Recognition: unknown
The "Astonishing Regularity'' Revisited: Sensitivity of Learning-Rate Estimates to Practice-Sequence Length
Pith reviewed 2026-05-09 17:18 UTC · model grok-4.3
The pith
Capping practice sequences at the first five to ten opportunities per student-skill pair substantially inflates estimates of student learning-rate variability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
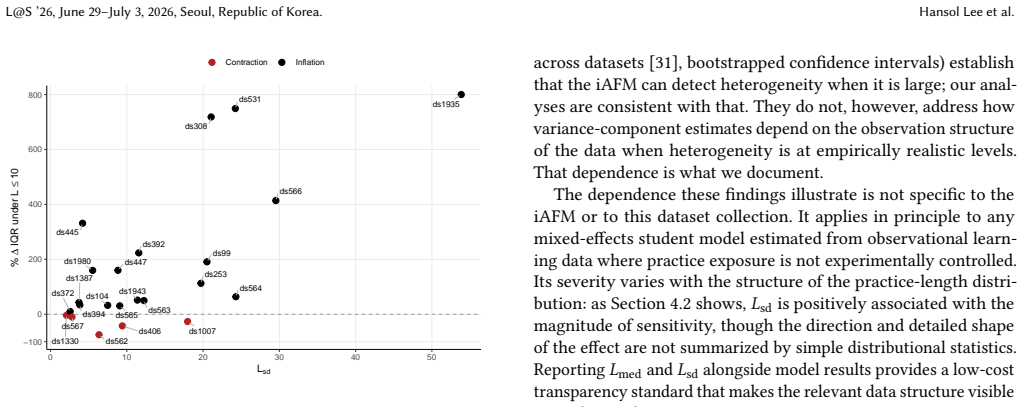
Refitting the iAFM on 26 educational datasets while truncating practice sequences at successive fixed depths, holding the set of students and knowledge components constant, produces large increases in the estimated interquartile range of student learning rates. The median inflation reaches 75 percent at a cap of ten opportunities and 205 percent at a cap of five, with individual datasets showing effects from negligible to 17-fold. This pattern diverges from predictions under ignorable truncation and points to three candidate mechanisms: informative observation length, functional-form misspecification, or identification weakness from sparse per-pair data. Observational analysis alone cannot区分
What carries the argument
Systematic truncation of practice sequences at fixed depths to test the ignorability assumption in mixed-effects estimation of the individual Additive Factors Model.
If this is right
- Conclusions about learning-rate homogeneity depend on the distribution of observed practice lengths and require explicit reporting of those lengths.
- Mixed-effects models applied to observational learning data can be sensitive to the sparsity created by early truncation.
- The three candidate mechanisms—informative observation length, functional-form misspecification, and identification weakness from sparse per-pair data—remain possible explanations for the observed sensitivity.
- Further analysis is needed to distinguish among those mechanisms before the regularity can be treated as robust.
Where Pith is reading between the lines
- If observation length is informative, then estimates from full sequences would show even greater learning-rate heterogeneity than the already-inflated truncated results.
- Similar truncation sensitivity may affect longitudinal mixed-effects analyses in other domains that rely on observational sequences of varying lengths.
- Educational platforms could reduce bias by either collecting longer sequences per student-skill pair or modeling the process that determines sequence length.
- A direct test could compare iAFM estimates on naturally complete versus artificially truncated versions of datasets where some students already have very long sequences.
Load-bearing premise
That systematic truncation of practice sequences at fixed depths provides a valid test of the ignorability assumption without introducing new biases from resulting data sparsity or the specific functional form of iAFM.
What would settle it
A simulation study that generates data under known learning-rate heterogeneity and ignorable truncation, then applies the same capping procedure and checks whether the reported magnitude of IQR inflation appears.
Figures




read the original abstract
A 2023 \textit{PNAS} study by Koedinger et al. (2023) fit the individual Additive Factors Model (iAFM) to 27 educational datasets and reported an ``astonishing regularity'' in student learning rates: students vary substantially in initial knowledge but learn at remarkably similar rates with practice. We probe a largely unexamined assumption underlying this finding -- that observation length in student log data is ignorable for mixed-effects estimation -- by refitting the iAFM on 26 of the original datasets while systematically truncating practice sequences at various depths, holding the set of students and knowledge components constant. Capping at the first ten opportunities per student-skill pair inflates the median estimated IQR of student learning rates by 75\%; capping at five inflates it by 205\%, with individual datasets ranging from negligible to 17-fold. The magnitude of this sensitivity diverges from what standard estimation theory predicts under ignorable truncation, and the dataset-specific heterogeneity is substantial. Three candidate mechanisms from adjacent literatures could account for the pattern -- informative observation length, functional-form misspecification, and identification weakness from sparse per-pair data -- but observational analysis on these data alone cannot adjudicate among them. We argue that practice sequence length distributions are an unexamined property of mixed-effects estimation on observational learning data, deserving explicit reporting before conclusions about learning-rate heterogeneity are drawn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript revisits the 'astonishing regularity' reported by Koedinger et al. (2023) of substantial between-student variation in initial knowledge but low variation in learning rates, obtained by fitting the individual Additive Factors Model (iAFM) to 27 educational datasets. The authors test the assumption that observation length is ignorable for mixed-effects estimation by refitting the iAFM to 26 of those datasets after systematically truncating each student-skill pair's practice sequence at fixed depths (e.g., first 5 or 10 opportunities), while holding the sets of students and knowledge components fixed. They report that truncation at 10 opportunities inflates the median estimated IQR of student learning rates by 75% and at 5 opportunities by 205%, with dataset-specific inflations ranging from negligible to 17-fold. The observed sensitivity diverges from predictions under ignorable truncation, and the authors conclude that practice-sequence length distributions constitute an unexamined property of such analyses that should be explicitly reported before drawing conclusions about learning-rate heterogeneity.
Significance. If the reported sensitivity is not an artifact of the truncation procedure itself, the work identifies a previously under-examined methodological vulnerability in mixed-effects modeling of observational learning data. It supplies concrete, multi-dataset empirical evidence that conclusions about learning-rate homogeneity can be highly sensitive to sequence length, thereby strengthening the case for routine reporting of opportunity-length distributions as a standard practice in educational data mining and learning analytics.
major comments (2)
- [Discussion of candidate mechanisms] The truncation protocol necessarily produces extreme sparsity (many student-skill pairs reduced to 1–3 observations). In random-slopes mixed models, REML/ML estimators for the slope variance component are known to be upward-biased or unstable under such conditions, especially when random intercepts are also estimated and the design matrix is ill-conditioned. The manuscript notes divergence from 'standard estimation theory' but supplies neither a derivation nor a simulation study under the exact iAFM likelihood and the empirical opportunity-length distributions to quantify how much of the observed 75–205% median IQR inflation is attributable to this sparsity-induced bias rather than to any violation of ignorability in the uncapped data. This distinction is load-bearing for the central claim that sequence length is non-ignorable.
- [Discussion] The paper correctly lists three candidate mechanisms (informative observation length, functional-form misspecification, and identification weakness from sparse per-pair data) but performs no quantitative adjudication among them. Without targeted simulations that isolate each mechanism while preserving the empirical marginal distributions of sequence lengths, the recommendation to report sequence-length distributions rests on an ambiguous attribution and cannot yet be translated into a specific diagnostic or correction procedure.
minor comments (2)
- [Methods] Clarify in the methods section the precise criterion used to drop the 27th dataset and whether any sensitivity checks were performed on the excluded dataset.
- [Abstract] The abstract states that the magnitude 'diverges from what standard estimation theory predicts under ignorable truncation'; a brief parenthetical reference to the relevant variance-component bias results (e.g., from linear mixed-model literature) would make this claim more immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and limitations of our analysis. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Discussion of candidate mechanisms] The truncation protocol necessarily produces extreme sparsity (many student-skill pairs reduced to 1–3 observations). In random-slopes mixed models, REML/ML estimators for the slope variance component are known to be upward-biased or unstable under such conditions, especially when random intercepts are also estimated and the design matrix is ill-conditioned. The manuscript notes divergence from 'standard estimation theory' but supplies neither a derivation nor a simulation study under the exact iAFM likelihood and the empirical opportunity-length distributions to quantify how much of the observed 75–205% median IQR inflation is attributable to this sparsity-induced bias rather than to any violation of ignorability in the uncapped data. This distinction is load-bearing for the central claim that sequence length is non-ignorable.
Authors: We agree that sparsity induced by truncation can contribute to upward bias in variance-component estimates for random-slopes models. The manuscript documents that the magnitude of inflation across 26 datasets diverges from what would be expected under ignorable truncation, but we did not supply an analytic derivation or simulation isolating the bias term because the primary contribution is the multi-dataset empirical demonstration itself. We will add a paragraph in the Discussion explicitly acknowledging that a portion of the observed inflation may reflect finite-sample estimation instability rather than non-ignorability alone, and that targeted simulations under the iAFM likelihood would be a valuable extension. revision: partial
-
Referee: [Discussion] The paper correctly lists three candidate mechanisms (informative observation length, functional-form misspecification, and identification weakness from sparse per-pair data) but performs no quantitative adjudication among them. Without targeted simulations that isolate each mechanism while preserving the empirical marginal distributions of sequence lengths, the recommendation to report sequence-length distributions rests on an ambiguous attribution and cannot yet be translated into a specific diagnostic or correction procedure.
Authors: We accept that the current observational design cannot quantitatively separate the three mechanisms. Our recommendation to report opportunity-length distributions is deliberately mechanism-agnostic: the empirical result that truncation at 5 or 10 opportunities materially alters learning-rate IQR estimates in the majority of datasets is sufficient to establish that these distributions are a relevant reporting item, irrespective of which mechanism predominates. We will revise the final paragraph of the Discussion to state that the recommendation is a minimal, low-cost safeguard pending future methodological work that could include the isolating simulations the referee describes. revision: partial
Circularity Check
No circularity: empirical refitting on truncated sequences is self-contained
full rationale
The paper conducts a direct empirical sensitivity analysis by systematically truncating the 26 datasets at fixed opportunity depths (5 or 10), holding students and knowledge components fixed, then refitting the iAFM mixed-effects model and reporting the resulting changes in median IQR of student learning-rate estimates. This procedure is a straightforward computational experiment on the observed data; the reported inflation figures (75% and 205%) are the literal output of the refits rather than any quantity derived by construction from fitted parameters, self-citations, or ansatzes. No step invokes a uniqueness theorem, renames a known result, or reduces the central claim to an input by definition. The note that the observed sensitivity diverges from standard estimation theory is an observation, not a derivation that closes on itself. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Observation length in student log data is ignorable for mixed-effects estimation of learning rates in iAFM
- standard math Standard mixed-effects estimation theory applies to the truncated datasets
Reference graph
Works this paper leans on
-
[1]
Vincent Aleven, Elmar Stahl, Silke Schworm, Frank Fischer, and Raven Wallace
-
[2]
Help seeking and help design in interactive learning environments.Review of Educational Research73, 3 (2003), 277–320
2003
-
[3]
Ryan S. J. d. Baker. 2007. Modeling and understanding students’ off-task behavior in intelligent tutoring systems. InProceedings of the ACM CHI Conference on Human Factors in Computing Systems. 1059–1068
2007
-
[4]
Ryan S. J. d. Baker, Albert T. Corbett, Kenneth R. Koedinger, Shelley Evenson, Ido Roll, Angela Z. Wagner, Meghan Naim, Jay Raspat, Daniel J. Baker, and Joseph E. Beck. 2006. Adapting to when students game an intelligent tutoring system. InProceedings of the International Conference on Intelligent Tutoring Systems. Springer, 392–401
2006
-
[5]
Douglas Bates, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models using lme4.Journal of Statistical Software67, 1 (2015), 1–48
2015
-
[6]
Beck and Yue Gong
Joseph E. Beck and Yue Gong. 2013. Wheel-spinning: Students who fail to master a skill. InProceedings of the International Conference on Artificial Intelligence in Education. Springer, 431–440
2013
-
[7]
Block and Robert B
James H. Block and Robert B. Burns. 1976. Mastery learning.Review of Research in Education4 (1976), 3–49
1976
-
[8]
Hao Cen, Kenneth Koedinger, and Brian Junker. 2006. Learning Factors Analysis: a general method for cognitive model evaluation and improvement. InProceedings of the International Conference on Intelligent Tutoring Systems. Springer, 164–175
2006
-
[9]
Corbett and John R
Albert T. Corbett and John R. Anderson. 1994. Knowledge tracing: modeling the acquisition of procedural knowledge.User Modeling and User-Adapted Interaction 4, 4 (1994), 253–278
1994
-
[10]
Daniels and Joseph W
Michael J. Daniels and Joseph W. Hogan. 2008.Missing Data in Longitudinal Studies: Strategies for Bayesian Modeling and Sensitivity Analysis. Chapman and Hall/CRC
2008
-
[11]
Peter Diggle and Michael G. Kenward. 1994. Informative drop-out in longitudinal data analysis.Journal of the Royal Statistical Society: Series C (Applied Statistics) 43, 1 (1994), 49–73
1994
-
[12]
Shayan Doroudi and Emma Brunskill. 2017. The misidentified identifiability problem of Bayesian knowledge tracing. InProceedings of the 10th International Conference on Educational Data Mining (EDM)
2017
-
[13]
Evans, Scott D
Nathan J. Evans, Scott D. Brown, Douglas J. K. Mewhort, and Andrew Heathcote
-
[14]
Refining the law of practice.Psychological Review125, 4 (2018), 592–605
2018
-
[15]
Theodore W. Frick. 1990. A comparison of three decision models for adapting the length of computer-based mastery tests.Journal of Educational Computing Research6, 4 (1990), 479–513
1990
-
[16]
Andrew Heathcote, Scott Brown, and D. J. K. Mewhort. 2000. The power law repealed: the case for an exponential law of practice.Psychonomic Bulletin & Review7, 2 (2000), 185–207
2000
-
[17]
Hogan, Jason Roy, and Christina Korkontzelou
Joseph W. Hogan, Jason Roy, and Christina Korkontzelou. 2004. Handling dropout in longitudinal studies.Statistics in Medicine23, 9 (2004), 1455–1497
2004
-
[18]
Bolt, and Xiangyi Liao
Qi Huang, Daniel M. Bolt, and Xiangyi Liao. 2025. Theory-driven IRT modeling of vocabulary development: Matthew effects and the case for unipolar IRT.Journal of Educational Measurement(2025)
2025
-
[19]
Koedinger, and Markus Gross
Tanja Käser, Kenneth R. Koedinger, and Markus Gross. 2014. Different parame- ters – same prediction: an analysis of learning curves. InProceedings of the 7th International Conference on Educational Data Mining. 52–59. L@S ’26, June 29–July 3, 2026, Seoul, Republic of Korea. Hansol Lee et al
2014
-
[20]
Koedinger, Ryan S
Kenneth R. Koedinger, Ryan S. J. d. Baker, Kyle Cunningham, Alida Skogsholm, Brett Leber, and John Stamper. 2010. A data repository for the EDM community: the PSLC DataShop. InHandbook of Educational Data Mining, Cristóbal Romero, Sebastián Ventura, Mykola Pechenizkiy, and Ryan S. J. d. Baker (Eds.). CRC Press, 43–56
2010
-
[21]
Kenneth R Koedinger, Emma Brunskill, Ryan SJd Baker, Elizabeth A McLaughlin, and John Stamper. 2013. New potentials for data-driven intelligent tutoring system development and optimization.Ai Magazine34, 3 (2013), 27–41
2013
-
[22]
Koedinger, Paulo F
Kenneth R. Koedinger, Paulo F. Carvalho, Ran Liu, and Elizabeth A. McLaughlin
-
[23]
An astonishing regularity in student learning rate.Proceedings of the National Academy of Sciences120, 13 (2023), e2221311120. doi:10.1073/pnas. 2221311120
-
[24]
Roderick J. A. Little. 1993. Pattern-mixture models for multivariate incomplete data.J. Amer. Statist. Assoc.88, 421 (1993), 125–134
1993
-
[25]
Roderick J. A. Little. 1995. Modeling the drop-out mechanism in repeated- measures studies.J. Amer. Statist. Assoc.90, 431 (1995), 1112–1121
1995
-
[26]
Roderick J. A. Little and Donald B. Rubin. 2019.Statistical Analysis with Missing Data(3rd ed.). John Wiley & Sons
2019
-
[27]
Koedinger
Ran Liu and Kenneth R. Koedinger. 2017. Towards reliable and valid measurement of individualized student parameters. InProceedings of the 10th International Conference on Educational Data Mining. 135–142
2017
-
[28]
Rosenbloom
Allen Newell and Paul S. Rosenbloom. 1981. Mechanisms of skill acquisition and the law of practice. InCognitive Skills and Their Acquisition, John R. Anderson (Ed.). Psychology Press, 1–55
1981
-
[29]
Guibas, and Jascha Sohl-Dickstein
Chris Piech, Jonathan Bassen, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas J. Guibas, and Jascha Sohl-Dickstein. 2015. Deep knowledge tracing. In Advances in Neural Information Processing Systems, Vol. 28
2015
-
[30]
Raudenbush and Anthony S
Stephen W. Raudenbush and Anthony S. Bryk. 2002.Hierarchical Linear Models: Applications and Data Analysis Methods(2nd ed.). Sage Publications
2002
-
[31]
2012.Joint Models for Longitudinal and Time-to-Event Data: With Applications in R
Dimitris Rizopoulos. 2012.Joint Models for Longitudinal and Time-to-Event Data: With Applications in R. CRC Press
2012
-
[32]
G. K. Robinson. 1991. That BLUP is a good thing: the estimation of random effects.Statist. Sci.6, 1 (1991), 15–32
1991
-
[33]
Donald B. Rubin. 1976. Inference and missing data.Biometrika63, 3 (1976), 581–592
1976
-
[34]
Astonishing Regularity in Student Learning Rate
Mary Ann Simpson, Kole A. Norberg, and Stephen E. Fancsali. 2024. Replicating an “Astonishing Regularity in Student Learning Rate”. InProceedings of the 17th International Conference on Educational Data Mining. 420–425
2024
-
[35]
Tsiatis and Marie Davidian
Anastasios A. Tsiatis and Marie Davidian. 2004. Joint modeling of longitudinal and time-to-event data: an overview.Statistica Sinica14 (2004), 809–834
2004
-
[36]
Kurt VanLehn. 2006. The behavior of tutoring systems.International Journal of Artificial Intelligence in Education16, 3 (2006), 227–265
2006
-
[37]
Jaroslav Čechák and Radek Pelánek. 2019. Item ordering biases in educational data. InProceedings of the International Conference on Artificial Intelligence in Education (Lecture Notes in Computer Science). 48–58
2019
-
[38]
Herbert J Walberg and Shiow-Ling Tsai. 1983. Matthew effects in education. American educational research journal20, 3 (1983), 359–373
1983
-
[39]
Yi, and Yangxin Huang
Lang Wu, Wei Liu, Grace Y. Yi, and Yangxin Huang. 2012. Analysis of longitudinal and survival data: joint modeling, inference methods, and issues.Journal of Probability and Statistics2012 (2012), 640153
2012
-
[40]
Wu and Raymond J
Margaret C. Wu and Raymond J. Carroll. 1988. Estimation and comparison of changes in the presence of informative right censoring by modeling the censoring process.Biometrics44, 1 (1988), 175–188
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.