Recognition: unknown
Neural Equalisers for Highly Compressed Faster-than-Nyquist Signalling: Design, Performance, Complexity and Robustness
Pith reviewed 2026-05-09 17:38 UTC · model grok-4.3
The pith
Deep learning receivers enable reliable detection in Faster-than-Nyquist systems compressed by up to 75 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A deep-learning framework for FTN signalling, built around a sliding-window detector, delivers reliable symbol recovery even under aggressive spectral compression up to 75 percent; the architecture is tuned for low latency and low complexity and maintains accuracy across varying channel conditions and noise profiles.
What carries the argument
The sliding-window detection method inside deep-learning receivers, which supplies limited temporal context to mitigate the controlled intersymbol interference that FTN deliberately introduces.
If this is right
- FTN systems become viable at packing factors that achieve 75 percent spectral compression without catastrophic error rates.
- Low-latency, low-complexity neural receivers make FTN suitable for real-time, scalable deployments.
- The models exhibit resilience to changes in noise profiles and channel conditions within the tested range.
- Aggressive FTN no longer requires high-complexity traditional equalizers to remain practical.
Where Pith is reading between the lines
- The same sliding-window neural structure might be applied to other controlled-interference schemes that exceed classical Nyquist limits.
- Hardware deployment would likely require retraining or adaptation steps to capture impairments absent from the simulation environment.
- If robustness holds, FTN could increase throughput in spectrum-constrained links such as satellite or dense urban wireless channels.
Load-bearing premise
That detection performance measured under simulated channel and noise conditions will continue to hold when the same networks encounter unmodeled hardware distortions and time-varying propagation effects.
What would settle it
Bit-error-rate measurements of the trained neural equalizers on real RF hardware transmitting FTN waveforms under measured multipath and hardware impairments, compared directly against the simulated results reported in the paper.
Figures

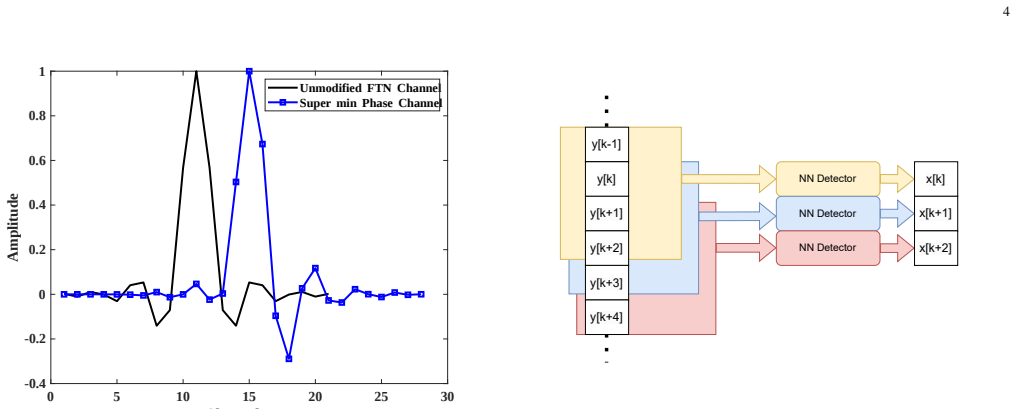
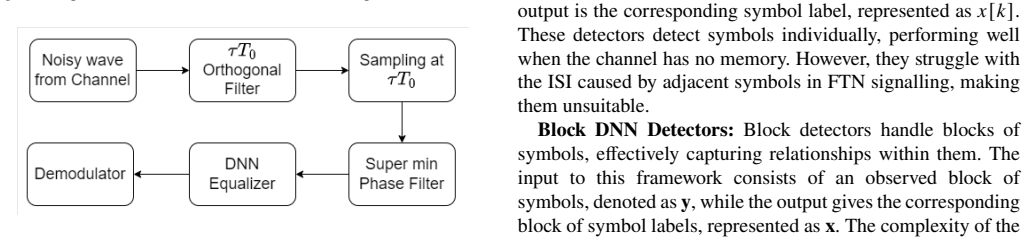






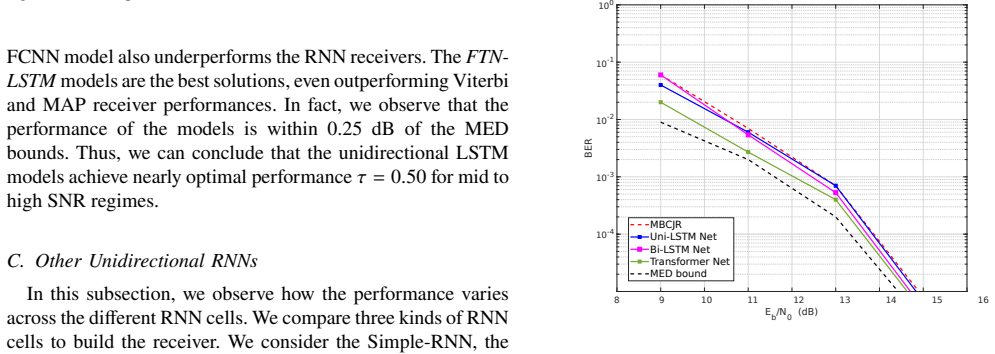






read the original abstract
Faster-than-Nyquist (FTN) signalling has emerged as a compelling technique for enhancing spectral efficiency in bandwidth-constrained communication systems. By intentionally introducing controlled intersymbol interference (ISI), FTN allows transmission at rates exceeding the traditional Nyquist limit, unlocking new potential in high-speed data communication. However, its practical deployment remains challenged by the need for low-complexity detection strategies that can cope with the induced ISI while maintaining low latency and robust performance. We propose deep learning receivers that are resilient to non-idealities. In this paper, we present a deep learning-based framework for FTN signalling that addresses these challenges through several novel contributions. First, we propose a sliding window detection method that leverages temporal context while preserving computational efficiency. Second, we demonstrate the viability of FTN systems with very low packing factors, showing that reliable performance can be achieved even under aggressive spectral compression (up to 75\%). Our architecture is optimised for low latency and low complexity, making it suitable for real-time applications and scalable deployment. In addition, we assess the robustness of our models across varying channel conditions and noise profiles, providing insights into their generalisability and resilience.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a deep learning framework for detection in Faster-than-Nyquist (FTN) signalling, featuring a sliding-window neural equalizer architecture. It claims to demonstrate reliable performance at very low packing factors (corresponding to up to 75% spectral compression), with optimizations for low latency and complexity, plus an assessment of robustness across simulated channel conditions and noise profiles.
Significance. If the empirical results hold under the stated conditions, the work could meaningfully advance practical FTN deployment by showing that neural equalizers can handle aggressive ISI at packing factors down to 0.25 while remaining computationally tractable. The focus on sliding-window processing and robustness evaluation addresses real barriers to FTN adoption in bandwidth-constrained systems.
major comments (2)
- [Abstract and robustness section] Abstract and robustness assessment: the central claim that 'reliable performance can be achieved even under aggressive spectral compression (up to 75%)' rests on Monte Carlo simulations over AWGN or static multipath with fixed noise statistics and perfect synchronization. No injection of phase noise, I/Q imbalance, amplifier nonlinearity, or Doppler spread is described, so the reported error rates do not yet substantiate viability under the hardware impairments and time-varying environments that would alter the effective ISI pattern.
- [Abstract and results] Performance evaluation: the abstract states performance and robustness claims but supplies no quantitative BER curves, baseline comparisons against conventional equalizers (e.g., BCJR or MMSE), error bars, or training hyper-parameter details. Without these, the viability demonstration at packing factor 0.25 cannot be verified or reproduced.
minor comments (2)
- [Design section] The sliding-window method is introduced but the manuscript should explicitly state how window size is selected, its latency-complexity trade-off, and any ablation on window length.
- [Throughout] Notation for packing factor and compression ratio should be defined once at first use and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the scope and presentation of our results. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract and robustness section] Abstract and robustness assessment: the central claim that 'reliable performance can be achieved even under aggressive spectral compression (up to 75%)' rests on Monte Carlo simulations over AWGN or static multipath with fixed noise statistics and perfect synchronization. No injection of phase noise, I/Q imbalance, amplifier nonlinearity, or Doppler spread is described, so the reported error rates do not yet substantiate viability under the hardware impairments and time-varying environments that would alter the effective ISI pattern.
Authors: We appreciate the referee highlighting the boundaries of the evaluated conditions. The manuscript reports robustness results under AWGN and static multipath channels with varying noise profiles and perfect synchronization, as described in the robustness assessment section. We agree that phase noise, I/Q imbalance, amplifier nonlinearity, and Doppler spread were not injected into the simulations. We will revise the abstract to state the evaluated conditions more precisely and add a short paragraph in the robustness section acknowledging these unmodeled impairments as a limitation, together with a note that they constitute important directions for future work. revision: partial
-
Referee: [Abstract and results] Performance evaluation: the abstract states performance and robustness claims but supplies no quantitative BER curves, baseline comparisons against conventional equalizers (e.g., BCJR or MMSE), error bars, or training hyper-parameter details. Without these, the viability demonstration at packing factor 0.25 cannot be verified or reproduced.
Authors: The body of the manuscript contains the requested quantitative elements: BER curves at packing factors down to 0.25, direct comparisons against BCJR and MMSE equalizers, Monte-Carlo error bars, and full training hyper-parameter tables in the experimental setup and results sections. To improve accessibility, we will revise the abstract to include a concise statement of key quantitative outcomes (e.g., achieved BER at packing factor 0.25) and explicit reference to the baseline comparisons. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes neural equalizer architectures for FTN signalling and reports simulation results for performance, complexity, and robustness under AWGN and static multipath channels. No equations, uniqueness theorems, or predictions are presented that reduce by construction to fitted inputs, self-citations, or ansatzes from prior author work. Claims of viability at low packing factors rest on empirical Monte Carlo assessments of the proposed models rather than any self-referential derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On ”sampling, data transmission, and the nyquist rate
D. Tufts, “On ”sampling, data transmission, and the nyquist rate” and adaptive communication using randomly time-varying channels,” Proceedings of the IEEE, vol. 56, no. 5, pp. 889–889, 1968
1968
-
[2]
Exploiting faster-than-nyquist signaling,
A. Liveris and C. Georghiades, “Exploiting faster-than-nyquist signaling,” IEEE Transactions on Communications, vol. 51, no. 9, pp. 1502–1511, 2003
2003
-
[3]
Faster-than-nyquist signaling,
J. E. Mazo, “Faster-than-nyquist signaling,”The Bell System Technical Journal, vol. 54, no. 8, pp. 1451–1462, 1975
1975
-
[4]
On the minimum distance problem for faster-than-nyquist signaling,
J. Mazo and H. Landau, “On the minimum distance problem for faster-than-nyquist signaling,”IEEE Transactions on Information Theory, vol. 34, no. 6, pp. 1420–1427, 1988
1988
-
[5]
On computing the minimum distance for faster than nyquist signaling,
D. Hajela, “On computing the minimum distance for faster than nyquist signaling,”IEEE Transactions on Information Theory, vol. 36, no. 2, pp. 289–295, 1990
1990
-
[6]
Frequency-domain equalization of faster-than-nyquist signal- ing,
S. Sugiura, “Frequency-domain equalization of faster-than-nyquist signal- ing,”IEEE Wireless Communications Letters, vol. 2, no. 5, pp. 555–558, 2013
2013
-
[7]
Svd-precoded faster-than-nyquist signaling with optimal and truncated power allocation,
T. Ishihara and S. Sugiura, “Svd-precoded faster-than-nyquist signaling with optimal and truncated power allocation,”IEEE Transactions on Wireless Communications, vol. 18, no. 12, pp. 5909–5923, 2019
2019
-
[8]
Receivers for faster-than- nyquist signaling with and without turbo equalization,
A. Prlja, J. B. Anderson, and F. Rusek, “Receivers for faster-than- nyquist signaling with and without turbo equalization,” in2008 IEEE International Symposium on Information Theory, 2008, pp. 464–468
2008
-
[9]
Reduced-complexity receivers for strongly narrowband intersymbol interference introduced by faster-than-nyquist signaling,
A. Prlja and J. B. Anderson, “Reduced-complexity receivers for strongly narrowband intersymbol interference introduced by faster-than-nyquist signaling,”IEEE Transactions on Communications, vol. 60, no. 9, pp. 2591–2601, 2012
2012
-
[10]
Turbo equalization and an m-bcjr algorithm for strongly narrowband intersymbol interference,
J. B. Anderson and A. Prlja, “Turbo equalization and an m-bcjr algorithm for strongly narrowband intersymbol interference,” in2010 International Symposium On Information Theory and Its Applications, 2010, pp. 261– 266
2010
-
[11]
Faster-than-nyquist signaling,
J. B. Anderson, F. Rusek, and V. ¨Owall, “Faster-than-nyquist signaling,” Proceedings of the IEEE, vol. 101, no. 8, pp. 1817–1830, 2013
2013
-
[12]
Pre-equalized faster-than- nyquist transmission,
M. Jana, A. Medra, L. Lampe, and J. Mitra, “Pre-equalized faster-than- nyquist transmission,”IEEE Transactions on Communications, vol. 65, no. 10, pp. 4406–4418, 2017
2017
-
[13]
Faster-than- nyquist signaling: An overview,
J. Fan, S. Guo, X. Zhou, Y. Ren, G. Y. Li, and X. Chen, “Faster-than- nyquist signaling: An overview,”IEEE Access, vol. 5, pp. 1925–1940, 2017
1925
-
[14]
Eigendecomposition-precoded faster-than-nyquist signaling with index modulation,
P. Chaki, T. Ishihara, and S. Sugiura, “Eigendecomposition-precoded faster-than-nyquist signaling with index modulation,”IEEE Transactions on Communications, vol. 70, no. 7, pp. 4822–4836, 2022
2022
-
[15]
Optimal decoding of linear codes for minimizing symbol error rate (corresp.),
L. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding of linear codes for minimizing symbol error rate (corresp.),”IEEE Transactions on Information Theory, vol. 20, no. 2, pp. 284–287, 1974
1974
-
[16]
Deep-learning based equal- ization of highly compressed faster than nyquist signals,
S. Paul, N. Seshadri, and R. D. Koilpillai, “Deep-learning based equal- ization of highly compressed faster than nyquist signals,” in2023 IEEE International Conference on Advanced Networks and Telecommunica- tions Systems (ANTS), 2023, pp. 396–401
2023
-
[17]
Learning to communicate and energize: Modulation, coding, and multiple access designs for wireless information-power transmission,
M. Varasteh, J. Hoydis, and B. Clerckx, “Learning to communicate and energize: Modulation, coding, and multiple access designs for wireless information-power transmission,”IEEE Transactions on Communica- tions, vol. 68, no. 11, pp. 6822–6839, 2020
2020
-
[18]
An introduction to deep learning for the physical layer,
T. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer,”IEEE Transactions on Cognitive Communications and Networking, vol. 3, no. 4, pp. 563–575, 2017
2017
-
[19]
Joint learning of geometric and probabilistic constellation shaping,
M. Stark, F. Ait Aoudia, and J. Hoydis, “Joint learning of geometric and probabilistic constellation shaping,” in2019 IEEE Globecom Workshops (GC Wkshps), 2019, pp. 1–6
2019
-
[20]
Backpropagating through the air: Deep learning at physical layer without channel models,
V. Raj and S. Kalyani, “Backpropagating through the air: Deep learning at physical layer without channel models,”IEEE Communications Letters, vol. 22, no. 11, pp. 2278–2281, 2018
2018
-
[21]
One-bit ofdm receivers via deep learning,
E. Balevi and J. G. Andrews, “One-bit ofdm receivers via deep learning,” IEEE Transactions on Communications, vol. 67, no. 6, pp. 4326–4336, 2019
2019
-
[22]
Deep learning based symbol detection for molecular communications,
S. Sharma, D. Dixit, and K. Deka, “Deep learning based symbol detection for molecular communications,” in2020 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), 2020, pp. 1–6
2020
-
[23]
Viterbinet: A deep learning based viterbi algorithm for symbol detection,
N. Shlezinger, N. Farsad, Y. C. Eldar, and A. J. Goldsmith, “Viterbinet: A deep learning based viterbi algorithm for symbol detection,”IEEE Transactions on Wireless Communications, vol. 19, no. 5, pp. 3319–3331, 2020
2020
-
[24]
Neural network detection of data sequences in communication systems,
N. Farsad and A. Goldsmith, “Neural network detection of data sequences in communication systems,”IEEE Transactions on Signal Processing, vol. 66, no. 21, pp. 5663–5678, 2018
2018
-
[25]
Interference cancellation technique for faster-than-nyquist signalling,
S. Nie, M. Guo, and Y. Shen, “Interference cancellation technique for faster-than-nyquist signalling,”Electronics Letters, vol. 52, no. 13, pp. 1126–1128, 2016
2016
-
[26]
A very low complexity successive symbol-by-symbol sequence estimator for faster-than-nyquist signaling,
E. Bedeer, M. H. Ahmed, and H. Yanikomeroglu, “A very low complexity successive symbol-by-symbol sequence estimator for faster-than-nyquist signaling,”IEEE Access, vol. 5, pp. 7414–7422, 2017
2017
-
[27]
Low complexity message passing receiver for faster-than-nyquist signaling in nonlinear channels,
X. Wen, W. Yuan, D. Yang, N. Wu, and J. Kuang, “Low complexity message passing receiver for faster-than-nyquist signaling in nonlinear channels,”IEEE Access, vol. 6, pp. 68 233–68 241, 2018
2018
-
[28]
Joint precoding and pre-equalization for faster-than-nyquist transmission over multipath fading channels,
S. Wen, G. Liu, C. Liu, H. Qu, L. Zhang, and M. A. Imran, “Joint precoding and pre-equalization for faster-than-nyquist transmission over multipath fading channels,”IEEE Transactions on Vehicular Technology, vol. 71, no. 4, pp. 3948–3963, 2022
2022
-
[29]
Receiver design for faster- than-nyquist signaling: Deep-learning-based architectures,
P. Song, F. Gong, Q. Li, G. Li, and H. Ding, “Receiver design for faster- than-nyquist signaling: Deep-learning-based architectures,”IEEE Access, vol. 8, pp. 68 866–68 873, 2020
2020
-
[30]
Deep learning-based list sphere decoding for faster-than-nyquist (ftn) signaling detection,
A. Sina and E. Bedeer, “Deep learning-based list sphere decoding for faster-than-nyquist (ftn) signaling detection,” in2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), 2022, pp. 1–6
2022
-
[31]
A novel sum-product detection algorithm for faster-than-nyquist signaling: A deep learning approach,
B. Liu, S. Li, Y. Xie, and J. Yuan, “A novel sum-product detection algorithm for faster-than-nyquist signaling: A deep learning approach,” IEEE Transactions on Communications, vol. 69, no. 9, pp. 5975–5987, 2021
2021
-
[32]
Mhsa-cnn-bi- lstm based interference cancellation algorithm for mimo-ftn-owc system,
Q. Yang, M. Cao, G. Zhou, Y. Zhang, R. Yao, and H. Wang, “Mhsa-cnn-bi- lstm based interference cancellation algorithm for mimo-ftn-owc system,” in2024 IEEE 16th International Conference on Advanced Infocomm Technology (ICAIT), 2024, pp. 1–5
2024
-
[33]
Ftn-based non- orthogonal signal detection technique with machine learning in quasi- static multipath channel,
M.-S. Baek, E.-S. Jung, Y. S. Park, and Y.-T. Lee, “Ftn-based non- orthogonal signal detection technique with machine learning in quasi- static multipath channel,”IEEE Transactions on Broadcasting, vol. 70, no. 1, pp. 78–86, 2024
2024
-
[34]
Cyclic prefix/suffix-assisted frequency-domain equalization for faster-than-nyquist signaling block transmission,
S.-B. Hong and J.-S. Seo, “Cyclic prefix/suffix-assisted frequency-domain equalization for faster-than-nyquist signaling block transmission,” in2016 IEEE 27th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), 2016, pp. 1–6
2016
-
[35]
For security and higher spectrum efficiency: A variable packing ratio transmission system based on faster-than-nyquist and deep learning,
P. Song, N. Zhang, L. Cai, G. Li, T. Wu, and F.-K. Gong, “For security and higher spectrum efficiency: A variable packing ratio transmission system based on faster-than-nyquist and deep learning,”IEEE Transactions on Wireless Communications, vol. 22, no. 9, pp. 5898–5913, 2023
2023
-
[36]
A mimo detec- tor utilizing dnn for faster-than-nyquist optical wireless communications,
M. Cao, R. Yao, Q. Sun, Y. Zhang, Q. Yang, and H. Wang, “A mimo detec- tor utilizing dnn for faster-than-nyquist optical wireless communications,” in2023 IEEE 15th International Conference on Advanced Infocomm Technology (ICAIT), 2023, pp. 27–30
2023
-
[37]
A mimo detector with deep-neural-network for faster-than-nyquist optical wireless communications,
——, “A mimo detector with deep-neural-network for faster-than-nyquist optical wireless communications,”IEEE Photonics Journal, vol. 16, no. 2, pp. 1–9, 2024
2024
-
[38]
Deep learning assisted pre-equalization scheme for faster-than- nyquist optical wireless communications,
C. Minghua, W. Zhaoheng, W. Huiqin, X. Jieping, Z. Jiawei, and L. Wen- wen, “Deep learning assisted pre-equalization scheme for faster-than- nyquist optical wireless communications,” in2021 13th International Conference on Advanced Infocomm Technology (ICAIT), 2021, pp. 118– 121
2021
-
[39]
The evolution of faster-than-nyquist signaling,
T. Ishihara, S. Sugiura, and L. Hanzo, “The evolution of faster-than-nyquist signaling,”IEEE Access, vol. 9, pp. 86 535–86 564, 2021. 14
2021
-
[40]
Reduced Receivers for Faster-than-Nyquist Signaling and General Linear Channels,
Prlja, Adnan, “Reduced Receivers for Faster-than-Nyquist Signaling and General Linear Channels,” Ph.D. dissertation, Lund University, 2013. [Online]. Available:{https://lup.lub.lu.se/search/files/3525903/3447172. pdf}
-
[41]
Sliding bidirectional recurrent neural net- works for sequence detection in communication systems,
N. Farsad and A. Goldsmith, “Sliding bidirectional recurrent neural net- works for sequence detection in communication systems,” in2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 2331–2335
2018
-
[42]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” inAdvances in Neural Information Processing Systems, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, Eds., vol. 25. Curran Associates, Inc., 2012. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2012/file/c399862d3b...
2012
-
[43]
Learning mid-level features for recognition,
Y.-L. Boureau, F. Bach, Y. LeCun, and J. Ponce, “Learning mid-level features for recognition,” in2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2010, pp. 2559–2566
2010
-
[44]
Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury, “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,”IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82–97, 2012
2012
-
[45]
Deep learning,
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,”nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[46]
Ian goodfellow, yoshua bengio, and aaron courville: Deep learning: The mit press, 2016, 800 pp, isbn: 0262035618,
J. Heaton, “Ian goodfellow, yoshua bengio, and aaron courville: Deep learning: The mit press, 2016, 800 pp, isbn: 0262035618,”Genetic programming and evolvable machines, vol. 19, no. 1, pp. 305–307, 2018
2016
-
[47]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,”arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review arXiv 2014
-
[48]
Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainathet al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,”IEEE Signal processing magazine, vol. 29, no. 6, pp. 82–97, 2012
2012
-
[49]
Delayed decision-feedback sequence estimation,
A. Duel-Hallen and C. Heegard, “Delayed decision-feedback sequence estimation,”IEEE Transactions on Communications, vol. 37, no. 5, pp. 428–436, 1989
1989
-
[50]
Decision feedback equalization,
C. Belfiore and J. Park, “Decision feedback equalization,”Proceedings of the IEEE, vol. 67, no. 8, pp. 1143–1156, 1979
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.