Recognition: unknown
VAnim: Rendering-Aware Sparse State Modeling for Structure-Preserving Vector Animation
Pith reviewed 2026-05-09 14:02 UTC · model grok-4.3
The pith
VAnim generates text-to-SVG animations through sparse updates to a fixed vector structure instead of full sequence regeneration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Animation is reconceptualized as Sparse State Updates on a persistent SVG DOM tree rather than sequence generation. This yields sequence compression exceeding 9.8 times while preserving the full DOM structure and all non-participating elements by construction. An Identification-First Motion Planning step grounds text instructions to explicit visual entities, and Rendering-Aware Reinforcement Learning via Group Relative Policy Optimization aligns the discrete code updates with high-fidelity visual signals from a video perception model, overcoming the non-differentiable rendering barrier.
What carries the argument
Sparse State Updates (SSU) on a persistent SVG DOM tree, which performs targeted code modifications while leaving the overall structure and untouched elements unchanged.
If this is right
- Generated animations remain fully editable as standard SVG files with preserved topology and non-rigid motion capability.
- Generation becomes more efficient through sequence length reduction while still supporting complex open-domain instructions.
- Semantic alignment improves because updates are grounded to specific visual entities before code changes occur.
- Professional workflows benefit from resolution-independent output that does not require post-processing to restore structure.
- The same persistent-structure approach can handle both rigid and non-rigid deformations without separate pipelines.
Where Pith is reading between the lines
- Design tools could add direct natural-language editing of existing SVG files by reusing the same sparse-update loop.
- The compression benefit may extend to other vector formats if the DOM persistence pattern is adapted.
- Interactive preview loops become feasible because each update can be rendered and checked without regenerating the entire file.
- Longer animation sequences could be composed by chaining multiple sparse-update stages on the same base structure.
Load-bearing premise
The hybrid visual reward from a video perception model will correctly steer discrete SVG code changes toward faithful motion without misalignment or entity errors in the initial planning step.
What would settle it
A set of test cases with non-rigid deformations where the output SVG either loses topological consistency, alters non-participating elements, or visually diverges from the motion described in the input text.
Figures


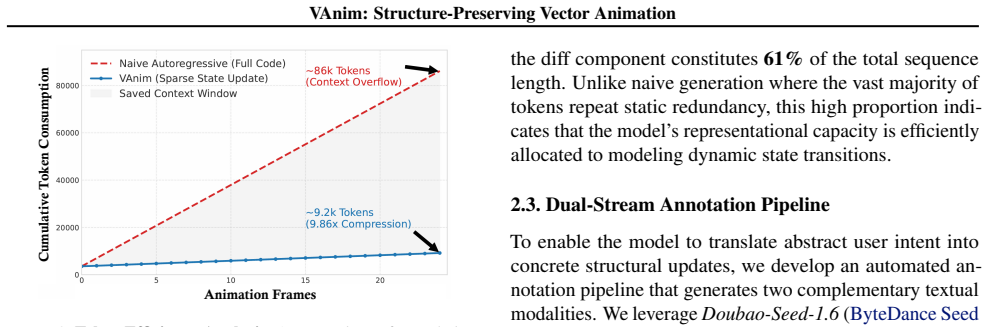

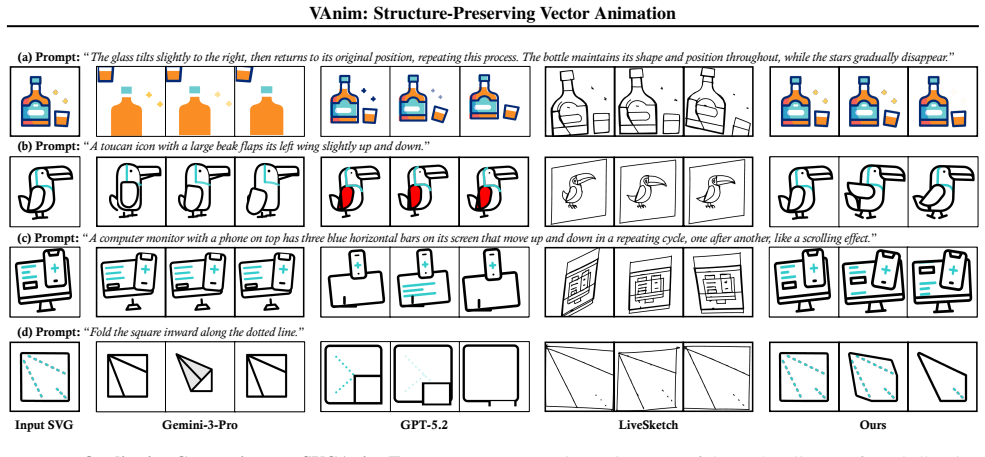

read the original abstract
Scalable Vector Graphics (SVG) animation generation is pivotal for professional design due to their structural editability and resolution independence. However, this task remains challenging as it requires bridging discrete code representations with continuous visual dynamics. Existing optimization-based methods often destroy topological consistency, while general-purpose LLMs rely on rigid CSS/SMIL transformations, failing to model geometry-level non-rigid deformations. To address these limitations, we present VAnim, the first LLM-based framework for open-domain text-to-SVG animation. We reconceptualize animation not as sequence generation, but as Sparse State Updates (SSU) on a persistent SVG DOM tree. This paradigm compresses sequence length by over 9.8x while preserving the SVG DOM structure and non-participating elements by construction. To enable precise control, we propose an Identification-First Motion Planning mechanism that grounds textual instructions in explicit visual entities. Furthermore, to overcome the non-differentiable nature of SVG rendering, we employ Rendering-Aware Reinforcement Learning via Group Relative Policy Optimization (GRPO). By leveraging a hybrid reward from a state-of-the-art video perception encoder, we align discrete code updates with high-fidelity visual feedback. We also introduce SVGAnim-134k, the first benchmark for vector animation. Extensive experiments demonstrate that VAnim significantly outperforms state-of-the-art baselines in semantic alignment and structural validity, with additional appendix metrics further validating motion quality and identity preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents VAnim, an LLM-based framework for open-domain text-to-SVG animation. It reconceptualizes animation generation as Sparse State Updates (SSU) on a persistent SVG DOM tree, which compresses sequence length by over 9.8x while preserving structure and non-participating elements by construction. The approach includes Identification-First Motion Planning to ground textual instructions in visual entities and Rendering-Aware Reinforcement Learning via Group Relative Policy Optimization (GRPO) that uses a hybrid reward from a state-of-the-art video perception encoder to align discrete code updates with visual feedback. The paper introduces the SVGAnim-134k benchmark and reports that VAnim significantly outperforms state-of-the-art baselines in semantic alignment and structural validity.
Significance. If the results hold, this work could meaningfully advance controllable vector animation by preserving the editability and resolution independence of SVG while enabling non-rigid deformations beyond rigid CSS/SMIL transforms. The SSU paradigm and the new SVGAnim-134k benchmark are clear strengths that address gaps in structure preservation and evaluation. The rendering-aware RL component is a creative attempt to handle non-differentiability, though its impact depends on the fidelity of the visual reward signal.
major comments (2)
- [Rendering-Aware Reinforcement Learning via GRPO] Rendering-Aware Reinforcement Learning via GRPO section: The central performance claims rest on the hybrid reward from the raster-trained video perception encoder successfully guiding discrete SVG code updates toward geometric fidelity. Given the raster-to-vector domain gap, the manuscript should supply concrete evidence (e.g., correlation between reward values and geometric metrics such as path topology or control-point displacement) that the policy optimizes for true structural validity rather than rendering artifacts.
- [Experiments] Experiments section: The asserted outperformance in semantic alignment and structural validity requires explicit reporting of quantitative metrics, chosen baselines, error bars, and statistical tests. Without these details, it is difficult to assess whether the gains are robust or attributable to the proposed components.
minor comments (1)
- [Abstract] Abstract: Including one or two key quantitative results (e.g., specific improvement margins on the benchmark) would better substantiate the performance claims for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential of the SSU paradigm and the new benchmark. We address the two major comments below and plan to revise the manuscript to incorporate additional evidence and clarifications.
read point-by-point responses
-
Referee: Rendering-Aware Reinforcement Learning via GRPO section: The central performance claims rest on the hybrid reward from the raster-trained video perception encoder successfully guiding discrete SVG code updates toward geometric fidelity. Given the raster-to-vector domain gap, the manuscript should supply concrete evidence (e.g., correlation between reward values and geometric metrics such as path topology or control-point displacement) that the policy optimizes for true structural validity rather than rendering artifacts.
Authors: We acknowledge the referee's valid concern regarding the raster-to-vector domain gap and the need for evidence that the reward guides geometric fidelity. The manuscript describes the hybrid reward in the Rendering-Aware RL section but does not provide explicit correlation analysis with geometric metrics. To address this, we will include in the revision a quantitative study reporting correlations between the reward signals and geometric metrics like path topology and control-point displacement on the SVGAnim-134k dataset. This will demonstrate that the policy optimizes for structural aspects beyond rendering artifacts. revision: yes
-
Referee: Experiments section: The asserted outperformance in semantic alignment and structural validity requires explicit reporting of quantitative metrics, chosen baselines, error bars, and statistical tests. Without these details, it is difficult to assess whether the gains are robust or attributable to the proposed components.
Authors: We agree that explicit details are necessary for assessing the robustness of our results. While the Experiments section reports outperformance with quantitative metrics on semantic alignment and structural validity using the introduced benchmark and several baselines, we will revise to explicitly detail the metrics (e.g., specific similarity scores and validity rates), list all chosen baselines, include error bars from repeated experiments, and add statistical tests such as significance levels. These enhancements will be made in the main text and tables. revision: yes
Circularity Check
No circularity: novel framework components and experimental claims remain independent of inputs
full rationale
The paper introduces VAnim as a new reconceptualization of SVG animation as Sparse State Updates (SSU) on a persistent DOM tree, plus Identification-First Motion Planning and Rendering-Aware RL via GRPO with a hybrid video-encoder reward. The abstract explicitly states the 9.8x compression and DOM preservation occur 'by construction,' which is definitional rather than a derived prediction. No equations, self-citations as load-bearing uniqueness theorems, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the provided text. Performance claims rest on a new benchmark (SVGAnim-134k) and comparisons to external baselines, keeping the derivation self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SVG rendering is non-differentiable, so direct gradient-based optimization is impossible and RL must be used instead.
- domain assumption A state-of-the-art video perception encoder supplies a hybrid reward that aligns discrete code changes with human-perceived animation quality.
invented entities (3)
-
Sparse State Updates (SSU)
no independent evidence
-
Identification-First Motion Planning
no independent evidence
-
Rendering-Aware Reinforcement Learning via GRPO
no independent evidence
Forward citations
Cited by 3 Pith papers
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR improves automated program repair by using execution-grounded RL with a sequence-level assessor and line-level credit allocator, reaching 40.7% on SWE-bench Verified and strong cross-language results.
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR uses supervised fine-tuning on verified fixes, dual sequence- and line-level reward models from execution feedback, and PPO to reach 40.7% on SWE-bench Verified with strong cross-language results.
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR boosts automated program repair by training a sequence-level assessor and line-level credit allocator from execution outcomes, then applying them in PPO to reach 40.7% on SWE-bench Verified.
Reference graph
Works this paper leans on
-
[1]
World Wide Web Consortium , title=
-
[2]
Proceedings of the eleventh international conference on 3D web technology , pages=
Integrating web 2D and 3D technologies for architectural visualization: applications of SVG and X3D/VRML in environmental behavior simulation , author=. Proceedings of the eleventh international conference on 3D web technology , pages=
-
[3]
2005 , publisher=
Visualizing Information Using SVG and X3D: XML-based Technologies for the XML-based Web , author=. 2005 , publisher=
2005
-
[4]
科学技术与工程 , volume=
面向汉字矢量图形特征的字向量表征方法 , author=. 科学技术与工程 , volume=
-
[5]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Communications of the ACM , volume=
Generative adversarial networks , author=. Communications of the ACM , volume=. 2020 , publisher=
2020
-
[7]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 2002 , publisher=
2002
-
[8]
Design and applications , volume=
Recurrent neural networks , author=. Design and applications , volume=
-
[9]
Supervised sequence labelling with recurrent neural networks , pages=
Long short-term memory , author=. Supervised sequence labelling with recurrent neural networks , pages=. 2012 , publisher=
2012
-
[10]
3rd International Conference on Learning Representations (ICLR 2015) , year=
Very deep convolutional networks for large-scale image recognition , author=. 3rd International Conference on Learning Representations (ICLR 2015) , year=
2015
-
[11]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[12]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[13]
Visioncortex , title=
-
[14]
Potrace: a polygon-based tracing algorithm , author=
-
[15]
2008 , publisher=
The art of artificial evolution: A handbook on evolutionary art and music , author=. 2008 , publisher=
2008
-
[16]
IEEE Transactions on Visualization & Computer Graphics , volume=
ClipGen: A Deep Generative Model for Clipart Vectorization and Synthesis , author=. IEEE Transactions on Visualization & Computer Graphics , volume=. 2022 , publisher=
2022
-
[17]
Artificial Intelligence in Music, Sound, Art and Design , pages=
Modern evolution strategies for creativity: Fitting concrete images and abstract concepts , author=. Artificial Intelligence in Music, Sound, Art and Design , pages=. 2022 , organization=
2022
-
[18]
Proceedings of the 17th annual conference on Computer graphics and interactive techniques , pages=
Paint by numbers: Abstract image representations , author=. Proceedings of the 17th annual conference on Computer graphics and interactive techniques , pages=
-
[19]
Workshops on Applications of Evolutionary Computation , pages=
Genetic paint: A search for salient paintings , author=. Workshops on Applications of Evolutionary Computation , pages=. 2005 , organization=
2005
-
[20]
IEEE Transactions on Visualization and Computer Graphics , volume=
Abstract art by shape classification , author=. IEEE Transactions on Visualization and Computer Graphics , volume=. 2013 , publisher=
2013
-
[21]
Roger Johansson , title=
-
[22]
Proceedings of the 25th annual conference on Computer graphics and interactive techniques , pages=
Painterly rendering with curved brush strokes of multiple sizes , author=. Proceedings of the 25th annual conference on Computer graphics and interactive techniques , pages=
-
[23]
Evolution strategies as a scalable alternative to reinforcement learning , author=. arXiv preprint arXiv:1703.03864 , year=
-
[24]
ACM Transactions on Graphics (ToG) , volume=
Modular primitives for high-performance differentiable rendering , author=. ACM Transactions on Graphics (ToG) , volume=. 2020 , publisher=
2020
-
[25]
International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) , pages=
Paintings, polygons and plant propagation , author=. International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) , pages=. 2019 , organization=
2019
-
[26]
2022 , publisher=
Computer vision: algorithms and applications , author=. 2022 , publisher=
2022
-
[27]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[28]
Advances in neural information processing systems , volume=
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. Advances in neural information processing systems , volume=
-
[29]
International Conference on Learning Representations (ICLR) , year=
A Neural Representation of Sketch Drawings , author=. International Conference on Learning Representations (ICLR) , year=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
A learned representation for scalable vector graphics , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Deepsvg: A hierarchical generative network for vector graphics animation , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Im2vec: Synthesizing vector graphics without vector supervision , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[33]
SVGFusion: A VAE-Diffusion Transformer for Vector Graphic Generation
SVGFusion: Scalable Text-to-SVG Generation via Vector Space Diffusion , author=. arXiv preprint arXiv:2412.10437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
ACM Transactions on Graphics (TOG) , numpages=
Wang, Yizhi and Lian, Zhouhui , title=. ACM Transactions on Graphics (TOG) , numpages=
-
[35]
ACM Transactions on Graphics (TOG) , volume=
Iconshop: Text-guided vector icon synthesis with autoregressive transformers , author=. ACM Transactions on Graphics (TOG) , volume=. 2023 , publisher=
2023
-
[36]
International Conference on Machine Learning , pages=
StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[37]
ACM Transactions on Graphics (TOG) , volume=
Differentiable vector graphics rasterization for editing and learning , author=. ACM Transactions on Graphics (TOG) , volume=. 2020 , publisher=
2020
-
[38]
International Conference on Machine Learning (ICML) , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning (ICML) , pages=. 2021 , organization=
2021
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Clipascene: Scene sketching with different types and levels of abstraction , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[40]
ACM Transactions on Graphics (TOG) , volume=
Word-as-image for semantic typography , author=. ACM Transactions on Graphics (TOG) , volume=. 2023 , publisher=
2023
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Advances in Neural Information Processing Systems , volume=
Diffsketcher: Text guided vector sketch synthesis through latent diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
NIVeL: Neural Implicit Vector Layers for Text-to-Vector Generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[44]
ACM Transactions on Graphics (TOG) , volume=
Text-to-vector generation with neural path representation , author=. ACM Transactions on Graphics (TOG) , volume=. 2024 , publisher=
2024
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
SVGDreamer: Text guided svg generation with diffusion model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Svgdreamer++: Advancing editability and diversity in text-guided svg generation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[47]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Sketchagent: Language-driven sequential sketch generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Towards layer-wise image vectorization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[50]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
SAMVG: A multi-stage image vectorization model with the segment-anything model , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[51]
IEEE transactions on pattern analysis and machine intelligence , volume=
SLIC superpixels compared to state-of-the-art superpixel methods , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2012 , publisher=
2012
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Supersvg: Superpixel-based scalable vector graphics synthesis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Optimize & reduce: a top-down approach for image vectorization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[54]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Less is More: Efficient Image Vectorization with Adaptive Parameterization , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[55]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Layered image vectorization via semantic simplification , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[56]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , year =
LayerPeeler: Autoregressive Peeling for Layer-wise Image Vectorization , author =. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , year =
2025
-
[57]
arXiv preprint arXiv:2511.17454 , year=
Illustrator's Depth: Monocular Layer Index Prediction for Image Decomposition , author=. arXiv preprint arXiv:2511.17454 , year=
-
[58]
Layertracer: Cognitive-aligned layered svg synthesis via diffusion transformer , author=. arXiv preprint arXiv:2502.01105 , year=
-
[59]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Empowering llms to understand and generate complex vector graphics , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[60]
ACM Transactions on Graphics , volume=
Joint stroke tracing and correspondence for 2d animation , author=. ACM Transactions on Graphics , volume=. 2024 , publisher=
2024
-
[61]
Le and Ruslan Salakhutdinov , title =
Zihang Dai and Zhilin Yang and Yiming Yang and Jaime Carbonell and Quoc V. Le and Ruslan Salakhutdinov , title =. 2019 , note =
2019
-
[62]
CVPR , year =
Shenghai Yuan and Jinfa Huang and Xianyi He and Yunyuan Ge and Yujun Shi and Liuhan Chen and Jiebo Luo and Li Yuan , title =. CVPR , year =
-
[63]
Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution , booktitle =
Zhou,. Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution , booktitle =. 2024 , howpublished =
2024
-
[64]
Differentiable Vector Graphics Rasterization for Editing and Learning , year =
Tzu-Mao Li and Michal Luk. Differentiable Vector Graphics Rasterization for Editing and Learning , year =
-
[65]
CSS Transforms Module Level 1 , year =
-
[66]
SVG Animations , year =
-
[67]
SVG attribute: d , year =
-
[68]
Document Object Model (DOM) Specifications , year =
-
[69]
GPT-5.2 Model | OpenAI API , year =
-
[70]
Gemini 3 Pro (Vertex AI Generative AI models documentation) , year =
-
[71]
Peters and Arman Cohan , title =
Iz Beltagy and Matthew E. Peters and Arman Cohan , title =. 2020 , note =
2020
-
[72]
2024 , note =
Tiffany Tseng and Ruijia Cheng and Jeffrey Nichols , title =. 2024 , note =
2024
-
[73]
2013 , publisher =
Dan Saffer , title =. 2013 , publisher =
2013
-
[74]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Training language models to follow instructions with human feedback
Training Language Models to Follow Instructions with Human Feedback , author =. arXiv preprint arXiv:2203.02155 , year =
work page internal anchor Pith review arXiv
-
[79]
Perception Models: Powerful Models for Image, Video, and Audio Perception , year =
-
[81]
Qwen/Qwen3-VL-8B-Thinking (Model Card) , author =
-
[82]
Playwright Documentation , author =
-
[84]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations , year =
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations , year =
-
[86]
SC20: International Conference for High Performance Computing, Networking, Storage and Analysis , year =
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models , author =. SC20: International Conference for High Performance Computing, Networking, Storage and Analysis , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.