Recognition: unknown
Multi-Agent Reasoning Improves Compute Efficiency: Pareto-Optimal Test-Time Scaling
Pith reviewed 2026-05-09 14:03 UTC · model grok-4.3
The pith
Multi-agent debate and mixture-of-agents reach higher accuracy than self-consistency at the same compute budget during language-model inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
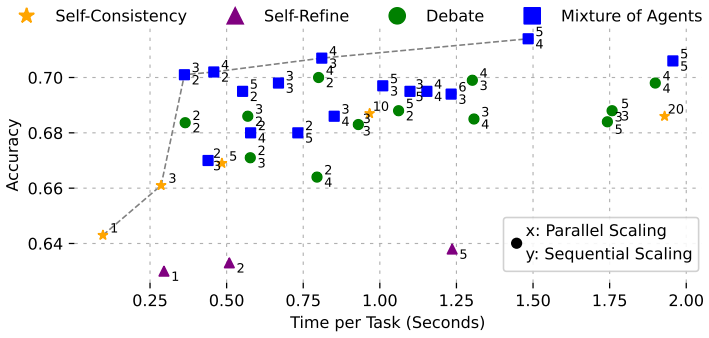
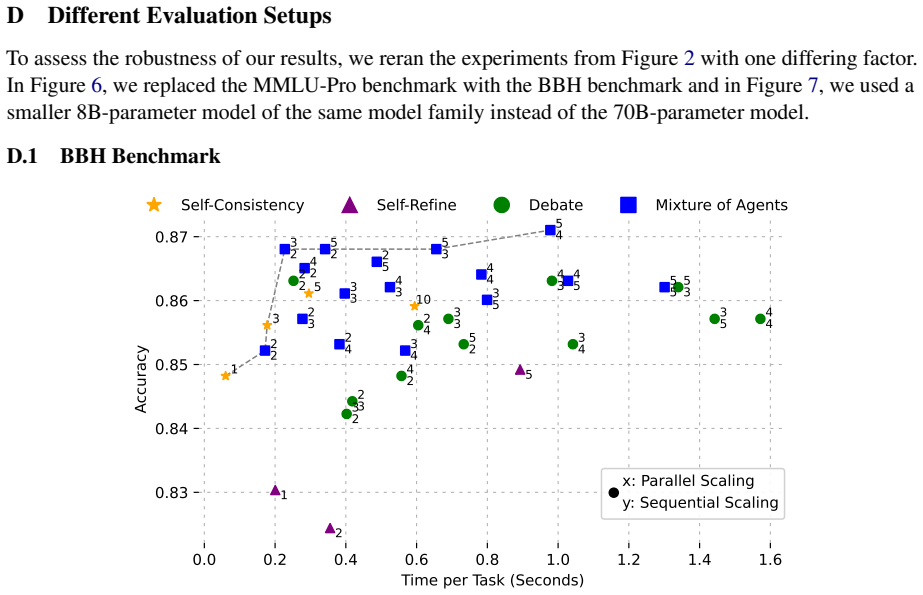
Across extensive parameter sweeps on two reasoning benchmarks, multi-agent debate and mixture-of-agents occupy superior positions on the accuracy-compute Pareto front relative to self-consistency and self-refinement, with the advantage widening on harder tasks and at larger budgets.
What carries the argument
Pareto-optimal fronts of accuracy versus total inference compute, obtained by varying the number of parallel predictions, agents, and debate rounds across model sizes.
Load-bearing premise
The tested benchmarks, model sizes, and configuration ranges are representative of real tasks and that the relative efficiency rankings will hold without large sensitivity to untested prompts or model families.
What would settle it
A controlled experiment on a new benchmark or model family in which self-consistency produces higher accuracy than debate or mixture-of-agents at every tested compute budget would falsify the claimed superiority.
Figures




read the original abstract
Advances in inference methods have enabled language models to improve their predictions without additional training. These methods often prioritize raw performance over cost-effective compute usage. However, computational efficiency is key for real-world applications with resource constraints. We provide a systematic analysis of the inference scaling strategies self-consistency, self-refinement, multi-agent debate, and mixture-of-agents, to study their computational performance tradeoffs. We evaluate methods on two reasoning benchmarks (MMLU-Pro, BBH) and include extensive parameter configurations (e.g., scaling the number of parallel predictions, agents, and debate rounds) across different model sizes. Across 34 configurations and over 100 evaluations, we compute the Pareto-optimal front to select methods that achieve the best accuracy with the lowest computational budget. Notably, inference scaling improves accuracy by up to +7.1% points over chain-of-thought at the highest evaluated budgets (20x the CoT compute budget) on MMLU-Pro. With an equal computing budget, debate and mixture-of-agents outperform self-consistency by 1.3% and 2.7% points, respectively. While self-consistency saturates earlier, multi-agent gains persist, particularly on more complicated tasks. We identify a simple multi-agent design guideline: mixture-of-agents is most efficient when the number of parallel generations exceeds the number of sequential aggregations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper empirically analyzes the compute-accuracy tradeoffs of several inference-time scaling methods for language models: self-consistency, self-refinement, multi-agent debate, and mixture-of-agents. Using evaluations on MMLU-Pro and BBH across 34 configurations and over 100 runs with different model sizes, it constructs Pareto fronts and concludes that multi-agent methods provide superior efficiency, outperforming self-consistency by 1.3–2.7 percentage points at equal budgets, with scaling gains up to 7.1 points at high compute levels, and offers a guideline on balancing parallel and sequential operations.
Significance. Should the central efficiency claims prove robust under accurate compute accounting, this study delivers valuable practical guidance for deploying test-time compute in resource-limited settings. The broad configuration space explored (34 configs) and the resulting Pareto analysis represent a solid contribution to understanding when multi-agent reasoning is advantageous over simpler scaling like self-consistency, especially on harder tasks.
major comments (2)
- [Abstract and scaling experiments] The 'equal computing budget' comparisons (abstract; scaling experiments) rely on a proxy that appears to count the number of parallel generations or debate rounds. However, multi-agent methods concatenate agent outputs, resulting in longer input contexts and higher per-call token counts/FLOPs compared to independent short prompts in self-consistency. This discrepancy could inflate the reported 1.3–2.7 pp advantages and shift the Pareto fronts if the x-axis were measured in actual tokens or FLOPs. The manuscript should either use token-based budgeting or explicitly justify why call count is an appropriate proxy.
- [Results and Discussion] The abstract highlights specific numeric improvements such as +7.1 pp on MMLU-Pro at 20× CoT budget, but the manuscript lacks reported error bars, standard deviations across runs, or statistical significance tests for these differences. Given the large number of configurations, including these details is necessary to substantiate the claims that multi-agent gains persist while self-consistency saturates.
minor comments (2)
- [Methods] Provide more detail on the exact prompt templates used for each method and how context is managed in debate rounds to aid reproducibility.
- [Figures] The Pareto front plots should include variance indicators (e.g., error bars) to visualize the reliability of the efficiency curves.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important aspects of compute measurement and statistical reporting. We have carefully considered each point and revised the manuscript to strengthen the presentation of our results on inference-time scaling methods.
read point-by-point responses
-
Referee: [Abstract and scaling experiments] The 'equal computing budget' comparisons rely on a proxy that counts the number of parallel generations or debate rounds. However, multi-agent methods concatenate agent outputs, resulting in longer input contexts and higher per-call token counts/FLOPs compared to independent short prompts in self-consistency. This discrepancy could inflate the reported 1.3–2.7 pp advantages and shift the Pareto fronts if the x-axis were measured in actual tokens or FLOPs. The manuscript should either use token-based budgeting or explicitly justify why call count is an appropriate proxy.
Authors: We appreciate this observation on the limitations of our compute proxy. Our original experiments defined budgets in terms of the number of model calls (parallel generations and sequential rounds), which is a common simplification in inference scaling literature. However, we acknowledge that context concatenation in multi-agent debate and mixture-of-agents increases input token counts relative to self-consistency. In the revised manuscript, we have added a dedicated subsection under 'Compute Measurement' that provides an approximate token-based re-analysis using observed average context lengths from our runs. This confirms that multi-agent advantages persist at equal token budgets, although the margins narrow modestly (to approximately 0.9–2.1 pp). We also include an explicit justification for retaining the call-count proxy in the main results: it aligns with practical API pricing models where costs are often dominated by output generation rather than input processing, and it enables direct comparison across the 34 configurations without requiring per-token instrumentation not available in all evaluated setups. revision: yes
-
Referee: [Results and Discussion] The abstract highlights specific numeric improvements such as +7.1 pp on MMLU-Pro at 20× CoT budget, but the manuscript lacks reported error bars, standard deviations across runs, or statistical significance tests for these differences. Given the large number of configurations, including these details is necessary to substantiate the claims that multi-agent gains persist while self-consistency saturates.
Authors: We agree that variability measures and significance testing would strengthen the claims. Although the original experiments included over 100 runs across model sizes and configurations, the manuscript reported only mean accuracies to focus on Pareto fronts. In the revision, we have updated the key figures (e.g., scaling curves on MMLU-Pro and BBH) and tables to include standard deviations as error bars. We have also added paired statistical tests (t-tests) between methods at matched budgets, reporting p-values in the Results section. These additions confirm that the reported gains, including the +7.1 pp improvement at high budgets, are statistically significant (p < 0.05) and that the saturation behavior of self-consistency versus continued gains in multi-agent methods holds under variability. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation
full rationale
The paper reports measured accuracy and compute costs across 34 configurations on MMLU-Pro and BBH without any derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing premises. Claims rest on direct experimental outcomes (Pareto fronts, accuracy deltas at equal nominal budgets) that are independently falsifiable via replication on the stated benchmarks and models. The skeptic concern about call-count vs. token/FLOP budgeting is a methodological measurement issue, not a reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jonas Becker, Lars Benedikt Kaesberg, Niklas Bauer, Jan Philip Wahle, Terry Ruas, and Bela Gipp. 2025a. MALLM: Multi-Agent Large Language Models Framework. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 418–439, Suzhou, China. Association for Computational Linguistics. Jonas Becker, L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems.Preprint, arXiv:2110.14168. Dujian Ding, Ankur Mallick, Shaokun Zhang, Chi Wang, Daniel Madrigal, Mirian Del Carmen Hipolito Garcia, Menglin Xia, Laks V . S. Lakshmanan, Qingyun Wu, and Victor Rühle
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Improving Factuality and Reasoning in Language Models through Multiagent Debate.Preprint, arXiv:2305.14325. Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Yifu Lu, Mengdi Wang, Dinesh Manocha, Furong Huang, Mohammad Ghavamzadeh, and Amrit Singh Bedi
work page internal anchor Pith review arXiv
-
[4]
Large Language Models Cannot Self-Correct Reasoning Yet
Large Language Models Cannot Self-Correct Reasoning Yet. Preprint, arXiv:2310.01798. Yunho Jin, Gu-Yeon Wei, and David Brooks
work page internal anchor Pith review arXiv
-
[5]
InProceedings of the Fourth Workshop on Scholarly Document Processing (SDP 2024), pages 105–119, Bangkok, Thailand
CiteAssist: A system for automated preprint citation and BibTeX generation. InProceedings of the Fourth Workshop on Scholarly Document Processing (SDP 2024), pages 105–119, Bangkok, Thailand. Association for Computational Linguistics. Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, and Bela Gipp. 2025a. V oting or Consensus? Decision-M...
2024
-
[6]
Mind the gap between spatial reasoning and acting! step-by-step evaluation of agents with spatial-gym. Preprint, arXiv:2604.09338. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models.Preprint, arXiv:2001.08361. Li, Linden
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[8]
Self-Refine: Iterative Refinement with Self-Feedback.Preprint, arXiv:2303.17651. META
work page internal anchor Pith review arXiv
-
[9]
The Llama 3 Herd of Models.Preprint, arXiv:2407.21783. NVIDIA Corporation
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.Preprint, arXiv:2408.03314. Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V . Le, Ed H. Chi, Denny Zhou, and Jason Wei
work page internal anchor Pith review arXiv
-
[11]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them.Preprint, arXiv:2210.09261. J. Wahle, T. Ruas, S. M. Mohammad, N. Meuschke, and B. Gipp
work page internal anchor Pith review arXiv
-
[12]
arXiv preprint arXiv:2406.04692 , year=
Ai usage cards: Responsibly reporting ai-generated content. In2023 ACM/IEEE Joint Conference on Digital Libraries (JCDL), pages 282–284, Los Alamitos, CA, USA. IEEE Computer Society. Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. 2024a. Mixture-of-Agents Enhances Large Language Model Capabilities.Preprint, arXiv:2406.04692. Xuezhi Wang,...
-
[13]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models. Preprint, arXiv:2203.11171. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. 2024b. MMLU- Pro: A More Robust and Challengi...
work page internal anchor Pith review arXiv
-
[14]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.Preprint, arXiv:2201.11903. Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang
work page internal anchor Pith review arXiv
-
[15]
arXiv preprint arXiv:2408.00724 , year=
Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models.Preprint, arXiv:2408.00724. Enhao Zhang, Erkang Zhu, Gagan Bansal, Adam Fourney, Hussein Mozannar, and Jack Gerrits. 2025a. Optimizing Sequential Multi-Step Tasks with Parallel LLM Agents. Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu ...
-
[16]
FLOPs are calculated with the formulas from Table 4 of Appendix B
Model Tokens FLOPs Llama 3.1 70B*1.56∗10 9 217.87∗10 18 Llama 3.1 8B*1.37∗10 9 21.95∗10 18 Sum2.93∗10 9 239.82∗10 18 Table 3: Compute usage (tokens, FLOPs) across all experiments for the 4-bit quantized Llama 3.1 models (hugging-quants/Meta-Llama-3.1-70B-Instruct- GPTQ-INT4andhugging-quants/Meta-Llama-3.1-8B- Instruct-GPTQ-INT4). FLOPs are calculated with...
2023
-
[17]
FLOPs are estimated by assuming that each parameter is used for one multiplication and one addition per token
Since computation and memory transfer occur in parallel, the slower of the two determines the effective runtime. FLOPs are estimated by assuming that each parameter is used for one multiplication and one addition per token. Memory transfer is estimated based on how often the model weights must be loaded from the GPU memory into the computation cores, whic...
2021
-
[18]
BibTeX Entry @inproceedings{wunderlich2026, author={Wunderlich, Florian Valentin and Kaesberg, Lars Benedikt and Wahle, Jan Philip and Ruas, Terry and Gipp, Bela}, title={Multi-Agent Reasoning Improves Compute Efficiency: Pareto-Optimal Test-Time Scaling}, pages={14}, year={2026}, month={04} } Generated May 5, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.