Maistros: A Greek Large Language Model Adapted Through Knowledge Distillation From Large Reasoning Models
Pith reviewed 2026-05-08 19:02 UTC · model grok-4.3
The pith
An 8B Greek LLM distilled from large reasoning models outperforms other open models on Greek QA benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Maistros 8B is a state-of-the-art open-weights Greek LLM obtained by knowledge distillation from large reasoning models followed by fine-tuning on CulturaQA, a high-quality LRM-generated and human-curated Greek QA dataset. Evaluation across nine human-curated Greek QA datasets shows Maistros 8B surpassing nine other LLMs, including both general and Greek-specific models.
What carries the argument
Knowledge distillation from large reasoning models into an 8B base model, using the CulturaQA dataset of LRM-generated and human-curated Greek question-answer pairs for fine-tuning.
If this is right
- Maistros 8B sets a new reference performance level for open Greek LLMs on question answering.
- CulturaQA provides a reusable training and evaluation resource for future Greek language models.
- The memory-efficient evaluation framework can be reused for other languages and QA tasks.
- Targeted distillation allows smaller models to acquire reasoning strengths for specific languages without full-scale pretraining.
Where Pith is reading between the lines
- The same dataset-generation and distillation pipeline could be applied to other low-resource languages by swapping the target language in the LRM prompts.
- Prioritizing human curation after LRM generation may prove more effective than simply scaling data volume for multilingual adaptation.
- Future experiments could test whether adding chain-of-thought supervision during distillation further boosts performance on multi-step Greek reasoning tasks.
Load-bearing premise
The CulturaQA dataset, created by large reasoning models and then curated by humans, supplies data of sufficient quality and cultural representativeness for distillation to yield better Greek QA performance than existing models.
What would settle it
If Maistros 8B scores below other open-weights Greek or multilingual models on the nine held-out Greek QA datasets, or if an ablated version trained only on the uncured LRM-generated portion matches its results, the central claim would be refuted.
Figures

read the original abstract
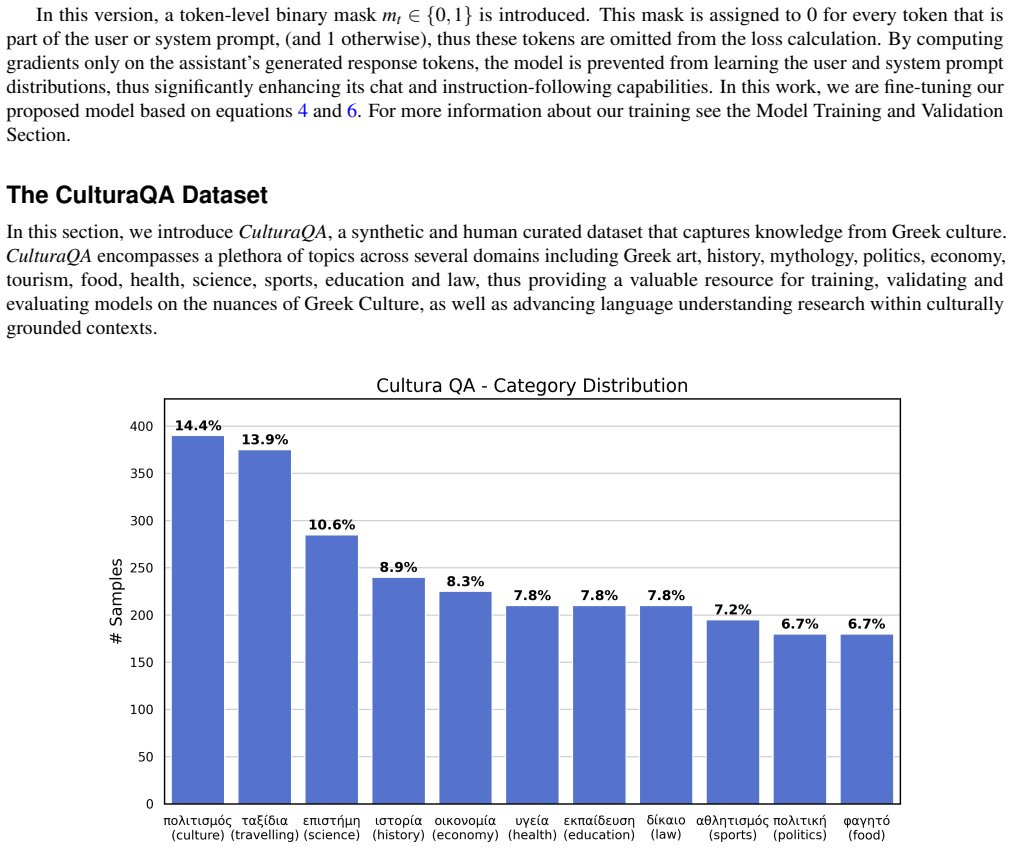
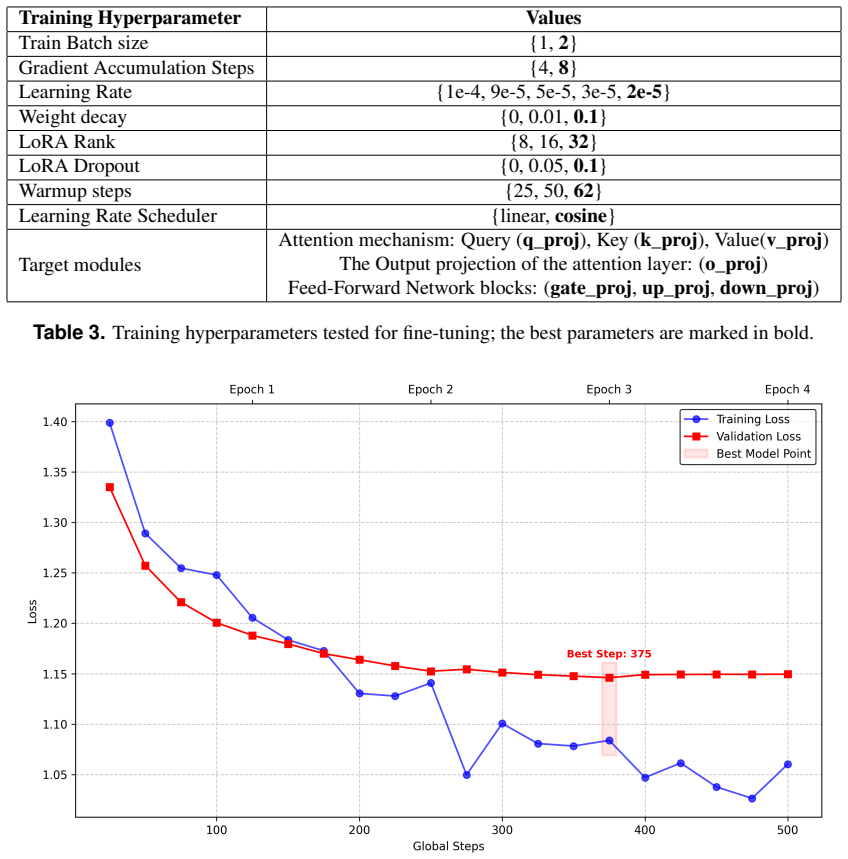
Large Language Models (LLMs) have substantially advanced the field of Natural Language Processing (NLP), achieving state-of-the-art performance across a wide range of tasks. These improvements have been attributed, in part, to their emerging reasoning capabilities, which are enabled by large-scale training and increased model capacity. However, existing LLMs can generate erroneous responses when addressing complex queries that fall outside their training distribution, due to limited internal knowledge or the need for multi-step reasoning. To address these limitations, recent work has introduced large reasoning models (LRMs), which incorporate explicit internal reasoning processes to improve response accuracy. Additionally, state-of-the-art LRMs often comprise hundreds of billions of parameters and require several seconds per inference, even on advanced multi-GPU systems. These characteristics limit their practicality for deployment in conventional computing environments. Meanwhile, NLP research on multilingual LLMs continues to prioritize high-resource languages. However, these models exhibit limited performance in under-resourced languages, primarily due to insufficient language- and culture-specific training data. In this paper, we focus on Modern Greek, for which only a limited number of question answering (QA) datasets have been proposed, most of which are intended for model evaluation. To address this research gap in Greek QA, we make the following contributions: (i) CulturaQA, a high-quality LRM-generated and human-curated dataset, for Greek LLM training and evaluation; (ii) a memory-efficient LLM evaluation framework adaptable to diverse languages and QA tasks; (iii) Maistros 8B, a state-of-the-art open-weights Greek LLM developed via knowledge distillation and fine-tuning on CulturaQA; and (iv) a comprehensive evaluation of nine LLMs across nine human-curated Greek QA datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CulturaQA, a new high-quality Greek QA dataset generated using large reasoning models (LRMs) and refined through human curation; a memory-efficient framework for LLM evaluation on QA tasks; and Maistros 8B, an 8B-parameter open-weights Greek LLM obtained via knowledge distillation from LRMs followed by fine-tuning on CulturaQA. It claims Maistros 8B achieves state-of-the-art results on Greek QA and reports a broad evaluation of nine LLMs across nine human-curated Greek QA datasets.
Significance. If the performance claims and dataset quality are substantiated with quantitative evidence, the work would provide a useful open-weights model and training resource for Modern Greek, helping close the gap for under-resourced languages. The distillation pipeline and evaluation framework could serve as a template for similar adaptations in other languages. The significance is currently limited by the absence of supporting metrics.
major comments (2)
- [Abstract] Abstract: the central claim that Maistros 8B is state-of-the-art is stated without any quantitative metrics, baseline comparisons, or error analysis, which is load-bearing for the primary contribution and cannot be assessed from the given description.
- [Abstract] Contributions (i): CulturaQA is described as high-quality LRM-generated and human-curated data sufficient to enable superior distillation performance, yet no validation statistics (e.g., inter-annotator agreement, LRM hallucination rates before/after curation, lexical diversity, or comparison to existing Greek QA corpora) are referenced, leaving open the possibility that any gains are attributable to unverified data quality rather than the method.
minor comments (1)
- [Abstract] The abstract lists evaluation of nine LLMs on nine datasets but does not name them; adding this information would improve clarity even if details appear later.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we will implement to improve the clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Maistros 8B is state-of-the-art is stated without any quantitative metrics, baseline comparisons, or error analysis, which is load-bearing for the primary contribution and cannot be assessed from the given description.
Authors: We agree that the abstract, in its current concise form, does not include specific quantitative metrics or direct references to baseline comparisons and error analysis. The full manuscript contains these details in the evaluation section, reporting results across nine Greek QA datasets with comparisons to nine other LLMs. We will revise the abstract to incorporate key performance figures (e.g., accuracy improvements on CulturaQA and other benchmarks) and a brief mention of the comparative evaluation to make the state-of-the-art claim immediately verifiable from the abstract alone. revision: yes
-
Referee: [Abstract] Contributions (i): CulturaQA is described as high-quality LRM-generated and human-curated data sufficient to enable superior distillation performance, yet no validation statistics (e.g., inter-annotator agreement, LRM hallucination rates before/after curation, lexical diversity, or comparison to existing Greek QA corpora) are referenced, leaving open the possibility that any gains are attributable to unverified data quality rather than the method.
Authors: The abstract summarizes the contribution at a high level. The full paper provides the requested validation statistics in the CulturaQA construction section, including inter-annotator agreement, pre/post-curation hallucination rates from the LRMs, lexical diversity metrics, and direct comparisons against prior Greek QA corpora. To address the concern directly in the abstract, we will add a brief clause referencing these supporting statistics so that the data-quality claims are substantiated without requiring the reader to consult the body text. revision: yes
Circularity Check
No circularity: standard empirical pipeline with no self-referential derivations
full rationale
The paper describes a conventional empirical workflow: LRM-generated and human-curated CulturaQA dataset creation, followed by knowledge distillation and fine-tuning to produce Maistros 8B, then evaluation of nine LLMs on nine Greek QA datasets. No equations, parameters, or derivations appear in the abstract or described contributions that reduce performance claims to fitted inputs, self-definitions, or self-citation chains. No uniqueness theorems, ansatzes, or renamings of known results are invoked. The central claim rests on dataset construction and benchmarking rather than any load-bearing loop back to the paper's own inputs by construction. Absence of quantitative data-quality metrics is a potential evidence gap but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge distillation from large reasoning models transfers useful reasoning capabilities to smaller models for a low-resource language.
invented entities (1)
-
CulturaQA dataset
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith.Foundation.AlphaCoordinateFixationalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
W = W₀ + sAB, s = α/r ... LoRA optimizes efficiency by learning low-rank matrices
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Naveed, H.et al.A comprehensive overview of large language models.ACM Trans. Intell. Syst. Technol.16, DOI: 10.1145/3744746 (2025). 3.Bommasani, R.et al.On the opportunities and risks of foundation models (2022). 2108.07258
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Brown, T. B.et al.Language models are few-shot learners. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20 (Curran Associates Inc., Red Hook, NY , USA, 2020). 5.Touvron, H.et al.Llama 2: Open foundation and fine-tuned chat models (2023). 2307.09288. 6.Singh, A.et al.Openai gpt-5 system card (2025). 2601....
work page internal anchor Pith review arXiv 2020
-
[3]
Xu, F.et al.Toward large reasoning models: A survey of reinforced reasoning with large language models.Patterns6, 101370, DOI: https://doi.org/10.1016/j.patter.2025.101370 (2025)
-
[4]
Shani, C., Reif, Y ., Roll, N., Jurafsky, D. & Shutova, E. The roots of performance disparity in multilingual language models: Intrinsic modeling difficulty or design choices? (2026). 2601.07220
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
M¨ uller, L´ aszl´ o N´ emeth, Luis Oala, Lennart Purucker, Sahithya Ravi, 10 Jan N
Qin, L.et al.A survey of multilingual large language models.Patterns6, 101118, DOI: https://doi.org/10.1016/j.patter. 2024.101118 (2025)
-
[6]
Bakagianni, J., Pouli, K., Gavriilidou, M. & Pavlopoulos, J. A systematic survey of natural language processing for the greek language.Patterns6, 101313, DOI: https://doi.org/10.1016/j.patter.2025.101313 (2025). 12.Papantoniou, K. & Tzitzikas, Y . Nlp for the greek language: A longer survey (2024). 2408.10962
-
[7]
Giarelis, N., Mastrokostas, C., Siachos, I. & Karacapilidis, N. A review of greek nlp technologies for chatbot development. InProceedings of the 27th Pan-Hellenic Conference on Progress in Computing and Informatics, PCI ’23, 15–20, DOI: 10.1145/3635059.3635062 (Association for Computing Machinery, New York, NY , USA, 2024)
-
[8]
In Christodoulopoulos, C., Chakraborty, T., Rose, C
Roussis, D.et al.Krikri: Advancing open large language models for Greek. In Christodoulopoulos, C., Chakraborty, T., Rose, C. & Peng, V . (eds.)Findings of the Association for Computational Linguistics: EMNLP 2025, 5012–5033, DOI: 10.18653/v1/2025.findings-emnlp.268 (Association for Computational Linguistics, Suzhou, China, 2025)
-
[9]
Zhang, Y .et al.Greekmmlu: A native-sourced multitask benchmark for evaluating language models in greek (2026). 2602.05150
-
[10]
Mastrokostas, C., Giarelis, N. & Karacapilidis, N. Evaluating monolingual and multilingual large language models for greek question answering: The demosqa benchmark (2026). 2602.16811. 17.Liu, A. H.et al.Ministral 3 (2026). 2601.08584
-
[11]
Zhang, T., Kishore, V ., Wu, F., Weinberger, K. Q. & Artzi, Y . Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations(2020). 19.Grattafiori, A.et al.The llama 3 herd of models (2024). 2407.21783. 20.Kamath, A.et al.Gemma 3 technical report (2025). 2503.19786. 21.Yang, A.et al.Qwen3 technical report (2025)...
work page internal anchor Pith review arXiv 2020
-
[12]
In Christodoulopoulos, C., Chakraborty, T., Rose, C
Peng, X.et al.Plutus: Benchmarking large language models in low-resource Greek finance. In Christodoulopoulos, C., Chakraborty, T., Rose, C. & Peng, V . (eds.)Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 30176–30202, DOI: 10.18653/v1/2025.emnlp-main.1535 (Association for Computational Linguistics, Suzhou, China, ...
-
[13]
Gesnouin, J.et al.Llamandement: Large language models for summarization of french legislative proposals (2024). 2401.16182
-
[14]
Ong, D. & Limkonchotiwat, P. SEA-LION (Southeast Asian languages in one network): A family of Southeast Asian language models. In Tan, L., Milajevs, D., Chauhan, G., Gwinnup, J. & Rippeth, E. (eds.)Proceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023), 245–245, DOI: 10.18653/v1/2023.nlposs-1.26 (Association fo...
-
[15]
Polignano, M., Basile, P. & Semeraro, G. Advanced natural-based interaction for the ITAlian language: LLaMAntino-3- ANITA.Sci. Reports16, 5375, DOI: 10.1038/s41598-025-31319-0 (2026). 27.Vreš, D.et al.Building a strong instruction language model for a less-resourced language (2026). 2603.01691
-
[16]
Translationese in Machine Translation Evaluation
Graham, Y ., Haddow, B. & Koehn, P. Translationese in Machine Translation Evaluation, DOI: 10.48550/arXiv.1906.09833 (2019). ArXiv:1906.09833. 29.V oukoutis, L.et al.Meltemi: The first open large language model for greek (2024). 2407.20743
-
[17]
InThe Thirteenth International Conference on Learning Representations(2025)
Romanou, A.et al.INCLUDE: Evaluating multilingual language understanding with regional knowledge. InThe Thirteenth International Conference on Learning Representations(2025)
work page 2025
-
[18]
Kyriazi, P. & Prokopidis, P. Multiple choice qa greek asep.Hugging Face. https://huggingface.co/datasets/ilsp/mcqa_ greek_asep/ (2025)
work page 2025
-
[19]
Vacalopoulou, A., Sofianopoulos, S. & Prokopidis, P. Greek physical commonsense reasoning dataset.Hugging Face. https://huggingface.co/datasets/ilsp/greek_pcr/ (2025)
work page 2025
-
[20]
Chang, T. A.et al.Global piqa: Evaluating physical commonsense reasoning across 100+ languages and cultures (2025). 2510.24081
work page internal anchor Pith review arXiv 2025
-
[21]
J.et al.LoRA: Low-rank adaptation of large language models
Hu, E. J.et al.LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations(2022)
work page 2022
-
[22]
Mao, Y .et al.A survey on LoRA of large language models.Front. Comput. Sci.19, 197605, DOI: 10.1007/ s11704-024-40663-9 (2024)
work page 2024
-
[23]
Biderman, D.et al.LoRA learns less and forgets less.Transactions on Mach. Learn. Res.(2024). Featured Certification
work page 2024
-
[24]
Shuttleworth, R. S., Andreas, J., Torralba, A. & Sharma, P. LoRA vs full fine-tuning: An illusion of equivalence. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2025). 38.Chowdhery, A.et al.Palm: Scaling language modeling with pathways.J. Mach. Learn. Res.24, 1–113 (2023)
work page 2025
-
[25]
Transformers: State-of-the-Art Natural Language Processing
Wolf, T.et al.Transformers: State-of-the-art natural language processing. In Liu, Q. & Schlangen, D. (eds.)Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 38–45, DOI: 10.18653/v1/2020.emnlp-demos.6 (Association for Computational Linguistics, Online, 2020)
-
[26]
The effect of sampling temperature on problem solving in large language models
Renze, M. The effect of sampling temperature on problem solving in large language models. In Al-Onaizan, Y ., Bansal, M. & Chen, Y . N. (eds.)Findings of the Association for Computational Linguistics: EMNLP 2024, 7346–7356, DOI: 10.18653/v1/2024.findings-emnlp.432 (Association for Computational Linguistics, Miami, Florida, USA, 2024)
-
[27]
Dettmers, T., Pagnoni, A., Holtzman, A. & Zettlemoyer, L. Qlora: efficient finetuning of quantized llms. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23 (Curran Associates Inc., Red Hook, NY , USA, 2023)
work page 2023
-
[28]
Smith, S. L., Kindermans, P. J. & Le, Q. V . Don’t decay the learning rate, increase the batch size. InInternational Conference on Learning Representations(2018)
work page 2018
-
[29]
Zhang, J., He, T., Sra, S. & Jadbabaie, A. Why gradient clipping accelerates training: A theoretical justification for adaptivity. InInternational Conference on Learning Representations(2020). 44.Dettmers, T., Lewis, M., Shleifer, S. & Zettlemoyer, L. 8-bit optimizers via block-wise quantization (2022). 2110.02861
-
[30]
The Hitchhiker ' s Guide to Testing Statistical Significance in Natural Language Processing
Dror, R., Baumer, G., Shlomov, S. & Reichart, R. The hitchhiker’s guide to testing statistical significance in natural language processing. In Gurevych, I. & Miyao, Y . (eds.)Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1383–1392, DOI: 10.18653/v1/P18-1128 (Association for Computational L...
-
[31]
Kaddas, P., Gatos, B., Palaiologos, K., Christopoulou, K. & Kritsis, K. Text line detection and recognition of greek polytonic documents. In Coustaty, M. & Fornés, A. (eds.)Document Analysis and Recognition – ICDAR 2023 Workshops, 213–225 (Springer Nature Switzerland, Cham, 2023). 12/15
work page 2023
- [32]
-
[33]
Chlapanis, Dimitris Galanis, Nikolaos Aletras, and Ion Androut- sopoulos
Chlapanis, O. S., Galanis, D., Aletras, N. & Androutsopoulos, I. GreekBarBench: A challenging benchmark for free-text legal reasoning and citations. In Christodoulopoulos, C., Chakraborty, T., Rose, C. & Peng, V . (eds.)Findings of the Association for Computational Linguistics: EMNLP 2025, 25099–25119, DOI: 10.18653/v1/2025.findings-emnlp.1368 (Associatio...
-
[34]
Tsourma, M., Michail, D., Varlamis, I., Drosou, A. & Tzovaras, D. Legal assistance in low-resource languages: Evaluating rag and fine-tuned llms for greek e-governance. In2025 3rd International Conference on Foundation and Large Language Models (FLLM), 366–373, DOI: 10.1109/FLLM67465.2025.11391043 (2025)
-
[35]
Koniaris, M., Galanis, D., Giannini, E. & Tsanakas, P. Evaluation of automatic legal text summarization techniques for greek case law.Information14, DOI: 10.3390/info14040250 (2023)
-
[36]
Giarelis, N., Mastrokostas, C. & Karacapilidis, N. Greekt5: Sequence-to-sequence models for greek news summarization. In Maglogiannis, I., Iliadis, L., Macintyre, J., Avlonitis, M. & Papaleonidas, A. (eds.)Artificial Intelligence Applications and Innovations, 60–73 (Springer Nature Switzerland, Cham, 2024)
work page 2024
-
[37]
Giarelis, N., Mastrokostas, C. & Karacapilidis, N. Greek wikipedia: A study on abstractive summarization. InProceedings of the 13th Hellenic Conference on Artificial Intelligence, SETN ’24, DOI: 10.1145/3688671.3688769 (Association for Computing Machinery, New York, NY , USA, 2024)
-
[38]
Loukas, L.et al.GR-NLP-TOOLKIT: An open-source NLP toolkit for Modern Greek. In Rambow, O.et al.(eds.) Proceedings of the 31st International Conference on Computational Linguistics: System Demonstrations, 174–182 (Association for Computational Linguistics, Abu Dhabi, UAE, 2025)
work page 2025
-
[39]
Liapis, C. M., Kyritsis, K., Perikos, I. & Paraskevas, M. Transformer-based embeddings for greek language categorization. In2024 IEEE/ACIS 24th International Conference on Computer and Information Science (ICIS), 176–181, DOI: 10.1109/ ICIS61260.2024.10778332 (2024)
-
[40]
Stylianou, N., Tsikrika, T., Vrochidis, S. & Kompatsiaris, I. Cross-domain hate speech detection for content moderation in greek social networks. In2024 IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), 373–379, DOI: 10.1109/WI-IAT62293.2024.00059 (2024)
-
[41]
Mastrokostas, C., Giarelis, N. & Karacapilidis, N. Social media topic classification on greek reddit.Information15, DOI: 10.3390/info15090521 (2024). Acknowledgements This work has received funding from the European Union’s Horizon Europe research and innovation programme under grant agreement No. 101235708 (BLUEPRINT – Building Living Urban Ecosystems th...
-
[43]
3.Απόφυγε τη χρήση στερεοτύπων
Λάβε υπόψη τον ελληνικό πολιτισμό και την ελληνική κοινωνική πραγματικότητα όπου είναι σχετικό. 3.Απόφυγε τη χρήση στερεοτύπων
-
[44]
Βάλε πάντα το σύμβολο • πριν από κάθε ερώτηση
-
[45]
Δημιούργησε σημαντικές, συχνά προκύπ- τουσες και χρήσιμες ερωτήσεις για το θέμα
-
[46]
΄Ολες οι ερωτήσεις πρέπει να μπορούν να απαντηθούν αντικειμενικά
-
[47]
Μη δημιουργείς επαναλαμβανόμενες ερωτήσεις
-
[48]
Κάθε ερώτηση πρέπει να είναι σαφώς ορισμένη
-
[49]
Γράψε μόνο το κείμενο των ερωτήσεων, χωρίς επιπλέον σχόλια. Παρακαλώ δημιούργησε 15 ερώτησεις για το εξής θέμα:{topic} You are an extremely developed Artificial Intelligence model for the Greek Language. Use the following instructions to create a series of questions on the topic mentioned by the user: Instructions:
-
[52]
Avoid the use of stereotypes
-
[53]
Always place the symbol • before each question
-
[54]
Create significant, frequently occurring and useful questions for the topic
-
[55]
All questions must be able to be answered objectively
-
[56]
Do not create repeated questions
-
[57]
Every question must be clearly defined
-
[58]
Write only the text of the questions, without extra comments. Please create 15 questions for the follow- ing topic: {topic} Continued on next page 14/15 Table A1 – continued from previous page Prompt Type Greek English (Translated) Dataset Creation (Answers) Είσαι ένα εξαιρετικά ανεπτυγμένο μοντέλο Τεχνητής Νοημοσύνης για την Ελληνική γλώσσα. Χρησιμοποίησ...
-
[59]
Απάντα αποκλειστικά στα Ελληνικά με άψογη γραμματική, σύνταξη και ορθογραφία
-
[60]
Λάβε υπόψη τον ελληνικό πολιτισμό και την ελληνική κοινωνική πραγματικότητα όπου είναι σχετικό
-
[61]
4.Απόφυγε τη χρήση στερεότυπων
Απάντησε στις ερωτήσεις του χρήστη με ειλικρίνεια και επιστημονική ακρίβεια. 4.Απόφυγε τη χρήση στερεότυπων
-
[62]
χώρα, περίοδος): –Μην ζητήσεις διευκρίνιση
Αν η ερώτηση είναι ασαφής ή λείπει πληροφορία (π.χ. χώρα, περίοδος): –Μην ζητήσεις διευκρίνιση. – Δώσε την απάντηση κάνοντας ρητές παραδοχές (π.χ. ¨Ελλείψει άλλης αναφοράς, θεωρούμε ως προεπιλογή την Ελλάδα και το τρέχον έτος¨). Παρακαλώ απάντησε στη παρακάτω ερώτηση: {question} You are an extremely developed Artificial Intelligence model for the Greek La...
-
[63]
Answer exclusively in Greek with impeccable grammar, syntax and spelling
-
[64]
Take into consideration the Greek civilization and the Greek social reality where relevant
-
[65]
Answer the user question with honesty and scientific accuracy
-
[66]
In the absence of other reference, we assume as a default Greece and the current year
If the question is vague or information is missing (e.g., country, time period): – Do not ask for clarification. – Give the answer by making explicit assump- tions (e.g. "In the absence of other reference, we assume as a default Greece and the current year”). Please answer the following question: {ques- tion} Multiple Choice (Evaluation) Διάβασε προσεκτικ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.