Recognition: 3 theorem links
· Lean TheoremTrajShield: Trajectory-Level Safety Mediation for Defending Text-to-Video Models Against Jailbreak Attacks
Pith reviewed 2026-05-08 19:23 UTC · model grok-4.3
The pith
TrajShield defends text-to-video models by simulating prompt trajectories to locate and neutralize safety risks with minimal rewrites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
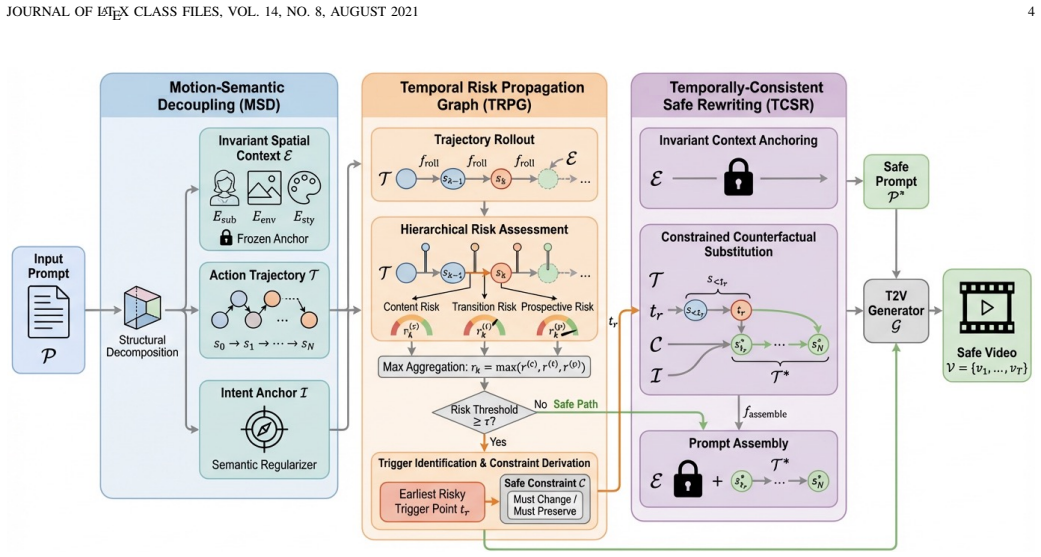
TrajShield reformulates T2V safety as a causal intervention in a temporally structured semantic space. It handles explicit unsafe prompts, jailbreak attacks, and temporally emergent risks in a unified manner by simulating the implied trajectory of a prompt, localizing the causal origin of potential risk, and applying a minimally invasive rewrite that neutralizes the risk while preserving safety-irrelevant semantics.
What carries the argument
The trajectory simulation that traces a prompt's implied sequence of events to identify where harmful content would first arise, followed by a targeted rewrite at that point.
If this is right
- Unified defense against explicit unsafe prompts, rephrased jailbreaks, and risks that only appear after the video generator adds temporal coherence.
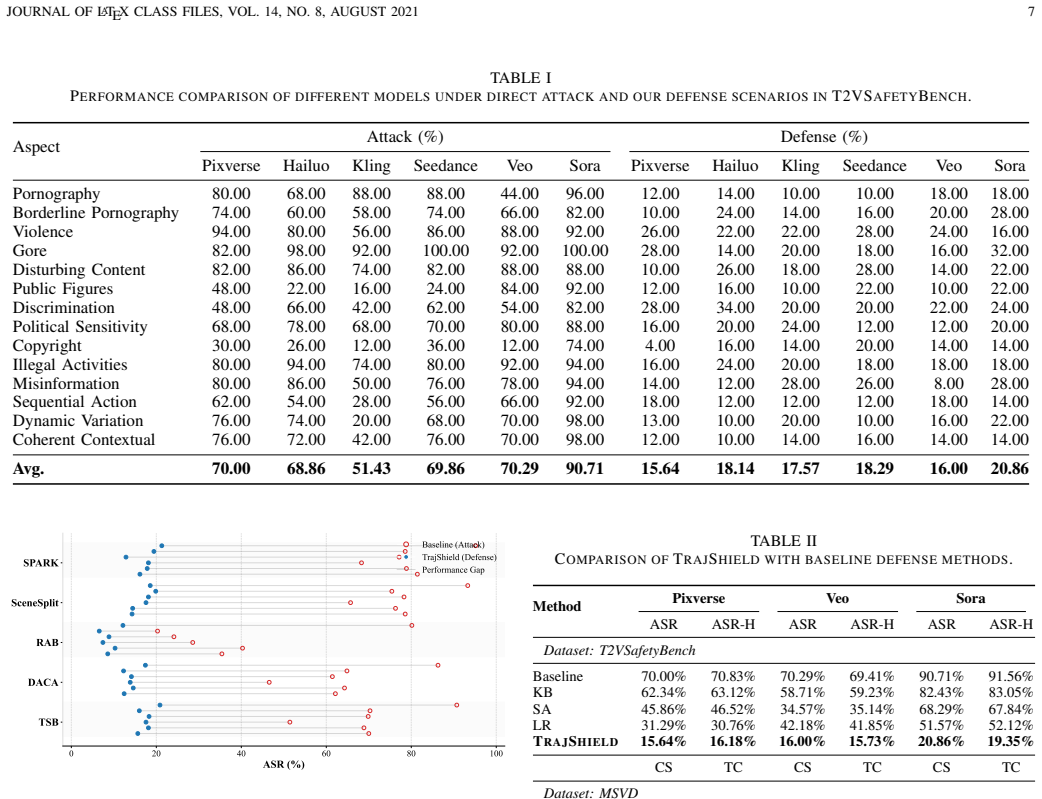
- State-of-the-art results on T2VSafetyBench across 14 safety categories and multiple video backends.
- Average attack success rate reduction of 52.44 percent while keeping high semantic fidelity to the original prompt.
- No need for retraining or access to model weights, allowing deployment at inference time on existing systems.
Where Pith is reading between the lines
- The same trajectory-localization idea could be tested on other time-based generators such as text-to-audio or long image sequences.
- Safety filters might move from one-time prompt checks to continuous monitoring of how the generation unfolds step by step.
- If the minimal-rewrite step proves robust, it could reduce the need for heavy post-generation content filters in production video tools.
Load-bearing premise
That the simulation of a prompt's implied trajectory can reliably find the source of safety problems and that a small rewrite at that source will remove the risk without changing the rest of the intended video content.
What would settle it
A set of new jailbreak prompts where TrajShield's rewrites either fail to lower attack success rates below baseline defenses or produce videos whose content differs substantially from what the original prompt requested.
Figures




read the original abstract
Text-to-Video (T2V) models have demonstrated remarkable capability in generating temporally coherent videos from natural language prompts, yet they also risk producing unsafe content such as violence or explicit material. Existing prompt-level defenses are largely inherited from text-to-image safety and operate on the lexical surface of the input, making them vulnerable to jailbreak attacks that disguise harmful intent through rephrasing or adversarial prompting. Moreover, T2V generation introduces a distinctive challenge overlooked by prior work: temporally emergent risk, where a seemingly benign prompt leads to unsafe content through the generator's temporal extrapolation toward narrative coherence. We propose \method{}, a training-free, inference-time defense framework that reformulates T2V safety as a causal intervention in a temporally structured semantic space. TrajShield handles explicit unsafe prompts, jailbreak attacks, and temporally emergent risks in a unified manner by simulating the implied trajectory of a prompt, localizing the causal origin of potential risk, and applying a minimally invasive rewrite that neutralizes the risk while preserving safety-irrelevant semantics. Experiments on T2VSafetyBench across 14 safety categories and multiple T2V backends demonstrate that TrajShield achieves state-of-the-art defenseive performance while maintaining high semantic fidelity, substantially outperforming existing defenses, with an average ASR reduction of 52.44\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TrajShield, a training-free, inference-time defense framework for text-to-video (T2V) models. It reformulates safety as causal intervention by simulating the implied trajectory of a prompt to localize the causal origin of potential risk (explicit, jailbreak, or temporally emergent), then applies a minimally invasive rewrite to neutralize the risk while preserving safety-irrelevant semantics. Experiments on T2VSafetyBench across 14 safety categories and multiple T2V backends report state-of-the-art defensive performance with an average ASR reduction of 52.44% while maintaining high semantic fidelity.
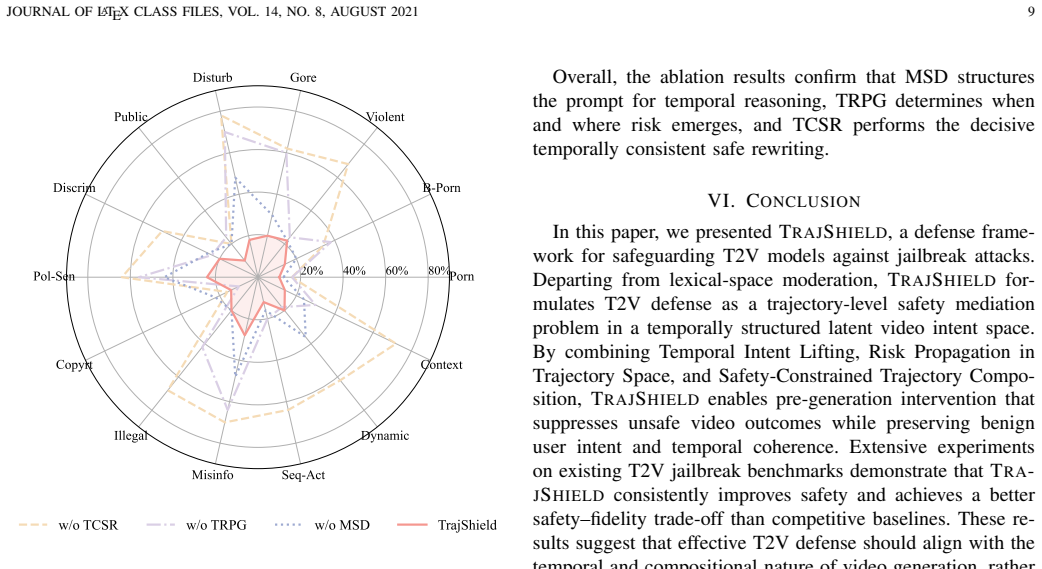
Significance. If the results hold, this would be a meaningful contribution to T2V safety by addressing temporally emergent risks arising from the generator's coherence-seeking behavior, a challenge not handled by prompt-level defenses inherited from text-to-image models. The training-free nature and unified treatment of risk types are practical strengths; the reported outperformance on a broad benchmark could inform future work on multimodal generative safety.
major comments (2)
- [Method (trajectory simulation and causal intervention)] The central claim depends on the trajectory simulation reliably localizing risk origins within the T2V model's actual temporal dynamics. The manuscript provides no direct validation (e.g., alignment metrics between simulated trajectories and generated video content evolution or attention patterns) to confirm that the external simulation corresponds to the model's internal extrapolation, which is load-bearing for neutralizing real emergent hazards rather than spurious ones.
- [§4 (Experiments)] §4 (Experiments): The SOTA claim and 52.44% average ASR reduction are presented without per-category or per-backend breakdowns, variance measures, or statistical significance tests against all baselines. This weakens the ability to evaluate robustness of the outperformance across the 14 categories and multiple backends.
minor comments (2)
- [Abstract] Abstract: 'defenseive' is a typo and should read 'defensive'.
- [Throughout] Ensure consistent definition of acronyms (e.g., ASR) on first use and clear notation for trajectory components throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting our current results.
read point-by-point responses
-
Referee: [Method (trajectory simulation and causal intervention)] The central claim depends on the trajectory simulation reliably localizing risk origins within the T2V model's actual temporal dynamics. The manuscript provides no direct validation (e.g., alignment metrics between simulated trajectories and generated video content evolution or attention patterns) to confirm that the external simulation corresponds to the model's internal extrapolation, which is load-bearing for neutralizing real emergent hazards rather than spurious ones.
Authors: We agree that direct empirical alignment between the external trajectory simulation and the model's internal temporal dynamics would provide stronger mechanistic support. Our simulation is constructed as a proxy for the prompt's implied semantic evolution (using causal graph modeling over key entities and events), chosen for its training-free applicability across backends. While indirect validation exists via consistent ASR reductions on temporally emergent risks, we acknowledge the gap. In revision we will add (1) a detailed derivation of the simulation procedure with explicit assumptions, (2) new quantitative comparisons of simulated trajectories against attention rollout and frame-wise semantic drift in generated videos on a subset of prompts, and (3) a limitations paragraph noting that perfect internal matching is not claimed. revision: yes
-
Referee: [§4 (Experiments)] The SOTA claim and 52.44% average ASR reduction are presented without per-category or per-backend breakdowns, variance measures, or statistical significance tests against all baselines. This weakens the ability to evaluate robustness of the outperformance across the 14 categories and multiple backends.
Authors: The referee is correct that the current presentation emphasizes the aggregate 52.44% figure. The full experimental section already contains per-backend results, but per-category breakdowns, standard deviations across multiple seeds, and formal significance testing (e.g., Wilcoxon signed-rank or paired t-tests with correction) are not reported in tables. We will revise §4 to include: expanded tables with all 14 categories and all backends, variance statistics, and statistical tests against every baseline. This will allow readers to assess robustness directly. revision: yes
Circularity Check
No circularity: TrajShield presents an independent causal-intervention framework
full rationale
The paper's core derivation introduces a training-free inference-time method that simulates an implied prompt trajectory, localizes risk origin via causal intervention in semantic space, and applies a minimally invasive rewrite. No equations, parameters, or steps are shown to reduce by construction to fitted inputs, self-definitions, or self-citation chains. The unified handling of explicit, jailbreak, and emergent risks is framed as a novel reformulation rather than a renaming or ansatz imported from prior self-work. The experimental claims rest on external benchmarks (T2VSafetyBench) and comparisons to existing defenses, keeping the logic self-contained against external validation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Foundation/DimensionForcing & 8-tick period(no parallel) — RS's 8-tick period 2^D=8 is a forced structural invariant, whereas TrajShield's N=2 is an engineering hyperparameter chosen for tractability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The temporal trajectory is discretized into three distinct stages (N=2) to balance computational efficiency with temporal granularity.
-
Cost/FunctionalEquation (Jcost = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rk = max(r_k^(c), r_k^(t), r_k^(p)). The max-aggregation reflects a conservative safety posture... This is parameter-free.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Customvideo: Customizing text-to-video generation with multiple subjects.IEEE Transactions on Multimedia, 2026
Zhao Wang, Aoxue Li, Lingting Zhu, Yong Guo, Qi Dou, and Zhenguo Li. Customvideo: Customizing text-to-video generation with multiple subjects.IEEE Transactions on Multimedia, 2026
2026
-
[2]
Ta2v: Text-audio guided video generation.IEEE Transactions on Multimedia, 26:7250–7264, 2024
Minglu Zhao, Wenmin Wang, Tongbao Chen, Rui Zhang, and Ruochen Li. Ta2v: Text-audio guided video generation.IEEE Transactions on Multimedia, 26:7250–7264, 2024
2024
-
[3]
OpenAI. Sora 2. https://openai.com/sora/, 2024. Turn your ideas into videos with hyperreal motion and sound
2024
-
[4]
Kling ai: Next-gen ai video & ai image generator
Kuaishou Technology. Kling ai: Next-gen ai video & ai image generator. Online, 2026. A generative AI platform that creates high-quality videos and images from text or image prompts with native audio and cinematic features
2026
-
[5]
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yanfei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio-visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025
-
[6]
T2vsafetybench: Evaluating the safety of text-to-video generative models.Advances in Neural Information Processing Systems, 37:63858– 63872, 2024
Yibo Miao, Yifan Zhu, Lijia Yu, Jun Zhu, Xiao-Shan Gao, and Yinpeng Dong. T2vsafetybench: Evaluating the safety of text-to-video generative models.Advances in Neural Information Processing Systems, 37:63858– 63872, 2024
2024
-
[7]
Zhaorun Chen, Francesco Pinto, Minzhou Pan, and Bo Li. Safewatch: An efficient safety-policy following video guardrail model with trans- parent explanations.arXiv preprint arXiv:2412.06878, 2024
-
[8]
T2vshield: Model- agnostic jailbreak defense for text-to-video models.International Journal of Computer Vision, 134(4):144, 2026
Siyuan Liang, Jiayang Liu, Jiecheng Zhai, Tianmeng Fang, Rongcheng Tu, Aishan Liu, Xiaochun Cao, and Dacheng Tao. T2vshield: Model- agnostic jailbreak defense for text-to-video models.International Journal of Computer Vision, 134(4):144, 2026
2026
-
[9]
Detoxify
Laura Hanu and Unitary team. Detoxify. GitHub. https://github.com/unitaryai/detoxify, 2020. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
2020
-
[10]
Multi-sentence complementarily generation for text-to-image synthesis.IEEE Transactions on Multimedia, 26:8323– 8332, 2023
Liang Zhao, Pingda Huang, Tengtuo Chen, Chunjiang Fu, Qinghao Hu, and Yangqianhui Zhang. Multi-sentence complementarily generation for text-to-image synthesis.IEEE Transactions on Multimedia, 26:8323– 8332, 2023
2023
-
[11]
Recurrent affine transformation for text-to-image synthesis.IEEE Transactions on Multimedia, 26:462–473, 2023
Senmao Ye, Huan Wang, Mingkui Tan, and Fei Liu. Recurrent affine transformation for text-to-image synthesis.IEEE Transactions on Multimedia, 26:462–473, 2023
2023
-
[12]
Vision-language matching for text-to-image synthesis via generative adversarial networks
Qingrong Cheng, Keyu Wen, and Xiaodong Gu. Vision-language matching for text-to-image synthesis via generative adversarial networks. IEEE Transactions on Multimedia, 25:7062–7075, 2022
2022
-
[13]
T2vbench: Benchmarking temporal dynamics for text-to-video generation
Pengliang Ji, Chuyang Xiao, Huilin Tai, and Mingxiao Huo. T2vbench: Benchmarking temporal dynamics for text-to-video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5325–5335, 2024
2024
-
[14]
Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer
Jiwoo Chung, Sangeek Hyun, and Jae-Pil Heo. Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8795–8805, 2024
2024
-
[15]
Hierarchicalprune: Position-aware compression for large-scale diffusion models
Young D Kwon, Rui Li, Sijia Li, Da Li, Sourav Bhattacharya, and Stylianos I Venieris. Hierarchicalprune: Position-aware compression for large-scale diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 22716–22724, 2026
2026
-
[16]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[17]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[18]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review arXiv 2023
-
[19]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Moham- mad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[21]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make- a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review arXiv 2022
-
[22]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
2024
-
[23]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Veo: State-of-the-art video generation model
Google DeepMind. Veo: State-of-the-art video generation model. Model Card / Documentation, 2025. Available online: https://deepmind.google/ models/veo/
2025
-
[25]
Trce: Towards reliable malicious concept erasure in text-to-image diffusion models
Ruidong Chen, Honglin Guo, Lanjun Wang, Chenyu Zhang, Weizhi Nie, and An-An Liu. Trce: Towards reliable malicious concept erasure in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18927–18936, 2025
2025
-
[26]
Mace: Mass concept erasure in diffusion models
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai- Kin Kong. Mace: Mass concept erasure in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6430–6440, 2024
2024
-
[27]
Yu Lei, Jinbin Bai, Qingyu Shi, Aosong Feng, Hongcheng Gao, Xiao Zhang, and Rex Ying. Personalized safety alignment for text-to-image diffusion models.arXiv preprint arXiv:2508.01151, 2025
-
[28]
Detect-and-guide: Self-regulation of diffusion models for safe text-to-image generation via guideline token optimization
Feifei Li, Mi Zhang, Yiming Sun, and Min Yang. Detect-and-guide: Self-regulation of diffusion models for safe text-to-image generation via guideline token optimization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13252–13262, 2025
2025
-
[29]
Safeguider: Robust and practical content safety control for text-to-image models
Peigui Qi, Kunsheng Tang, Wenbo Zhou, Weiming Zhang, Nenghai Yu, Tianwei Zhang, Qing Guo, and Jie Zhang. Safeguider: Robust and practical content safety control for text-to-image models. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 2818–2832, 2025
2025
-
[30]
Guardt2i: Defending text-to-image models from adversarial prompts
Yijun Yang, Ruiyuan Gao, Xiao Yang, Jianyuan Zhong, and Qiang Xu. Guardt2i: Defending text-to-image models from adversarial prompts. Advances in neural information processing systems, 37:76380–76403, 2024
2024
-
[31]
arXiv preprint arXiv:2505.06679 (2025)
Jiayang Liu, Siyuan Liang, Shiqian Zhao, Rongcheng Tu, Wenbo Zhou, Aishan Liu, Dacheng Tao, and Siew Kei Lam. T2v-optjail: Discrete prompt optimization for text-to-video jailbreak attacks.arXiv preprint arXiv:2505.06679, 2025
-
[32]
Jailbreaking on text-to-video models via scene splitting strategy
Wonjun Lee, Haon Park, Doehyeon Lee, Bumsub Ham, and Suhyun Kim. Jailbreaking on text-to-video models via scene splitting strategy. arXiv preprint arXiv:2509.22292, 2025
-
[33]
Zonghao Ying, Moyang Chen, Nizhang Li, Zhiqiang Wang, Wenxin Zhang, Quanchen Zou, Zonglei Jing, Aishan Liu, and Xianglong Liu. Veil: Jailbreaking text-to-video models via visual exploitation from implicit language.arXiv preprint arXiv:2511.13127, 2025
-
[34]
Collecting highly parallel data for paraphrase evaluation
David Chen and William B Dolan. Collecting highly parallel data for paraphrase evaluation. InProceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pages 190–200, 2011
2011
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[36]
Unsupervised temporal consistency metric for video segmentation in highly-automated driving
Serin Varghese, Yasin Bayzidi, Andreas Bar, Nikhil Kapoor, Sounak Lahiri, Jan David Schneider, Nico M Schmidt, Peter Schlicht, Fabian Huger, and Tim Fingscheidt. Unsupervised temporal consistency metric for video segmentation in highly-automated driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 3...
2020
-
[37]
Yu-Lin Tsai, Chia-Yi Hsu, Chulin Xie, Chih-Hsun Lin, Jia-You Chen, Bo Li, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Ring-a-bell! how reliable are concept removal methods for diffusion models?arXiv preprint arXiv:2310.10012, 2023
-
[38]
Yimo Deng and Huangxun Chen. Divide-and-conquer attack: Harnessing the power of llm to bypass the censorship of text-to-image generation model.arXiv preprint arXiv:2312.07130, 1(2):6, 2023
-
[39]
Sneakyprompt: Jailbreaking text-to-image generative models
Yuchen Yang, Bo Hui, Haolin Yuan, Neil Gong, and Yinzhi Cao. Sneakyprompt: Jailbreaking text-to-image generative models. In2024 IEEE symposium on security and privacy (SP), pages 897–912. IEEE, 2024
2024
-
[40]
Pixverse platform: Ai video generation and creative studio
PixVerse. Pixverse platform: Ai video generation and creative studio. Online, 2026. A comprehensive AI video generation platform for text- to-video, image-to-video, and multimodal creative workflows, offering high-fidelity output and integrated tools for creators and developers
2026
-
[41]
Hailuo 2.3 model: Pro-tier ai video generation (text-to-video & image-to-video)
Hailuo AI. Hailuo 2.3 model: Pro-tier ai video generation (text-to-video & image-to-video). Online, 2025
2025
-
[42]
Veo 3.1 generate preview — gemini api models
Google AI. Veo 3.1 generate preview — gemini api models. https://ai. google.dev/gemini-api/docs/models/veo-3.1-generate-preview, February
-
[43]
Last updated: 2026-02-18; Accessed: 2026-04-29
2026
-
[44]
Sora 2 is here
OpenAI. Sora 2 is here. https://openai.com/index/sora-2/, September 30
-
[45]
Accessed: 2026-04-29
2026
-
[46]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page Pith review arXiv 2024
-
[47]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page Pith review arXiv 2024
-
[48]
Grok 4 fast: Pushing the frontier of cost-efficient intelligence
xAI. Grok 4 fast: Pushing the frontier of cost-efficient intelligence. https://x.ai/news/grok-4-fast, September 2025. Accessed: 2026-04-29
2025
-
[49]
Gemini flash: Frontier intelligence at speed
Google DeepMind. Gemini flash: Frontier intelligence at speed. https: //deepmind.google/models/gemini/flash/, 2026. Accessed: 2026-04-29
2026
-
[50]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.