Recognition: 2 theorem links
· Lean TheoremVideo Active Perception: Effective Inference-Time Long-Form Video Understanding with Vision-Language Models
Pith reviewed 2026-05-08 19:12 UTC · model grok-4.3
The pith
Treating keyframe selection as active perception with a video generation model as prior knowledge allows vision-language models to achieve state-of-the-art zero-shot performance on long-form video QA with up to 5.6 times higher frame效率.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Video Active Perception (VAP) is a training-free inference-time approach that models keyframe selection as data acquisition under active perception theory. By using a lightweight text-conditioned video generation model to embody prior world knowledge, VAP selects frames that differ from generated expectations, supplying vision-language models with more informative inputs for question answering. This yields state-of-the-art zero-shot results on EgoSchema, NExT-QA, ActivityNet-QA, IntentQA, and CLEVRER while delivering up to 5.6 times greater frame efficiency than uniform sampling with models such as GPT-4o, Gemini 1.5 Pro, and LLaVA-OV.
What carries the argument
The text-conditioned video generation model serving as proxy for prior world knowledge to drive active-perception keyframe selection that maximizes information gain for the vision-language model.
If this is right
- Vision-language models can answer long-form and reasoning questions with substantially fewer frames while maintaining or improving accuracy.
- Keyframe choices become more aligned with question content rather than uniform coverage of the entire video.
- No additional training or fine-tuning is required to obtain the efficiency and accuracy gains on multiple public benchmarks.
- Reasoning performance improves on tasks that depend on temporal and causal understanding across video segments.
Where Pith is reading between the lines
- The same expectation-based selection could be applied at test time to other multimodal tasks such as video captioning or temporal action localization.
- Replacing the current lightweight generator with a stronger one might further increase the quality of the prior and the resulting efficiency gains.
- The method opens a path to hybrid systems that combine active perception at inference time with lightweight adaptation of the underlying vision-language model.
Load-bearing premise
A lightweight text-conditioned video generation model supplies a reliable enough proxy for the vision-language model's prior knowledge to identify frames that actually improve question-answering performance.
What would settle it
On a held-out video QA dataset where the generation model produces frames that closely match the actual video content yet VAP still underperforms uniform sampling in accuracy or efficiency.
Figures

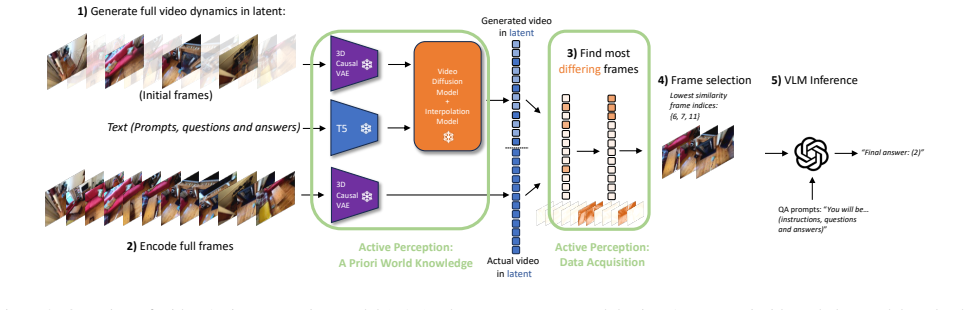
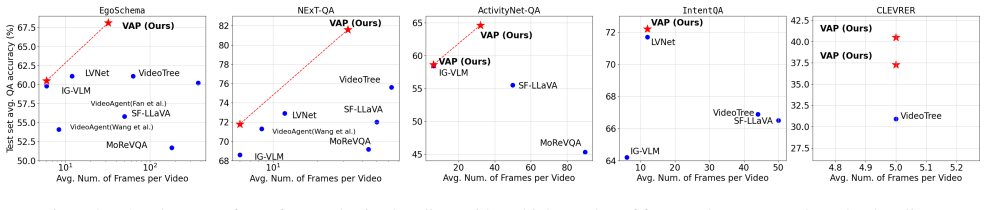

read the original abstract
Large vision-language models (VLMs) have advanced multimodal tasks such as video question answering (QA). However, VLMs face the challenge of selecting frames effectively and efficiently, as standard uniform sampling is expensive and performance may plateau. Inspired by active perception theory, which posits that models gain information by acquiring data that differs from their expectations, we introduce Video Active Perception (VAP), a training-free method to enhance long-form video QA using VLMs. Our approach treats keyframe selection as data acquisition in active perception and leverages a lightweight text-conditioned video generation model to represent prior world knowledge. Empirically, VAP achieves state-of-the-art zero-shot results on long-form or reasoning video QA datasets such as EgoSchema, NExT-QA, ActivityNet-QA, IntentQA, and CLEVRER, achieving an increase of up to 5.6 x frame efficiency by frames per question over standard GPT-4o, Gemini 1.5 Pro, and LLaVA-OV. Moreover, VAP shows stronger reasoning abilities than previous methods and effectively selects keyframes relevant to questions. These findings highlight the potential of leveraging active perception to improve the frame effectiveness and efficiency of long-form video QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Video Active Perception (VAP), a training-free method for long-form video question answering with vision-language models. It frames keyframe selection as an active perception process, using a lightweight text-conditioned video generation model to encode prior world knowledge and selecting frames whose content deviates from the model's generated expectations. The approach is evaluated zero-shot on EgoSchema, NExT-QA, ActivityNet-QA, IntentQA, and CLEVRER, claiming state-of-the-art results together with up to 5.6× improvement in frames-per-question efficiency relative to GPT-4o, Gemini 1.5 Pro, and LLaVA-OV.
Significance. If the gains prove robust, the work would be significant for inference-time video understanding: it offers a principled, training-free route to higher frame efficiency and stronger reasoning by importing active-perception ideas into VLM pipelines. The explicit use of a generative prior as a proxy for world knowledge is a distinctive technical choice that, if validated, could generalize beyond the reported QA tasks.
major comments (3)
- [§3.2–3.3] §3.2–3.3: The central claim that the text-conditioned video generation model supplies a reliable proxy for prior knowledge is load-bearing, yet the manuscript provides no quantitative measure of generation fidelity (e.g., FID, CLIP similarity, or human preference) on the target domains (egocentric, web, or synthetic). Without such evidence the active-perception step risks reducing to an unverified heuristic.
- [§4.1 and §5.1] §4.1 and §5.1: No ablation isolates the contribution of the discrepancy-based selection against uniform sampling or random selection at identical frame budgets; the reported efficiency gains therefore cannot be attributed unambiguously to the active-perception mechanism rather than simply to the choice of total frame count.
- [§5.2, Tables 2–4] §5.2, Tables 2–4: Performance numbers are presented without standard deviations across multiple runs, without statistical significance tests, and without details of the exact keyframe-selection algorithm (threshold, top-k rule, or stopping criterion). This prevents verification that the claimed SOTA margins are stable.
minor comments (2)
- [Eq. 3] The notation for the discrepancy score (Eq. 3) is introduced without an explicit definition of the distance metric or the conditioning text used for generation; a short pseudocode block would improve reproducibility.
- [Figure 3] Figure 3 caption does not state the exact number of frames shown or the source of the ground-truth question; readers cannot judge whether the visualized keyframes are representative.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions that will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2–3.3] §3.2–3.3: The central claim that the text-conditioned video generation model supplies a reliable proxy for prior knowledge is load-bearing, yet the manuscript provides no quantitative measure of generation fidelity (e.g., FID, CLIP similarity, or human preference) on the target domains (egocentric, web, or synthetic). Without such evidence the active-perception step risks reducing to an unverified heuristic.
Authors: We agree that quantitative evidence of generation fidelity on the target domains would provide stronger grounding for the claim. While downstream QA gains and keyframe relevance serve as indirect validation in the current manuscript, this is a valid gap. In the revised version we will add FID scores and CLIP similarities between the text-conditioned generations and real frames sampled from EgoSchema, NExT-QA, ActivityNet-QA, IntentQA, and CLEVRER to directly measure fidelity on the evaluation domains. revision: yes
-
Referee: [§4.1 and §5.1] §4.1 and §5.1: No ablation isolates the contribution of the discrepancy-based selection against uniform sampling or random selection at identical frame budgets; the reported efficiency gains therefore cannot be attributed unambiguously to the active-perception mechanism rather than simply to the choice of total frame count.
Authors: We thank the referee for this observation. To isolate the effect of discrepancy-based selection, the revised manuscript will include new ablations that compare VAP against both uniform sampling and random selection while holding the exact frame budget per question fixed to the values used in the main experiments. These results will be reported in §4.1 and §5.1 to demonstrate that the observed gains arise from the active-perception mechanism rather than frame count alone. revision: yes
-
Referee: [§5.2, Tables 2–4] §5.2, Tables 2–4: Performance numbers are presented without standard deviations across multiple runs, without statistical significance tests, and without details of the exact keyframe-selection algorithm (threshold, top-k rule, or stopping criterion). This prevents verification that the claimed SOTA margins are stable.
Authors: We agree that these details are necessary for reproducibility and for confirming the stability of the reported margins. In the revision we will (i) report standard deviations computed over multiple independent runs of both keyframe selection and VLM inference, (ii) add statistical significance tests (paired t-tests) for all SOTA comparisons in Tables 2–4, and (iii) provide a precise algorithmic description of the discrepancy threshold, top-k rule, and stopping criterion in §5.2 together with pseudocode in the appendix. revision: yes
Circularity Check
No significant circularity; derivation relies on external pretrained components
full rationale
The paper introduces VAP as a training-free inference-time method that applies active perception principles by using a separate lightweight text-conditioned video generation model (external and pretrained) to generate expectations for keyframe selection. No equations, fitted parameters, or derivations in the abstract or described method reduce the performance claims to inputs by construction. Claims of improved efficiency and SOTA zero-shot results are presented as empirical outcomes on independent datasets (EgoSchema, NExT-QA, etc.), not forced by self-definition or self-citation chains. The approach is self-contained against external benchmarks without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Active perception theory can be directly operationalized for keyframe selection in video QA via a generative prior.
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (J-cost machinery)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
leverages a lightweight text-conditioned video generation model to represent prior world knowledge ... compute the cosine similarity ... select indices of n=32 real frames with the lowest similarities
-
Foundation.LogicAsFunctionalEquation / ArithmeticFromLogicn/a (no distinction-based forcing structure invoked) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inspired by active perception theory, which posits that models gain information by acquiring data that differs from their expectations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[2]
Psychology Press,
Yiannis Aloimonos.Active perception. Psychology Press,
-
[3]
Active perception.Proceedings of the IEEE, 76(8):966–1005, 1988
Ruzena Bajcsy. Active perception.Proceedings of the IEEE, 76(8):966–1005, 1988
1988
-
[4]
Revisiting active perception.Autonomous Robots, 42:177– 196, 2018
Ruzena Bajcsy, Yiannis Aloimonos, and John K Tsotsos. Revisiting active perception.Autonomous Robots, 42:177– 196, 2018. 1, 2
2018
-
[5]
Activitynet: A large-scale video bench- mark for human activity understanding
FabianCabaHeilbron,VictorEscorcia,BernardGhanem,and Juan Carlos Niebles. Activitynet: A large-scale video bench- mark for human activity understanding. InProceedings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 5
2015
-
[6]
The perception-behavior expressway: Auto- maticeffectsofsocialperceptiononsocialbehavior.Advances in Experimental Social Psychology/Academic Press, 2001
Ap Dijksterhuis. The perception-behavior expressway: Auto- maticeffectsofsocialperceptiononsocialbehavior.Advances in Experimental Social Psychology/Academic Press, 2001. 1
2001
-
[7]
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multimodal agent for video understanding.arXiv preprint arXiv:2403.11481, 2024. 1, 2, 5, 6
-
[8]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[9]
AndreasGoulas,VasileiosMezaris,andIoannisPatras.Vidctx: Context-aware video question answering with image models,
-
[10]
Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
JonathanHo,TimSalimans,AlexeyGritsenko,WilliamChan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022. 4
2022
-
[11]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generationviatransformers.arXivpreprintarXiv:2205.15868,
work page internal anchor Pith review arXiv
-
[12]
Real-time intermediate flow estimation for video frame interpolation
Zhewei Huang, Tianyuan Zhang, Wen Heng, Boxin Shi, and Shuchang Zhou. Real-time intermediate flow estimation for video frame interpolation. InEuropean Conference on Computer Vision, pages 624–642. Springer, 2022. 4
2022
-
[13]
Building a mind palace: Structuring environment- grounded semantic graphs for effective long video analysis with llms, 2025
Zeyi Huang, Yuyang Ji, Xiaofang Wang, Nikhil Mehta, Tong Xiao, Donghyun Lee, Sigmund Vanvalkenburgh, Shengxin Zha, Bolin Lai, Licheng Yu, Ning Zhang, Yong Jae Lee, and Miao Liu. Building a mind palace: Structuring environment- grounded semantic graphs for effective long video analysis with llms, 2025. 2
2025
-
[14]
Adaptivevideounderstanding agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning, 2024
Sullam Jeoung, Goeric Huybrechts, Bhavana Ganesh, Aram Galstyan,andSravanBodapati. Adaptivevideounderstanding agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning, 2024. 2
2024
-
[15]
Cost-sensitive feature acquisi- tionandclassification.PatternRecognition,40(5):1474–1485,
Shihao Ji and Lawrence Carin. Cost-sensitive feature acquisi- tionandclassification.PatternRecognition,40(5):1474–1485,
-
[16]
Egoschema leaderboard.Kaggle Leaderboard, 2024
Kaggle. Egoschema leaderboard.Kaggle Leaderboard, 2024. 4
2024
-
[17]
An image grid can be worth a video: Zero-shot video question answering using a vlm,
Wonkyun Kim, Changin Choi, Wonseok Lee, and Won- jong Rhee. An image grid can be worth a video: Zero- shot video question answering using a vlm.arXiv preprint arXiv:2403.18406, 2024. 2, 5, 6
-
[18]
arXiv preprint arXiv:2211.05039 , year=
Jannik Kossen, Cătălina Cangea, Eszter Vértes, Andrew Jaegle, Viorica Patraucean, Ira Ktena, Nenad Tomasev, and DanielleBelgrave. Activeacquisitionformultimodaltemporal data: A challenging decision-making task.arXiv preprint arXiv:2211.05039, 2022. 2
-
[19]
Active data acqui- sition in autonomous driving simulation.arXiv preprint arXiv:2306.13923, 2023
Jianyu Lai, Zexuan Jia, and Boao Li. Active data acqui- sition in autonomous driving simulation.arXiv preprint arXiv:2306.13923, 2023. 2
-
[20]
Accurateimputationandefficientdataacquisitionwith transformer-based vaes
Sarah Lewis, Tatiana Matejovicova, Yingzhen Li, Angus Lamb, Yordan Zaykov, Miltiadis Allamanis, and Cheng Zhang. Accurateimputationandefficientdataacquisitionwith transformer-based vaes. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. 2
2021
-
[21]
Lmms-eval: Accelerating the development of large multimoal models, 2024
Bo Li, Peiyuan Zhang, Kaichen Zhang, Fanyi Pu, Xinrun Du, Yuhao Dong, Haotian Liu, Yuanhan Zhang, Ge Zhang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Accelerating the development of large multimoal models, 2024. 6
2024
-
[22]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 2, 5, 6
work page Pith review arXiv 2024
-
[23]
Intentqa: Context-aware video intent reasoning
JiapengLi,PingWei,WenjuanHan,andLifengFan. Intentqa: Context-aware video intent reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11963–11974, 2023. 2, 5
2023
-
[24]
Mvbench: Acomprehensivemulti-modalvideounderstanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: Acomprehensivemulti-modalvideounderstanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195– 22206, 2024. 6
2024
-
[25]
Foundations & trends in multimodal machine learning: Prin- ciples, challenges, and open questions.ACM Computing Surveys, 56(10):1–42, 2024
Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. Foundations & trends in multimodal machine learning: Prin- ciples, challenges, and open questions.ACM Computing Surveys, 56(10):1–42, 2024. 1
2024
-
[26]
Videoinsta: Zero-shot long video understanding via informative spatial- temporal reasoning with llms, 2024
Ruotong Liao, Max Erler, Huiyu Wang, Guangyao Zhai, Gengyuan Zhang, Yunpu Ma, and Volker Tresp. Videoinsta: Zero-shot long video understanding via informative spatial- temporal reasoning with llms, 2024. 2 9
2024
-
[27]
Video-rag: Visually-aligned retrieval-augmented long video comprehension, 2024
Yongdong Luo, Xiawu Zheng, Xiao Yang, Guilin Li, Haojia Lin, JinfaHuang, JiayiJi, FeiChao, JieboLuo, andRongrong Ji. Video-rag: Visually-aligned retrieval-augmented long video comprehension, 2024. 2
2024
-
[28]
Drvideo: Document retrieval based long video understanding, 2024
Ziyu Ma, Chenhui Gou, Hengcan Shi, Bin Sun, Shutao Li, Hamid Rezatofighi, and Jianfei Cai. Drvideo: Document retrieval based long video understanding, 2024. 2, 5, 6
2024
-
[29]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424, 2023. 5
work page internal anchor Pith review arXiv 2023
-
[30]
Egoschema: A diagnostic benchmark for very long- form video language understanding.Advances in Neural Information Processing Systems, 36, 2024
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding.Advances in Neural Information Processing Systems, 36, 2024. 1, 4
2024
-
[31]
LeslieZMcArthurandReubenMBaron.Towardanecological theory of social perception.Psychological review, 90(3):215,
-
[32]
Morevqa: Exploring modular reasoning models for video question answering
Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, and Cordelia Schmid. Morevqa: Exploring modular reasoning models for video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13235–13245, 2024. 2, 5, 6
2024
-
[33]
Gpt-4o blog: Hello gpt-4o, 2024
OpenAI. Gpt-4o blog: Hello gpt-4o, 2024. 5, 6
2024
-
[34]
Too many frames, not all useful: Efficient strategies for long-form video qa,
Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryoo, Donghyun Kim, and Michael S Ryoo. Too many frames, not all useful: Efficient strategies for long-form video qa.arXiv preprint arXiv:2406.09396, 2024. 5, 6
-
[35]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4195–4205,
-
[36]
Active percep- tion: sensorimotor circuits as a cortical basis for language
Friedemann Pulvermüller and Luciano Fadiga. Active percep- tion: sensorimotor circuits as a cortical basis for language. Nature reviews neuroscience, 11(5):351–360, 2010. 2
2010
-
[37]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 3
2020
-
[38]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
MachelReid,NikolaySavinov,DenisTeplyashin,DmitryLep- ikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across mil- lions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review arXiv
-
[39]
Active feature-value acquisition.Management Science, 55(4): 664–684, 2009
Maytal Saar-Tsechansky, Prem Melville, and Foster Provost. Active feature-value acquisition.Management Science, 55(4): 664–684, 2009. 2
2009
-
[40]
An ecological approach to personality: Psycholog- ical traits as drivers and consequences of active perception
Liam Paul Satchell, Roope Oskari Kaaronen, and Robert D Latzman. An ecological approach to personality: Psycholog- ical traits as drivers and consequences of active perception. Social and personality psychology compass, 15(5):e12595,
-
[41]
Maximizing information gain in partially observable environments via prediction reward
Yash Satsangi, Sungsu Lim, Shimon Whiteson, Frans Oliehoek, and Martha White. Maximizing information gain in partially observable environments via prediction reward. arXiv preprint arXiv:2005.04912, 2020. 2
-
[42]
Traveler: A modular multi-lmm agent framework for video question-answering, 2024
ChuyiShang,AmosYou,SanjaySubramanian,TrevorDarrell, and Roei Herzig. Traveler: A modular multi-lmm agent framework for video question-answering, 2024. 2
2024
-
[43]
Joint active feature acquisition and classification with variable-size set encoding.Advancesinneuralinformationprocessingsystems, 31, 2018
Hajin Shim, Sung Ju Hwang, and Eunho Yang. Joint active feature acquisition and classification with variable-size set encoding.Advancesinneuralinformationprocessingsystems, 31, 2018. 2
2018
-
[44]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[45]
Stanford University, 1971
Jay Martin Tenenbaum.Accommodation in computer vision. Stanford University, 1971. 1, 2
1971
-
[46]
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung- Levy. Videoagent: Long-formvideounderstandingwithlarge language model as agent.arXiv preprint arXiv:2403.10517,
-
[47]
Videotree: Adaptive tree- based video representation for llm reasoning on long videos,
ZiyangWang,ShoubinYu,EliasStengel-Eskin,JaehongYoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos.arXiv preprint arXiv:2405.19209, 2024. 1, 2, 5, 6
-
[48]
Network mechanisms of ongoing brain activity’s influence on conscious visual perception.Nature Communications, 15(1): 5720, 2024
Yuan-hao Wu, Ella Podvalny, Max Levinson, and Biyu J He. Network mechanisms of ongoing brain activity’s influence on conscious visual perception.Nature Communications, 15(1): 5720, 2024. 1
2024
-
[49]
Next-qa: Next phase of question-answering to explaining temporalactions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporalactions. InProceedingsoftheIEEE/CVFconference oncomputervisionandpatternrecognition,pages9777–9786,
-
[50]
Slowfast-llava: A strong training-free baseline for video large language models, 2024
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, and Afshin De- hghan. Slowfast-llava: A strong training-free baseline for video large language models, 2024. 2, 5, 6
2024
-
[51]
Evalai: Towards better evalua- tion systems for ai agents, 2019
Deshraj Yadav, Rishabh Jain, Harsh Agrawal, Prithvijit Chat- topadhyay, Taranjeet Singh, Akash Jain, Shiv Baran Singh, Stefan Lee, and Dhruv Batra. Evalai: Towards better evalua- tion systems for ai agents, 2019. 5
2019
-
[52]
Active sensing in the categorization of visual patterns.Elife, 5:e12215, 2016
ScottCheng-HsinYang,MateLengyel,andDanielMWolpert. Active sensing in the categorization of visual patterns.Elife, 5:e12215, 2016. 2
2016
-
[53]
Vca: Video curious agent for long video understanding, 2024
Zeyuan Yang, Delin Chen, Xueyang Yu, Maohao Shen, and Chuang Gan. Vca: Video curious agent for long video understanding, 2024. 2
2024
-
[54]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 3, 4
work page internal anchor Pith review arXiv 2024
-
[55]
Clevrer: Collision events for video representation and reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collisioneventsforvideorepresentationandreasoning.arXiv preprint arXiv:1910.01442, 2019. 2, 5
-
[56]
Reinforcementlearningwithefficient active feature acquisition.arXiv preprint arXiv:2011.00825,
HaiyanYin,YingzhenLi,SinnoJialinPan,ChengZhang,and SebastianTschiatschek. Reinforcementlearningwithefficient active feature acquisition.arXiv preprint arXiv:2011.00825,
-
[57]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, José Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, et al. Language model beats diffusion–tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[58]
Active sensing
Shipeng Yu, Balaji Krishnapuram, Romer Rosales, and R Bharat Rao. Active sensing. InArtificial Intelligence and Statistics, pages 639–646. PMLR, 2009. 2
2009
-
[59]
Activitynet-qa: A dataset for understandingcomplexwebvideosviaquestionanswering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understandingcomplexwebvideosviaquestionanswering. In ProceedingsoftheAAAIConferenceonArtificialIntelligence, pages 9127–9134, 2019. 2, 5
2019
-
[60]
Active perception and representation for robotic manipulation.arXiv preprint arXiv:2003.06734, 2020
Youssef Zaky, Gaurav Paruthi, Bryan Tripp, and James Bergstra. Active perception and representation for robotic manipulation.arXiv preprint arXiv:2003.06734, 2020. 2
-
[61]
A simple llmframeworkforlong-rangevideoquestion-answering,2024
Ce Zhang, Taixi Lu, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, and Gedas Bertasius. A simple llmframeworkforlong-rangevideoquestion-answering,2024. 2
2024
-
[62]
Zixu Zhang and Jaime F Fisac. Safe occlusion-aware au- tonomousdrivingviagame-theoreticactiveperception.arXiv preprint arXiv:2105.08169, 2021. 2
-
[63]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding.arXiv preprint arXiv:2406.04264, 2024. 6 11 Video Active Perception: Effective Inference-Time Long-Form Video Understanding with Vision-Language Models Supplementary Material
work page internal anchor Pith review arXiv 2024
-
[64]
Weprovideadetailedpromptwithexamplestoleverage the video generation model’s capacity as much as possi- ble
Appendix 6.1.V APimplementation details We provide the main prompt for the video generation model in9. Weprovideadetailedpromptwithexamplestoleverage the video generation model’s capacity as much as possi- ble. In terms of the video generation model, including the video diffusion model, 3D VAE, and interpolation model, we refer the details of the model ch...
-
[65]
1b)Extract visual cues that indicate the environment (e.g., indoor, outdoor, time of day) and participants (e.g., people, animals, objects)
Analyze the Initial Frames: 1a) Examine the provided initial frames to understand the setting, context, characters, objects, and any ongoing actions or events. 1b)Extract visual cues that indicate the environment (e.g., indoor, outdoor, time of day) and participants (e.g., people, animals, objects)
-
[66]
2b) Consider each possible answer to understand different potential outcomes or scenarios
Incorporate the Question and Possible Answers: 2a) Read the question carefully to determine what information is being sought. 2b) Consider each possible answer to understand different potential outcomes or scenarios. 2c) Use this information to guide your expectations of how the video might progress
-
[67]
3b) Focus on generating dynamics that would lead to scenarios described in the possible answers
Generate Expected Video Dynamics: 3a) Using your prior knowledge and the initial frames, predict plausible sequences of events that align with the context and are relevant to the question. 3b) Focus on generating dynamics that would lead to scenarios described in the possible answers. 3c) Create latent representations that capture these expected continuat...
-
[68]
Question about the video:{Question}
-
[69]
Possible Answers:{Answers}
-
[70]
Initial Frames:{Initial Frames} Instructions:
-
[71]
1b) Incorporate common sense and logical reasoning to predict what is likely to happen next
Leverage Prior Knowledge: 1a) Utilize your understanding of real-world behaviors, cause-and-effect relationships, and typical sequences of events. 1b) Incorporate common sense and logical reasoning to predict what is likely to happen next
-
[72]
2b) Highlight events or actions that would help distinguish between the different answers
Focus on Relevance: 2a) Ensure that the generated dynamics are directly relevant to the question and possible answers. 2b) Highlight events or actions that would help distinguish between the different answers
-
[73]
What does the person do after the light turns green?
Maintain Consistency: 3a) Keep the generated content consistent with the visual information in the initial frames (e.g., same characters, objects, setting). 3b) Avoid introducing improbable elements that contradict the initial context. Example: Initial Frames: Show a person standing at a crosswalk, waiting for the light to change. Question: "What does the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.