 2026-05-09 14:23 UTC · model grok-4.3
The pith
The first benchmark for 3D visual query localization is introduced along with a fusion method that outperforms existing baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
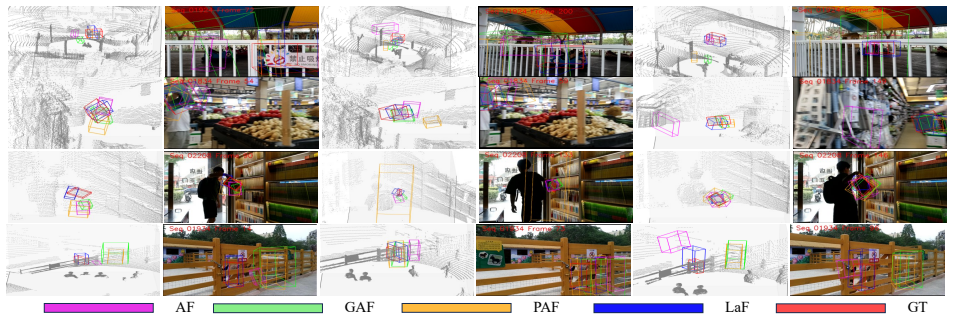
The paper presents 3DVQL as the first benchmark dataset for 3D multimodal visual query localization. It comprises 2,002 sequences totaling around 170,000 frames and 6.4K response track segments spanning 38 object categories. All sequences include point clouds, RGB images, and depth images with high-quality manual annotations verified in multiple rounds. Baselines using various fusion modules are implemented, and the proposed lift-and-attention fusion algorithm LaF is shown to significantly surpass them in predicting the most recent occurrence of the query.
What carries the argument
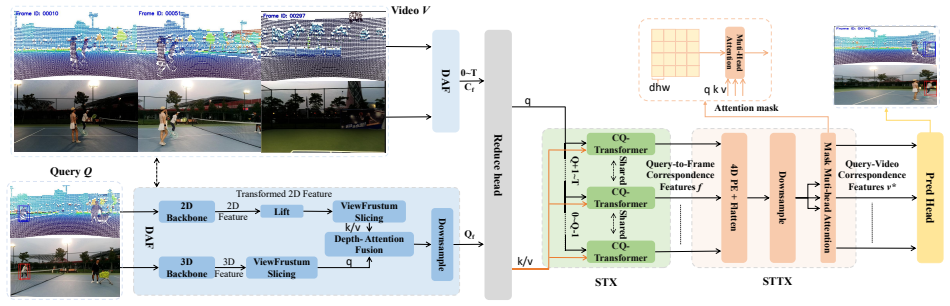
LaF, or lift-and-attention fusion, which lifts 2D features to 3D and applies attention to integrate point cloud and image data for localizing visual queries.
Load-bearing premise
The 2002 manually annotated sequences sufficiently represent the variety of real-world 3D scenes and the baselines adequately represent current multimodal fusion techniques.
What would settle it
A follow-up experiment showing that LaF does not outperform other fusion methods on a new set of 3D sequences collected independently or that benchmark scores do not predict performance in physical 3D environments.
Figures









read the original abstract
Visual query localization (VQL) aims to predict the spatio-temporal response of the most recent occurrence in a sequence given a query. Currently, most research focuses on visual query localization in 2D videos, while its counterpart in 3D space has received little attention. In this paper, we make the first attempt to address visual query localization in the 3D world by introducing a novel benchmark, dubbed 3DVQL. Specifically, 3DVQL contains 2,002 sequences with around 170,000 frames and 6.4K response track segments from 38 object categories. Each sequence in 3DVQL is provided with multiple modalities, including point clouds, RGB images, and depth images, to support flexible research. To ensure high-quality annotations, each sequence is manually annotated with multiple rounds of verification and refinement. To the best of our knowledge, 3DVQL is the first benchmark for 3D multimodal visual query localization. To facilitate comparison in subsequent research, we implement a series of representative 3D multimodal VQL baselines using point clouds and RGB images. The experimental results show that existing methods exhibit significant performance variations across different fusion modules. To encourage future research, we propose a lift-and-attention fusion algorithm named LaF, which significantly outperforms existing baseline models. Our benchmark and model will be publicly released at https://github.com/wuhengliangliang/3DVQL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 3DVQL, the first benchmark for 3D multimodal visual query localization, comprising 2,002 manually annotated sequences (~170k frames, 6.4k response tracks, 38 categories) with point-cloud, RGB, and depth modalities. It implements representative 3D multimodal baselines, documents large performance variation across fusion modules, and proposes a lift-and-attention fusion (LaF) module that outperforms the baselines.
Significance. If the benchmark annotations prove reliable and the LaF gains hold under standard splits and significance testing, the work would establish a new task and evaluation protocol for multimodal 3D localization, with the public release of data and code providing immediate value to the community. The multi-round manual verification pipeline is a concrete strength for data quality.
major comments (2)
- [§5] §5 (Experimental Results): the claim that LaF 'significantly outperforms' existing baselines is not accompanied by per-sequence or per-category standard deviations, confidence intervals, or statistical significance tests (e.g., paired t-test or Wilcoxon); without these, the reported gains cannot be assessed as robust rather than driven by a few easy sequences.
- [§4.2] §4.2 (Baseline Implementations): the adaptation of 2D VQL methods to 3D point-cloud inputs is described at a high level; the precise projection, voxelization, or feature-lifting steps used for each baseline are not specified, preventing exact reproduction of the reported performance variation across fusion modules.
minor comments (2)
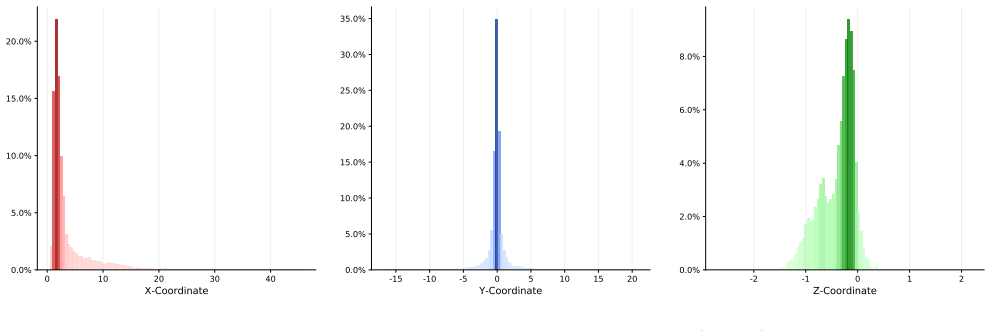
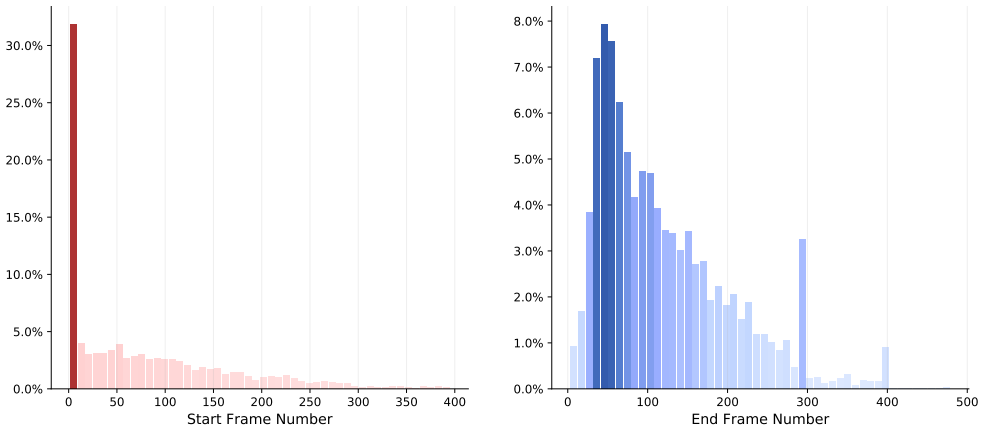
- [§3] §3 (Dataset Construction): the diversity statistics (e.g., scene-type distribution, camera-motion statistics) across the 2,002 sequences are not tabulated; adding a short summary table would strengthen the claim that the benchmark is representative.
- [Figure 3] Figure 3 and Table 1: axis labels and column headers use inconsistent abbreviations (e.g., 'PC' vs. 'point cloud'); a unified notation table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects for improving the clarity and rigor of our work on the 3DVQL benchmark and LaF module. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Results): the claim that LaF 'significantly outperforms' existing baselines is not accompanied by per-sequence or per-category standard deviations, confidence intervals, or statistical significance tests (e.g., paired t-test or Wilcoxon); without these, the reported gains cannot be assessed as robust rather than driven by a few easy sequences.
Authors: We acknowledge that the manuscript reports mean performance metrics without accompanying variance estimates or formal statistical tests, which limits the ability to rigorously substantiate the 'significantly outperforms' claim. While the gains appear consistent across the 38 categories and multiple baselines, we agree this is insufficient. In the revision we will add per-category and per-sequence standard deviations, 95% confidence intervals, and results from paired statistical tests (Wilcoxon signed-rank test on sequence-level metrics) to §5. These additions will be computed from the existing evaluation runs and included in the updated tables and text. revision: yes
-
Referee: [§4.2] §4.2 (Baseline Implementations): the adaptation of 2D VQL methods to 3D point-cloud inputs is described at a high level; the precise projection, voxelization, or feature-lifting steps used for each baseline are not specified, preventing exact reproduction of the reported performance variation across fusion modules.
Authors: We agree that the current description in §4.2 is insufficiently detailed for full reproducibility. In the revised manuscript we will expand this section with explicit implementation details for each baseline, including the precise 2D-to-3D projection method (e.g., depth-based lifting), voxelization grid resolution and coordinate mapping, feature extraction backbone choices, and any additional lifting or fusion steps. These specifications will be accompanied by pseudocode or a supplementary implementation note to enable exact replication of the reported baseline results and performance variations. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core contributions are the creation of a new manually annotated benchmark dataset (3DVQL with 2002 sequences) and the proposal of a lift-and-attention fusion module (LaF). These are empirical and constructive: the benchmark is defined by its collection and annotation process, while LaF is presented as a new algorithm whose performance is measured against separately implemented baselines on the new data. No equations, fitted parameters, or self-citations are used to derive the central claims by construction. The novelty assertion ('first benchmark') is a factual claim about prior literature rather than a self-referential loop, and the experimental section reports direct comparisons without reducing predictions to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manual multi-round annotation produces reliable ground-truth response tracks
Reference graph
Works this paper leans on
-
[1]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 5
2015
-
[2]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InCVPR, 2020. 3
2020
-
[3]
Monocular 3d object detection for autonomous driving
Xiaozhi Chen, Kaustav Kundu, Ziyu Zhang, Huimin Ma, Sanja Fidler, and Raquel Urtasun. Monocular 3d object detection for autonomous driving. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2147–2156, 2016. 3
2016
-
[4]
Focal sparse convolutional networks for 3d object detection
Yukang Chen, Yanwei Li, Xiangyu Zhang, Jian Sun, and Ji- aya Jia. Focal sparse convolutional networks for 3d object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5428–5437,
-
[5]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 3
2017
-
[6]
Lidar-camera calibration using 3d-3d point correspondences.arXiv, 2017
Ankit Dhall, Kunal Chelani, Vishnu Radhakrishnan, and K Madhava Krishna. Lidar-camera calibration using 3d-3d point correspondences.arXiv, 2017. 2
2017
-
[7]
An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021. 6, 7
2021
-
[8]
Bing Fan, Yunhe Feng, Yapeng Tian, James Chenhao Liang, Yuewei Lin, Yan Huang, and Heng Fan. Prvql: Progres- sive knowledge-guided refinement for robust egocentric vi- sual query localization.arXiv preprint arXiv:2502.07707,
-
[9]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InCVPR, 2012. 3
2012
-
[10]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 1, 2, 4, 5
2022
-
[11]
Single-stage visual query localization in egocen- tric videos.Advances in Neural Information Processing Sys- tems, 36:24143–24157, 2023
Hanwen Jiang, Santhosh Kumar Ramakrishnan, and Kristen Grauman. Single-stage visual query localization in egocen- tric videos.Advances in Neural Information Processing Sys- tems, 36:24143–24157, 2023. 1, 2, 3, 6, 7
2023
-
[12]
Gsot3d: Towards generic 3d single object tracking in the wild
Yifan Jiao, Yunhao Li, Junhua Ding, Qing Yang, Song Fu, Heng Fan, and Libo Zhang. Gsot3d: Towards generic 3d single object tracking in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5469–5478, 2025. 2
2025
-
[13]
Re- locate: A simple training-free baseline for visual query local- ization using region-based representations
Savya Khosla, Alexander Schwing, Derek Hoiem, et al. Re- locate: A simple training-free baseline for visual query local- ization using region-based representations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3697–3706, 2025. 2
2025
-
[14]
The eighth visual object tracking vot2020 chal- lenge results
Matej Kristan, Ale ˇs Leonardis, Ji ˇr´ı Matas, Michael Fels- berg, Roman Pflugfelder, Joni-Kristian K ¨am¨ar¨ainen, Martin Danelljan, Luka ˇCehovin Zajc, Alan Luke ˇziˇc, Ondrej Dr- bohlav, et al. The eighth visual object tracking vot2020 chal- lenge results. InEuropean conference on computer vision, pages 547–601. Springer, 2020. 6
2020
-
[15]
Monocular 3d object detection leveraging accurate proposals and shape reconstruction
Jason Ku, Alex D Pon, and Steven L Waslander. Monocular 3d object detection leveraging accurate proposals and shape reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11867– 11876, 2019. 3
2019
-
[16]
Uniformerv2: Unlocking the po- tential of image vits for video understanding
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. Uniformerv2: Unlocking the po- tential of image vits for video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 1632–1643, 2023. 1
2023
-
[17]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195– 22206, 2024
2024
-
[18]
Position: Prospective of au- tonomous driving-multimodal llms world models embodied intelligence ai alignment and mamba
Yunsheng Ma, Wenqian Ye, Can Cui, Haiming Zhang, Shuo Xing, Fucai Ke, Jinhong Wang, Chenglin Miao, Jintai Chen, Hamid Rezatofighi, et al. Position: Prospective of au- tonomous driving-multimodal llms world models embodied intelligence ai alignment and mamba. InProceedings of the Winter Conference on Applications of Computer Vision, pages 1010–1026, 2025. 1
2025
-
[19]
3d bounding box estimation using deep learn- ing and geometry
Arsalan Mousavian, Dragomir Anguelov, John Flynn, and Jana Kosecka. 3d bounding box estimation using deep learn- ing and geometry. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7074– 7082, 2017. 3
2017
-
[20]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660,
-
[22]
Point- voxel feature set abstraction for 3d object detection
Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li Pv-rcnn. Point- voxel feature set abstraction for 3d object detection. 2020 ieee. InCVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10526–10535, 2019. 3, 7
2020
-
[23]
Pointr- cnn: 3d object proposal generation and detection from point cloud
Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointr- cnn: 3d object proposal generation and detection from point cloud. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 770–779, 2019. 3, 6
2019
-
[24]
Sun rgb-d: A rgb-d scene understanding benchmark suite
Shuran Song, Samuel P Lichtenberg, and Jianxiong Xiao. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 567–576, 2015. 3
2015
-
[25]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 3
2020
-
[26]
Pointpainting: Sequential fusion for 3d object de- tection
Sourabh V ora, Alex H Lang, Bassam Helou, and Oscar Bei- jbom. Pointpainting: Sequential fusion for 3d object de- tection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4604–4612,
-
[27]
Embodiedscan: A holistic multi- modal 3d perception suite towards embodied ai
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, et al. Embodiedscan: A holistic multi- modal 3d perception suite towards embodied ai. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19757–19767, 2024. 1
2024
-
[28]
Nega- tive frames matter in egocentric visual query 2d localization
Mengmeng Xu, Cheng-Yang Fu, Yanghao Li, Bernard Ghanem, Juan-Manuel Perez-Rua, and Tao Xiang. Nega- tive frames matter in egocentric visual query 2d localization. arXiv preprint arXiv:2208.01949, 2022. 1, 2, 3
-
[29]
Where is my wallet? modeling object proposal sets for egocentric visual query localization
Mengmeng Xu, Yanghao Li, Cheng-Yang Fu, Bernard Ghanem, Tao Xiang, and Juan-Manuel P ´erez-R´ua. Where is my wallet? modeling object proposal sets for egocentric visual query localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2593–2603, 2023. 1, 2, 3
2023
-
[30]
Mbptrack: Improving 3d point cloud tracking with memory networks and box priors
Tian-Xing Xu, Yuan-Chen Guo, Yu-Kun Lai, and Song-Hai Zhang. Mbptrack: Improving 3d point cloud tracking with memory networks and box priors. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9911–9920, 2023. 7
2023
-
[31]
Towards generic 3d track- ing in rgbd videos: Benchmark and baseline
Jinyu Yang, Zhongqun Zhang, Zhe Li, Hyung Jin Chang, Aleˇs Leonardis, and Feng Zheng. Towards generic 3d track- ing in rgbd videos: Benchmark and baseline. InEuropean Conference on Computer Vision, pages 112–128. Springer,
-
[32]
Center- based 3d object detection and tracking
Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. Center- based 3d object detection and tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11784–11793, 2021. 3, 7
2021
-
[33]
Harley, and Katerina Fragkiadaki
Bowei Zhang, Lei Ke, Adam W Harley, and Katerina Fragki- adaki. Tapip3d: Tracking any point in persistent 3d geome- try.arXiv preprint arXiv:2504.14717, 2025. 7
-
[34]
V oxelnet: End-to-end learning for point cloud based 3d object detection
Yin Zhou and Oncel Tuzel. V oxelnet: End-to-end learning for point cloud based 3d object detection. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 4490–4499, 2018. 3
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.