Recognition: unknown
DataEvolver: Let Your Data Build and Improve Itself via Goal-Driven Loop Agents
Pith reviewed 2026-05-10 15:14 UTC · model grok-4.3
The pith
DataEvolver builds better visual datasets by running coupled loops of self-correction inside each sample and self-expansion across rounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
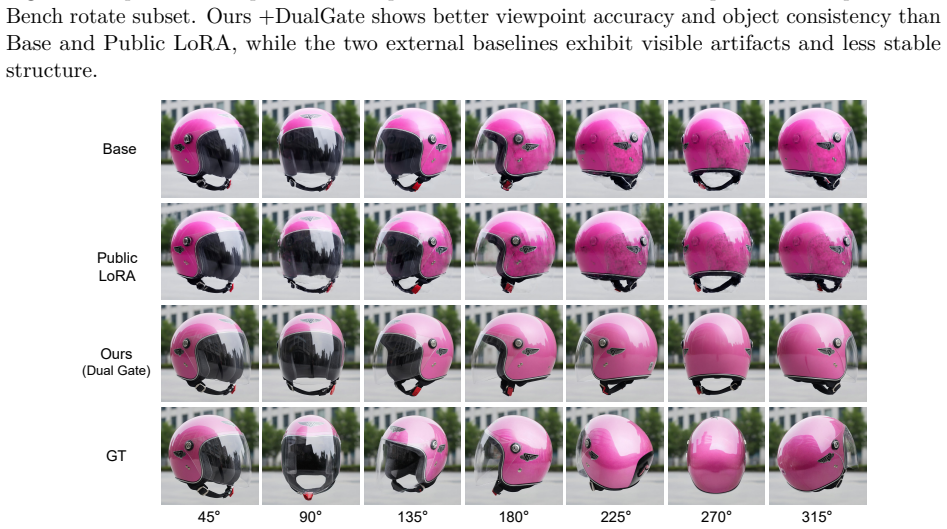
DataEvolver is a closed-loop visual data engine that organizes generation, inspection, correction, filtering, and export around explicit goals and acceptance decisions; its two coupled loops are generation-time self-correction within each sample and validation-time self-expansion across dataset rounds, and the resulting data yields models that outperform both unadapted baselines and public multi-angle adaptations on rotation benchmarks.
What carries the argument
The dual-loop engine that tracks goals, maintains persistent artifacts, applies bounded corrective actions, and makes acceptance decisions across generation-time self-correction and validation-time self-expansion.
If this is right
- Models trained on the evolved rotation data outperform both the unadapted base and a public multi-angle LoRA on SpatialEdit and a held-out set.
- Ablations show steady gains when moving from scene-aware generation to feedback-driven correction to dual-gated validation.
- The same loop structure supports multiple artifact types including RGB images, masks, depth maps, normal maps, meshes, poses, and trajectories.
- The framework supplies a reusable pattern of goal tracking, review, correction, and acceptance that can be applied to other visual dataset tasks.
Where Pith is reading between the lines
- The loop pattern could be extended to tasks beyond object rotation, such as more complex scene edits or video trajectories, to test whether gains scale.
- If the acceptance decisions reliably filter artifacts, the approach might lower the amount of human review needed for large visual datasets.
- Similar goal-driven loops might transfer to non-visual modalities where iterative refinement of training examples is also costly.
Load-bearing premise
That repeated self-correction inside samples and dual-gated validation across rounds will raise net data quality without introducing new artifacts or distribution shifts that hurt downstream performance.
What would settle it
Training a model on data produced by the full DataEvolver pipeline and observing that its accuracy on SpatialEdit and the held-out set is no higher than the unadapted base model.
Figures












read the original abstract
Constructing controllable visual data is a major bottleneck for image editing and multimodal understanding. Useful supervision is rarely produced by a single rendering pass; instead it emerges through iterative generation, inspection, correction, filtering, and export. We present DataEvolver, a closed-loop visual data engine that organizes this process around explicit goals, persistent artifacts, bounded corrective actions, and acceptance decisions. DataEvolver supports multiple artifact types, including RGB images, masks, depth maps, normal maps, meshes, poses, trajectories, and review traces. In the current release, the system operates through two coupled loops: generation-time self-correction within each sample and validation-time self-expansion across dataset rounds. We validate the framework on an image-level object-rotation setting. With a fixed Qwen-Edit LoRA probe, our final Ours+DualGate model outperforms both the unadapted base model and a public multi-angle LoRA on SpatialEdit and a held-out evaluation set. Ablations show a consistent improvement path from scene-aware generation to feedback-driven correction and dual-gated validation. Beyond the released rotation data, our main contribution is a reusable framework for building visual datasets through explicit goal tracking, review, correction, and acceptance loops.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DataEvolver, a closed-loop visual data engine that organizes dataset construction around explicit goals, persistent artifacts, bounded corrective actions, and acceptance decisions. It implements two coupled loops—generation-time self-correction within each sample and validation-time self-expansion across dataset rounds—supporting multiple artifact types including RGB images, masks, depth maps, normals, meshes, poses, trajectories, and review traces. The framework is validated on an image-level object-rotation task. With a fixed Qwen-Edit LoRA probe, the final Ours+DualGate model is reported to outperform both the unadapted base model and a public multi-angle LoRA on SpatialEdit and a held-out evaluation set. Ablations are said to demonstrate a consistent improvement path from scene-aware generation through feedback-driven correction to dual-gated validation. The main contribution is positioned as the reusable framework rather than the released rotation data alone.
Significance. If the empirical gains are substantiated, the work supplies a practical, reusable framework for iterative visual data construction that directly targets a recognized bottleneck in controllable image editing and multimodal understanding. The explicit separation of generation-time correction and validation-time expansion, combined with bounded actions and acceptance criteria, offers a structured alternative to single-pass rendering or purely manual curation. Credit is due for the multi-artifact support and the emphasis on persistent review traces, which could aid reproducibility and downstream auditing. The approach has clear potential to generalize beyond the rotation setting if the net-positive utility of the loops is confirmed.
major comments (2)
- [Validation and Ablation Results] The central empirical claim—that the final Ours+DualGate model outperforms the base and public multi-angle LoRA on SpatialEdit and the held-out set—is stated without any quantitative metrics, ablation tables, error bars, statistical tests, or experimental protocol details. This absence is load-bearing because the outperformance result is the primary evidence offered for the utility of the dual-loop framework.
- [System Design and Dual-Gate Mechanism] The description of the dual-gated validation loop does not specify the exact acceptance criteria, the distribution of corrective actions taken, or any measurement of introduced artifacts or distribution shifts. Without these, it is impossible to evaluate whether the self-expansion step produces net data-quality gains as assumed in the weakest link of the argument.
minor comments (2)
- [Abstract and §2] The abstract and system overview would benefit from a concise diagram or pseudocode summarizing the two coupled loops, the role of the DualGate, and the flow of artifacts between generation and validation rounds.
- [Notation and Terminology] Notation for the various artifact types and the Qwen-Edit LoRA probe is introduced without a dedicated table or glossary, making it harder to track which components are fixed versus adapted across experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below and will revise the manuscript accordingly to provide the missing quantitative evidence and system details.
read point-by-point responses
-
Referee: [Validation and Ablation Results] The central empirical claim—that the final Ours+DualGate model outperforms the base and public multi-angle LoRA on SpatialEdit and the held-out set—is stated without any quantitative metrics, ablation tables, error bars, statistical tests, or experimental protocol details. This absence is load-bearing because the outperformance result is the primary evidence offered for the utility of the dual-loop framework.
Authors: We agree that the outperformance claim requires explicit quantitative backing to substantiate the value of the dual-loop framework. The submitted manuscript states the result in the abstract and main text but does not include supporting tables, metrics, or protocol details. In the revised version we will add comprehensive ablation tables with concrete metrics (e.g., accuracy or success rates) on both SpatialEdit and the held-out set, direct comparisons to the base model and public multi-angle LoRA, error bars from repeated runs where available, a full description of the experimental protocol, and statistical significance tests. These additions will make the empirical support for the framework explicit and reproducible. revision: yes
-
Referee: [System Design and Dual-Gate Mechanism] The description of the dual-gated validation loop does not specify the exact acceptance criteria, the distribution of corrective actions taken, or any measurement of introduced artifacts or distribution shifts. Without these, it is impossible to evaluate whether the self-expansion step produces net data-quality gains as assumed in the weakest link of the argument.
Authors: We concur that additional specificity on the dual-gated validation loop is required to assess net quality gains. The current manuscript describes the high-level loop structure and the role of acceptance decisions but omits concrete criteria and statistics. In the revision we will expand the system-design section to state the exact acceptance criteria (including thresholds and decision rules), report the observed distribution of corrective actions (types and frequencies), and include an analysis of any introduced artifacts or distribution shifts together with measurements or observations on whether the self-expansion step yields net positive quality improvements. This will close the gap in evaluating the weakest link of the argument. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a system description of a closed-loop data engine with generation-time self-correction and validation-time self-expansion loops, validated empirically on an object-rotation task using a fixed Qwen-Edit LoRA probe. No mathematical derivations, equations, or fitted parameters are present. Central claims rest on reported performance gains and ablations on SpatialEdit and held-out sets rather than any self-referential definitions or reductions to inputs by construction. Self-citations, if present, are not load-bearing for the framework's validity, which is demonstrated through external benchmarks and reusable design.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cora: Correspondence-aware image editing using few step diffusion, 2025
Amirhossein Almohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, and Ali Mahdavi-Amiri. Cora: Correspondence-aware image editing using few step diffusion, 2025. URLhttps://arxiv.org/abs/2505.23907
-
[2]
arXiv preprint arXiv:2509.19296 (2025)
Sherwin Bahmani et al. Lyra: Generative 3D scene reconstruction via video diffusion model self-distillation, 2025. URLhttps://arxiv.org/abs/2509.19296
-
[3]
EditP23: 3D editing via propagation of image prompts to multi-view, 2025
Roi Bar-On, Dana Cohen-Bar, and Daniel Cohen-Or. EditP23: 3D editing via propagation of image prompts to multi-view, 2025. URLhttps://arxiv.org/abs/2506.20652
-
[4]
Blender: Free and open source 3D creation software.https://www.blen der.org/, 2026
Blender Foundation. Blender: Free and open source 3D creation software.https://www.blen der.org/, 2026. Accessed as an implementation tool reference
2026
-
[5]
Physx-3d: Physical- grounded 3d asset generation,
Ziang Cao, Zhaoxi Chen, Liang Pan, and Ziwei Liu. PhysX: Physical-grounded 3D asset generation, 2025. URLhttps://arxiv.org/abs/2507.12465
-
[6]
SAM 3: Segment anything with concepts,
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R"adle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane...
-
[7]
URLhttps://arxiv.org/abs/2511.16719
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
PartEdit: Fine-grained image editing using pre-trained diffusion models, 2025
Aleksandar Cvejic, Abdelrahman Eldesokey, and Peter Wonka. PartEdit: Fine-grained image editing using pre-trained diffusion models, 2025. URLhttps://arxiv.org/abs/2502.04050
-
[9]
Qwen-Image-Edit-2511-Multiple-Angles-LoRA
fal. Qwen-Image-Edit-2511-Multiple-Angles-LoRA. https://huggingface.co/fal/Qwen-Ima ge-Edit-2511-Multiple-Angles-LoRA, 2026. Hugging Face model card
2026
-
[10]
SPATIALGEN: Layout-guided 3D indoor scene generation, 2025
Chuan Fang, Heng Li, Yixun Liang, Jia Zheng, Yongsen Mao, Yuan Liu, Rui Tang, Zihan Zhou, and Ping Tan. SPATIALGEN: Layout-guided 3D indoor scene generation, 2025. URL https://arxiv.org/abs/2509.14981
-
[11]
Seed3D 1.0: From images to high-fidelity simulation-ready 3D assets, 2025
Jiashi Feng et al. Seed3D 1.0: From images to high-fidelity simulation-ready 3D assets, 2025. URLhttps://arxiv.org/abs/2510.19944. 27
-
[12]
Feng Han et al. UniREditBench: A unified reasoning-based image editing benchmark, 2025. URLhttps://arxiv.org/abs/2511.01295
-
[13]
Image editing as programs with diffusion models.arXiv preprint arXiv:2506.04158, 2025
Yujia Hu, Songhua Liu, Zhenxiong Tan, Xingyi Yang, and Xinchao Wang. Image editing as programs with diffusion models, 2025. URLhttps://arxiv.org/abs/2506.04158
-
[14]
arXiv preprint arXiv:2506.16504 , year=
Zeqiang Lai et al. Hunyuan3D 2.5: Towards high-fidelity 3D assets generation with ultimate details, 2025. URLhttps://arxiv.org/abs/2506.16504
-
[15]
Hunyuan3D Studio: End-to-end AI pipeline for game-ready 3D asset generation,
Biwen Lei et al. Hunyuan3D Studio: End-to-end AI pipeline for game-ready 3D asset generation,
- [16]
-
[17]
Lavida-o: Elastic large masked diffusion models for unified multimodal understanding and generation
Shufan Li, Jiuxiang Gu, Kangning Liu, Zhe Lin, Zijun Wei, Aditya Grover, and Jason Kuen. Lavida-O: Elastic large masked diffusion models for unified multimodal understanding and generation, 2025. URLhttps://arxiv.org/abs/2509.19244
-
[18]
Step1X-3D: Towards high-fidelity and controllable generation of textured 3D assets, 2025
Weiyu Li et al. Step1X-3D: Towards high-fidelity and controllable generation of textured 3D assets, 2025. URLhttps://arxiv.org/abs/2505.07747
-
[19]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu et al. Step1X-Edit: A practical framework for general image editing, 2025. URL https://arxiv.org/abs/2504.17761
work page internal anchor Pith review arXiv 2025
-
[20]
PICABench: How far are we from physically realistic image editing?, 2025
Yuandong Pu et al. PICABench: How far are we from physically realistic image editing?, 2025. URLhttps://arxiv.org/abs/2510.17681
-
[21]
Yusu Qian et al. Pico-Banana-400K: A large-scale dataset for text-guided image editing, 2025. URLhttps://arxiv.org/abs/2510.19808
-
[22]
Qwen-Image-Edit-2511.https://huggingface.co/Qwen/Qwen-Image-Edit-2 511, 2025
Qwen Team. Qwen-Image-Edit-2511.https://huggingface.co/Qwen/Qwen-Image-Edit-2 511, 2025. Hugging Face model card
2025
-
[23]
A scalable attention-based approach for image-to-3D texture mapping, 2025
Arianna Rampini, Kanika Madan, Bruno Roy, AmirHossein Zamani, and Derek Cheung. A scalable attention-based approach for image-to-3D texture mapping, 2025. URLhttps: //arxiv.org/abs/2509.05131
-
[24]
Papadopoulos
Marco Schouten, Mehmet Onurcan Kaya, Serge Belongie, and Dim P. Papadopoulos. POEM: Precise object-level editing via MLLM control, 2025. URLhttps://arxiv.org/abs/2504.0 8111
2025
-
[25]
Xiang Tang, Ruotong Li, and Xiaopeng Fan. ZeroScene: A zero-shot framework for 3D scene generation from a single image and controllable texture editing, 2025. URLhttps: //arxiv.org/abs/2509.23607
-
[26]
Team Hunyuan3D. Hunyuan3D 2.1: From images to high-fidelity 3D assets with production- ready PBR material, 2025. URLhttps://arxiv.org/abs/2506.15442
-
[27]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
SpatialEdit: Benchmarking fine-grained image spatial editing, 2026
Yicheng Xiao, Wenhu Zhang, Lin Song, Yukang Chen, Wenbo Li, Nan Jiang, Tianhe Ren, Haokun Lin, Wei Huang, Haoyang Huang, Xiu Li, Nan Duan, and Xiaojuan Qi. SpatialEdit: Benchmarking fine-grained image spatial editing, 2026. URLhttps://arxiv.org/abs/2604 .04911
2026
-
[29]
Advancing high-fidelity 3D and texture generation with 2.5D latents, 2025
Xin Yang, Jiantao Lin, Yingjie Xu, Haodong Li, and Yingcong Chen. Advancing high-fidelity 3D and texture generation with 2.5D latents, 2025. URLhttps://arxiv.org/abs/2505.21050
-
[30]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye et al. ImgEdit: A unified image editing dataset and benchmark, 2025. URL https://arxiv.org/abs/2505.20275
work page internal anchor Pith review arXiv 2025
-
[31]
I2E: From Image Pixels to Actionable Interactive Environments for Text-Guided Image Editing
Jinghan Yu et al. I2E: From image pixels to actionable interactive environments for text-guided image editing, 2026. URLhttps://arxiv.org/abs/2601.03741
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
GeoRemover: Removing objects and their causal visual artifacts, 2025
Zixin Zhu, Haoxiang Li, Xuelu Feng, He Wu, Chunming Qiao, and Junsong Yuan. GeoRemover: Removing objects and their causal visual artifacts, 2025. URLhttps://arxiv.org/abs/2509 .18538
2025
-
[33]
Zhentao Zou et al. Beyond textual CoT: Interleaved text-image chains with deep confidence reasoning for image editing, 2025. URLhttps://arxiv.org/abs/2510.08157. 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.