Recognition: unknown
DP-SfM: Dual-Pixel Structure-from-Motion without Scale Ambiguity
Pith reviewed 2026-05-10 14:54 UTC · model grok-4.3
The pith
Dual-pixel sensor images resolve the unknown scale in multi-view 3D reconstruction without reference objects or calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
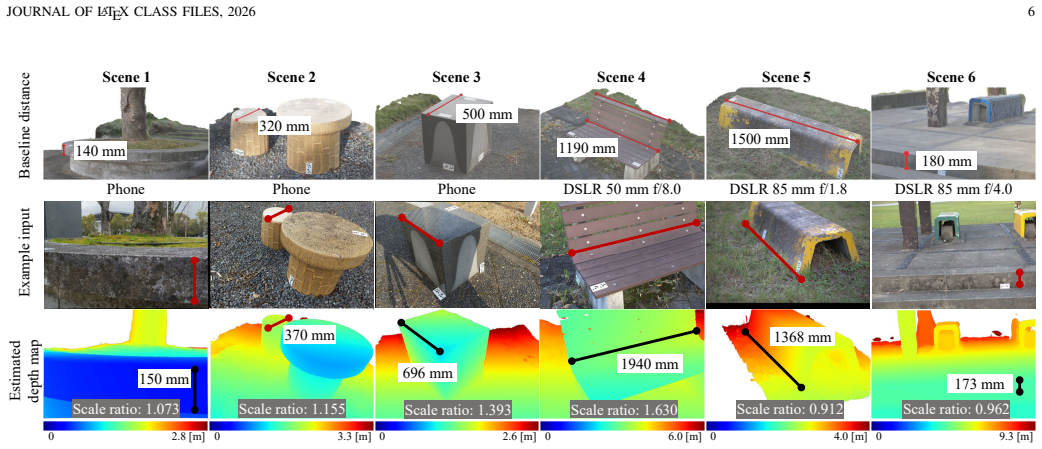
The paper establishes that multi-view images captured using a dual-pixel sensor can automatically resolve the scale ambiguity in structure-from-motion. The defocus blur observed in DP images provides sufficient information to determine the absolute scale when paired with depth maps recovered from multi-view 3D reconstruction. The authors present a simple linear method to estimate this absolute scale, followed by an intensity-based optimization stage that aligns the left and right DP images by shifting them back toward each other using cross-view blur kernels.
What carries the argument
The linear scale estimator that pairs defocus blur measurements from dual-pixel left-right images with up-to-scale depth maps from SfM, followed by cross-view blur-kernel alignment optimization.
Load-bearing premise
The defocus blur in dual-pixel images encodes reliable absolute-scale information once combined with the up-to-scale depths produced by standard structure-from-motion.
What would settle it
A controlled scene containing a measured object or baseline distance in which the scale recovered by the linear estimator and optimization deviates from the known physical ground truth.
Figures




read the original abstract
Multi-view 3D reconstruction, namely, structure-from-motion followed by multi-view stereo, is a fundamental component of 3D computer vision. In general, multi-view 3D reconstruction suffers from an unknown scale ambiguity unless a reference object of known size is present in the scene. In this article, we show that multi-view images captured using a dual-pixel (DP) sensor can automatically resolve the scale ambiguity, without requiring a reference object or prior calibration. Specifically, the defocus blur observed in DP images provides sufficient information to determine the absolute scale when paired with depth maps (up to scale) recovered from multi-view 3D reconstruction. Based on this observation, we develop a simple yet effective linear method to estimate the absolute scale, followed by the intensity-based optimization stage that aligns the left and right DP images by shifting them back toward each other using cross-view blur kernels. Experiments demonstrate the effectiveness of the proposed approach across diverse scenes captured with different cameras and lenses. Code and data are available at https://github.com/lilika-makabe/dp-sfm-tpami.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that dual-pixel (DP) sensors in multi-view images can resolve the scale ambiguity inherent in structure-from-motion (SfM) reconstructions. It shows that defocus blur observed in DP left/right views supplies an absolute-scale constraint when combined with up-to-scale depth maps from SfM, via a linear estimator for the scale factor followed by an intensity-based optimization that aligns the views by shifting them according to cross-view blur kernels. Experiments on diverse scenes with multiple cameras and lenses are reported to validate the approach, with code and data released.
Significance. If the central claim holds, the work provides a practical, calibration-free route to metric 3D reconstruction that exploits hardware already present in many consumer cameras. The linear formulation, explicit use of the thin-lens defocus model, and release of reproducible code strengthen the contribution relative to prior scale-recovery techniques that require known objects or additional sensors.
major comments (2)
- [§4.2, Eq. (7)] §4.2, Eq. (7): the linear scale estimator assumes that the observed DP disparity is exactly proportional to the reciprocal of the SfM depth scaled by the unknown factor s; however, the derivation does not explicitly bound the error introduced when the thin-lens approximation deviates from the actual lens (e.g., spherical aberration or aperture-dependent effects). A sensitivity analysis or synthetic ablation under realistic lens models would be needed to confirm that the estimator remains unbiased.
- [§5.3, Table 2] §5.3, Table 2: the reported scale-error reductions are shown only for scenes where the DP baseline is non-zero and the focal plane is within the depth range; no quantitative results are given for the failure regime where the entire scene lies at the focal plane (zero blur), which would make the linear system singular. Clarifying the practical operating range is load-bearing for the claim of automatic scale recovery.
minor comments (3)
- The notation for the left/right DP images (I_L, I_R) and the corresponding blur kernels is introduced without a clear diagram; adding a figure that illustrates the cross-view shift and kernel alignment would improve readability.
- [§4] Several equations in §4 use the symbol d for both scene depth and DP disparity; a brief disambiguation sentence or consistent subscripting would prevent confusion.
- The abstract states that the method works 'without requiring a reference object or prior calibration,' yet the experiments implicitly rely on known camera intrinsics from the SfM stage; a short clarification in the introduction would align the claim with the actual pipeline.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. The comments highlight important aspects of the method's assumptions and operating range. We address each point below and will revise the manuscript accordingly to incorporate clarifications and additional analysis.
read point-by-point responses
-
Referee: [§4.2, Eq. (7)] §4.2, Eq. (7): the linear scale estimator assumes that the observed DP disparity is exactly proportional to the reciprocal of the SfM depth scaled by the unknown factor s; however, the derivation does not explicitly bound the error introduced when the thin-lens approximation deviates from the actual lens (e.g., spherical aberration or aperture-dependent effects). A sensitivity analysis or synthetic ablation under realistic lens models would be needed to confirm that the estimator remains unbiased.
Authors: The linear estimator in §4.2 is derived under the thin-lens model, which is the standard approximation employed throughout the dual-pixel and defocus literature. While real lenses can introduce higher-order effects such as spherical aberration, the multi-camera, multi-lens experiments in §5 demonstrate consistent and accurate scale recovery on real data. To directly address the concern about potential bias, we will add a sensitivity analysis using synthetic data rendered with more realistic lens models (e.g., incorporating spherical aberration) in the revised manuscript. revision: yes
-
Referee: [§5.3, Table 2] §5.3, Table 2: the reported scale-error reductions are shown only for scenes where the DP baseline is non-zero and the focal plane is within the depth range; no quantitative results are given for the failure regime where the entire scene lies at the focal plane (zero blur), which would make the linear system singular. Clarifying the practical operating range is load-bearing for the claim of automatic scale recovery.
Authors: We agree that zero defocus blur (entire scene at the focal plane) makes the linear system singular, as no cross-view disparity information is present. This is an inherent limitation of any defocus-based scale recovery method. The manuscript's experiments and claims focus on scenes exhibiting sufficient defocus, consistent with the problem setting. To clarify the practical operating range, we will add an explicit discussion in §5.3 stating the requirement for non-zero blur and noting the singular failure case. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's core derivation estimates absolute scale via a linear solver that combines observed DP defocus disparity (from the thin-lens model) with up-to-scale SfM depths; the scale factor is the unknown solved for, not presupposed. The follow-on kernel-alignment stage is a direct consequence of the recovered scale and does not feed back into the scale estimate. No equations reduce a prediction to a fitted input by construction, no uniqueness theorems are imported via self-citation, and no ansatz is smuggled in. The approach is externally falsifiable on real multi-camera data and remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard pinhole camera model and defocus blur kernel assumptions hold for the DP sensor.
Reference graph
Works this paper leans on
-
[1]
Hartley and A
R. Hartley and A. Zisserman,Multiple View Geometry in Computer Vision, 2nd ed. Cambridge University Press, ISBN: 0521540518, 2004
2004
-
[2]
Resolving Scale Ambiguity in Multi-view 3D Reconstruction Using Dual-Pixel Sensors,
K. Ashida, H. Santo, F. Okura, and Y . Matsushita, “Resolving Scale Ambiguity in Multi-view 3D Reconstruction Using Dual-Pixel Sensors,” inProceedings of European Conference on Computer Vision (ECCV), 2024, pp. 162–178
2024
-
[3]
Modeling Defocus-Disparity in Dual-Pixel Sensors,
A. Punnappurath, A. Abuolaim, M. Afifi, and M. S. Brown, “Modeling Defocus-Disparity in Dual-Pixel Sensors,” inInternational Conference on Computational Photography (ICCP), 2020, pp. 1–12
2020
-
[4]
Bayesian scale estimation for monocular SLAM based on generic object detection for correcting scale drift,
E. Sucar and J.-B. Hayet, “Bayesian scale estimation for monocular SLAM based on generic object detection for correcting scale drift,” in IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 5152–5158
2018
-
[5]
Recovering stable scale in monocular SLAM using object-supplemented bundle adjustment,
D. Frost, V . Prisacariu, and D. Murray, “Recovering stable scale in monocular SLAM using object-supplemented bundle adjustment,”IEEE Transactions on Robotics, vol. 34, no. 3, pp. 736–747, 2018
2018
-
[6]
Robust Scale Estimation in Real-Time Monocular SFM for Autonomous Driving,
S. Song and M. Chandraker, “Robust Scale Estimation in Real-Time Monocular SFM for Autonomous Driving,” inProceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1566–1573
2014
-
[7]
Reliable scale estimation and correction for monocular visual odometry,
D. Zhou, Y . Dai, and H. Li, “Reliable scale estimation and correction for monocular visual odometry,” inProceedings of IEEE Intelligent V ehicles Symposium (IV), 2016, pp. 490–495. JOURNAL OF LATEX CLASS FILES, 2026 8
2016
-
[8]
Ground-plane-based absolute scale estimation for monocular visual odometry,
——, “Ground-plane-based absolute scale estimation for monocular visual odometry,”IEEE Transactions on Intelligent Transportation Sys- tems, vol. 21, no. 2, pp. 791–802, 2019
2019
-
[9]
Leveraging the user’s face for absolute scale estimation in handheld monocular SLAM,
S. B. Knorr and D. Kurz, “Leveraging the user’s face for absolute scale estimation in handheld monocular SLAM,” inProceedings of IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2016, pp. 11–17
2016
-
[10]
Monocular depth estimation in new environments with absolute scale,
T. Roussel, L. Van Eycken, and T. Tuytelaars, “Monocular depth estimation in new environments with absolute scale,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 1735–1741
2019
-
[11]
Estimation of absolute scale in monocular SLAM using synthetic data,
D. Rukhovich, D. Mouritzen, R. Kaestner, M. Rufli, and A. Velizhev, “Estimation of absolute scale in monocular SLAM using synthetic data,” inProceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2019, pp. 803–812
2019
-
[12]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
S. F. Bhat, R. Birkl, D. Wofk, P. Wonka, and M. M ¨uller, “Zoedepth: Zero-shot transfer by combining relative and metric depth,”arXiv preprint arXiv:2302.12288, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data,” in Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 10 371–10 381
2024
-
[14]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth Anything V2,”arXiv:2406.09414, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Large-scale direct SLAM with stereo cameras,
J. Engel, J. St ¨uckler, and D. Cremers, “Large-scale direct SLAM with stereo cameras,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2015, pp. 1935–1942
2015
-
[16]
Scale Estimation of Monocular SfM for a Multi-modal Stereo Camera,
S. Sumikura, K. Sakurada, N. Kawaguchi, and R. Nakamura, “Scale Estimation of Monocular SfM for a Multi-modal Stereo Camera,” in Proceedings of Asian Conference on Computer Vision (ACCV), 2019, pp. 281–297
2019
-
[17]
Scale correct monocular visual odometry using a lidar altimeter,
R. Giubilato, S. Chiodini, M. Pertile, and S. Debei, “Scale correct monocular visual odometry using a lidar altimeter,” inIEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), 2018, pp. 3694–3700
2018
-
[18]
Fusion of IMU and vision for absolute scale estimation in monocular SLAM,
G. N ¨utzi, S. Weiss, D. Scaramuzza, and R. Siegwart, “Fusion of IMU and vision for absolute scale estimation in monocular SLAM,”Journal of Intelligent & Robotic Systems, vol. 61, no. 1, pp. 287–299, 2011
2011
-
[19]
Towards scale-aware, robust, and generalizable unsupervised monocular depth estimation by integrating IMU motion dynamics,
S. Zhang, J. Zhang, and D. Tao, “Towards scale-aware, robust, and generalizable unsupervised monocular depth estimation by integrating IMU motion dynamics,” inProceedings of European Conference on Computer Vision (ECCV), 2022, pp. 143–160
2022
-
[20]
Absolute scale in structure from motion from a single vehicle mounted camera by exploiting nonholonomic constraints,
D. Scaramuzza, F. Fraundorfer, M. Pollefeys, and R. Siegwart, “Absolute scale in structure from motion from a single vehicle mounted camera by exploiting nonholonomic constraints,” inProceedings of IEEE/CVF International Conference on Computer Vision (ICCV), 2009, pp. 1413– 1419
2009
-
[21]
Stability-based scale estimation for monocular SLAM,
S. H. Lee and G. de Croon, “Stability-based scale estimation for monocular SLAM,”IEEE Robotics and Automation Letters, vol. 3, no. 2, pp. 780–787, 2018
2018
-
[22]
Scale- reconstructable structure from motion using refraction with a single camera,
A. Shibata, H. Fujii, A. Yamashita, and H. Asama, “Scale- reconstructable structure from motion using refraction with a single camera,” inIEEE International Conference on Robotics and Automation (ICRA), 2015, pp. 5239–5244
2015
-
[23]
Absolute scale structure from motion using a refractive plate,
——, “Absolute scale structure from motion using a refractive plate,” inProceedings of IEEE/SICE International Symposium on System Inte- gration (SII), 2015, pp. 540–545
2015
-
[24]
Monoc- ular 3D scene reconstruction at absolute scale,
C. W ¨ohler, P. d’Angelo, L. Kr¨uger, A. Kuhl, and H.-M. Groß, “Monoc- ular 3D scene reconstruction at absolute scale,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 64, no. 6, pp. 529–540, 2009
2009
-
[25]
Eliminating scale drift in monocular SLAM using depth from defocus,
T. Shiozaki and G. Dissanayake, “Eliminating scale drift in monocular SLAM using depth from defocus,”IEEE Robotics and Automation Letters, vol. 3, no. 1, pp. 581–587, 2017
2017
-
[26]
Absolute Scale from Varifocal Monocular Camera through SfM and Defocus Combined,
N. Mishima, A. Seki, and S. Hiura, “Absolute Scale from Varifocal Monocular Camera through SfM and Defocus Combined,” inProceed- ings of British Machine Vision Conference (BMVC), 2021, pp. 28–28
2021
-
[27]
Deep Depth From Aberration Map,
M. Kashiwagi, N. Mishima, T. Kozakaya, and S. Hiura, “Deep Depth From Aberration Map,” inProceedings of IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 4070–4079
2019
-
[28]
Revisiting Autofocus for Smartphone Cameras,
A. Abuolaim, A. Punnappurath, and M. S. Brown, “Revisiting Autofocus for Smartphone Cameras,” inProceedings of European Conference on Computer Vision (ECCV), 2018, pp. 545–559
2018
-
[29]
Learning to Autofocus,
C. Herrmann, R. S. Bowen, N. Wadhwa, R. Garg, Q. He, J. T. Barron, and R. Zabih, “Learning to Autofocus,” inProceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2227–2236
2020
-
[30]
Defocus Deblurring Using Dual-Pixel Data,
A. Abuolaim and M. S. Brown, “Defocus Deblurring Using Dual-Pixel Data,” inProceedings of European Conference on Computer Vision (ECCV), 2020, pp. 111–126
2020
-
[31]
Dual Pixel Exploration: Simultaneous Depth Estimation and Image Restoration,
L. Pan, S. Chowdhury, R. Hartley, M. Liu, H. Zhang, and H. Li, “Dual Pixel Exploration: Simultaneous Depth Estimation and Image Restoration,” inProceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 4340–4349
2021
-
[32]
NTIRE 2021 Challenge for Defocus Deblurring Using Dual-Pixel Images: Methods and Results,
A. Abuolaim, R. Timofte, and M. S. Brown, “NTIRE 2021 Challenge for Defocus Deblurring Using Dual-Pixel Images: Methods and Results,” in Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2021, pp. 578–587
2021
-
[33]
Learning To Reduce Defocus Blur by Realistically Modeling Dual- Pixel Data,
A. Abuolaim, M. Delbracio, D. Kelly, M. S. Brown, and P. Milanfar, “Learning To Reduce Defocus Blur by Realistically Modeling Dual- Pixel Data,” inProceedings of IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 2289–2298
2021
-
[34]
Defocus Map Estimation and Deblurring From a Single Dual-Pixel Image,
S. Xin, N. Wadhwa, T. Xue, J. T. Barron, P. P. Srinivasan, J. Chen, I. Gkioulekas, and R. Garg, “Defocus Map Estimation and Deblurring From a Single Dual-Pixel Image,” inProceedings of IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2021, pp. 2228–2238
2021
-
[35]
K3DN: Disparity-Aware Ker- nel Estimation for Dual-Pixel Defocus Deblurring,
Y . Yang, L. Pan, L. Liu, and M. Liu, “K3DN: Disparity-Aware Ker- nel Estimation for Dual-Pixel Defocus Deblurring,” inProceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 13 263–13 272
2023
-
[36]
Improving Single-Image Defocus Deblurring: How Dual-Pixel Images Help Through Multi- Task Learning,
A. Abuolaim, M. Afifi, and M. S. Brown, “Improving Single-Image Defocus Deblurring: How Dual-Pixel Images Help Through Multi- Task Learning,” inIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022, pp. 82–90
2022
-
[37]
Disparity probability volume guided defocus deblurring using dual pixel data,
S. H. Jung and Y . S. Heo, “Disparity probability volume guided defocus deblurring using dual pixel data,” inProceedings of International Con- ference on Information and Communication Technology Convergence (ICTC), 2021, pp. 305–308
2021
-
[38]
Synthetic depth-of-field with a single-camera mobile phone,
N. Wadhwa, R. Garg, D. E. Jacobs, B. E. Feldman, N. Kanazawa, R. Carroll, Y . Movshovitz-Attias, J. T. Barron, Y . Pritch, and M. Levoy, “Synthetic depth-of-field with a single-camera mobile phone,”ACM Transactions on Graphics (TOG), pp. 1–13, 2018
2018
-
[40]
Spatio-Focal Bidirectional Disparity Estimation From a Dual-Pixel Image,
D. Kim, H. Jang, I. Kim, and M. H. Kim, “Spatio-Focal Bidirectional Disparity Estimation From a Dual-Pixel Image,” inProceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 5023–5032
2023
-
[41]
Learning to Synthesize Photorealistic Dual-pixel Images from RGBD frames,
F. Li, H. Guo, H. Santo, F. Okura, and Y . Matsushita, “Learning to Synthesize Photorealistic Dual-pixel Images from RGBD frames,” in International Conference on Computational Photography (ICCP), 2023, pp. 1–11
2023
-
[42]
Reflection Removal Using a Dual- Pixel Sensor,
A. Punnappurath and M. S. Brown, “Reflection Removal Using a Dual- Pixel Sensor,” inProceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 1556–1565
2019
-
[43]
Facial Depth and Normal Estimation using Single Dual-Pixel Camera,
M. Kang, J. Choe, H. Ha, H.-G. Jeon, S. Im, and I. S. Kweon, “Facial Depth and Normal Estimation using Single Dual-Pixel Camera,” in Proceedings of European Conference on Computer Vision (ECCV), 2022, pp. 181–200
2022
-
[44]
Du2Net: Learning Depth Estimation from Dual-Cameras and Dual-Pixels,
Y . Zhang, N. Wadhwa, S. Orts-Escolano, C. H ¨ane, S. R. Fanello, and R. Garg, “Du2Net: Learning Depth Estimation from Dual-Cameras and Dual-Pixels,” inProceedings of European Conference on Computer Vision (ECCV), 2020, pp. 582–598
2020
-
[45]
Gentle,Matrix Albegra, ser
J. Gentle,Matrix Albegra, ser. Springer Texts in Statistics. Springer, New York, 2007
2007
-
[46]
Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography,
M. A. Fischler and R. C. Bolles, “Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography,”Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981
1981
-
[47]
Learning Single Cam- era Depth Estimation using Dual-Pixels,
R. Garg, N. Wadhwa, S. Ansari, and J. T. Barron, “Learning Single Cam- era Depth Estimation using Dual-Pixels,” inProceedings of IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 7628– 7637
2019
-
[48]
UniDepth: Universal monocular metric depth estimation,
L. Piccinelli, Y .-H. Yang, C. Sakaridis, M. Segu, S. Li, L. Van Gool, and F. Yu, “UniDepth: Universal monocular metric depth estimation,” in Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[49]
Unidepthv2: Universal monocular metric depth estimation made simpler
L. Piccinelli, C. Sakaridis, Y .-H. Yang, M. Segu, S. Li, W. Abbeloos, and L. V . Gool, “UniDepthV2: Universal monocular metric depth estimation made simpler,”arXiv preprint arXiv:2502.20110, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.