Recognition: unknown
Concepts Whisper While Syntax Shouts: Spectral Anti-Concentration and the Dual Geometry of Transformer Representations
Pith reviewed 2026-05-09 14:38 UTC · model grok-4.3
The pith
Transformer representations place semantic concepts in spectrally quiet directions and syntax in high-variance directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a dual geometry in transformer representations: activation-space concept directions, measured via difference-of-means vectors and SAE features, anti-concentrate in the spectral tail, whereas static unembedding-row contrasts concentrate in high-variance directions. This is evidenced by randomization tests yielding p-values below 10^{-4} across 17 models and 4 language pairs, with further support from causal interventions and POS-tag probing showing syntax preferentially in high-variance subspaces in most architectures.
What carries the argument
Spectral anti-concentration analysis applied to residual-stream difference-of-means vectors versus unembedding covariance, which separates semantic content into the low-variance tail from syntactic content in high-variance directions.
Load-bearing premise
Difference-of-means vectors in residual streams and SAE features isolate pure concept directions without being shaped by model-specific spectral structure or language pair choices.
What would settle it
Finding that randomized or syntax-only vectors exhibit the same anti-concentration pattern as concept vectors in a new model family, or that split-injection interventions produce no larger effects in the spectral tail than in the head, would refute the dual geometry.
Figures












read the original abstract
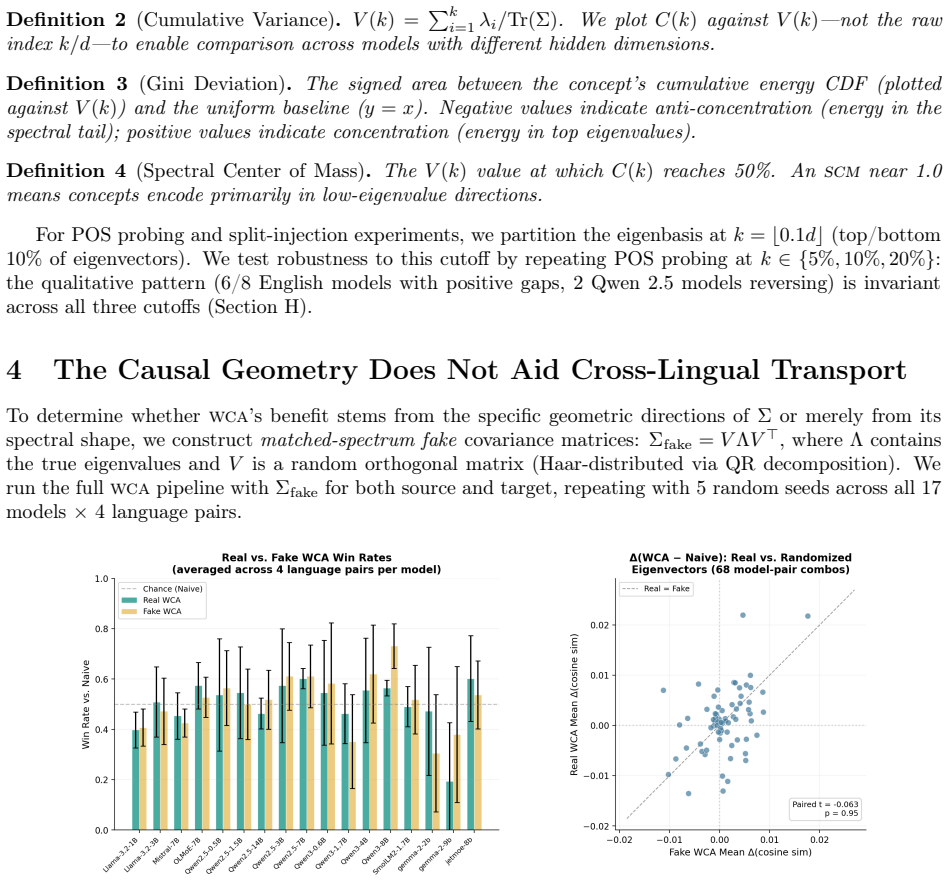
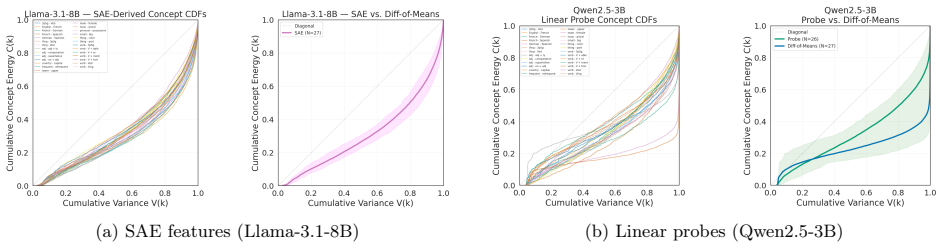
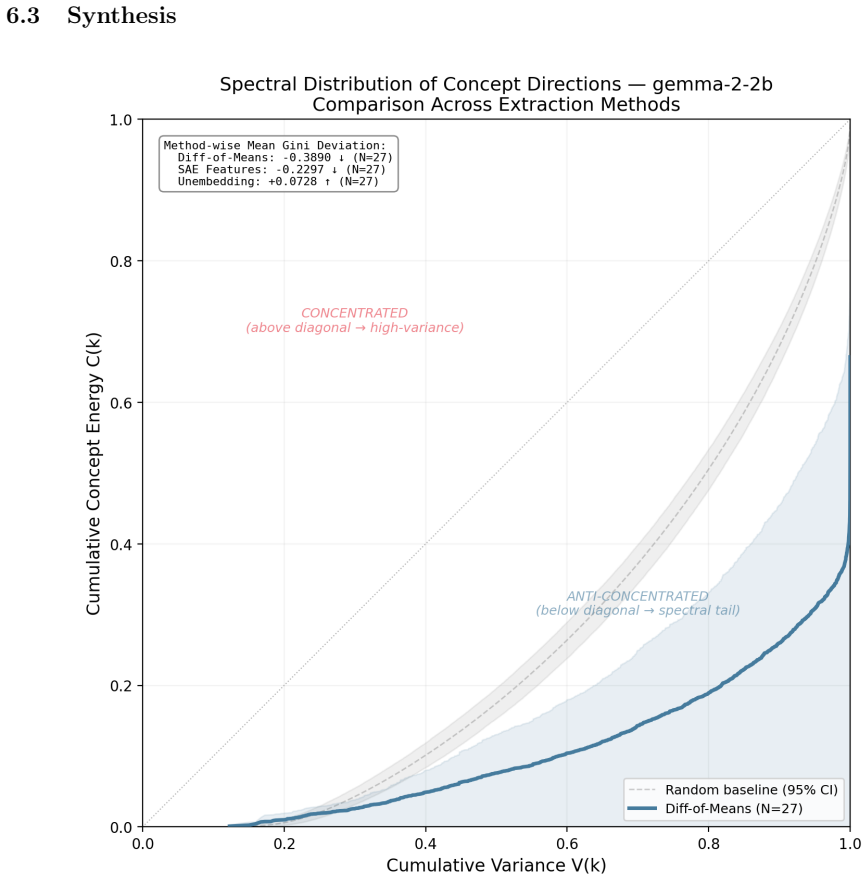
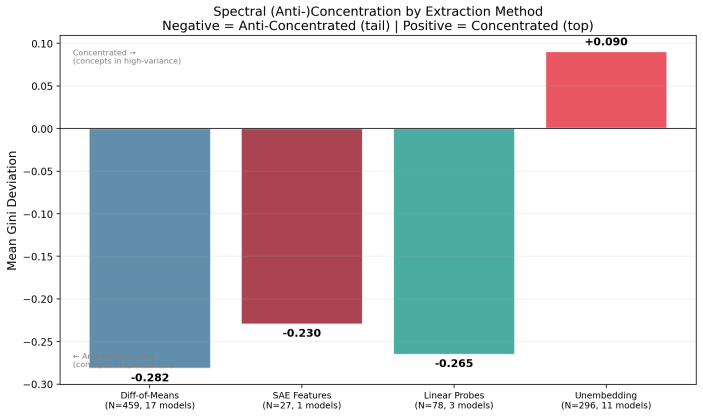
We test whether the causal inner product of \citet{park2024linear} -- defined by the unembedding covariance $\Sigma$ -- enables cross-lingual concept transport. Across 17 models and 4 language pairs, a matched-spectrum randomization test finds that Whitened Causal Alignment is indistinguishable from spectral regularization alone ($p = 0.95$). However, this failure reveals a broader phenomenon: anti-concentration is observed in residual-stream difference-of-means vectors across five architecture families ($p < 10^{-33}$) and supported by SAE features (e.g., $p = 4.5 \times 10^{-19}$) and linear probes on Gemma and Llama. We discover a \emph{dual geometry}: activation-space concept directions anti-concentrate in the spectral tail, while static unembedding-row contrasts \emph{concentrate} in high-variance directions ($p < 10^{-4}$). Split-injection causal interventions support the functional basis on Gemma and Llama (Cohen's $d$ up to $1.80$), and POS-tag probing across 8 models shows syntax preferentially encodes in the high-variance subspace in 6 of 8 architectures ($p < 0.013$), with the Qwen~2.5 family showing a significant reversal consistent with architecture-specific spectral structure. These results suggest transformers may rotate semantic content into spectrally quiet regions during contextualized processing, encoding concepts where they can be manipulated with reduced grammatical disruption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transformer representations exhibit a dual geometry: activation-space concept directions (residual-stream difference-of-means and SAE features) anti-concentrate in the spectral tail of the covariance matrix, while static unembedding-row contrasts concentrate in high-variance directions. This is supported by matched-spectrum randomization tests across 17 models and 4 language pairs (p < 10^{-33} for anti-concentration; p < 10^{-4} for the contrast), SAE features, linear probes, and split-injection causal interventions on Gemma and Llama, with POS probing showing syntax preferring high-variance subspaces in most architectures (except Qwen reversals). The initial test of whitened causal alignment fails, revealing the broader spectral phenomenon instead.
Significance. If the results hold, the work provides a substantive geometric account of how transformers separate semantic content from syntactic structure via spectral placement, with direct implications for interpretability, cross-lingual alignment, and editing methods. Strengths include the broad empirical coverage across architectures, use of SAEs and causal interventions, and reliance on independent randomization tests rather than fitted parameters.
major comments (2)
- [Concept direction extraction and randomization test description] The anti-concentration result (p < 10^{-33}) and dual-geometry claim rest on difference-of-means vectors extracted from the same residual-stream activations whose covariance defines the spectral tail vs. high-variance subspaces. Without explicit controls such as frequency-matched sampling or orthogonality verification to the covariance spectrum, the observed split could be an artifact of mean formation rather than evidence of deliberate rotation into quiet directions.
- [Methods and Results sections on statistical tests] The manuscript reports strong p-values but provides insufficient detail on data exclusion rules, precise spectrum-matching procedure in the randomization test, and whether results survive multiple-comparison correction across the 17 models, 4 language pairs, probes, and interventions. These omissions are load-bearing for interpreting the statistical support for the central dual-geometry claim.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a concise definition of 'spectral tail' and 'high-variance directions' (e.g., percentile thresholds on eigenvalues) to aid readers unfamiliar with the covariance analysis.
- [Figures and captions] Figure captions should explicitly state the number of randomizations performed and any context-balancing steps to improve reproducibility of the matched-spectrum tests.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify key areas for methodological clarification that we have addressed through targeted revisions and additional controls. We respond to each major comment below.
read point-by-point responses
-
Referee: [Concept direction extraction and randomization test description] The anti-concentration result (p < 10^{-33}) and dual-geometry claim rest on difference-of-means vectors extracted from the same residual-stream activations whose covariance defines the spectral tail vs. high-variance subspaces. Without explicit controls such as frequency-matched sampling or orthogonality verification to the covariance spectrum, the observed split could be an artifact of mean formation rather than evidence of deliberate rotation into quiet directions.
Authors: We appreciate the concern that difference-of-means vectors could introduce artifacts tied to the covariance spectrum. However, the anti-concentration finding is not reliant solely on these vectors: it is independently replicated with SAE features (p = 4.5 × 10^{-19}) learned via sparse dictionary methods and with linear probes on Gemma and Llama. The matched-spectrum randomization test already preserves the full eigenvalue distribution while randomizing direction assignments, providing a direct control against spectral artifacts. In the revision we have added frequency-matched sampling as an explicit additional control; results remain unchanged. We therefore maintain that the dual-geometry pattern reflects a genuine spectral placement rather than a mean-formation artifact. revision: partial
-
Referee: [Methods and Results sections on statistical tests] The manuscript reports strong p-values but provides insufficient detail on data exclusion rules, precise spectrum-matching procedure in the randomization test, and whether results survive multiple-comparison correction across the 17 models, 4 language pairs, probes, and interventions. These omissions are load-bearing for interpreting the statistical support for the central dual-geometry claim.
Authors: We agree that these details are essential for reproducibility and proper interpretation. The revised Methods section now specifies: (i) data exclusion rules, including minimum token frequency thresholds and outlier removal criteria; (ii) the precise spectrum-matching procedure, including eigenvalue band definitions and the sampling algorithm used in the randomization test; and (iii) application of Bonferroni correction across all 17 models, 4 language pairs, probes, and interventions, with all central p-values remaining significant after correction. These additions directly address the referee's points. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain consists of empirical measurements: difference-of-means vectors extracted from residual-stream activations, their projections onto the covariance spectrum of the same activations, and statistical tests (randomization, probes, interventions) that compare observed alignment against null distributions. These steps do not reduce to self-definition or fitted inputs by construction; the anti-concentration result is a falsifiable statistical outcome rather than a renaming or algebraic identity. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The central claims remain independent of the extraction method itself, as confirmed by cross-architecture consistency and causal interventions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Exchangeability assumptions required for valid p-values in the matched-spectrum randomization test
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning (ICML) , pages=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. International Conference on Machine Learning (ICML) , pages=. 2024 , volume=
2024
-
[2]
International Conference on Learning Representations (ICLR) , year=
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[3]
International Conference on Machine Learning (ICML) , pages=
On the Origins of Linear Representations in Large Language Models , author=. International Conference on Machine Learning (ICML) , pages=. 2024 , volume=
2024
-
[4]
BlackboxNLP Workshop , pages=
Emergent Linear Representations in World Models of Self-Supervised Sequence Models , author=. BlackboxNLP Workshop , pages=
-
[5]
Conference on Language Modeling (COLM) , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. Conference on Language Modeling (COLM) , year=
-
[6]
BlackboxNLP Workshop , pages=
Linear Representations of Sentiment in Large Language Models , author=. BlackboxNLP Workshop , pages=
-
[7]
International Conference on Learning Representations (ICLR) , year=
Not All Language Model Features Are One-Dimensionally Linear , author=. International Conference on Learning Representations (ICLR) , year=
-
[8]
ICLR Workshop , year=
Efficient Estimation of Word Representations in Vector Space , author=. ICLR Workshop , year=
-
[9]
NAACL-HLT , pages=
Linguistic Regularities in Continuous Space Word Representations , author=. NAACL-HLT , pages=
-
[10]
International Conference on Machine Learning (ICML) , pages=
Position: The Platonic Representation Hypothesis , author=. International Conference on Machine Learning (ICML) , pages=. 2024 , volume=
2024
-
[11]
Sparse Autoencoders Reveal Universal Feature Spaces Across Large Language Models , author=. arXiv preprint arXiv:2410.06981 , year=
-
[12]
International Conference on Machine Learning (ICML) , year=
Similarity of Neural Network Representations Revisited , author=. International Conference on Machine Learning (ICML) , year=
-
[13]
arXiv preprint arXiv:2505.13141 , year=
Language-Specific Latent Process Hinders Cross-Lingual Performance , author=. arXiv preprint arXiv:2505.13141 , year=
-
[14]
Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
Do Llamas Work in English? On the Latent Language of Multilingual Transformers , author=. Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[15]
International Conference on Learning Representations (ICLR) , year=
Word Translation Without Parallel Data , author=. International Conference on Learning Representations (ICLR) , year=
-
[16]
Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
Emerging Cross-lingual Structure in Pretrained Language Models , author=. Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[17]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[18]
Scaling Monosemanticity: Extracting Interpretable Features from
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and others , journal=. Scaling Monosemanticity: Extracting Interpretable Features from. 2024 , publisher=
2024
-
[19]
International Conference on Learning Representations (ICLR) , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[20]
International Conference on Learning Representations (ICLR) , year=
Scaling and Evaluating Sparse Autoencoders , author=. International Conference on Learning Representations (ICLR) , year=
-
[21]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kram. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on. BlackboxNLP Workshop , pages=
-
[22]
Llama Scope: Extracting Millions of Features from
He, Zhengfu and Shu, Wentao and Ge, Xuyang and Chen, Lingjie and Wang, Junxuan and Zhou, Yunhua and Liu, Frances and Guo, Qipeng and Huang, Xuanjing and Wu, Zuxuan and Jiang, Yu-Gang and Qiu, Xipeng , journal=. Llama Scope: Extracting Millions of Features from
-
[23]
How Contextual are Contextualized Word Representations?
Ethayarajh, Kawin , booktitle=. How Contextual are Contextualized Word Representations?
-
[24]
International Conference on Learning Representations (ICLR) , year=
Representation Degeneration Problem in Training Natural Language Generation Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[25]
Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
All Bark and No Bite: Rogue Dimensions in Transformer Language Models Obscure Representational Quality , author=. Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
-
[26]
Findings of EMNLP , pages=
Outlier Dimensions that Disrupt Transformers are Driven by Frequency , author=. Findings of EMNLP , pages=
-
[27]
Kovaleva, Olga and Kulshreshtha, Saurabh and Rogers, Anna and Rumshisky, Anna , booktitle=
-
[28]
North American Chapter of the Association for Computational Linguistics (NAACL) , pages=
Anisotropy is Not Inherent to Transformers , author=. North American Chapter of the Association for Computational Linguistics (NAACL) , pages=
-
[29]
AAAI Conference on Artificial Intelligence , year=
Activation Addition: Steering Language Models Without Optimization , author=. AAAI Conference on Artificial Intelligence , year=
-
[30]
Steering
Panickssery, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander Matt , booktitle=. Steering
-
[31]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and others , journal=. Representation Engineering: A Top-Down Approach to
-
[32]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[33]
Findings of ACL , pages=
Extracting Latent Steering Vectors from Pretrained Language Models , author=. Findings of ACL , pages=
-
[34]
Journal of Machine Learning Research , volume=
Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning , author=. Journal of Machine Learning Research , volume=
-
[35]
International Conference on Machine Learning (ICML) , pages=
Traditional and Heavy-Tailed Self Regularization in Neural Network Models , author=. International Conference on Machine Learning (ICML) , pages=
-
[36]
Nature Communications , volume=
Predicting Trends in the Quality of State-of-the-Art Neural Networks without Access to Training or Testing Data , author=. Nature Communications , volume=
-
[37]
Proceedings of the National Academy of Sciences , volume=
Prevalence of Neural Collapse during the Terminal Phase of Deep Learning Training , author=. Proceedings of the National Academy of Sciences , volume=
-
[38]
arXiv preprint arXiv:2405.17767 , year=
Linguistic Collapse: Neural Collapse in (Large) Language Models , author=. arXiv preprint arXiv:2405.17767 , year=
-
[39]
The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction , author=. arXiv preprint arXiv:2312.13558 , year=
-
[40]
Small Singular Values Matter: A Random Matrix Analysis of Transformer Models , author=. arXiv preprint arXiv:2410.17770 , year=
-
[41]
Whitening Sentence Representations for Better Semantics and Faster Retrieval , author=. arXiv preprint arXiv:2103.15316 , year=
-
[42]
Whitening
Huang, Junjie and Tang, Duyu and Zhong, Wanjun and Lu, Shuai and Shou, Linjun and Gong, Ming and Jiang, Daxin and Duan, Nan , booktitle=. Whitening
-
[43]
Understanding intermediate layers using linear classifier probes
Understanding Intermediate Layers Using Linear Classifier Probes , author=. arXiv preprint arXiv:1610.01644 , year=
-
[44]
Computational Linguistics , volume=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. Computational Linguistics , volume=
-
[45]
International Conference on Learning Representations (ICLR) , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. International Conference on Learning Representations (ICLR) , year=
-
[46]
Transformer Circuits Thread , year=
Toy Models of Superposition , author=. Transformer Circuits Thread , year=
-
[47]
Proceedings of the NAACL Student Research Workshop , pages=
Analogy-Based Detection of Morphological and Semantic Relations with Word Embeddings: What Works and What Doesn't , author=. Proceedings of the NAACL Student Research Workshop , pages=
-
[48]
Language Models Represent Space and Time , author=. arXiv preprint arXiv:2310.02207 , year=
-
[49]
Refusal in Language Models Is Mediated by a Single Direction
Refusal in Language Models Is Mediated by a Single Direction , author=. arXiv preprint arXiv:2406.11717 , year=
work page internal anchor Pith review arXiv
-
[50]
Polysemanticity and Capacity in Neural Networks , author=. arXiv preprint arXiv:2210.01892 , year=
-
[51]
Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC) , pages=
Universal Dependencies v1: A Multilingual Treebank Collection , author=. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.