Recognition: 3 theorem links
· Lean TheoremStable GFlowNets with Probabilistic Guarantees
Pith reviewed 2026-05-08 19:16 UTC · model grok-4.3
The pith
Bounded trajectory balance loss in GFlowNets implies small total variation distance to the target reward distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes converse guarantees by deriving loss-to-TV bounds that certify global fidelity from bounded trajectory balance losses. It first demonstrates sensitivity of GFlowNet objectives, where small TV distance does not preclude large loss. The derived inequalities then show that controlling the trajectory balance loss directly limits the total variation distance between the learned sampling distribution and the target. Stable GFlowNets uses these results to stabilize training and empirically achieves reduced loss spikes together with higher distributional fidelity.
What carries the argument
loss-to-TV bounds: inequalities that convert an upper limit on trajectory balance loss into an upper limit on total variation distance between the GFlowNet sampling distribution and the target reward distribution.
If this is right
- Keeping trajectory balance loss bounded during training guarantees that the generated distribution stays close to the target in total variation.
- Training procedures can now monitor loss values to certify distributional fidelity without directly computing TV distance.
- Stable GFlowNets reduces loss spikes and mode collapse by enforcing the loss bounds in practice.
- The same bounds apply to any GFlowNet variant that uses the trajectory balance loss in the stated form.
Where Pith is reading between the lines
- The bounds might extend to other GFlowNet losses if similar sensitivity analyses are performed.
- The stabilization technique could be tested on larger or more structured reward landscapes to check scalability.
- If the bounds are tight, they could guide the design of new loss functions that are easier to keep small while still enforcing fidelity.
Load-bearing premise
The bounds hold only for the exact mathematical form of the trajectory balance objective and GFlowNet sampling process stated in the paper.
What would settle it
A concrete counter-example in which the trajectory balance loss remains below the derived threshold yet the measured total variation distance between learned and target distributions exceeds the bound predicted by the inequalities.
Figures



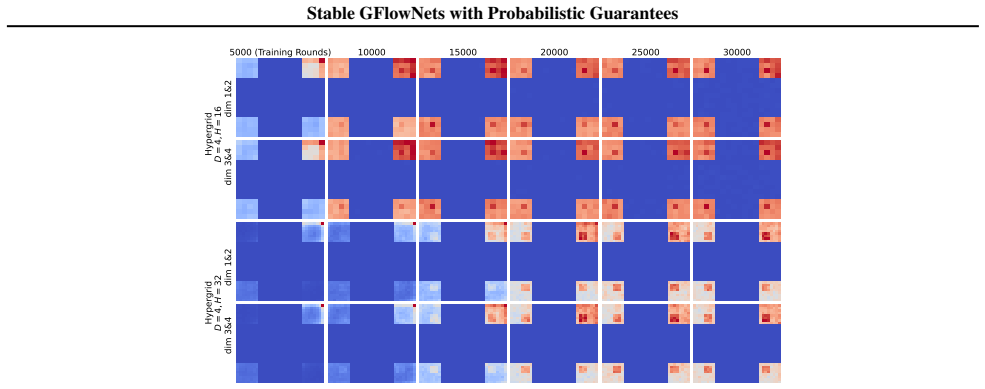

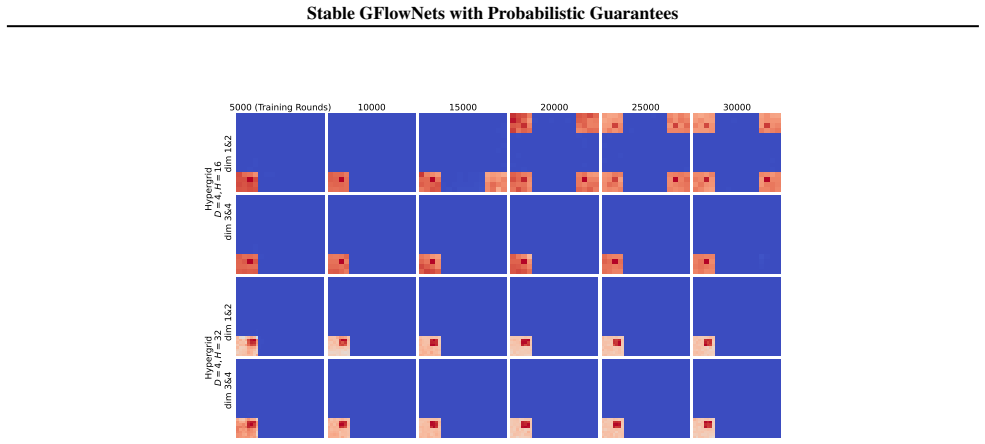


read the original abstract
Generative Flow Networks (GFlowNets) learn to sample states proportional to an unnormalized reward. Despite their theoretical promise, practical training is often unstable, exhibiting severe loss spikes and mode collapse. To tackle this, we first assess the sensitivity of GFlowNet objectives, demonstrating that a small Total Variation (TV) distance between the learned and target distributions does not preclude unbounded training loss. Motivated by this mismatch, we establish converse guarantees by deriving loss-to-TV bounds that certify global fidelity from bounded trajectory balance losses. Lastly, we propose Stable GFlowNets, an algorithm that leverages our theoretical results to stabilize training, and empirically demonstrate improved training behavior and superior distributional fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes the sensitivity of GFlowNet objectives to total variation (TV) distance, showing that small TV can coexist with unbounded losses. It derives converse loss-to-TV bounds from the trajectory balance objective to certify global distributional fidelity when losses are bounded. It then introduces the Stable GFlowNets algorithm that exploits these bounds for stabilization and reports empirical gains in training stability and sample fidelity over standard GFlowNet training.
Significance. If the loss-to-TV bounds are valid and the algorithm preserves the original GFlowNet sampling guarantees, the work supplies a principled route to reliable training of GFlowNets on complex reward landscapes. The combination of sensitivity analysis, explicit bounds, and a practical stabilization procedure addresses a documented practical weakness in the GFlowNet literature.
major comments (2)
- [§4] §4 (loss-to-TV bounds): the derivation of the converse guarantee appears to rely on a uniform bound on the trajectory balance loss across all trajectories; the manuscript should state whether this uniform bound is assumed or derived from the finite-state or finite-horizon setting, because violation of uniformity would invalidate the global TV certificate.
- [§5] §5 (Stable GFlowNets algorithm): the clipping or re-weighting step that enforces the bounded-loss regime must be shown not to alter the fixed point of the original GFlowNet objective; otherwise the fidelity guarantee no longer applies to the modified sampler.
minor comments (2)
- [§6] The experimental section should report the precise hyper-parameter ranges and random seeds used for the baseline comparisons; without them it is difficult to assess whether the reported stability gains are robust.
- [§2] Notation for the trajectory balance loss (Eq. (3) or equivalent) should be aligned with the standard GFlowNet literature to avoid confusion for readers familiar with the original TB objective.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and arguments.
read point-by-point responses
-
Referee: [§4] §4 (loss-to-TV bounds): the derivation of the converse guarantee appears to rely on a uniform bound on the trajectory balance loss across all trajectories; the manuscript should state whether this uniform bound is assumed or derived from the finite-state or finite-horizon setting, because violation of uniformity would invalidate the global TV certificate.
Authors: We agree that the converse loss-to-TV bounds require a uniform bound on the trajectory balance loss to certify global fidelity. This uniform bound is assumed (rather than derived) as a prerequisite for the certificate; it holds automatically in the finite-state and finite-horizon regimes analyzed in the paper because the trajectory space is finite and each loss term is finite. We will revise §4 to state the assumption explicitly, note that it is satisfied under the finite settings of the theorems, and discuss that the global TV guarantee is conditional on the losses remaining uniformly bounded. revision: yes
-
Referee: [§5] §5 (Stable GFlowNets algorithm): the clipping or re-weighting step that enforces the bounded-loss regime must be shown not to alter the fixed point of the original GFlowNet objective; otherwise the fidelity guarantee no longer applies to the modified sampler.
Authors: We thank the referee for highlighting this requirement. The clipping operation in Stable GFlowNets is applied only during training to cap loss spikes and is inactive once losses fall below the threshold. Consequently, the fixed points of the original trajectory-balance objective are preserved: at any stationary point the loss is zero on all trajectories, rendering clipping irrelevant. We will add a short proposition in the revised §5 formally showing that the modified updates share the same fixed points as the unmodified objective, thereby ensuring the fidelity guarantees continue to apply. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central contribution is a mathematical derivation of loss-to-TV bounds from the definitions of GFlowNet trajectory balance losses and total variation distance. This proceeds from the stated sensitivity analysis (small TV not implying bounded loss) to converse bounds that certify fidelity from bounded losses, without reducing to fitted parameters, self-referential normalizations, or load-bearing self-citations. The subsequent algorithm is motivated by but not equivalent to these bounds. No steps match the enumerated circularity patterns; the derivation is self-contained against the loss definitions and external TV metric.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.LogicAsFunctionalEquationwashburn_uniqueness_aczel (J=½(x+x⁻¹)−1) unclearwe derive loss-to-TV bounds that certify global fidelity from bounded trajectory balance losses ... TV(P_T, π_target) ≤ 1 − exp(−2c)
-
Foundation.AlphaCoordinateFixation / Cost.CostAlphaLogcost_alpha_one_eq_jcost unclearL_TB(τ) = (log[ZP_F(τ)/(R(x)Π P_B)])² ; bounds derived via exp(±c) ratio control
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
Learning diverse attacks on large language models for robust red-teaming and safety tuning , author =. International Conference on Learning Representations , year =
-
[2]
Jain, Moksh and Bengio, Emmanuel and Hernandez-Garcia, Alex and Rector-Brooks, Jarrid and Dossou, Bonaventure F. P. and Ekbote, Chanakya Ajit and Fu, Jie and Zhang, Tianyu and Kilgour, Michael and Zhang, Dinghuai and Simine, Lena and Das, Payel and Bengio, Yoshua , booktitle =. Biological Sequence Design with
-
[3]
Hu and Mo Tiwari and Emmanuel Bengio , title =
Yoshua Bengio and Salem Lahlou and Tristan Deleu and Edward J. Hu and Mo Tiwari and Emmanuel Bengio , title =. Journal of Machine Learning Research , year =
-
[4]
2023 , series =
A theory of continuous generative flow networks , author =. 2023 , series =
2023
-
[5]
Advances in Neural Information Processing Systems , year =
Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation , author =. Advances in Neural Information Processing Systems , year =
-
[6]
Towards Understanding and Improving
Shen, Max W and Bengio, Emmanuel and Hajiramezanali, Ehsan and Loukas, Andreas and Cho, Kyunghyun and Biancalani, Tommaso , booktitle =. Towards Understanding and Improving
-
[7]
2017 , booktitle =
Proximal Policy Optimization Algorithms , author =. 2017 , booktitle =
2017
-
[8]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers and Ariel Kwiatkowski and Jordan K. Terry and Gianluca De Cola and Tristan Deleu and Manuel Goul. Gymnasium:. arXiv preprint arXiv:2407.17032 , year =
work page internal anchor Pith review arXiv
-
[9]
Trajectory balance: Improved credit assignment in
Malkin, Nikolay and Jain, Moksh and Bengio, Emmanuel and Sun, Chen and Bengio, Yoshua , booktitle =. Trajectory balance: Improved credit assignment in
-
[10]
Learning
Madan, Kanika and Rector-Brooks, Jarrid and Korablyov, Maksym and Bengio, Emmanuel and Jain, Moksh and Nica, Andrei Cristian and Bosc, Tom and Bengio, Yoshua and Malkin, Nikolay , booktitle =. Learning
-
[11]
Robust Scheduling with
David W Zhang and Corrado Rainone and Markus Peschl and Roberto Bondesan , booktitle =. Robust Scheduling with
-
[12]
Let the Flows Tell: Solving Graph Combinatorial Problems with
Zhang, Dinghuai and Dai, Hanjun and Malkin, Nikolay and Courville, Aaron C and Bengio, Yoshua and Pan, Ling , booktitle =. Let the Flows Tell: Solving Graph Combinatorial Problems with
-
[13]
International Conference on Learning Representations , year =
Generative Augmented Flow Networks , author =. International Conference on Learning Representations , year =
-
[14]
Advances in Neural Information Processing Systems , editor =
Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation , author =. Advances in Neural Information Processing Systems , editor =
-
[15]
International Conference on Learning Representations , year =
Pre-Training and Fine-Tuning Generative Flow Networks , author =. International Conference on Learning Representations , year =
-
[16]
International Conference on Learning Representations , year =
Reinforcement Learning with Sparse Rewards using Guidance from Offline Demonstration , author =. International Conference on Learning Representations , year =
-
[17]
and Harada, Daishi and Russell, Stuart J
Ng, Andrew Y. and Harada, Daishi and Russell, Stuart J. , title =. 1999 , booktitle =
1999
-
[18]
Advances in Neural Information Processing Systems , year =
Hindsight Experience Replay , author =. Advances in Neural Information Processing Systems , year =
-
[19]
Advances in Neural Information Processing Systems , year =
Exploration-Guided Reward Shaping for Reinforcement Learning under Sparse Rewards , author =. Advances in Neural Information Processing Systems , year =
-
[20]
International Conference on Machine Learning , year =
GFlowNet Training by Policy Gradients , author =. International Conference on Machine Learning , year =
-
[21]
Artificial Intelligence , year =
Reward is enough , author =. Artificial Intelligence , year =
-
[22]
International Conference on Artificial Intelligence and Statistics , year =
Generative Flow Networks as Entropy-Regularized RL , author =. International Conference on Artificial Intelligence and Statistics , year =
-
[23]
Better training of
Pan, Ling and Malkin, Nikolay and Zhang, Dinghuai and Bengio, Yoshua , booktitle =. Better training of
-
[24]
International Conference on Learning Representations , year =
Tom Schaul and John Quan and Ioannis Antonoglou and David Silver , title =. International Conference on Learning Representations , year =
-
[25]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards , author =. arXiv preprint arXiv:1707.08817 , year =
-
[26]
Pessimistic Backward Policy for
Jang, Hyosoon and Jang, Yunhui and Kim, Minsu and Park, Jinkyoo and Ahn, Sungsoo , booktitle =. Pessimistic Backward Policy for
-
[27]
International Conference on Learning Representations , year=
Local search GFlowNets , author=. International Conference on Learning Representations , year=
-
[28]
International Conference on Learning Representations , year=
Large-scale study of curiosity-driven learning , author=. International Conference on Learning Representations , year=
-
[29]
torchgfn: A
Lahlou, Salem and Viviano, Joseph D and Schmidt, Victor and Bengio, Yoshua , booktitle=. torchgfn: A
-
[30]
International Conference on Learning Representations , year =
Hierarchical reinforcement learning by discovering intrinsic options , author =. International Conference on Learning Representations , year =
-
[31]
Looking Backward: Retrospective Backward Synthesis for Goal-Conditioned
Haoran He and Can Chang and Huazhe Xu and Ling Pan , booktitle =. Looking Backward: Retrospective Backward Synthesis for Goal-Conditioned
-
[32]
Transactions on Machine Learning Research , year =
Evolution Guided Generative Flow Networks , author =. Transactions on Machine Learning Research , year =
-
[33]
NeurIPS Workshop on System-2 Reasoning at Scale , year =
Proof Flow: Preliminary Study on Generative Flow Network Language Model Tuning for Formal Reasoning , author =. NeurIPS Workshop on System-2 Reasoning at Scale , year =
-
[34]
Distributional
Zhang, Dinghuai and Pan, Ling and Chen, Ricky TQ and Courville, Aaron and Bengio, Yoshua , booktitle =. Distributional
-
[35]
Thompson Sampling for Improved Exploration in
Rector-Brooks, Jarrid and Madan, Kanika and Jain, Moksh and Korablyov, Maksym and Liu, Cheng-Hao and Chandar, Sarath and Malkin, Nikolay and Bengio, Yoshua , booktitle=. Thompson Sampling for Improved Exploration in
-
[36]
Advances in Neural Information Processing Systems , year=
Improved off-policy training of diffusion samplers , author=. Advances in Neural Information Processing Systems , year=
-
[37]
An empirical study of the effectiveness of using a replay buffer on mode discovery in
Vemgal, Nikhil and Lau, Elaine and Precup, Doina , booktitle=. An empirical study of the effectiveness of using a replay buffer on mode discovery in
-
[38]
Learning to scale logits for temperature-conditional
Kim, Minsu and Ko, Joohwan and Yun, Taeyoung and Zhang, Dinghuai and Pan, Ling and Kim, Woochang and Park, Jinkyoo and Bengio, Emmanuel and Bengio, Yoshua , booktitle=. Learning to scale logits for temperature-conditional
-
[39]
International Conference on Learning Representations , year=
Adaptive teachers for amortized samplers , author=. International Conference on Learning Representations , year=
-
[40]
Towards Improving Exploration through Sibling Augmented
Madan, Kanika and Lamb, Alex and Bengio, Emmanuel and Berseth, Glen and Bengio, Yoshua , booktitle=. Towards Improving Exploration through Sibling Augmented
-
[41]
International Conference on Learning Representations , year=
Exploration by random network distillation , author=. International Conference on Learning Representations , year=
-
[42]
Science , year=
Optimization by simulated annealing , author=. Science , year=
-
[43]
Statistics and computing , year=
Annealed importance sampling , author=. Statistics and computing , year=
-
[44]
Advances in neural information processing systems , year=
Generative modeling by estimating gradients of the data distribution , author=. Advances in neural information processing systems , year=
-
[45]
Transactions on Machine Learning Research , year =
TacoGFN: Target-conditioned GFlownet for structure-based drug design , author=. Transactions on Machine Learning Research , year =
-
[46]
Ant colony sampling with
Kim, Minsu and Choi, Sanghyeok and Kim, Hyeonah and Son, Jiwoo and Park, Jinkyoo and Bengio, Yoshua , booktitle=. Ant colony sampling with
-
[47]
Order-Preserving
Yihang Chen and Lukas Mauch , booktitle=. Order-Preserving
-
[48]
International Conference on Learning Representations , year =
Diffusion generative flow samplers: Improving learning signals through partial trajectory optimization , author=. International Conference on Learning Representations , year =
-
[49]
Lau, Elaine and Vemgal, Nikhil and Precup, Doina and Bengio, Emmanuel , booktitle=
-
[50]
Advances in neural information processing systems , year=
Improved techniques for training gans , author=. Advances in neural information processing systems , year=
-
[51]
International Conference on Learning Representations , year =
Unrolled generative adversarial networks , author=. International Conference on Learning Representations , year =
-
[52]
Advances in Neural Information Processing Systems , year=
Rgfn: Synthesizable molecular generation using gflownets , author=. Advances in Neural Information Processing Systems , year=
-
[53]
Digital Discovery , year=
Gflownets for ai-driven scientific discovery , author=. Digital Discovery , year=
-
[54]
Intelligent data analysis , year=
Toward accurate dynamic time warping in linear time and space , author=. Intelligent data analysis , year=
-
[55]
International Conference on Artificial Intelligence and Statistics , year=
Generative flow networks as entropy-regularized rl , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[56]
Advances in Neural Information Processing Systems , year=
On divergence measures for training gflownets , author=. Advances in Neural Information Processing Systems , year=
-
[57]
International Conference on Learning Representations , year=
Beyond squared error: Exploring loss design for enhanced training of generative flow networks , author=. International Conference on Learning Representations , year=
-
[58]
International Conference on Learning Representations , year=
Optimizing backward policies in GFlownets via trajectory likelihood maximization , author=. International Conference on Learning Representations , year=
-
[59]
Advances in neural information processing systems , year=
Qgfn: Controllable greediness with action values , author=. Advances in neural information processing systems , year=
-
[60]
Advances in Neural Information Processing Systems , year=
Genetic-guided GFlowNets for sample efficient molecular optimization , author=. Advances in Neural Information Processing Systems , year=
-
[61]
AdaLead: A simple and robust adaptive greedy search algorithm for sequence design , author=
-
[62]
International Conference on Learning Representations , year=
When do GFlowNets learn the right distribution? , author=. International Conference on Learning Representations , year=
-
[63]
arXiv preprint arXiv:2505.02035 , year=
Secrets of GFlowNets' Learning Behavior: A Theoretical Study , author=. arXiv preprint arXiv:2505.02035 , year=
-
[64]
AI for Accelerated Materials Design-NeurIPS 2023 Workshop , year=
Hierarchical gflownet for crystal structure generation , author=. AI for Accelerated Materials Design-NeurIPS 2023 Workshop , year=
2023
-
[65]
arXiv preprint arXiv:2210.00580 , year=
GFlowNets and variational inference , author=. arXiv preprint arXiv:2210.00580 , year=
-
[66]
arXiv preprint arXiv:2505.15251 , year=
Loss-guided auxiliary agents for overcoming mode collapse in gflownets , author=. arXiv preprint arXiv:2505.15251 , year=
-
[67]
arXiv preprint arXiv:2209.02606 , year=
Unifying generative models with GFlowNets and beyond , author=. arXiv preprint arXiv:2209.02606 , year=
-
[68]
arXiv preprint arXiv:2505.03561 , year=
Ergodic Generative Flows , author=. arXiv preprint arXiv:2505.03561 , year=
-
[69]
2014 , publisher=
Understanding machine learning: From theory to algorithms , author=. 2014 , publisher=
2014
-
[70]
IEEE/CVF conference on computer vision and pattern recognition , year=
High-resolution image synthesis with latent diffusion models , author=. IEEE/CVF conference on computer vision and pattern recognition , year=
-
[71]
AAAI conference on artificial intelligence , year=
Deep reinforcement learning with double q-learning , author=. AAAI conference on artificial intelligence , year=
-
[72]
Continuous control with deep reinforcement learning
Continuous control with deep reinforcement learning , author=. arXiv preprint arXiv:1509.02971 , year=
work page internal anchor Pith review arXiv
-
[73]
Advances in neural information processing systems , year=
Maximum likelihood training of score-based diffusion models , author=. Advances in neural information processing systems , year=
-
[74]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[75]
Machine Learning , year=
An upper bound on the loss from approximate optimal-value functions , author=. Machine Learning , year=
-
[76]
International conference on machine learning , year=
Trust region policy optimization , author=. International conference on machine learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.