Recognition: unknown
Two-Pass Zero-Shot Temporal-Spatial Grounding of Rare Traffic Events in Surveillance Video
Pith reviewed 2026-05-09 14:06 UTC · model grok-4.3
The pith
A two-pass zero-shot pipeline with frozen vision-language models grounds rare traffic events in time, space, and type on real CCTV footage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A coarse-to-fine two-pass decomposition combined with specialist role assignment between two frozen vision-language models produces accurate joint (t, x, y, c) grounding of rare traffic events directly from real CCTV video, reaching ACC^S of 0.539 on the 2,027-video benchmark without any fine-tuning or labeled accident examples.
What carries the argument
The two-pass coarse-to-fine decomposition with deterministic confidence gates and role-specialized assignment of vision-language models to grounding versus typing subtasks.
If this is right
- Accurate joint grounding of rare events becomes possible without collecting and labeling large accident video datasets for training.
- The two-pass refinement plus gates raises precision over single-pass zero-shot baselines while limiting the impact of model uncertainty.
- Specialist model assignment allows combining strengths of different frozen models without retraining or merging them.
- The method scales to thousands of videos at modest API cost, opening the door to automated analysis of large existing CCTV archives.
Where Pith is reading between the lines
- Similar coarse-to-fine decomposition with fallback gates could be tested on other temporal localization tasks such as action spotting in sports video.
- If the gates prove general, they offer a lightweight way to increase reliability when applying off-the-shelf models to safety-critical rare-event detection.
- The low per-video cost suggests the pipeline could support continuous monitoring on live feeds if API latency is reduced.
Load-bearing premise
The chosen vision-language models can accurately locate and classify rare traffic events in real CCTV footage in zero-shot mode, and the confidence gates can handle uncertain cases without introducing systematic bias.
What would settle it
Applying the same pipeline to a new collection of labeled rare-event CCTV videos and measuring accuracy substantially below 0.539 or no better than the single-VLM baseline would show the two-pass structure does not deliver the claimed grounding performance.
Figures


read the original abstract
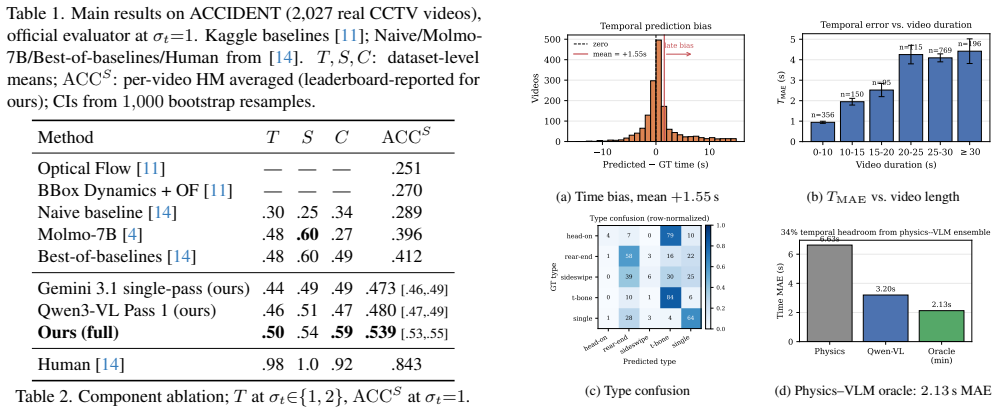
Grounding traffic accidents in real CCTV footage is a rare-event problem where training on labeled accident video is often prohibited, yet accurate joint localization in time, space, and collision type is required. We present a no-fine-tuning pipeline that elicits this joint output from frozen vision-language models through two ideas. First, a coarse-to-fine two-pass decomposition: a full-video pass at 1 fps produces a coarse (t, x, y, c) tuple, then a second pass at 5 fps within a +/- 3 s window refines time and location, with two deterministic confidence gates that revert to the coarse estimate on boundary hedges or edge-clamped coordinates. Second, a specialist role assignment: Qwen3-VL-Plus handles grounding, Gemini 3.1 Flash-Lite handles typing on a centered video clip. On the ACCIDENT@CVPR 2026 benchmark (2,027 real CCTV videos) we reach ACC^S = 0.539 (95% CI [0.525, 0.553]): +0.127 over the benchmark paper's best-of-baselines oracle (0.412), +0.143 over the strongest single-VLM baseline (Molmo-7B, 0.396), and +0.250 over the naive baseline (0.289). The VLM path uses up to three API calls per video (17% fall back to physics on API failures); the full run costs ~$20.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a no-fine-tuning, zero-shot pipeline for joint temporal-spatial grounding and collision typing of rare traffic accidents in real CCTV videos. It decomposes the task into a coarse 1 fps full-video pass using Qwen3-VL-Plus to produce an initial (t, x, y, c) tuple, followed by a gated 5 fps refinement pass within a ±3 s window; two deterministic confidence gates revert to the coarse estimate on boundary hedges or edge-clamped coordinates, with Gemini 3.1 Flash-Lite handling typing on a centered clip. On the ACCIDENT@CVPR 2026 benchmark of 2,027 videos the method reports ACC^S = 0.539 (95% CI [0.525, 0.553]), outperforming the benchmark's best oracle baseline (0.412), the strongest single-VLM baseline (0.396), and a naive baseline (0.289) at a cost of ~$20 with at most three API calls per video (17 % physics fallback).
Significance. If the reported margin is shown to arise from the two-pass structure and gates rather than VLM-specific behavior, the work provides a practical, low-cost route to accurate rare-event localization in video without labeled training data or model adaptation. This could be valuable for traffic-safety and surveillance applications where supervised data collection is restricted.
major comments (2)
- [Methods (two-pass pipeline and confidence gates)] The central claim attributes the +0.127 ACC^S gain over the oracle baseline to the two-pass decomposition and deterministic confidence gates, yet no ablation is presented that isolates the gates (e.g., by disabling them or replacing them with always-accept fine-pass output). Without this, it remains possible that the improvement is driven by the particular choice of Qwen3-VL-Plus rather than the proposed pipeline architecture.
- [Experiments and Results] No quantitative breakdown is given of gate-trigger frequency, the distribution of physics-fallback cases (17 % of videos), or error patterns on those videos. Such analysis is required to verify that the gates do not systematically discard correct fine-grained predictions on the tail of the accident distribution, which would inflate the headline ACC^S figure.
minor comments (2)
- [Methods] The exact decision rules for 'boundary hedges' and 'edge-clamped coordinates' are described only at a high level; a precise algorithmic statement or pseudocode would improve reproducibility.
- [Abstract and Results] The abstract and results section use ACC^S without an inline definition or reference to its precise formulation (e.g., whether it is a joint accuracy over time, space, and class).
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need to better isolate the contributions of the two-pass pipeline and to provide supporting analysis for the confidence gates. We address each major comment below and will incorporate the requested elements in the revised manuscript.
read point-by-point responses
-
Referee: [Methods (two-pass pipeline and confidence gates)] The central claim attributes the +0.127 ACC^S gain over the oracle baseline to the two-pass decomposition and deterministic confidence gates, yet no ablation is presented that isolates the gates (e.g., by disabling them or replacing them with always-accept fine-pass output). Without this, it remains possible that the improvement is driven by the particular choice of Qwen3-VL-Plus rather than the proposed pipeline architecture.
Authors: We agree that a direct ablation isolating the gates and two-pass structure is required to strengthen attribution of the gains. The existing single-VLM baseline (Molmo-7B at 0.396) uses a different model and lacks the decomposition, while the oracle baseline (0.412) is from the benchmark paper. To address the concern about VLM-specific effects, the revised manuscript will include a new ablation: Qwen3-VL-Plus run in a single-pass mode (full video at 1 fps, no refinement pass or gates). This will quantify the incremental benefit of the proposed architecture over the same VLM without the two-pass design. We expect this to confirm that the +0.127 margin arises primarily from the pipeline rather than model choice alone. revision: yes
-
Referee: [Experiments and Results] No quantitative breakdown is given of gate-trigger frequency, the distribution of physics-fallback cases (17 % of videos), or error patterns on those videos. Such analysis is required to verify that the gates do not systematically discard correct fine-grained predictions on the tail of the accident distribution, which would inflate the headline ACC^S figure.
Authors: We agree that this breakdown is necessary to validate the gates. The gates revert to the coarse estimate only on boundary hedges or edge-clamped coordinates, which are designed to flag unreliable fine-pass outputs. The 17% physics fallback occurs exclusively on API failures. In the revision we will add a dedicated analysis section (with table) reporting: (i) trigger rates for each gate type across the 2,027 videos, (ii) characteristics of the physics-fallback subset (e.g., accident duration, type distribution), and (iii) error patterns comparing fallback vs. non-fallback cases, including whether fallbacks disproportionately affect tail events. This will show that the gates improve robustness by correcting errors rather than discarding correct fine predictions. revision: yes
Circularity Check
No circularity: purely empirical pipeline on external benchmark
full rationale
The manuscript describes a zero-shot two-pass VLM pipeline evaluated directly on the ACCIDENT@CVPR 2026 benchmark (2,027 videos). No equations, derivations, parameter fitting, or self-citations appear in the provided text. The reported ACC^S = 0.539 is a direct measurement, not a constructed prediction. The deterministic gates and fallback logic are implementation details whose correctness is assessed empirically, not by construction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
free parameters (3)
- coarse sampling rate =
1 fps
- fine sampling rate =
5 fps
- refinement window =
+/- 3 seconds
axioms (1)
- domain assumption Commercial vision-language models can perform zero-shot temporal and spatial grounding on surveillance video
Reference graph
Works this paper leans on
-
[1]
Jinze Bai et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Uncertainty-based traffic accident anticipation with spatio-temporal relational learning
Wentao Bao, Qi Yu, and Yu Kong. Uncertainty-based traffic accident anticipation with spatio-temporal relational learning. InACM MM, 2020. 2
2020
-
[3]
VideoMiner: Iteratively grounding key frames of hour-long videos via tree-based group relative pol- icy optimization
Xiangyu Cao et al. VideoMiner: Iteratively grounding key frames of hour-long videos via tree-based group relative pol- icy optimization. InICCV, 2025. 2
2025
-
[4]
Molmo and PixMo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke et al. Molmo and PixMo: Open weights and open data for state-of-the-art vision-language models. InCVPR,
-
[5]
Vision-based traffic accident detection and anticipation: A survey.IEEE TCSVT, 2023
Jianwu Fang, Jiahuan Qiao, Jianru Xue, and Zhengguo Li. Vision-based traffic accident detection and anticipation: A survey.IEEE TCSVT, 2023. 2
2023
-
[6]
Gemini 3: A family of highly capable multimodal models, 2025
Google DeepMind. Gemini 3: A family of highly capable multimodal models, 2025. Technical report. 1, 2
2025
-
[7]
TRACE: Temporal grounding video LLM via causal event modeling
Yongxin Guo et al. TRACE: Temporal grounding video LLM via causal event modeling. InICLR, 2025. 2
2025
-
[8]
ReVisionLLM: Recursive vision- language model for temporal grounding in hour-long videos
Tanveer Hannan et al. ReVisionLLM: Recursive vision- language model for temporal grounding in hour-long videos. InCVPR, 2025. 2
2025
-
[9]
VTimeLLM: Empower LLM to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. VTimeLLM: Empower LLM to grasp video moments. InCVPR, 2024. 2
2024
-
[10]
ACCIDENT @ CVPR 2026: Public baseline notebooks (optical flow ACCs=0.251, bbox dynamics + of ACCs=0.270)
Kaggle Competition Organizers. ACCIDENT @ CVPR 2026: Public baseline notebooks (optical flow ACCs=0.251, bbox dynamics + of ACCs=0.270). https://www.kaggle. com/competitions/accident/code, 2026. 1, 4
2026
-
[11]
Muhammad Monjurul Karim, Yu Li, Ruwen Qin, and Zhaozheng Yin. DSTA: A dynamic spatial-temporal atten- tion network for early anticipation of traffic accidents.arXiv preprint arXiv:2106.10197, 2021. 2
-
[12]
DINOv2: Learning robust visual features without supervision.Trans
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, et al. DINOv2: Learning robust visual features without supervision.Trans. Mach. Learn. Res., 2024. 2
2024
-
[13]
ACCIDENT: A Benchmark Dataset for Vehicle Accident Detection from Traffic Surveillance Videos
Luk´aˇs Picek, Michal ˇCerm´ak, Marek Hanzl, and V ojt ˇech ˇCerm´ak. ACCIDENT: A benchmark dataset for vehicle accident detection from traffic surveillance videos.arXiv preprint arXiv:2604.09819, 2026. Project page: https: //accidentbench.github.io/. 1, 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
CADP: A novel dataset for CCTV traffic camera based accident analysis
Ankit Parag Shah, Jean-Baptiste Lamare, Tuan Nguyen Anh, and Alexander Hauptmann. CADP: A novel dataset for CCTV traffic camera based accident analysis. InAVSS, 2018. 2
2018
-
[15]
Amey Thakur and Sarvesh Talele. A modular zero-shot pipeline for accident detection, localization, and classification in traffic surveillance video.arXiv preprint arXiv:2604.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Michael Tschannen et al. SigLIP 2: Multilingual vision- language encoders with improved semantic understand- ing, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[17]
Grounded-VideoLLM: Sharpening fine- grained temporal grounding in video large language models
Haibo Wang et al. Grounded-VideoLLM: Sharpening fine- grained temporal grounding in video large language models. InFindings of EMNLP, 2025. 2
2025
-
[18]
VideoTree: Adaptive tree-based video representation for LLM reasoning on long videos
Ziyang Wang et al. VideoTree: Adaptive tree-based video representation for LLM reasoning on long videos. InCVPR,
-
[19]
VadCLIP: Adapting vision-language models for weakly supervised video anomaly detection
Peng Wu, Xuerong Zhou, Guansong Pang, Lingru Zhou, Qingsen Yan, Peng Wang, and Yanning Zhang. VadCLIP: Adapting vision-language models for weakly supervised video anomaly detection. InAAAI, 2024. 2
2024
-
[20]
Yajun Xu et al. TAD: A large-scale benchmark for traffic accidents detection from video surveillance.arXiv preprint arXiv:2209.12386, 2022. 2
-
[21]
DoTA: Unsupervised detection of traffic anomaly in driving videos.IEEE TPAMI, 2022
Yu Yao, Xizi Wang, Mingze Xu, Zelin Pu, Ella Atkins, and David Crandall. DoTA: Unsupervised detection of traffic anomaly in driving videos.IEEE TPAMI, 2022. 2
2022
-
[22]
Harnessing large language models for training-free video anomaly detection
Luca Zanella, Willi Menapace, Massimiliano Mancini, Yim- ing Wang, and Elisa Ricci. Harnessing large language models for training-free video anomaly detection. InCVPR, 2024. 2
2024
-
[23]
AnomalyCLIP: Object-agnostic prompt learning for zero-shot anomaly detection
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. AnomalyCLIP: Object-agnostic prompt learning for zero-shot anomaly detection. InICLR, 2024. 2 A. Prompts All three prompts are reproduced verbatim. Model API snapshots used for submission: qwen3-vl-plus (Al- ibaba DashScope, April 2026 endpoint dashscope-us), gemini-3.1-flash-lite-preview (Go...
2024
-
[24]
Time: At what second does the collision or accident impact occur?
-
[25]
Return coordinates as values between 0 and 1000, where (0,0) is top-left and (1000,1000) is bottom-right of the frame
Location: Point to the exact location in the frame where the impact happens. Return coordinates as values between 0 and 1000, where (0,0) is top-left and (1000,1000) is bottom-right of the frame
-
[26]
time": <seconds>,
Type: head-on, rear-end, t-bone, sideswipe, or single. Return ONLY a JSON object: {"time": <seconds>, "x": <0-1000>, "y": <0-1000>, "type": "<type>"} A.2. Pass 2 (Qwen3-VL, fine T+S) These frames are extracted at 5 frames per second from a traffic surveillance video. Each frame is 5 labeled with its precise timestamp. The time window shown is from {start}...
-
[27]
Exact time: The precise moment (to 0.1 second) of collision or impact
-
[28]
time": <seconds with 1 decimal or -1>,
Exact location: The impact point, as coordinates between 0 and 1000. If you cannot see a collision in these frames, return time as -1. Return ONLY a JSON object: {"time": <seconds with 1 decimal or -1>, "x": <0-1000>, "y": <0-1000>} A.3. Type Classification (Gemini 3.1) A traffic collision HAS occurred in this surveillance clip. You MUST classify its type...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.