Recognition: unknown
Efficient representations for team and imperfect-recall equilibrium computation
Pith reviewed 2026-05-09 15:57 UTC · model grok-4.3
The pith
Timeable two-player zero-sum games with imperfect recall reduce exactly to equivalent perfect-recall belief games whose strategy spaces are represented compactly as a team belief DAG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce the belief game, a perfect-recall game equivalent to any given timeable two-player zero-sum game with imperfect recall, so that mixed-strategy Nash equilibria correspond exactly between the two. They show that the strategy spaces of the belief game can be represented directly as a directed acyclic graph called the team belief DAG. This representation enables standard regret-minimization techniques to run efficiently while satisfying optimal parameterized complexity bounds, and it is used to compute team maxmin equilibria (equivalent to the imperfect-recall setting) with experimental performance that matches or exceeds prior methods on benchmarks.
What carries the argument
The belief game, a perfect-recall game that is exactly equivalent to the given timeable imperfect-recall game, together with the team belief DAG (TB-DAG) that encodes the players' strategy spaces as a directed acyclic graph.
Load-bearing premise
The input games must be timeable so that their information sets allow a consistent temporal ordering of moves.
What would settle it
Enumerate all equilibria of a small timeable imperfect-recall game by brute force, construct its belief game, and check whether the equilibrium sets and values match exactly.
Figures





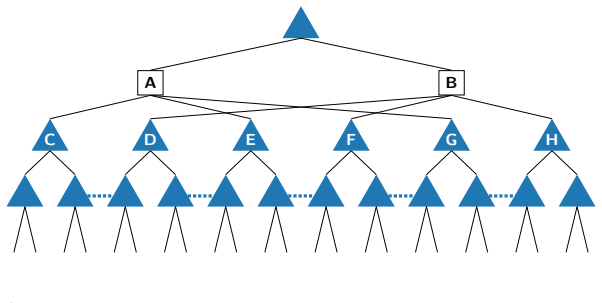

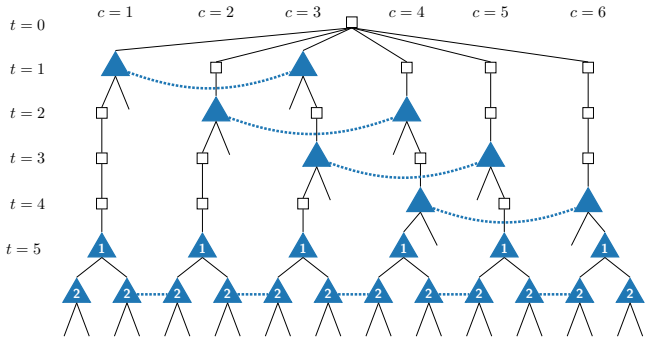
read the original abstract
Equilibrium finding in two-player zero-sum games with perfect recall is a well-studied topic that has led to many breakthroughs in computational game theory. This paper aims to generalize such techniques to (timeable) two-player zero-sum games with imperfect recall, or equivalently to two-team zero-sum games. In this setting, the problem of computing a mixed-strategy Nash equilibrium (or, equivalently, a team maxmin equilibrium with correlation) is known to be NP-hard. We connect the imperfect-recall setting with its perfect-recall counterpart through a novel construction we call the belief game. This is a perfect-recall game equivalent to a given (timeable) two-player zero-sum game with imperfect recall. The belief game may be exponentially larger than the original game but can be solved using any standard method. We then show that the strategy spaces of the two players in the belief game can be directly represented as a DAG, leading to a possibly exponential speedup. We call this the team belief DAG (TB-DAG). The TB-DAG simultaneously enjoys essentially optimal parameterized complexity bounds and the advantages of efficient regret minimization techniques. Along the way, we show $\Delta_2^P$-completeness and $\Sigma_2^P$-completeness of finding Nash equilibria in both mixed and behavioral strategies for the class of games we consider. Experimentally, we show that the TB-DAG, when paired with existing learning techniques, yields state-of-the-art performance on a wide variety of benchmark team games.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for timeable two-player zero-sum games with imperfect recall (equivalently, two-team zero-sum games), a novel belief-game construction yields an equivalent perfect-recall game whose equilibria (value, mixed, and behavioral strategies) correspond exactly to those of the original game. This allows standard perfect-recall solvers to be applied. The strategy spaces are then represented as a team belief DAG (TB-DAG) that supports efficient regret minimization and achieves essentially optimal parameterized complexity. The paper also proves Δ₂^P-completeness for mixed-strategy Nash equilibria and Σ₂^P-completeness for behavioral-strategy equilibria, and reports state-of-the-art experimental results on benchmark team games.
Significance. If the equivalence holds, the work is significant because it provides a principled reduction from an NP-hard imperfect-recall setting to perfect-recall equilibrium computation, together with a compact DAG representation that preserves the advantages of regret-minimization algorithms while attaining tight parameterized complexity bounds. The experimental results further suggest immediate practical utility for solving larger team games.
major comments (2)
- [belief game definition] Abstract and belief-game construction: the central claim that the belief game is exactly equivalent (preserving value and all mixed/behavioral equilibria) rests on the details of how information sets are formed across non-recall points and how terminal payoffs are lifted. Any implicit assumption in this mapping would invalidate both the theoretical reduction and the subsequent TB-DAG representation; the manuscript must supply an explicit, self-contained argument that every equilibrium maps back without distortion.
- [complexity results] Complexity section: the Δ₂^P-completeness (mixed) and Σ₂^P-completeness (behavioral) results are load-bearing for the paper's positioning; the reductions must be shown to apply precisely to the class of timeable games and to both the original and belief-game formulations.
minor comments (2)
- [preliminaries] Clarify the precise definition of 'timeable' and confirm that all experimental instances satisfy it.
- [experiments] The experimental section should report the exact baselines, number of runs, and any data-exclusion criteria to support the state-of-the-art claim.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each major comment below and have revised the manuscript to strengthen the presentation of the belief-game equivalence and the complexity results.
read point-by-point responses
-
Referee: Abstract and belief-game construction: the central claim that the belief game is exactly equivalent (preserving value and all mixed/behavioral equilibria) rests on the details of how information sets are formed across non-recall points and how terminal payoffs are lifted. The manuscript must supply an explicit, self-contained argument that every equilibrium maps back without distortion.
Authors: We agree that a fully explicit mapping strengthens the central claim. Section 3 defines the belief game by augmenting each information set with a belief state over histories that differ only in non-recall actions, and terminal payoffs are lifted by taking the expectation under the belief. Theorem 1 proves that this construction preserves the game value and induces a bijection on mixed strategies (with behavioral strategies obtained via the standard realization-equivalence argument). To address the referee's request for a self-contained argument, the revised manuscript adds a new subsection (3.3) that explicitly constructs the inverse mapping from any equilibrium of the belief game back to the original game, showing that no distortion occurs at non-recall points. This addition is self-contained and does not rely on external results. revision: yes
-
Referee: Complexity section: the Δ₂^P-completeness (mixed) and Σ₂^P-completeness (behavioral) results are load-bearing for the paper's positioning; the reductions must be shown to apply precisely to the class of timeable games and to both the original and belief-game formulations.
Authors: The hardness results in Section 5 are proven directly for timeable two-player zero-sum games with imperfect recall (the exact class considered throughout the paper). The reductions are from 3SAT and quantified Boolean formulas, respectively, and are constructed so that the resulting game instances are timeable. Because the belief-game construction is shown to be polynomial-time equivalent (value and equilibria preserved), the same complexity bounds apply verbatim to the belief-game formulation. In the revision we have added a short paragraph at the end of Section 5 that explicitly states this transfer and confirms that all reductions remain valid under the timeability restriction. revision: yes
Circularity Check
No circularity: belief-game construction is an explicit definition from the input game tree
full rationale
The paper's central step is the explicit, constructive definition of the belief game as a perfect-recall game whose information sets, actions, and payoffs are built directly from the original timeable imperfect-recall game tree. Equivalence of equilibria (including value and strategy mappings) is established by this construction rather than by any reduction to a fitted parameter, self-referential equation, or prior self-citation that itself assumes the result. The TB-DAG representation is then obtained by re-expressing the belief-game strategy spaces as a DAG; this is a representational transformation, not a circular renaming. Complexity results are stated as separate proofs. No load-bearing claim reduces to its own inputs by construction, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Games under consideration are timeable two-player zero-sum games
- standard math Standard extensive-form game semantics and Nash equilibrium definitions apply
invented entities (2)
-
belief game
no independent evidence
-
team belief DAG (TB-DAG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Miller, Sasha Mitts, Adithya Renduchintala, Stephen Roller, Dirk Rowe, Weiyan Shi, Joe Spisak, Alexander Wei, David Wu, Hugh Zhang, and Markus Zijlstra
Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, Athul Paul Jacob, Mojtaba Komeili, Karthik Konath, Minae Kwon, Adam Lerer, Mike Lewis, Alexander H. Miller, Sasha Mitts, Adithya Renduchintala, Stephen Roller, Dirk Rowe, Weiyan Shi, Joe Spisak, Alexander Wei, David Wu, Hugh Zhan...
2022
-
[2]
Heads-up limit hold’em poker is solved.Science, 347(6218), January 2015
Michael Bowling, Neil Burch, Michael Johanson, and Oskari Tammelin. Heads-up limit hold’em poker is solved.Science, 347(6218), January 2015
2015
-
[3]
Safe and nested subgame solving for imperfect-information games
Noam Brown and Tuomas Sandholm. Safe and nested subgame solving for imperfect-information games. InConference on Neural Information Processing Systems (NeurIPS), 2017
2017
-
[4]
Superhuman AI for heads-up no-limit poker: Libratus beats top professionals.Science, 359(6374):418–424, 2018
Noam Brown and Tuomas Sandholm. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals.Science, 359(6374):418–424, 2018
2018
-
[5]
Solving imperfect-information games via discounted regret minimization
Noam Brown and Tuomas Sandholm. Solving imperfect-information games via discounted regret minimization. InAAAI Conference on Artificial Intelligence (AAAI), 2019
2019
-
[6]
Superhuman AI for multiplayer poker.Science, 365(6456):885–890, 2019
Noam Brown and Tuomas Sandholm. Superhuman AI for multiplayer poker.Science, 365(6456):885–890, 2019
2019
-
[7]
Princeton University Press, 2003
Colin Camerer.Behavioral Game Theory: Experiments in Strategic Interaction. Princeton University Press, 2003
2003
-
[8]
Public information representa- tion for adversarial team games
Luca Carminati, Federico Cacciamani, Marco Ciccone, and Nicola Gatti. Public information representa- tion for adversarial team games. InNeurIPS Cooperative AI Workshop, 2021
2021
-
[9]
Computational results for extensive-form adversarial team games
Andrea Celli and Nicola Gatti. Computational results for extensive-form adversarial team games. In Proceedings of the AAAI Conference on Artificial Intelligence, number 1, 2018
2018
-
[10]
Approximating maxmin strategies in imperfect recall games using a-loss recall property.International Journal of Approximate Reasoning, 93:290–326, 2018
Jiří Čermák, Branislav Bošansk` y, Karel Horák, Viliam Lis` y, and Michal Pěchouček. Approximating maxmin strategies in imperfect recall games using a-loss recall property.International Journal of Approximate Reasoning, 93:290–326, 2018
2018
-
[11]
Tight lower bounds for certain parameterized NP-hard problems.Information and Computation, 201(2): 216–231, 2005
Jianer Chen, Benny Chor, Mike Fellows, Xiuzhen Huang, David Juedes, Iyad A Kanj, and Ge Xia. Tight lower bounds for certain parameterized NP-hard problems.Information and Computation, 201(2): 216–231, 2005. 33
2005
-
[12]
On the NP-completeness of finding an optimal strategy in games with common payoffs.International Journal of Game Theory, 2001
Francis Chu and Joseph Halpern. On the NP-completeness of finding an optimal strategy in games with common payoffs.International Journal of Game Theory, 2001
2001
-
[13]
Polynomial-time computation of optimal correlated equilibria in two-player extensive-form games with public chance moves and beyond
Gabriele Farina and Tuomas Sandholm. Polynomial-time computation of optimal correlated equilibria in two-player extensive-form games with public chance moves and beyond. InConference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[14]
Ex ante coordination and collusion in zero-sum multi-player extensive-form games
Gabriele Farina, Andrea Celli, Nicola Gatti, and Tuomas Sandholm. Ex ante coordination and collusion in zero-sum multi-player extensive-form games. InConference on Neural Information Processing Systems (NeurIPS), 2018
2018
-
[15]
Regret circuits: Composability of regret minimizers
Gabriele Farina, Christian Kroer, and Tuomas Sandholm. Regret circuits: Composability of regret minimizers. InInternational Conference on Machine Learning, 2019
2019
-
[16]
Connecting optimal ex-ante collusion in teams to extensive-form correlation: Faster algorithms and positive complexity results
Gabriele Farina, Andrea Celli, Nicola Gatti, and Tuomas Sandholm. Connecting optimal ex-ante collusion in teams to extensive-form correlation: Faster algorithms and positive complexity results. InInternational Conference on Machine Learning, 2021
2021
-
[17]
Faster game solving via predictive Blackwell approachability: Connecting regret matching and mirror descent
Gabriele Farina, Christian Kroer, and Tuomas Sandholm. Faster game solving via predictive Blackwell approachability: Connecting regret matching and mirror descent. InAAAI Conference on Artificial Intelligence (AAAI), 2021
2021
-
[18]
Bayesian action decoder for deep multi-agent reinforcement learning
Jakob Foerster, Francis Song, Edward Hughes, Neil Burch, Iain Dunning, Shimon Whiteson, Matthew Botvinick, and Michael Bowling. Bayesian action decoder for deep multi-agent reinforcement learning. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, 2019
2019
-
[19]
Endgame solving in large imperfect-information games
Sam Ganzfried and Tuomas Sandholm. Endgame solving in large imperfect-information games. In International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS), 2015
2015
-
[20]
A competitive Texas Hold’em poker player via automated abstraction and real-time equilibrium computation
Andrew Gilpin and Tuomas Sandholm. A competitive Texas Hold’em poker player via automated abstraction and real-time equilibrium computation. InNational Conference on Artificial Intelligence (AAAI), 2006
2006
-
[21]
Srivathsan
Hugo Gimbert, Soumyajit Paul, and B. Srivathsan. A bridge between polynomial optimization and games with imperfect recall. InAutonomous Agents and Multi-Agent Systems, 2020
2020
-
[22]
Grotschel, L
M. Grotschel, L. Lovász, and A. Schrijver.Geometric Algorithms and Combinatorial Optimizations. Springer-Verlag, 1993
1993
-
[23]
A simple adaptive procedure leading to correlated equilibrium
Sergiu Hart and Andreu Mas-Colell. A simple adaptive procedure leading to correlated equilibrium. Econometrica, 68:1127–1150, 2000
2000
-
[24]
Some optimal inapproximability results.Journal of the ACM (JACM), 48(4):798–859, 2001
Johan Håstad. Some optimal inapproximability results.Journal of the ACM (JACM), 48(4):798–859, 2001
2001
-
[25]
Defender (mis)coordination in security games
Albert Xin Jiang, Ariel Procaccia, Yundi Qian, Nisarg Shah, and Milind Tambe. Defender (mis)coordination in security games. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2013
2013
-
[26]
Measuring the size of large no-limit poker games
Michael Johanson. Measuring the size of large no-limit poker games. Technical report, University of Alberta, 2013
2013
-
[27]
Behavior strategies, mixed strategies and perfect recall.International Journal of Game Theory, 24(2):127–145, 1995
Mamoru Kaneko and J Jude Kline. Behavior strategies, mixed strategies and perfect recall.International Journal of Game Theory, 24(2):127–145, 1995
1995
-
[28]
The complexity of two-person zero-sum games in extensive form
Daphne Koller and Nimrod Megiddo. The complexity of two-person zero-sum games in extensive form. Games and Economic Behavior, 4(4):528–552, October 1992. 34
1992
-
[29]
Rethinking formal models of partially observable multiagent decision making.Artificial Intelligence, 303:1036–45, 2022
Vojtěch Kovařík, Martin Schmid, Neil Burch, Michael Bowling, and Viliam Lis` y. Rethinking formal models of partially observable multiagent decision making.Artificial Intelligence, 303:1036–45, 2022
2022
-
[30]
The complexity of optimization problems.Journal of computer and system sciences, 36(3):490–509, 1988
Mark W Krentel. The complexity of optimization problems.Journal of computer and system sciences, 36(3):490–509, 1988
1988
-
[31]
Imperfect-recall abstractions with bounds in games
Christian Kroer and Tuomas Sandholm. Imperfect-recall abstractions with bounds in games. InACM Conference on Economics and Computation (EC), 2016
2016
-
[32]
H. W. Kuhn. Extensive games.Proc. of the National Academy of Sciences, 36:570–576, 1950
1950
-
[33]
H. W. Kuhn. A simplified two-person poker. InContributions to the Theory of Games, volume 1 of Annals of Mathematics Studies, 24, pages 97–103. 1950
1950
-
[34]
H. W. Kuhn. Extensive games and the problem of information. InContributions to the Theory of Games, volume 2 ofAnnals of Mathematics Studies, 28, pages 193–216. 1953
1953
-
[35]
No-regret learning in extensive-form games with imperfect recall
Marc Lanctot, Richard Gibson, Neil Burch, Martin Zinkevich, and Michael Bowling. No-regret learning in extensive-form games with imperfect recall. InInternational Conference on Machine Learning (ICML), 2012
2012
-
[36]
Onlinemontecarlocounterfactualregretminimization for search in imperfect information games
ViliamLis` y, MarcLanctot, andMichaelHBowling. Onlinemontecarlocounterfactualregretminimization for search in imperfect information games. InAutonomous Agents and Multi-Agent Systems, 2015
2015
-
[37]
H. B. McMahan, Geoffrey J. Gordon, and Avrim Blum. Planning in the presence of cost functions controlled by an adversary. InInternational Conference on Machine Learning, 2003
2003
-
[38]
Refining subgames in large imperfect information games
Matej Moravcik, Martin Schmid, Karel Ha, Milan Hladik, and Stephen Gaukrodger. Refining subgames in large imperfect information games. InAAAI Conference on Artificial Intelligence (AAAI), 2016
2016
-
[39]
Deepstack: Expert-level artificial intelligence in heads-up no-limit poker.Science, May 2017
Matej Moravčík, Martin Schmid, Neil Burch, Viliam Lisý, Dustin Morrill, Nolan Bard, Trevor Davis, Kevin Waugh, Michael Johanson, and Michael Bowling. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker.Science, May 2017
2017
-
[40]
Decentralized stochastic control with partial history sharing: A common information approach.IEEE Transactions on Automatic Control, 58 (7):1644–1658, 2013
Ashutosh Nayyar, Aditya Mahajan, and Demosthenis Teneketzis. Decentralized stochastic control with partial history sharing: A common information approach.IEEE Transactions on Automatic Control, 58 (7):1644–1658, 2013
2013
-
[41]
Connor, Neil Burch, Thomas Anthony, Stephen McAleer, Romuald Elie, Sarah H
Julien Perolat, Bart De Vylder, Daniel Hennes, Eugene Tarassov, Florian Strub, Vincent de Boer, Paul Muller, Jerome T. Connor, Neil Burch, Thomas Anthony, Stephen McAleer, Romuald Elie, Sarah H. Cen, Zhe Wang, Audrunas Gruslys, Aleksandra Malysheva, Mina Khan, Sherjil Ozair, Finbarr Timbers, Toby Pohlen, Tom Eccles, Mark Rowland, Marc Lanctot, Jean-Baptis...
2022
-
[42]
On the interpretation of decision problems with imperfect recall
Michele Piccione and Ariel Rubinstein. On the interpretation of decision problems with imperfect recall. Games and Economic Behavior, 20:3–24, 1997
1997
-
[43]
Romanovskii
I. Romanovskii. Reduction of a game with complete memory to a matrix game.Soviet Mathematics, 3, 1962
1962
-
[44]
Settling the complexity of computing approximate two-player nash equilibria.ACM SIGecom Exchanges, 15(2):45–49, 2017
Aviad Rubinstein. Settling the complexity of computing approximate two-player nash equilibria.ACM SIGecom Exchanges, 15(2):45–49, 2017
2017
-
[45]
Abstraction for solving large incomplete-information games
Tuomas Sandholm. Abstraction for solving large incomplete-information games. InAAAI Conference on Artificial Intelligence (AAAI), 2015. Senior Member Track. 35
2015
-
[46]
Solving imperfect-information games.Science, 347(6218):122–123, 2015
Tuomas Sandholm. Solving imperfect-information games.Science, 347(6218):122–123, 2015
2015
-
[47]
Completeness in the polynomial-time hierarchy: A compendium
Marcus Schaefer and Christopher Umans. Completeness in the polynomial-time hierarchy: A compendium. SIGACT News, 33(3):32–49, 2002
2002
-
[48]
Bayes’ bluff: Opponent modelling in poker
Finnegan Southey, Michael Bowling, Bryce Larson, Carmelo Piccione, Neil Burch, Darse Billings, and Chris Rayner. Bayes’ bluff: Opponent modelling in poker. InConference on Uncertainty in Artificial Intelligence (UAI), 2005
2005
-
[49]
Solving heads-up limit Texas hold’em
Oskari Tammelin, Neil Burch, Michael Johanson, and Michael Bowling. Solving heads-up limit Texas hold’em. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2015
2015
-
[50]
Goldberg
Emanuel Tewolde, Caspar Oesterheld, Vincent Conitzer, and Paul W. Goldberg. The computational complexity of single-player imperfect-recall games. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2023
2023
-
[51]
Zur Theorie der Gesellschaftsspiele.Mathematische Annalen, 100:295–320, 1928
John von Neumann. Zur Theorie der Gesellschaftsspiele.Mathematische Annalen, 100:295–320, 1928
1928
-
[52]
Efficient computation of behavior strategies.Games and Economic Behavior, 14 (2):220–246, 1996
Bernhard von Stengel. Efficient computation of behavior strategies.Games and Economic Behavior, 14 (2):220–246, 1996
1996
-
[53]
Extensive-form correlated equilibrium: Definition and computational complexity.Mathematics of Operations Research, 33(4):1002–1022, 2008
Bernhard von Stengel and Françoise Forges. Extensive-form correlated equilibrium: Definition and computational complexity.Mathematics of Operations Research, 33(4):1002–1022, 2008
2008
-
[54]
Team-maxmin equilibria.Games and Economic Behavior, 21 (1):309–321, 1997
Bernhard von Stengel and Daphne Koller. Team-maxmin equilibria.Games and Economic Behavior, 21 (1):309–321, 1997
1997
-
[55]
Now Publishers Inc, 2008
Martin J Wainwright and Michael Irwin Jordan.Graphical models, exponential families, and variational inference. Now Publishers Inc, 2008
2008
-
[56]
Abstraction in large extensive games
Kevin Waugh. Abstraction in large extensive games. Master’s thesis, University of Alberta, 2009
2009
-
[57]
Polynomial-time optimal equilibria with a mediator in extensive- form games
Brian Hu Zhang and Tuomas Sandholm. Polynomial-time optimal equilibria with a mediator in extensive- form games. InConference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[58]
Team correlated equilibria in zero-sum extensive-form games via tree decompositions
Brian Hu Zhang and Tuomas Sandholm. Team correlated equilibria in zero-sum extensive-form games via tree decompositions. InAAAI Conference on Artificial Intelligence (AAAI), 2022
2022
-
[59]
Optimal correlated equilibria in general-sum extensive-form games: Fixed-parameter algorithms, hardness, and two-sided column- generation
Brian Hu Zhang, Gabriele Farina, Andrea Celli, and Tuomas Sandholm. Optimal correlated equilibria in general-sum extensive-form games: Fixed-parameter algorithms, hardness, and two-sided column- generation. InACM Conference on Economics and Computation (EC), 2022
2022
-
[60]
Computing optimal equilibria and mechanisms via learning in zero-sum extensive-form games
Brian Hu Zhang, Gabriele Farina, Ioannis Anagnostides, Federico Cacciamani, Stephen Marcus McAleer, Andreas Alexander Haupt, Andrea Celli, Nicola Gatti, Vincent Conitzer, and Tuomas Sandholm. Computing optimal equilibria and mechanisms via learning in zero-sum extensive-form games. In Conference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[61]
EfficientΦ-regret minimization with low-degree swap deviations in extensive-form games, 2024
Brian Hu Zhang, Ioannis Anagnostides, Gabriele Farina, and Tuomas Sandholm. EfficientΦ-regret minimization with low-degree swap deviations in extensive-form games, 2024. arXiv
2024
-
[62]
Mediator interpretation and faster learning algorithms for linear correlated equilibria in general extensive-form games
Brian Hu Zhang, Gabriele Farina, and Tuomas Sandholm. Mediator interpretation and faster learning algorithms for linear correlated equilibria in general extensive-form games. InInternational Conference on Learning Representations, 2024
2024
-
[63]
Faster game solving via hyperparameter schedules.arXiv preprint arXiv:2404.09097, 2024
Naifeng Zhang, Stephen McAleer, and Tuomas Sandholm. Faster game solving via hyperparameter schedules.arXiv preprint arXiv:2404.09097, 2024. 36
-
[64]
Converging to team-maxmin equilibria in zero-sum multiplayer games
Youzhi Zhang and Bo An. Converging to team-maxmin equilibria in zero-sum multiplayer games. In International Conference on Machine Learning (ICML), 2020
2020
-
[65]
Computing ex ante coordinated team-maxmin equilibria in zero-sum multiplayer extensive-form games
Youzhi Zhang, Bo An, and Jakub Čern` y. Computing ex ante coordinated team-maxmin equilibria in zero-sum multiplayer extensive-form games. InAAAI Conference on Artificial Intelligence (AAAI), 2021
2021
-
[66]
Online convex programming and generalized infinitesimal gradient ascent
Martin Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. In International Conference on Machine Learning (ICML), 2003
2003
-
[67]
Regret minimization in games with incomplete information
Martin Zinkevich, Michael Bowling, Michael Johanson, and Carmelo Piccione. Regret minimization in games with incomplete information. InConference on Neural Information Processing Systems (NeurIPS), 2007. AppendixA. Omitted Proofs from Section 5 Proposition 5.2.Let R and ˆR be as in AlgorithmDAG-Generic. Then the regret ofR with utility sequence u1, . . . ...
2007
-
[68]
If▼has perfect recall, it is inNP. Proof. Consider a behavioral max-min strategy represented by a distribution over the actions at each information set I. Let δ > 0, and consider rounding each entry of the behavioral-form strategy by at most an additive δ so that the resulting strategy is rational. Let x′ be the correlation plan of the resulting strategy....
-
[69]
This starkly contrasts the earlier counterexample, in which inflation was enough to achieve a small representation
No infoset inflates: all nontrivial infosets have size2, and it is easy to check that for all such infosets it is always possible to play to both nodes in them. This starkly contrasts the earlier counterexample, in which inflation was enough to achieve a small representation
-
[70]
Therefore, if using public-state-based beliefs, there will be a belief with2C/2 prescriptions
Every P2-node in layerC− 1is in the same public state, and it is always possible to play to at least C/2of them. Therefore, if using public-state-based beliefs, there will be a belief with2C/2 prescriptions. Thus, the public-state-based team belief DAG, will have a size of at least2C/2. We claim that layert≤C− 1does not have too many beliefs. LetB⊆ H t be...
-
[71]
the nodes ofJare subsets ofV, calledbags
-
[72]
for each edge(u, v)∈E, there is a bag containing bothuandv; and
-
[73]
Consider an arbitrary set of the form Π ={x∈ {0,1} n :g k(x) = 0∀k∈[m]} where the gks are arbitrary constraints, and as before letX = co Π
for each vertexu∈V, the subset of nodes ofJwhose bags containuis connected. Consider an arbitrary set of the form Π ={x∈ {0,1} n :g k(x) = 0∀k∈[m]} where the gks are arbitrary constraints, and as before letX = co Π. Each constraintgk has ascope Sk ⊆ [n] of variables on which it depends. Thedependency graphofΠis the graph GΠ whose nodes are the integers 1,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.