Recognition: unknown
GATE: GPU-Accelerated Traffic Engineering for the WAN
Pith reviewed 2026-05-09 16:48 UTC · model grok-4.3
The pith
GATE uses GPU-parallel decomposition to solve traffic engineering problems optimally up to 10 times faster than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GATE achieves near-optimal solutions 5-10x faster than state-of-the-art by using a highly-parallelizable GPU-compatible decomposition that iteratively converges to the provably optimal solution for a wide spectrum of fairness objectives.
What carries the argument
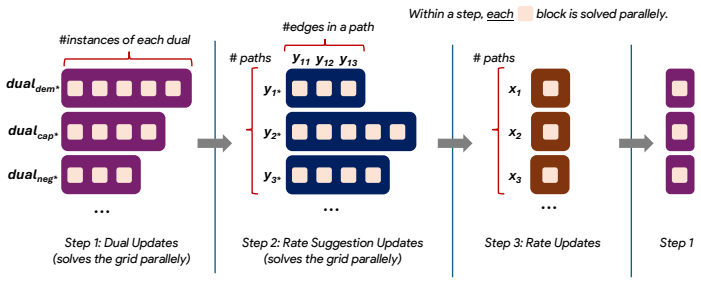
The GPU-compatible decomposition of the traffic engineering optimization problem, which allows parallel computation while ensuring convergence.
If this is right
- Network operators can respond to demand shifts or failures in seconds instead of longer runtimes.
- The same solver handles multiple fairness objectives without redesign.
- Larger networks gain more from the parallelism, improving scalability.
- Theoretical convergence bounds allow safe use of near-optimal results after limited iterations.
Where Pith is reading between the lines
- The decomposition technique could extend to other network resource allocation problems that currently rely on slow solvers.
- Real-time TE might become standard in highly dynamic environments like edge computing.
- Production systems could reduce dependence on heuristic approximations for critical routing decisions.
Load-bearing premise
The traffic engineering optimization problem admits a decomposition that is highly parallelizable on GPUs and that the iterative method converges to the optimal solution for a wide spectrum of fairness objectives.
What would settle it
A case where GATE's decomposition fails to converge to optimal or where its GPU implementation shows no significant speedup over CPU methods on production-scale networks.
Figures






read the original abstract
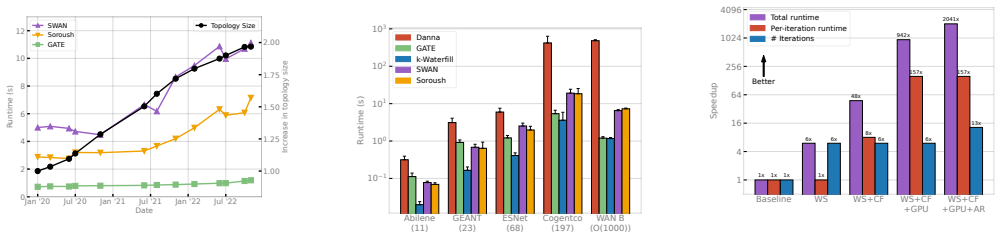
Traffic engineering (TE) has become a crucial tool for enforcing routing policy and maintaining operational efficiency in large networks. Existing TE solutions pick an objective function to optimize, aiming to balance (i) allocating traffic optimally with (ii) reacting quickly to demand changes and disruption events. However, as the scale of networks grows, the runtime of the existing optimal solution becomes infeasibly large. The alternative - approximate solvers - result in costly inefficiencies. We present GPU-Accelerated Traffic Engineering (GATE), which achieves the best of both worlds: enabling fast TE runtimes through a highly-parallelizable GPU-compatible decomposition, while iteratively converging to the provably optimal solution. GATE unlocks a unique set of desirable properties: it becomes increasingly parallelizable with network size, supports a wide spectrum of fairness objectives, and offers theoretically guaranteed convergence to the optimal solution and near-optimal convergence within a bounded time. We evaluate GATE on production traces from two large cloud WANs, and show that GATE achieves near-optimal solutions 5-10x faster than state-of-the-art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GATE, a GPU-accelerated decomposition algorithm for traffic engineering (TE) in wide-area networks. It claims to enable highly parallelizable computation on GPUs while iteratively converging to the provably optimal solution for a wide spectrum of fairness objectives, with theoretical convergence guarantees and near-optimal performance within bounded time. Evaluation on production traces from two large cloud WANs reports 5-10x speedups over state-of-the-art solvers.
Significance. If the decomposition and convergence properties hold, GATE would meaningfully advance scalable TE by closing the gap between slow exact solvers and fast but suboptimal approximations in large cloud networks. The use of real production traces from two WANs is a positive aspect that grounds the performance claims.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The claim of convergence to the 'provably optimal solution' for a 'wide spectrum of fairness objectives' rests on unstated separability and convexity assumptions in the decomposition. Standard formulations with alpha-fairness (alpha ≠ 1), max-min, or lex-max objectives are nonlinear and couple flows across paths; without explicit conditions showing that the chosen blocks remain convex and the fixed point is the global optimum (rather than a stationary point of a relaxation), the guarantee does not hold for arbitrary objectives or dense traffic matrices.
- [Abstract and §5] Abstract and §5 (evaluation): The 5-10x speedup to 'near-optimal' solutions is reported on production traces, but the abstract provides no details on iteration counts, optimality gaps, baseline solvers, or error analysis. This makes it impossible to assess whether the speedup is independent of the fairness parameter or holds only for specific cases where the decomposition converges quickly.
minor comments (2)
- [§2] Notation for the fairness objectives and the decomposition blocks should be introduced earlier and used consistently to aid readability.
- [Abstract] The abstract mentions 'theoretically guaranteed convergence' but does not reference the specific theorem or proof sketch; adding a forward pointer would help.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and will revise the manuscript to incorporate clarifications and additional details where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The claim of convergence to the 'provably optimal solution' for a 'wide spectrum of fairness objectives' rests on unstated separability and convexity assumptions in the decomposition. Standard formulations with alpha-fairness (alpha ≠ 1), max-min, or lex-max objectives are nonlinear and couple flows across paths; without explicit conditions showing that the chosen blocks remain convex and the fixed point is the global optimum (rather than a stationary point of a relaxation), the guarantee does not hold for arbitrary objectives or dense traffic matrices.
Authors: We appreciate the referee pointing out the need for explicit assumptions. Section 3 of the manuscript defines the block decomposition and states that convergence holds when the objective is separable across blocks and each subproblem is convex. For the supported fairness objectives (including alpha-fairness for alpha > 0, max-min, and lex-max), the utility functions are concave and the flow conservation constraints are linear, preserving convexity of the blocks. The fixed point of the iterative procedure coincides with the global optimum of the original problem under these conditions. We will revise §3 to explicitly enumerate the separability and convexity requirements, add a short proof sketch confirming the fixed point is the global optimum (not merely a stationary point of a relaxation), and clarify that the guarantee applies to the spectrum of objectives for which these properties hold rather than arbitrary nonlinear objectives. revision: yes
-
Referee: [Abstract and §5] Abstract and §5 (evaluation): The 5-10x speedup to 'near-optimal' solutions is reported on production traces, but the abstract provides no details on iteration counts, optimality gaps, baseline solvers, or error analysis. This makes it impossible to assess whether the speedup is independent of the fairness parameter or holds only for specific cases where the decomposition converges quickly.
Authors: We agree that additional quantitative details in the abstract and evaluation section would improve clarity. In the revised manuscript we will expand §5 to report observed iteration counts, measured optimality gaps relative to exact solvers, the specific baseline solvers employed, and an analysis of performance variation across fairness parameters. The abstract will be updated with a concise statement summarizing these aspects. This will allow readers to verify that the reported speedups are consistent across the tested range of fairness objectives on the production traces. revision: yes
Circularity Check
No significant circularity; derivation relies on algorithmic decomposition and external evaluation
full rationale
The paper describes GATE as a GPU-parallelizable decomposition of the TE problem with claimed theoretical convergence guarantees to the optimal solution for a range of fairness objectives. No equations or steps in the provided abstract reduce a prediction or optimality claim to a fitted parameter, self-definition, or self-citation chain by construction. The speedup and near-optimality results are presented as outcomes of evaluation on production traces from two cloud WANs, which are independent of the derivation. This is consistent with a self-contained algorithmic contribution whose central claims do not collapse to renaming or fitting inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Traffic engineering can be formulated as an optimization problem that admits a highly parallelizable decomposition suitable for GPU execution.
- domain assumption The iterative method converges to the provably optimal solution for a wide spectrum of fairness objectives.
Reference graph
Works this paper leans on
-
[1]
https: //atscaleconference.com/events/ networking-scale-2024/, Jan
Networking @scale 2024. https: //atscaleconference.com/events/ networking-scale-2024/, Jan. 2024. Accessed: 2026-2-6
2024
-
[2]
Abuzaid, P
F. Abuzaid, P. Bailis, and M. Zaharia. Solving large- scale granular resource allocation problems efficiently with pop. In Proceedings of the 28th ACM Symposium on Operating Systems Principles (SOSP ’21), pages 638–652, 2021
2021
-
[3]
Abuzaid, S
F. Abuzaid, S. Kandula, B. Arzani, I. Menache, M. Za- haria, and P. Bailis. Contracting wide-area network topologies to solve flow problems quickly. In 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), pages 175–192, 2021
2021
-
[4]
Annamalai
N. Annamalai. Azure networking updates on security, reliability, and high availability. https://azure.microsoft.com/en-us/blog/ azure-networking-updates-on-security-reliability-and-high-availability/ , Dec. 2025. Accessed: 2026-2-6
2025
-
[5]
D. P. Bertsekas and R. G. Gallager. Data Networks. Prentice Hall, Englewood Cliffs, NJ, 3rd edition, 2009
2009
-
[6]
S. Boyd, P. Neal, C. Eric, P. Borja, and E. Jonathan. Distributed optimization and statistical learning via the alternating direction method of multipliers.Foundations and Trends® in Machine learning, 3(1):1–122, 2011
2011
-
[7]
Danna, A
E. Danna, A. Hassidim, H. Kaplan, A. Kumar, Y . Man- sour, D. Raz, and M. Segalov. Upward max-min fairness. Journal of the ACM (JACM), 64(1):1–24, 2017
2017
-
[8]
Danna, S
E. Danna, S. Mandal, and A. Singh. A practical algo- rithm for balancing the max-min fairness and throughput objectives in traffic engineering. In 2012 Proceedings IEEE INFOCOM, pages 846–854. IEEE, 2012
2012
-
[9]
Data center it capex 5-year forecast report
Dell’Oro Group. Data center it capex 5-year forecast report. Market research report, Dell’Oro Group, January
-
[10]
Cloud Capex to Surge as AI Infrastructure Matures
Summarized in Light Reading: "Cloud Capex to Surge as AI Infrastructure Matures"
-
[11]
Denis, Y
M. Denis, Y . Yao, A. Hatch, Q. Zhang, C. L. Lim, S. Zhang, K. Sugrue, H. Kwok, M. J. Fernandez, P. La- pukhov, et al. EBB: Reliable and evolvable express backbone network in meta. In Proceedings of the ACM SIGCOMM 2023 Conference, pages 346–359, 2023
2023
-
[12]
Feamster, J
N. Feamster, J. Rexford, and E. Zegura. The road to SDN: an intellectual history of programmable networks. SIGCOMM Comput. Commun. Rev., 44(2):87–98, Apr. 2014
2014
-
[13]
J. He, M. Bresler, M. Chiang, and J. Rexford. To- wards robust multi-layer traffic engineering: Optimiza- tion of congestion control and routing. IEEE Journal on selected areas in communications, 25(5):868–880, 2007
2007
-
[14]
M. R. Hestenes. Multiplier and gradient meth- ods. Journal of Optimization Theory and Applications, 4:303–320, 1969
1969
-
[15]
C.-Y . Hong, S. Kandula, R. Mahajan, M. Zhang, V . Gill, M. Nanduri, and R. Wattenhofer. Achieving high uti- lization with software-driven wan. In Proceedings of the ACM SIGCOMM 2013 conference on SIGCOMM, pages 15–26. ACM, 2013
2013
-
[16]
S. Jain, A. Kumar, S. Mandal, J. Ong, L. Poutievski, A. Singh, S. Venkata, J. Wanderer, J. Zhou, M. Zhu, J. Zolla, U. Hölzle, S. Stuart, and A. Vahdat. B4: Experi- ence with a globally deployed software defined wan. In Proceedings of the ACM SIGCOMM Conference, Hong Kong, China, 2013
2013
-
[17]
L. Jose, S. Ibanez, M. Alizadeh, and N. McKeown. A distributed algorithm to calculate max-min fair rates without per-flow state. Proceedings of the ACM on Measurement and Analysis of Computing Systems, 3(2):1–25, 2019
2019
-
[18]
Jurkiewicz
P. Jurkiewicz. Topohub: A repository of reference gabriel graph and real-world topologies for networking research. SoftwareX, 24:101540, 2023. 13
2023
-
[19]
F. P. Kelly, A. K. Maulloo, and D. K. H. Tan. Rate con- trol for communication networks: shadow prices, propor- tional fairness and stability. Journal of the Operational Research society, 49(3):237–252, 1998
1998
-
[20]
Kikuta, E
K. Kikuta, E. Oki, N. Yamanaka, N. Togawa, and H. Nakazato. Effective parallel algorithm for gpgpu- accelerated explicit routing optimization. In 2015 IEEE Global Communications Conference (GLOBECOM), pages 1–6, 2015
2015
-
[21]
B. Koley. Google’s AI-powered next-gen global net- work: Built for the gemini era. Google Cloud Next 25, Apr. 2025
2025
-
[22]
Krentsel, N
A. Krentsel, N. Saran, B. Koley, S. Mandal, A. Narayanan, S. Ratnasamy, A. Al-Shabibi, A. Shaikh, R. Shakir, A. Singla, and H. Weatherspoon. A decen- tralized sdn architecture for the wan. In Proceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, page 938–953, New York, NY , USA,
2024
-
[23]
Association for Computing Machinery
-
[24]
Krishnaswamy, R
U. Krishnaswamy, R. Singh, P. Mattes, P.-A. C. Bis- sonnette, N. Bjørner, Z. Nasrin, S. Kothari, P. Reddy, J. Abeln, S. Kandula, H. Raj, L. Irun-Briz, J. Gaudette, and E. Lan. OneWAN is better than two: Unifying a split WAN architecture. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 515–529, Boston, MA, Apr. 2023...
2023
-
[25]
S. Liao. On the homotopy analysis method for nonlin- ear problems. Applied Mathematics and Computation, 147(2):499–513, 2004
2004
-
[26]
Lin and N
X. Lin and N. B. Shroff. Utility maximization for com- munication networks with multipath routing. IEEE Transactions on Automatic Control, 51(5):766–781, 2006
2006
-
[27]
S. H. Low and D. E. Lapsley. Optimization flow con- trol. i. basic algorithm and convergence. IEEE/ACM Transactions on networking, 7(6):861–874, 1999
1999
-
[28]
Y . Lu, S. Kandula, A. C. König, and S. Chaudhuri. Pre- training summarization models of structured datasets for cardinality estimation. Proceedings of the VLDB Endowment, 15(3):414–426, 2021
2021
- [29]
-
[30]
Nace and M
D. Nace and M. Pióro. Max-min fairness and its appli- cations to routing and load-balancing in communication networks: a tutorial. IEEE Communications Surveys & Tutorials, 10(4):5–17, 2009
2009
-
[31]
Namyar, B
P. Namyar, B. Arzani, S. Kandula, S. Segarra, D. Crankshaw, U. Krishnaswamy, R. Govindan, and H. Raj. Solving max-min fair resource allocations quickly on large graphs. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 1937–1958, 2024
1937
-
[32]
Orlowski, R
S. Orlowski, R. Wessäly, M. Pióro, and A. Tomaszewski. Sndlib 1.0—survivable network design library. Networks, 55(3):276–286, 2010
2010
-
[33]
Perry, F
Y . Perry, F. V . Frujeri, C. Hoch, S. Kandula, I. Men- ache, M. Schapira, and A. Tamar. {DOTE}: Rethink- ing (predictive) {WAN} traffic engineering. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 1557–1581, 2023
2023
-
[34]
Roughan, A
M. Roughan, A. Greenberg, C. Kalmanek, M. Rum- sewicz, J. Yates, and Y . Zhang. Experience in measuring backbone traffic variability: models, metrics, measure- ments and meaning. In Proceedings of the 2nd ACM SIGCOMM Workshop on Internet Measurment, IMW ’02, page 91–92, New York, NY , USA, 2002. Associa- tion for Computing Machinery
2002
-
[35]
R. Srikant. The mathematics of Internet congestion control. Springer, 2004
2004
-
[36]
Srikant and L
R. Srikant and L. Ying. Communication networks: An optimization, control and stochastic networks perspective. Cambridge University Press, 2014
2014
-
[37]
Stoer and R
J. Stoer and R. Bulirsch. Introduction to Numerical Analysis, volume 12 of Texts in Applied Mathematics. Springer-Verlag, New York, 2002
2002
-
[38]
X. Wang, Q. Zhang, J. Ren, S. Xu, S. Wang, and S. Yu. Toward efficient parallel routing optimization for large- scale sdn networks using gpgpu. Journal of Network and Computer Applications, 113:1–13, 2018
2018
-
[39]
Z. Xu, F. Y . Yan, R. Singh, J. T. Chiu, A. M. Rush, and M. Yu. Teal: Learning-accelerated optimization of wan traffic engineering. In Proceedings of the ACM SIGCOMM 2023 Conference, pages 313–328, 2023
2023
-
[40]
Z. Xu, M. Yu, and F. Y . Yan. Decouple and decompose: Scaling resource allocation with dede. In Proceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). USENIX Asso- ciation, July 2025
2025
-
[41]
dual k demst β + Dst − ∑ r∈Pst xk r !# + (19) slackk+1 cape =
F. Zhang and S. Boyd. Solving large multicommod- ity network flow problems on GPUs. Automation and Remote Control, 86(8):782–795, 2025. 14 Max-flow Danna GATE k-Waterfill SWAN Soroush0.80 0.85 0.90 0.95 1.00 1.05Demand served w.rt. Danna Max-flow Danna GATE k-Waterfill SWAN Soroush Figure 13:GATE runtime with increasing GPU threads A Evaluation Continued ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.