Recognition: 2 theorem links
· Lean TheoremMAGIC: Multi-Step Advantage-Gated Causal Influence for Multi-agent Reinforcement Learning
Pith reviewed 2026-05-12 02:39 UTC · model grok-4.3
The pith
MAGIC turns multi-step causal effects of one agent's actions into gated intrinsic rewards to improve coordination in multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
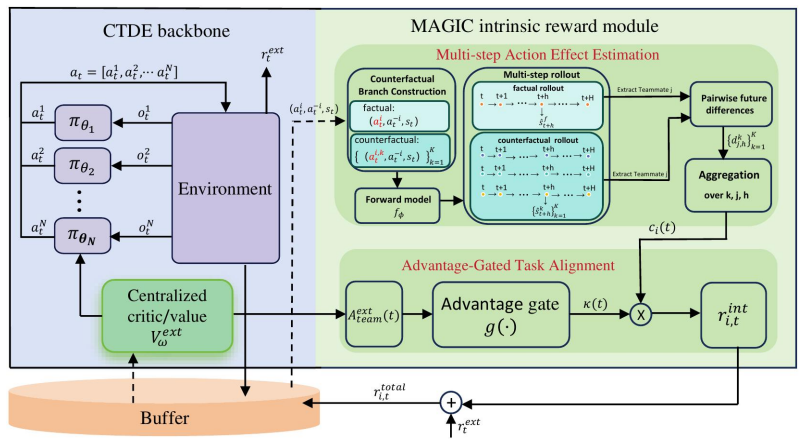
MAGIC estimates multi-step action effects between agents by comparing teammate futures under factual and counterfactual branches, and selectively converts them into intrinsic rewards using an advantage gate to direct exploration toward beneficial coordinated behaviors.
What carries the argument
The multi-step advantage-gated interventional causal estimator, which computes causal influences over future interaction steps via counterfactual interventions and gates them by advantage to produce intrinsic rewards.
If this is right
- Agents receive positive intrinsic rewards only for actions that produce measurable future benefits for teammates.
- Exploration is steered toward task-aligned coordination without requiring explicit communication channels.
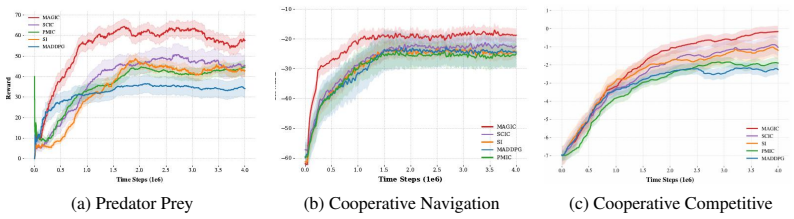
- The same framework produces consistent gains on both simple particle environments and complex StarCraft micromanagement tasks.
- Performance improvements average 26.9 percent relative on MPE and 10.1 percent on SMAC and SMACv2 compared with prior leading methods.
Where Pith is reading between the lines
- The method could be tested in partially observable settings where the model used for counterfactuals must be learned from limited data.
- Removing the advantage gate while keeping the causal estimates would likely reduce the focus on task-relevant influences.
- Similar causal gating could be applied to single-agent settings with long-horizon credit assignment.
- Real-world multi-robot teams might use learned models of teammate dynamics to generate comparable intrinsic rewards.
Load-bearing premise
Counterfactual action interventions in the learned or simulated model accurately isolate the true causal influence of one agent's action on teammates' future trajectories without confounding from environment dynamics or other agents.
What would settle it
A controlled experiment that perturbs the counterfactual model so that estimated causal influences no longer match true intervention outcomes, then checks whether the performance gains over baselines disappear.
Figures




read the original abstract
A key challenge in multi-agent reinforcement learning (MARL) lies in designing learning signals that effectively promote coordination among agents. Designing such signals requires estimating how one agent's current action affects its teammates over future interaction steps. To address this, we introduce Multi-step Advantage-Gated Interventional Causal MARL (MAGIC), a framework that estimates multi-step action effects between agents and selectively converts them into intrinsic rewards. MAGIC uses counterfactual action interventions to compare teammate futures under factual and counterfactual branches, and introduces a gate based on advantage to direct exploration toward beneficial behaviors aligned with the task goal. Experiments on Multi-Agent Particle Environments (MPE) and StarCraft micromanagement benchmarks (SMAC and SMACv2) show that MAGIC consistently outperforms leading prior methods, with average relative final performance improvements of 26.9% and 10.1%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAGIC, a framework for multi-agent reinforcement learning that estimates multi-step causal influences of one agent's actions on teammates via counterfactual interventions in a dynamics model, gates these estimates using an advantage function to generate intrinsic rewards, and thereby promotes coordination. Experiments on MPE, SMAC, and SMACv2 benchmarks report average relative performance gains of 26.9% and 10.1% over prior methods.
Significance. If the interventional estimates reliably isolate causal effects, the method offers a principled mechanism for shaping coordination signals in MARL that aligns exploration with task objectives. The scale of reported gains on established benchmarks indicates potential impact for cooperative MARL, provided the core causal isolation assumption holds under realistic stochasticity.
major comments (2)
- [§3.2] §3.2 (Multi-step Advantage-Gated Interventional Causal Influence): the counterfactual trajectory comparison is described as comparing factual and intervened branches, but the text does not specify whether the dynamics model is conditioned on the joint policy of all other agents or uses a fixed policy; without this, the estimator cannot be guaranteed to remove confounding from concurrent teammate actions and environment stochasticity.
- [§4.3] §4.3 (Ablation Studies): no ablation is reported that replaces the interventional causal estimator with a non-causal correlation-based alternative while keeping the advantage gate fixed; such a control is required to establish that the claimed 26.9% and 10.1% gains are attributable to the causal component rather than the gating or intrinsic-reward structure alone.
minor comments (2)
- [Tables 1-2] Table 1 and Table 2: variance or standard-error bars are not shown for the reported mean returns; this makes it difficult to assess whether the relative improvements are statistically reliable across random seeds.
- [§3.1] §3.1: the advantage-gate threshold is introduced as a hyper-parameter but its tuning procedure and sensitivity analysis are not detailed, even though it directly modulates which causal influences become intrinsic rewards.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate clarifications and additional experiments in the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Multi-step Advantage-Gated Interventional Causal Influence): the counterfactual trajectory comparison is described as comparing factual and intervened branches, but the text does not specify whether the dynamics model is conditioned on the joint policy of all other agents or uses a fixed policy; without this, the estimator cannot be guaranteed to remove confounding from concurrent teammate actions and environment stochasticity.
Authors: We agree that the current description in §3.2 is insufficiently precise on this point. The dynamics model in MAGIC is trained to predict next states from joint states and joint actions. During counterfactual rollouts, one agent's action is intervened upon while the actions of all other agents are sampled from their current policies (i.e., the model is conditioned on the joint policy). This design aims to isolate the intervened agent's causal effect while holding teammate behavior fixed. We will revise §3.2 to explicitly state this conditioning and the sampling procedure for other agents' actions, thereby clarifying how confounding from concurrent actions is addressed. revision: yes
-
Referee: [§4.3] §4.3 (Ablation Studies): no ablation is reported that replaces the interventional causal estimator with a non-causal correlation-based alternative while keeping the advantage gate fixed; such a control is required to establish that the claimed 26.9% and 10.1% gains are attributable to the causal component rather than the gating or intrinsic-reward structure alone.
Authors: We acknowledge that the existing ablations in §4.3 do not include this specific control. To isolate the contribution of the interventional estimator, we will add a new ablation that replaces the counterfactual intervention with a non-causal alternative (e.g., a simple lagged correlation between an agent's action and teammates' future returns) while retaining the advantage gate and intrinsic-reward structure. Results from this ablation on the MPE and SMAC benchmarks will be reported in the revised §4.3. revision: yes
Circularity Check
No significant circularity detected in MAGIC's derivation chain.
full rationale
The paper introduces MAGIC as a novel framework that defines multi-step interventional causal influence via counterfactual action branches in a learned or simulated dynamics model, then applies an advantage-based gate to convert those estimates into intrinsic rewards. These components are presented as explicit design choices rather than derived quantities. The reported performance gains (26.9% on MPE, 10.1% on SMAC/SMACv2) are empirical outcomes from benchmark experiments, not predictions that reduce by construction to fitted parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes that presuppose the target result appear in the abstract or described methodology; the derivation remains self-contained against external RL and causal inference primitives.
Axiom & Free-Parameter Ledger
free parameters (1)
- advantage gate threshold or scaling coefficient
axioms (1)
- domain assumption Counterfactual interventions can be performed accurately inside the environment or learned dynamics model
invented entities (1)
-
Multi-step Advantage-Gated Interventional Causal influence estimator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MAGIC uses counterfactual action interventions to compare teammate futures under factual and counterfactual branches, and introduces a gate based on advantage to direct exploration toward beneficial behaviors
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The scaled action effect score ci(t) measures how strongly the realized action of agent i changes teammate futures... gated with an extrinsic team advantage
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Exploration-Guided Reward Shaping for Reinforcement Learning under Sparse Rewards , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Situation-Dependent Causal Influence-Based Cooperative Multi-Agent Reinforcement Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[3]
Advances in Neural Information Processing Systems , volume=
LIIR: Learning Individual Intrinsic Reward in Multi-Agent Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
SMACv2: An Improved Benchmark for Cooperative Multi-Agent Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Potential-Based Reward Shaping for Intrinsic Motivation , author=. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=. 2024 , publisher=
work page 2024
-
[6]
Proceedings of the 36th International Conference on Machine Learning , series=
Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning , author=. Proceedings of the 36th International Conference on Machine Learning , series=. 2019 , publisher=
work page 2019
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Settling Decentralized Multi-Agent Coordinated Exploration by Novelty Sharing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
Proceedings of the 39th International Conference on Machine Learning , series=
PMIC: Improving Multi-Agent Reinforcement Learning with Progressive Mutual Information Collaboration , author=. Proceedings of the 39th International Conference on Machine Learning , series=. 2022 , publisher=
work page 2022
-
[9]
Proceedings of the 40th International Conference on Machine Learning , series=
Lazy Agents: A New Perspective on Solving Sparse Reward Problem in Multi-Agent Reinforcement Learning , author=. Proceedings of the 40th International Conference on Machine Learning , series=. 2023 , publisher=
work page 2023
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Imagine, Initialize, and Explore: An Effective Exploration Method in Multi-Agent Reinforcement Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
ELIGN: Expectation Alignment as a Multi-Agent Intrinsic Reward , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Qin, Haoyuan and Liu, Zhengzhu and Lin, Chenxing and Ma, Chennan and Mei, Songzhu and Shen, Siqi and Wang, Cheng , booktitle=. 2025 , publisher=
work page 2025
-
[14]
Rashid, Tabish and Samvelyan, Mikayel and Schroeder de Witt, Christian and Farquhar, Gregory and Foerster, Jakob and Whiteson, Shimon , booktitle=. 2018 , publisher=
work page 2018
-
[15]
The StarCraft Multi-Agent Challenge , author=. Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pages=
-
[16]
Advances in Neural Information Processing Systems , volume=
PettingZoo: Gym for Multi-Agent Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Efficient Potential-Based Exploration in Reinforcement Learning Using Inverse Dynamic Bisimulation Metric , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Advances in Neural Information Processing Systems , volume=
The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.