Recognition: 3 theorem links
· Lean TheoremAct2See: Emergent Active Visual Perception for Video Reasoning
Pith reviewed 2026-05-08 19:30 UTC · model grok-4.3
The pith
VLMs can learn to actively retrieve or synthesize video frames mid-reasoning by fine-tuning on verified active CoT traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
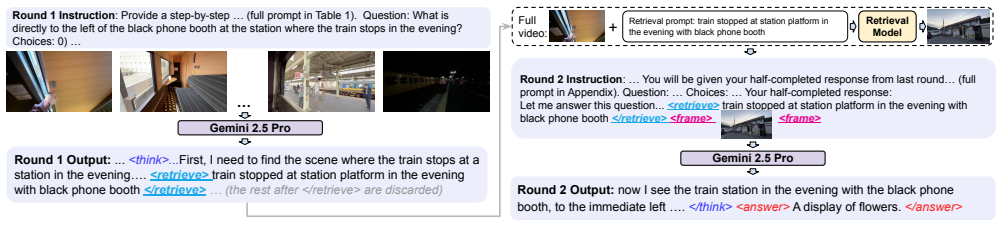
Act2See trains VLMs through supervised fine-tuning on high-quality reasoning traces generated by a frontier model; each trace interleaves text steps with active calls to retrieve existing video frames or synthesize new ones, and every trace is verified against human-annotated chains of thought. The resulting models exhibit emergent active visual perception: during inference they autonomously determine when to search for or generate the visual evidence needed to continue or correct their reasoning, rather than remaining restricted to the initial static frames.
What carries the argument
Act2See framework of supervised fine-tuning on verified reasoning traces that embed explicit active calls to retrieve or synthesize video frames inside text CoTs.
If this is right
- The model can now handle counterfactual and hypothetical video scenarios by synthesizing frames on demand.
- Performance improves on benchmarks that reward dynamic evidence gathering, such as VideoEspresso and ViTIB.
- The same training recipe yields gains on EgoNormia and VCR-Bench even against larger models that lack active perception.
- Reasoning chains become more interpretable because each active frame call is explicit in the output trace.
Where Pith is reading between the lines
- The approach could be extended to live video streams by letting the model request the next relevant clip instead of waiting for a full upload.
- Similar active-perception training might transfer to other modalities where evidence must be acquired on the fly, such as tool-use or embodied agents.
- If the verification step against human CoTs is relaxed, the method might still work but could increase the risk of inherited errors.
Load-bearing premise
That fine-tuning on frontier-generated and human-verified traces will produce reliable active frame calls at inference without copying over the teacher model's biases or hallucinations.
What would settle it
Run the fine-tuned model on a video reasoning question whose correct answer requires a frame that was never shown in the initial input; measure whether the model emits a correct retrieval or synthesis call before answering, versus hallucinating the missing content.
Figures




read the original abstract
Vision-Language Models (VLMs) typically rely on static initial frames for video reasoning, restricting their ability to incorporate essential dynamic information as the reasoning process evolves. Existing methods that augment Chain-of-Thought (CoT) with additional frame information often exhibit suboptimal CoT quality and lack the crucial ability to synthesize visual information for hypothetical or counterfactual scenarios. We introduce Act-to-See (Act2See), a novel framework that enables active visual perception by empowering VLMs to actively interleave video frames within text CoTs. Act2See is developed via Supervised Fine-Tuning (SFT) on a high-quality dataset of reasoning traces generated by a frontier VLM. These traces integrate active calls to either retrieve existing frames or generate new ones, and are rigorously verified against human-annotated CoTs to ensure quality. This approach cultivates an emergent capability: at inference time, the model actively determines when to search for or synthesize the necessary visual evidence. Act2See establishes new state-of-the-art results on challenging benchmarks, including VideoEspresso and ViTIB, and outperforms comparable or larger models on Video-MME, EgoNormia, and VCR-Bench, demonstrating an advancement in enabling VLMs with active visual perception for video reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Act2See, a framework that enables VLMs to perform active visual perception for video reasoning by interleaving explicit calls to retrieve existing frames or generate new (hypothetical/counterfactual) frames within text-based chain-of-thought traces. The model is trained via supervised fine-tuning on a dataset of such traces produced by a frontier VLM and rigorously verified against human-annotated CoTs. At inference the fine-tuned model is claimed to autonomously decide when and how to invoke these actions, yielding new state-of-the-art results on VideoEspresso and ViTIB while outperforming comparable or larger models on Video-MME, EgoNormia, and VCR-Bench.
Significance. If the reported gains are shown to arise from genuine emergent active perception rather than distillation artifacts, the work would meaningfully advance VLM capabilities for dynamic, evidence-seeking video reasoning. The use of human-verified frontier-VLM traces for dataset construction is a concrete strength that improves data quality over purely synthetic or unverified sources. The significance remains conditional on stronger evidence that the 'generate new ones' pathway produces accurate synthesized frames and that frame-selection decisions are not simply inherited from the teacher.
major comments (3)
- [Abstract] Abstract: The claim of new state-of-the-art results on VideoEspresso and ViTIB (and outperformance on Video-MME, EgoNormia, VCR-Bench) is presented without any mention of statistical significance testing, multiple-run variance, or ablation controls on the active-perception components; this information is load-bearing for the central claim that the gains reflect emergent active perception.
- [Method] Training and inference sections: The 'generate new ones' pathway for hypothetical or counterfactual frames is central to the active-perception claim, yet the manuscript provides no quantitative evaluation of the accuracy or utility of the synthesized frames at inference time, nor any comparison isolating generation versus retrieval; without this, it is impossible to rule out that performance improvements are artifacts of teacher-model biases propagated through SFT.
- [Experiments] Experiments: No ablation is reported that compares the fine-tuned Act2See model against direct imitation of the teacher VLM's frame-selection policy or against a version trained only on retrieval actions; such a control is required to substantiate that the observed benchmark gains arise from learned active decision-making rather than supervised imitation.
minor comments (1)
- [Abstract] The abstract and method sections use the term 'emergent capability' without a precise operational definition distinguishing it from behavior acquired through SFT; a short clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the evidence of emergent active perception in Act2See. We address each major comment point-by-point below, committing to targeted revisions that directly respond to the concerns while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of new state-of-the-art results on VideoEspresso and ViTIB (and outperformance on Video-MME, EgoNormia, VCR-Bench) is presented without any mention of statistical significance testing, multiple-run variance, or ablation controls on the active-perception components; this information is load-bearing for the central claim that the gains reflect emergent active perception.
Authors: We agree that the abstract claims would be more robust with explicit reference to statistical support. In the revised manuscript, we will expand the Experiments section to report results averaged over multiple independent runs (with means and standard deviations), include statistical significance testing where applicable, and add ablations isolating active-perception components. The abstract will be lightly updated to reference these supporting analyses in the main text, respecting length limits while addressing the load-bearing concern. revision: partial
-
Referee: [Method] Training and inference sections: The 'generate new ones' pathway for hypothetical or counterfactual frames is central to the active-perception claim, yet the manuscript provides no quantitative evaluation of the accuracy or utility of the synthesized frames at inference time, nor any comparison isolating generation versus retrieval; without this, it is impossible to rule out that performance improvements are artifacts of teacher-model biases propagated through SFT.
Authors: The referee correctly notes this evaluation gap for the generation pathway. Although training traces were human-verified, we did not quantify synthesized frame fidelity or isolate generation at inference. In the revision, we will add a dedicated analysis subsection using perceptual similarity metrics and available ground-truth counterfactuals from benchmarks to evaluate generated frame accuracy and utility. We will also include an ablation comparing the full model against a retrieval-only variant to separate the contributions and mitigate concerns about teacher bias propagation. revision: yes
-
Referee: [Experiments] Experiments: No ablation is reported that compares the fine-tuned Act2See model against direct imitation of the teacher VLM's frame-selection policy or against a version trained only on retrieval actions; such a control is required to substantiate that the observed benchmark gains arise from learned active decision-making rather than supervised imitation.
Authors: We acknowledge that distinguishing learned active decision-making from direct imitation is essential for the 'emergent' claim. The current setup relies on verified CoT traces and autonomous inference behavior, but lacks these specific controls. In the revised Experiments section, we will add ablations comparing Act2See to (i) a model trained via direct imitation of the teacher's frame-selection policy and (ii) a retrieval-only training variant. These will help demonstrate that benchmark gains stem from the learned active perception capability rather than pure supervised imitation. revision: yes
Circularity Check
No circularity: empirical SFT on external verified traces with independent benchmark evaluation
full rationale
The paper's core procedure is supervised fine-tuning on reasoning traces produced by an external frontier VLM and cross-checked against separate human-annotated CoTs. The claimed 'emergent' active-perception behavior at inference is the direct learned output of that training objective rather than a derived prediction that collapses back onto the inputs by construction. No equations, uniqueness theorems, self-citations, or fitted parameters are invoked to justify the results; performance is reported on held-out benchmarks (VideoEspresso, ViTIB, Video-MME, etc.) that are not used in training. This satisfies the default expectation of a non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- SFT hyperparameters and dataset size
axioms (1)
- domain assumption Frontier VLM generates high-quality, verifiable reasoning traces suitable for SFT
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J(x)=½(x+x⁻¹)−1)washburn_uniqueness_aczel unclearJ(θ) = − (1/N) Σ Σ log P(y_t | V, Q, y_<t; θ) ... We compute the token-level losses over the whole rollout, including sequences of retrieval or generation queries, only excluding retrieved or generated frames.
-
Foundation (parameter-free forcing chain)reality_from_one_distinction unclearWe fine-tune with LoRA with 8 A100 GPUs, using a learning rate of 2.5×10^−6, a batch size of 1, and a single epoch.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 1, 2, 5, 6
work page Pith review arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 5, 6, 4
work page Pith review arXiv 2025
-
[3]
Active perception.Proceedings of the IEEE, 76(8):966–1005, 1988
Ruzena Bajcsy. Active perception.Proceedings of the IEEE, 76(8):966–1005, 1988. 1, 8
1988
-
[4]
Qualitative failures of image generation models and their application in detecting deepfakes.Image and Vi- sion Computing, 137:104771, 2023
Ali Borji. Qualitative failures of image generation models and their application in detecting deepfakes.Image and Vi- sion Computing, 137:104771, 2023. 7
2023
-
[5]
M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation. InFindings of the association for computational linguistics: ACL 2024, pages 2318–2335, 2024. 4, 3
2024
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 1, 2, 5, 6
work page internal anchor Pith review arXiv 2024
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1, 4, 5, 6
work page Pith review arXiv 2025
-
[8]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[9]
Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, Meishan Zhang, Mong-Li Lee, and Wynne Hsu. Video-of-thought: Step-by-step video reasoning from perception to cognition. arXiv preprint arXiv:2501.03230, 2024. 8
-
[10]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review arXiv
-
[11]
Aaron Foss, Chloe Evans, Sasha Mitts, Koustuv Sinha, Am- mar Rizvi, and Justine T Kao. Causalvqa: A physically grounded causal reasoning benchmark for video models. arXiv preprint arXiv:2506.09943, 2025. 1, 2, 4, 5, 7
-
[12]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 2, 5, 7, 4
2025
-
[13]
Famemind: Frame-interleaved video reasoning via reinforcement learning.arXiv e-prints, pages arXiv– 2509, 2025
Haonan Ge, Yiwei Wang, Kai-Wei Chang, Hang Wu, and Yujun Cai. Famemind: Frame-interleaved video reasoning via reinforcement learning.arXiv e-prints, pages arXiv– 2509, 2025. 1, 2, 5, 6, 7, 8
2025
-
[14]
Chain-of-Frames: Advancing Video Understanding in Multimodal LLMs via Frame-Aware Reasoning
Sara Ghazanfari, Francesco Croce, Nicolas Flammarion, Prashanth Krishnamurthy, Farshad Khorrami, and Siddharth Garg. Chain-of-frames: Advancing video understanding in multimodal llms via frame-aware reasoning.arXiv preprint arXiv:2506.00318, 2025. 1, 5, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
2024
-
[16]
Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection
Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, and Si Liu. Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 26181–26191, 2025. 1, 2, 3, 4, 5, 7
2025
-
[17]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arxiv 2021.arXiv preprint arXiv:2106.09685, 10, 2021. 5
work page internal anchor Pith review arXiv 2021
-
[18]
Cos: Chain-of-shot prompting for long video under- standing.arXiv preprint arXiv:2502.06428, 2025
Jian Hu, Zixu Cheng, Chenyang Si, Wei Li, and Shaogang Gong. Cos: Chain-of-shot prompting for long video under- standing.arXiv preprint arXiv:2502.06428, 2025. 1, 2, 5, 6, 8
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 1, 5, 6
work page Pith review arXiv 2024
-
[20]
Interac- tive sketchpad: A multimodal tutoring system for collabora- tive, visual problem-solving
Jimin Lee, Steven-Shine Chen, and Paul Pu Liang. Interac- tive sketchpad: A multimodal tutoring system for collabora- tive, visual problem-solving. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Com- puting Systems, pages 1–14, 2025. 8
2025
-
[21]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 4, 2
2023
-
[22]
Eyes can deceive: Benchmarking counterfac- tual reasoning abilities of multi-modal large language mod- els.CoRR, 2024
Yian Li, Wentao Tian, Yang Jiao, Jingjing Chen, and Yu- Gang Jiang. Eyes can deceive: Benchmarking counterfac- tual reasoning abilities of multi-modal large language mod- els.CoRR, 2024. 1
2024
-
[23]
Foundations & trends in multimodal machine learning: Prin- ciples, challenges, and open questions.ACM Computing Sur- veys, 56(10):1–42, 2024
Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. Foundations & trends in multimodal machine learning: Prin- ciples, challenges, and open questions.ACM Computing Sur- veys, 56(10):1–42, 2024. 8
2024
-
[24]
Leena Mathur, Marian Qian, Paul Pu Liang, and Louis- Philippe Morency. Social genome: Grounded social rea- soning abilities of multimodal models.arXiv preprint arXiv:2502.15109, 2025. 2, 4, 5, 7, 1
-
[25]
Xuefei Ning, Guohao Dai, Haoli Bai, Lu Hou, Yu Wang, and Qun Liu
Arsha Nagrani, Sachit Menon, Ahmet Iscen, Shyamal Buch, Ramin Mehran, Nilpa Jha, Anja Hauth, Yukun Zhu, Carl V ondrick, Mikhail Sirotenko, et al. Minerva: Evaluating complex video reasoning.arXiv preprint arXiv:2505.00681,
-
[26]
Yukun Qi, Yiming Zhao, Yu Zeng, Xikun Bao, Wenxuan Huang, Lin Chen, Zehui Chen, Jie Zhao, Zhongang Qi, and Feng Zhao. Vcr-bench: A comprehensive evaluation frame- work for video chain-of-thought reasoning.arXiv preprint arXiv:2504.07956, 2025. 2, 5, 7, 4
-
[27]
Egonormia: Benchmarking physical social norm understanding.arXiv preprint arXiv:2502.20490, 2025
MohammadHossein Rezaei, Yicheng Fu, Phil Cuvin, Caleb Ziems, Yanzhe Zhang, Hao Zhu, and Diyi Yang. Egonormia: Benchmarking physical social norm understanding.arXiv preprint arXiv:2502.20490, 2025. 1, 2, 5, 4
-
[28]
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Jun- tao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning.arXiv preprint arXiv:2505.08617, 2025. 1, 8
-
[29]
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning.arXiv preprint arXiv:2505.12434,
-
[30]
Yan Wang, Yawen Zeng, Jingsheng Zheng, Xiaofen Xing, Jin Xu, and Xiangmin Xu. Videocot: A video chain-of- thought dataset with active annotation tool.arXiv preprint arXiv:2407.05355, 2024. 1, 8
-
[31]
Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 1
2022
-
[32]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understand- ing.arXiv preprint arXiv:2501.13106, 2025. 1, 2, 5, 6
work page internal anchor Pith review arXiv 2025
-
[33]
Congzhi Zhang, Zhibin Wang, Yinchao Ma, Jiawei Peng, Yi- han Wang, Qiang Zhou, Jun Song, and Bo Zheng. Rewatch- r1: Boosting complex video reasoning in large vision- language models through agentic data synthesis.arXiv preprint arXiv:2509.23652, 2025. 1, 2, 5, 6, 7, 8
-
[34]
Yongheng Zhang, Xu Liu, Ruihan Tao, Qiguang Chen, Hao Fei, Wanxiang Che, and Libo Qin. Vitcot: Video-text in- terleaved chain-of-thought for boosting video understanding in large language models.arXiv preprint arXiv:2507.09876,
-
[35]
Training-free video temporal grounding using large-scale pre-trained models
Minghang Zheng, Xinhao Cai, Qingchao Chen, Yuxin Peng, and Yang Liu. Training-free video temporal grounding using large-scale pre-trained models. InEuropean Conference on Computer Vision, pages 20–37. Springer, 2024. 4, 5
2024
-
[36]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deep- eyes: Incentivizing” thinking with images” via reinforce- ment learning.arXiv preprint arXiv:2505.14362, 2025. 1, 8 ACT2SEE: Emergent Active Visual Perception for Video Reasoning Supplementary Material A. Impact statement The ACT2SEEframework significant...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.