Recognition: 2 theorem links
· Lean TheoremProfile-Specific 3DMM Regression from a Single Lateral Face Image
Pith reviewed 2026-05-08 19:32 UTC · model grok-4.3
The pith
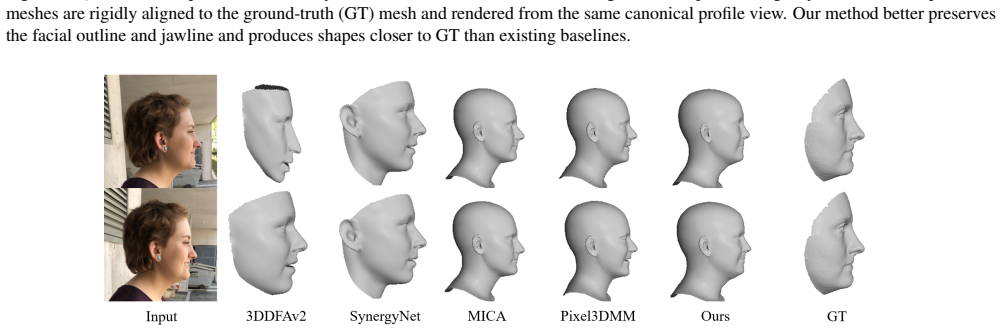
Introduces the ProfileSynth dataset and a profile-specific FLAME 3DMM regression baseline with visibility-aware jawline regularization for 3D reconstruction from single lateral face images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We bridge this gap with geometry-conditioned synthetic data and a simple profile-specific FLAME regression baseline for single lateral images.
Load-bearing premise
That synthetic profile images generated by a diffusion model conditioned on depth and normal maps from FLAME parameters will generalize sufficiently to real-world lateral RGB images for clinically accurate 3DMM regression.
Figures



read the original abstract
Single-image 3D face reconstruction is a core problem in computer vision, with important clinical applications such as cephalometric landmark analysis in orthodontics. Traditionally, this analysis relies on lateral X-ray imaging; however, frequent X-ray exposure is impractical due to radiation concerns. While recent research has explored detecting landmarks from lateral RGB images as an alternative, existing methods typically rely on 2D features such as the eyes, mouth, ears, and boundary silhouettes, failing to fully exploit the underlying 3D facial geometry spanning the facial profile and jawline, which is essential for accurate diagnosis. Meanwhile, although 3D face reconstruction from frontal views has seen significant progress, most learning-based 3D morphable model (3DMM) regressors are developed and benchmarked on near-frontal images, where appearance cues are abundant. In extreme profile views (yaw $\approx 90^\circ$), much of the face is occluded, and the available signal is dominated by boundary cues, making accurate 3D reconstruction challenging. In this paper, we bridge this gap with geometry-conditioned synthetic data and a simple profile-specific FLAME regression baseline for single lateral images. We introduce ProfileSynth, a dataset created by sampling FLAME shape and pose parameters in extreme yaw ranges and generating photorealistic profile images using a diffusion model conditioned on depth and normal maps. We further study a profile-specific baseline with visibility-aware jawline regularization. Our framework provides a practical baseline for "profile $\times$ 3DMM" reconstruction and a promising foundation for more accurate, non-invasive cephalometric analysis from lateral RGB images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the difficulty of 3D morphable model (3DMM) regression from single lateral face images (yaw ≈ 90°), where occlusions limit appearance cues and most existing regressors are tuned for near-frontal views. It introduces ProfileSynth, a synthetic dataset generated by sampling FLAME shape/pose parameters over extreme yaw ranges and rendering photorealistic profile images via a diffusion model conditioned on depth and normal maps derived from those parameters. It further proposes a profile-specific FLAME regression baseline that incorporates visibility-aware jawline regularization to mitigate occlusion effects. The stated goal is to supply a practical baseline for profile × 3DMM reconstruction that can support non-invasive cephalometric landmark analysis as a radiation-free alternative to lateral X-rays.
Significance. If the geometry-conditioned synthetic data pipeline and the associated regressor transfer to real lateral photographs, the work would supply a useful starting point for an underexplored regime of 3D face reconstruction. The explicit coupling of data generation to FLAME parameters and the targeted jawline regularization constitute concrete, reproducible contributions that future methods can build upon. The clinical motivation is well-motivated, yet the practical significance remains conditional on empirical evidence that the synthetic-to-real gap does not degrade accuracy below clinically usable levels.
major comments (1)
- [§4 and §5] §4 (Experiments) and §5 (Results): the reported evaluations appear confined to synthetic ProfileSynth images; no quantitative metrics (shape-parameter error, landmark reprojection error, or cephalometric angle accuracy) are supplied on any real lateral RGB dataset. Because the central claim is that the framework “bridges the gap” to clinically useful non-invasive analysis, the absence of real-data validation is load-bearing: the synthetic-to-real generalization that the diffusion conditioning is intended to achieve is not demonstrated.
minor comments (2)
- [§3] The method section would benefit from an explicit statement of the network architecture (backbone, output dimensionality, loss weights) and the precise formulation of the visibility-aware jawline term, including how visibility masks are computed from the FLAME mesh.
- [§2.2] Table or figure captions that compare ProfileSynth statistics (yaw distribution, lighting variation) against existing profile datasets would help readers assess domain coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the contributions of the ProfileSynth dataset and the profile-specific baseline. We address the major comment below.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experiments) and §5 (Results): the reported evaluations appear confined to synthetic ProfileSynth images; no quantitative metrics (shape-parameter error, landmark reprojection error, or cephalometric angle accuracy) are supplied on any real lateral RGB dataset. Because the central claim is that the framework “bridges the gap” to clinically useful non-invasive analysis, the absence of real-data validation is load-bearing: the synthetic-to-real generalization that the diffusion conditioning is intended to achieve is not demonstrated.
Authors: We agree that all quantitative evaluations in Sections 4 and 5 are performed exclusively on the synthetic ProfileSynth test set, using metrics such as shape-parameter error and landmark reprojection error. No real lateral RGB datasets with corresponding 3D ground truth are evaluated. The manuscript's primary contributions are the geometry-conditioned synthetic data pipeline (FLAME parameters to depth/normal maps to diffusion-rendered profiles) and the visibility-aware jawline regularization for the profile regressor; both are fully demonstrated and reproducible within the synthetic regime. We acknowledge that this leaves the synthetic-to-real generalization unquantified, which limits the strength of claims regarding immediate clinical utility for cephalometric analysis. In the revised manuscript we will (i) revise the abstract and introduction to state that the work supplies a synthetic baseline and foundation rather than a completed bridge to clinical use, and (ii) add an explicit limitations paragraph discussing the domain gap and outlining future adaptation steps. These textual changes clarify scope without requiring new experiments outside the current contribution. revision: partial
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AxiomDischargePlanwashburn_uniqueness_aczel (J = ½(x+x⁻¹)−1) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use an ImageNet-pretrained ResNet-50 backbone f(·) ... an MLP head g(·) to regress FLAME parameters ... L = w_p L_param + w_l L_lm3d + w_j L_jaw
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A morphable model for the synthesis of 3d faces
V olker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. InProceedings of the 26th Annual Conference on Computer Graphics and Interactive Tech- niques, pages 187–194, USA, 1999. ACM Press/Addison- Wesley Publishing Co. 1, 2
1999
-
[2]
A 3d morphable model learnt from 10,000 faces
James Booth, Anastasios Roussos, Stefanos Zafeiriou, Allan Ponniah, and David Dunaway. A 3d morphable model learnt from 10,000 faces. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 2
2016
-
[3]
Realy: Rethinking the evaluation of 3d face reconstruction
Zenghao Chai, Haoxian Zhang, Jing Ren, Di Kang, Zhengzhuo Xu, Xuefei Zhe, Chun Yuan, and Linchao Bao. Realy: Rethinking the evaluation of 3d face reconstruction. InProceedings of the European Conference on Computer Vi- sion (ECCV), 2022. 2, 6
2022
-
[4]
Black, and Timo Bolkart
Radek Danecek, Michael J. Black, and Timo Bolkart. EMOCA: Emotion driven monocular face capture and an- imation. InConference on Computer Vision and Pattern Recognition (CVPR), pages 20311–20322, 2022. 1, 2, 5, 7
2022
-
[5]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 3
2009
-
[6]
Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set
Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2019. 2
2019
-
[7]
Bernhard Egger, William A. P. Smith, Ayush Tewari, Ste- fanie Wuhrer, Michael Zollhoefer, Thabo Beeler, Florian Bernard, Timo Bolkart, Adam Kortylewski, Sami Romdhani, Christian Theobalt, V olker Blanz, and Thomas Vetter. 3d morphable face models—past, present, and future.ACM Trans. Graph., 39(5), 2020. 1, 2
2020
-
[8]
Joint 3d face reconstruction and dense alignment with position map regression network
Yao Feng, Fan Wu, Xiaohu Shao, Yanfeng Wang, and Xi Zhou. Joint 3d face reconstruction and dense alignment with position map regression network. InProceedings of the Eu- ropean Conference on Computer Vision (ECCV), 2018. 2
2018
-
[9]
Black, and Timo Bolkart
Yao Feng, Haiwen Feng, Michael J. Black, and Timo Bolkart. Learning an animatable detailed 3D face model from in-the-wild images.ACM Transactions on Graphics (ToG), Proc. SIGGRAPH, 40(4):88:1–88:13, 2021. 1, 2, 5, 7
2021
-
[10]
Filntisis, George Retsinas, Foivos Paraperas- Papantoniou, Athanasios Katsamanis, Anastasios Roussos, and Petros Maragos
Panagiotis P. Filntisis, George Retsinas, Foivos Paraperas- Papantoniou, Athanasios Katsamanis, Anastasios Roussos, and Petros Maragos. SPECTRE: Visual speech-informed perceptual 3d facial expression reconstruction from videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 5745–5755, 2023. 5
2023
-
[11]
arXiv preprint arXiv:2505.00615 , year=
Simon Giebenhain, Tobias Kirschstein, Martin R ¨unz, Lour- des Agapito, and Matthias Nießner. Pixel3dmm: Versatile screen-space priors for single-image 3d face reconstruction. arXiv preprint arXiv:2505.00615, 2025. 2, 5, 7
-
[12]
3ddfa.https: //github.com/cleardusk/3DDFA, 2018
Jianzhu Guo, Xiangyu Zhu, and Zhen Lei. 3ddfa.https: //github.com/cleardusk/3DDFA, 2018. 5
2018
-
[13]
Towards fast, accurate and stable 3d dense face alignment
Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei, and Stan Z Li. Towards fast, accurate and stable 3d dense face alignment. InProceedings of the European Conference on Computer Vision (ECCV), 2020. 2, 5
2020
-
[14]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 3
2016
-
[15]
Neu- ral 3d mesh renderer
Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. Neu- ral 3d mesh renderer. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 2
2018
-
[16]
Automatic cephalometric landmark detection on x-ray images using object detection
Cheng-Ho King, Yin-Lin Wang, Wei-Yang Lin, and Chia- Ling Tsai. Automatic cephalometric landmark detection on x-ray images using object detection. In2022 IEEE 19th In- ternational Symposium on Biomedical Imaging (ISBI), pages 1–4, 2022. 1
2022
-
[17]
Modular primitives for high-performance differentiable rendering.ACM Transac- tions on Graphics, 39(6), 2020
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primitives for high-performance differentiable rendering.ACM Transac- tions on Graphics, 39(6), 2020. 2
2020
-
[18]
Black, Hao Li, and Javier Romero
Tianye Li, Timo Bolkart, Michael J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and ex- pression from 4d scans.ACM Trans. Graph., 36(6), 2017. 1, 2, 3, 8, 11
2017
-
[19]
Lindner, C
C. Lindner, C. W. Wang, C. T. Huang, et al. Fully automatic system for accurate localisation and analysis of cephalomet- ric landmarks in lateral cephalograms.Scientific Reports, 6 (33581), 2016. 1
2016
-
[20]
Soft ras- terizer: A differentiable renderer for image-based 3d reason- ing
Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. Soft ras- terizer: A differentiable renderer for image-based 3d reason- ing. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV), 2019. 2
2019
-
[21]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations (ICLR), 2019. 6
2019
-
[22]
Torchvision: Py- torch’s computer vision library.https://github.com/ pytorch/vision, 2016
TorchVision maintainers and contributors. Torchvision: Py- torch’s computer vision library.https://github.com/ pytorch/vision, 2016. 6
2016
-
[23]
Dad- 3dheads: A large-scale dense, accurate and diverse dataset for 3d head alignment from a single image
Tetiana Martyniuk, Orest Kupyn, Yana Kurlyak, Igor Krashenyi, Ji ˇr´ı Matas, and Viktoriia Sharmanska. Dad- 3dheads: A large-scale dense, accurate and diverse dataset for 3d head alignment from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 20942–20952, 2022. 1, 2
2022
-
[24]
A 3d face model for pose and illumination invariant face recognition
Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami Romdhani, and Thomas Vetter. A 3d face model for pose and illumination invariant face recognition. In2009 Sixth IEEE International Conference on Advanced Video and Sig- nal Based Surveillance, pages 296–301, 2009. 2
2009
-
[25]
Accelerating 3D Deep Learning with PyTorch3D
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Tay- lor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia 9 Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020. 2, 4, 6
work page internal anchor Pith review arXiv 2007
-
[26]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 2, 4, 11
2022
-
[27]
Grabcut: Interactive foreground extraction using iterated graph cuts
Carsten Rother, Vladimir Kolmogorov, and Andrew Blake. Grabcut: Interactive foreground extraction using iterated graph cuts. InACM SIGGRAPH 2004 Papers, pages 309– 314, 2004. 12
2004
-
[28]
Fake it without making it: Conditioned face generation for accurate 3d face reconstruction, 2023
Will Rowan, Patrik Huber, Nick Pears, and Andrew Keeling. Fake it without making it: Conditioned face generation for accurate 3d face reconstruction, 2023. 2, 3
2023
-
[29]
Soubhik Sanyal, Timo Bolkart, Haiwen Feng, and Michael J. Black. Learning to regress 3d face shape and expression from an image without 3d supervision. InProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019. 2, 5, 6, 7, 8
2019
-
[30]
Accuracy of cephalometric landmark and cephalo- metric analysis from lateral facial photograph by using cnn- based algorithm.Scientific Reports, 14(31089), 2024
Yui Shimamura, Chie Tachiki, Kaisei Takahashi, Satoru Mat- sunaga, Takashi Takaki, Masafumi Hagiwara, and Yasushi Nishii. Accuracy of cephalometric landmark and cephalo- metric analysis from lateral facial photograph by using cnn- based algorithm.Scientific Reports, 14(31089), 2024. 1, 12
2024
-
[31]
Cephalometric landmark detection without x-rays combining coordinate regression and heatmap regression.Scientific Reports, 13(20011), 2023
Kaisei Takahashi, Yui Shimamura, Chie Tachiki, Yasushi Nishii, and Masafumi Hagiwara. Cephalometric landmark detection without x-rays combining coordinate regression and heatmap regression.Scientific Reports, 13(20011), 2023. 1, 12
2023
-
[32]
Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376– 380, 1991
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376– 380, 1991. 5
1991
-
[33]
Diffusers: State-of-the-art diffu- sion models.https://github.com/huggingface/ diffusers, 2022
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffu- sion models.https://github.com/huggingface/ diffusers, 2022. 6
2022
-
[34]
3d face reconstruction with the geometric guidance of facial part segmentation
Zidu Wang, Xiangyu Zhu, Tianshuo Zhang, Baiqin Wang, and Zhen Lei. 3d face reconstruction with the geometric guidance of facial part segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1672–1682, 2024. 1, 2
2024
-
[35]
Cashman, and Jamie Shotton
Erroll Wood, Tadas Baltru ˇsaitis, Charlie Hewitt, Sebastian Dziadzio, Thomas J. Cashman, and Jamie Shotton. Fake it till you make it: Face analysis in the wild using synthetic data alone. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3681–3691,
-
[36]
Syn- ergy between 3dmm and 3d landmarks for accurate 3d facial geometry
Cho-Ying Wu, Qiangeng Xu, and Ulrich Neumann. Syn- ergy between 3dmm and 3d landmarks for accurate 3d facial geometry. In2021 International Conference on 3D Vision (3DV), 2021. 2, 5
2021
-
[37]
Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face pre- diction
Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang, and Xun Cao. Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face pre- diction. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 2
2020
-
[38]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023. 2, 4, 5, 11
2023
-
[39]
Xiangyu Zhu, Zhen Lei, Xiaoming Liu, Hailin Shi, and Stan Z. Li. Face alignment across large poses: A 3d solu- tion. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 2
2016
-
[40]
Towards metrical reconstruction of human faces
Wojciech Zielonka, Timo Bolkart, and Justus Thies. Towards metrical reconstruction of human faces. InProceedings of the European Conference on Computer Vision (ECCV),
-
[41]
1, 2, 5, 7 10 Profile-Specific 3DMM Regression from a Single Lateral Face Image Supplementary Material Table 5. ProfileSynth generation setup. Item Setting Face model FLAME2020 [18] Requested sample count 100,000 Shape dimensionality 300 Expression fixed to zero Yaw range[85 ◦,95 ◦] Other pose components clipped Gaussian sampling Camera fixed perspective,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.