Recognition: 2 theorem links
· Lean TheoremDual-branch Robust Unlearnable Examples
Pith reviewed 2026-05-10 15:44 UTC · model grok-4.3
The pith
DUNE achieves robust unlearnability by separately optimizing perturbations in spatial and color domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
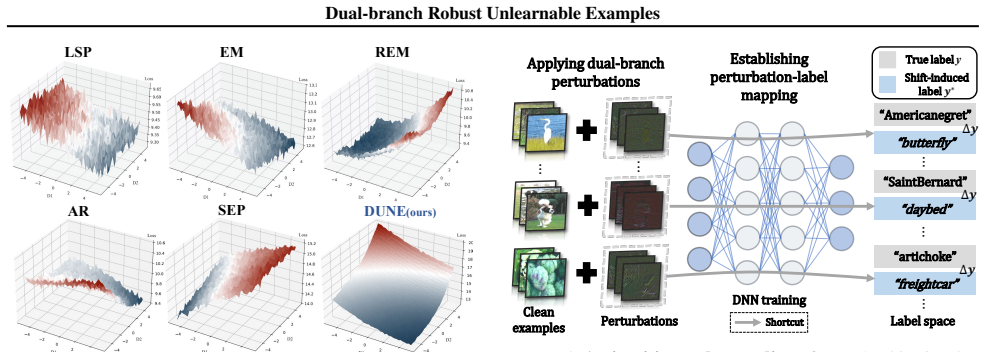
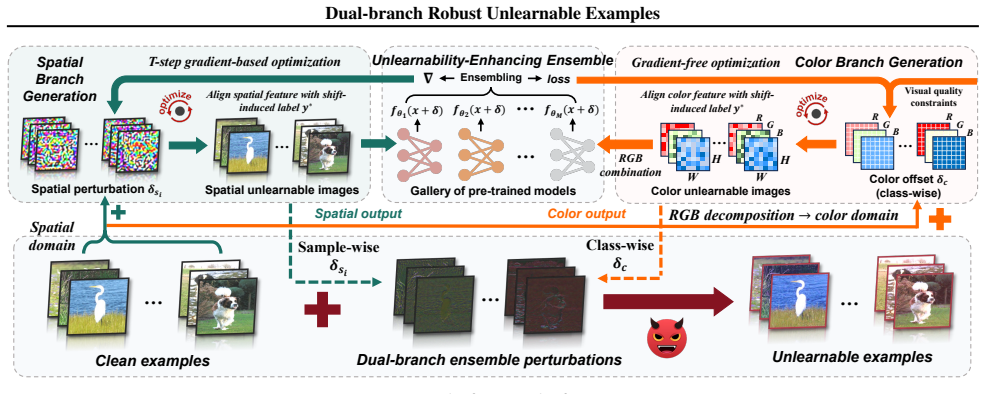
DUNE separately optimizes perturbations in the spatial and color domains to establish the mapping between perturbations and shift-induced labels. This extends the perturbation domain to increase noise intensity for improving robustness and drives the models to learn perturbation-oriented features with degraded generalization, thereby achieving unlearnability. An unlearnability-enhancing ensemble strategy aggregates diverse pre-trained models during the dual-branch optimization.
What carries the argument
Dual-branch optimization that maps perturbations to shift-induced labels by handling spatial and color domains separately, strengthened by ensemble aggregation of pre-trained models.
If this is right
- Models trained on DUNE-protected images learn perturbation-oriented features instead of clean-image content, degrading generalization.
- Noise intensity rises because the perturbation domain now spans both spatial and color changes.
- The ensemble aggregation step strengthens unlearnability by incorporating diverse model behaviors during optimization.
- The approach delivers lower average test accuracy than twelve prior unlearnable-example schemes across seven mainstream defenses.
Where Pith is reading between the lines
- The same principle of splitting optimization across distinct image domains could be tested on other modalities such as video frames or audio spectrograms to check whether robustness gains transfer.
- Varying the number or diversity of models inside the ensemble during optimization offers a direct way to tune the strength of the unlearnability effect for different datasets.
- If the core mechanism is forcing attention onto perturbation patterns, then combining DUNE-style changes with existing differential-privacy noise might produce even stronger protection against unauthorized training.
Load-bearing premise
That dual-branch optimization in spatial and color domains combined with ensemble aggregation will reliably increase noise intensity, drive models to learn perturbation-oriented features, and maintain unlearnability against advanced defenses without introducing exploitable weaknesses.
What would settle it
A new defense that lets a model trained on DUNE examples reach test accuracy on CIFAR-10 or ImageNet comparable to training on clean images would show the robustness gain does not hold.
Figures





read the original abstract
Unlearnable examples (UEs) aim to compromise model training by injecting imperceptible perturbations to clean samples. However, existing UE schemes exhibit limited robustness against advanced defenses due to their heuristic design or narrowly scoped domain perturbations. To address this, we propose \texttt{DUNE}, a \underline{\textbf{D}}ual-branch \underline{\textbf{UN}}learnable \underline{\textbf{E}}nsemble perturbation optimization approach. Specifically, \texttt{DUNE} separately optimizes perturbations in the spatial and color domains to establish the mapping between perturbations and shift-induced labels. This design extends the perturbation domain to increase noise intensity for improving robustness and drives the models to learn perturbation-oriented features with degraded generalization, thereby achieving unlearnability. To strengthen \texttt{DUNE}'s performance, we further propose an unlearnability-enhancing ensemble strategy that aggregates diverse pre-trained models during the dual-branch optimization. Extensive experiments on benchmark datasets CIFAR-10 and ImageNet verify that \texttt{DUNE}'s robustness outperforms 12 SOTA UE schemes under 7 mainstream defenses, yielding a lower average test accuracy of 14.95\% to 50.82\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DUNE, a dual-branch unlearnable ensemble perturbation optimization approach that separately optimizes perturbations in the spatial and color domains to map perturbations to shift-induced labels, extends the perturbation domain to increase noise intensity, and aggregates diverse pre-trained models during optimization. It claims this yields more robust unlearnable examples that outperform 12 SOTA UE schemes under 7 mainstream defenses on CIFAR-10 and ImageNet, producing lower average test accuracies ranging from 14.95% to 50.82%.
Significance. If the robustness gains hold under matched perturbation budgets and verifiable optimization details, the work would advance unlearnable example generation by addressing limited robustness in prior heuristic or single-domain methods, with potential implications for data protection in ML training pipelines.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): the dual-branch optimization separately optimizes spatial and color perturbations then aggregates them, but provides no joint L_∞ or L2 constraint, renormalization step, or cross-term in the loss to ensure the summed perturbation δ = δ_spatial + δ_color remains within the imperceptibility budget. This directly risks violating the central assumption that the method reliably increases effective noise intensity without introducing separable components exploitable by advanced defenses.
- [§4] §4 (Experiments): the reported average test accuracy range of 14.95%–50.82% across 7 defenses is presented without the exact optimization equations, data exclusion rules, error bars, or ablation on the joint-norm constraint, preventing verification that the claimed superiority over 12 SOTA methods is not an artifact of mismatched perturbation budgets.
minor comments (1)
- [§3] Notation for the ensemble aggregation step and shift-induced labels is introduced without a formal definition or pseudocode, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing clarifications and committing to revisions that strengthen the presentation of the dual-branch optimization and experimental reproducibility.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the dual-branch optimization separately optimizes spatial and color perturbations then aggregates them, but provides no joint L_∞ or L2 constraint, renormalization step, or cross-term in the loss to ensure the summed perturbation δ = δ_spatial + δ_color remains within the imperceptibility budget. This directly risks violating the central assumption that the method reliably increases effective noise intensity without introducing separable components exploitable by advanced defenses.
Authors: We acknowledge that the manuscript does not explicitly describe a joint constraint or renormalization on the summed perturbation. In the implementation, each branch is independently bounded by an L_∞ norm of ε/2 before summation, followed by a final clipping operation to enforce ||δ||_∞ ≤ ε overall. We will revise §3 to include the exact optimization equations, add an explicit renormalization step after aggregation, and incorporate a cross-term in the loss that penalizes violations of the joint budget. We will also add an ablation study on the joint-norm constraint to demonstrate that the reported robustness gains hold under this enforcement and that separable components are not exploitable by the evaluated defenses. revision: yes
-
Referee: [§4] §4 (Experiments): the reported average test accuracy range of 14.95%–50.82% across 7 defenses is presented without the exact optimization equations, data exclusion rules, error bars, or ablation on the joint-norm constraint, preventing verification that the claimed superiority over 12 SOTA methods is not an artifact of mismatched perturbation budgets.
Authors: We agree that additional details are required for full reproducibility and verification. The revised manuscript will include the precise optimization equations in §3 (cross-referenced in §4), state that no training samples were excluded on either CIFAR-10 or ImageNet, report error bars computed over three independent runs with different random seeds, and add an ablation study isolating the effect of the joint-norm constraint. These changes will confirm that all comparisons use matched perturbation budgets and that the superiority over the 12 baselines is not an artifact of implementation differences. revision: yes
Circularity Check
No circularity: empirical optimization method with independent experimental validation
full rationale
The paper presents DUNE as a proposed dual-branch optimization procedure that separately perturbs spatial and color domains to map perturbations onto shift-induced labels, with the explicit goal of increasing effective noise and forcing perturbation-oriented features. Claims of improved robustness are supported solely by empirical measurements on CIFAR-10 and ImageNet against 12 SOTA baselines under 7 defenses; no equations, fitted parameters, or first-principles derivations are shown that reduce the performance outcome to the optimization inputs by construction. No self-citations appear as load-bearing premises, no uniqueness theorems are imported, and no ansatz is smuggled via prior work. The method is therefore self-contained as an engineering design whose success is measured externally rather than asserted tautologically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient-based optimization can establish a reliable mapping from dual-domain perturbations to shift-induced labels that degrades model generalization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDUNE separately optimizes perturbations in the spatial and color domains to establish the mapping between perturbations and shift-induced labels... dual-branch optimization
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearWe decompose the joint dual-domain optimization into two independent sub-optimization problems... δu ≜ δs ⊕ δc
Reference graph
Works this paper leans on
-
[1]
A., Paleka, D., Pearce, W., Anderson, H., Terzis, A., Thomas, K., and Tramèr, F
Carlini, N., Jagielski, M., Choquette-Choo, C. A., Paleka, D., Pearce, W., Anderson, H., Terzis, A., Thomas, K., and Tramèr, F. Poisoning web-scale training datasets is practical. InPro- ceedings of the 2024 IEEE Symposium on Security and Privacy (S&P’24), pp. 407–425. IEEE,
2024
-
[2]
Imagenet: A large-scale hierarchical image database
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR’09), pp. 248–255,
2009
-
[3]
Dolatabadi, H. M., Erfani, S., and Leckie, C. The devil’s advocate: Shattering the illusion of unexploitable data using diffusion models.arXiv preprint arXiv:2303.08500,
-
[4]
Deep residual learn- ing for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learn- ing for image recognition. InProceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR’16), pp. 770–778,
2016
-
[5]
Huang, G., Liu, Z., Van Der Maaten, L., and Weinberger, K. Q. Densely connected convolutional networks. InProceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR’17), pp. 4700–4708,
2017
-
[6]
E-lpips: robust per- ceptual image similarity via random transformation ensembles
Kettunen, M., Härkönen, E., and Lehtinen, J. E-lpips: robust per- ceptual image similarity via random transformation ensembles. arXiv preprint arXiv:1906.03973,
-
[7]
Learning the unlearn- able: Adversarial augmentations suppress unlearnable example attacks,
Qin, T., Gao, X., Zhao, J., Ye, K., and Xu, C.-Z. Learning the unlearnable: Adversarial augmentations suppress unlearnable example attacks.arXiv preprint arXiv:2303.15127,
-
[8]
S., Soltanolkotabi, M., and Feizi, S
Sadasivan, V . S., Soltanolkotabi, M., and Feizi, S. Cuda: Convolution-based unlearnable datasets. InProceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR’23), pp. 3862–3871,
2023
-
[9]
Shen, X., Cai, Y ., Ning, R., Xin, C., and Wu, H. Df-logit: Data- free logic-gated backdoor attacks in vision transformers.arXiv preprint arXiv:2602.03040,
-
[10]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K. and Zisserman, A. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Trojanrobot: Physical-world backdoor attacks against vlm-based robotic manipulation
Wang, X., Hu, S., Zhang, Y ., Zhou, Z., Zhang, L. Y ., Xu, P., Wan, W., and Jin, H. Eclipse: Expunging clean-label indiscriminate poisons via sparse diffusion purification. InProceedings of the 29th European Symposium on Research in Computer Security (ESORICS’24), 2024a. Wang, X., Li, M., Liu, W., Zhang, H., Hu, S., Zhang, Y ., Zhou, Z., and Jin, H. Unlea...
-
[12]
Yu, Y ., Wang, Y ., Xia, S., Yang, W., Lu, S., Tan, Y .-P., and Kot, A. C. Purify unlearnable examples via rate-constrained varia- tional autoencoders.arXiv preprint arXiv:2405.01460, 2024a. Yu, Y ., Zheng, Q., Yang, S., Yang, W., Liu, J., Lu, S., Tan, Y .-P., Lam, K.-Y ., and Kot, A. Unlearnable examples detection via iterative filtering. InProceedings o...
-
[13]
Y ., Zhou, Z., Wang, X., Zhang, Y ., and Chen, C
Zhang, H., Hu, S., Wang, Y ., Zhang, L. Y ., Zhou, Z., Wang, X., Zhang, Y ., and Chen, C. Detector collapse: Backdooring object detection to catastrophic overload or blindness.arXiv preprint arXiv:2404.11357,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.