Recognition: unknown
RV-IM100: Quantifying ISA Extension, Datapath Width, and Pipeline Depth Trade-offs in RISC-V Microarchitectures
Pith reviewed 2026-05-09 15:59 UTC · model grok-4.3
The pith
RV32IM at eight pipeline stages triples frequency and increases throughput 71 percent while cutting per-MHz efficiency 41 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
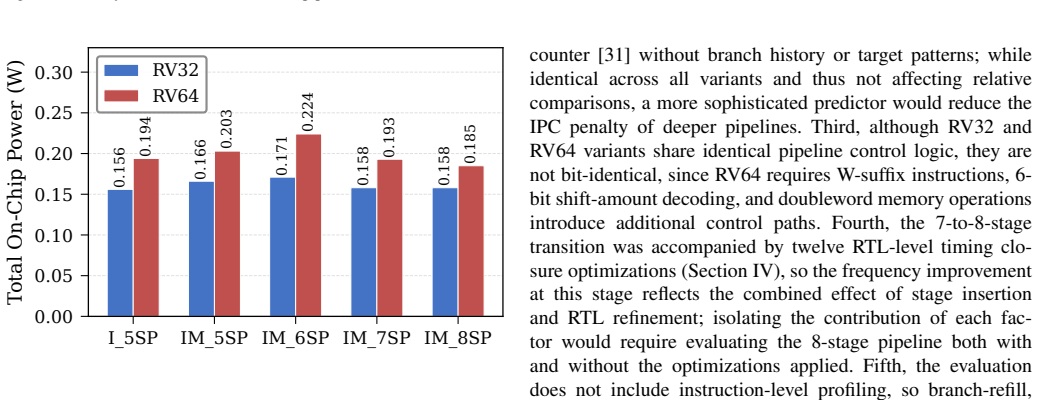
By deriving ten microarchitectures from a common five-stage RV32I baseline and systematically varying instruction-set extension to IM, datapath width to 64 bits, and pipeline depth to eight stages under controlled FPGA conditions, the study establishes that the I-to-IM change produces strongly benchmark-dependent throughput effects, that pipeline deepening from five to eight stages in the RV32IM case raises maximum frequency from 43 to 126 MHz and increases both Dhrystone and CoreMark throughput by 71 percent while decreasing per-MHz efficiency by 41 percent, and that RV32 versions require substantially fewer resources than RV64 versions at the deepest pipeline depth.
What carries the argument
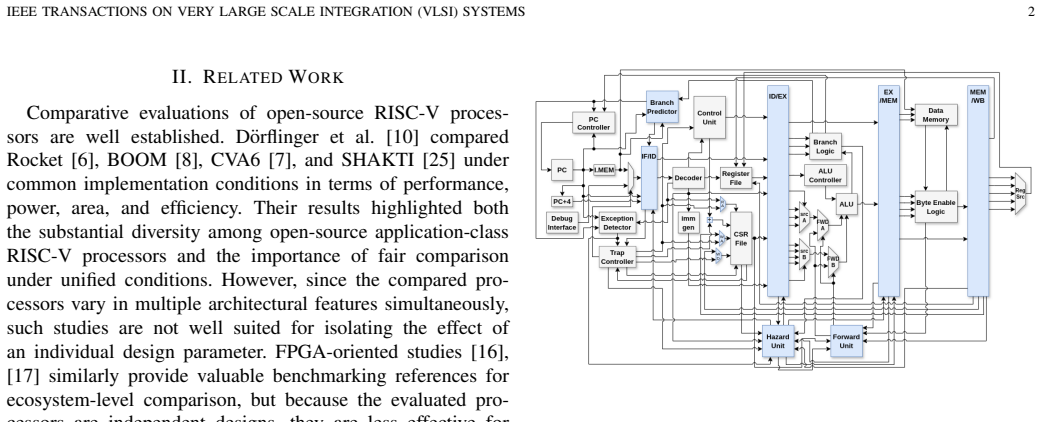
A family of ten incremental FPGA microarchitectures obtained by applying controlled, one-at-a-time changes in ISA extension, datapath width, and pipeline depth to a shared five-stage baseline.
If this is right
- CoreMark throughput more than doubles after the I-to-IM extension at five stages while Dhrystone throughput decreases marginally.
- Pipeline deepening from five to eight stages in RV32IM triples maximum frequency and raises both benchmark throughputs by 71 percent.
- Per-MHz efficiency falls 41 percent after the same five-to-eight-stage deepening.
- RV32 at eight stages requires 59 percent fewer LUTs, 51 percent fewer flip-flops, and 80 percent fewer DSPs than RV64.
- The six-to-seven-stage transition produces throughput regression in RV64 despite higher frequency.
Where Pith is reading between the lines
- Designers on resource-limited FPGAs may favor the RV32IM eight-stage point when absolute throughput matters more than per-cycle efficiency.
- Workload character strongly influences whether the M extension is worth including, because gains are not uniform across benchmarks.
- Repeating the incremental exercise on ASIC targets could expose different frequency and power trade-offs that are masked by FPGA routing delays.
- Testing stages beyond eight in the narrower configurations could reveal whether throughput continues to rise or begins to plateau.
Load-bearing premise
The measured frequency, throughput, efficiency, and resource changes observed on one FPGA with a specific synthesis flow and two benchmarks will generalize to other targets, workloads, or ASIC implementations without strong interactions between the varied parameters.
What would settle it
Re-running the same ten configurations on an ASIC process or a second FPGA family while adding more benchmarks would show whether the reported 71 percent throughput gain, 41 percent efficiency drop, and large resource savings remain consistent.
Figures





read the original abstract
While functional RISC-V implementations are readily available in academia, controlled empirical studies that extend a single baseline architecture along multiple design axes and quantify the resulting trade-offs at each step remain scarce. This paper presents RV-IM100, a family of 10 incremental FPGA-implemented microarchitectures derived from a common 5-stage pipeline baseline, systematically varying datapath width from RV32 to RV64, instruction set from I to IM, and pipeline depth from 5 to 8 stages under controlled conditions. The I-to-IM extension produced strongly benchmark-dependent effects at the 5-stage level: CoreMark throughput more than doubled while Dhrystone throughput decreased marginally despite improved per-MHz efficiency. Within the RV32IM configuration, an iterative timing-closure methodology combined with pipeline deepening from 5 to 8 stages raised max frequency from 43 to 126MHz, increasing both Dhrystone and CoreMark throughput by 71%, while per-MHz efficiency decreased by 41%. The 6-to-7-stage transition caused throughput regression in RV64 despite higher frequency, revealing that the outcome depends on available frequency headroom. Cross-width comparison showed RV32 outperforming RV64 in absolute throughput, with per-MHz efficiency diverging by benchmark: RV64 led by 2.3% in DMIPS/MHz while RV32 led by 4.6% in CoreMark/MHz. At 8 stages, RV32 required 59% fewer LUTs, 51% fewer FFs, and 80% fewer DSPs, indicating that the resource cost of width extension substantially exceeds the modest efficiency differences. These results provide a quantitative reference for design-space exploration in RISC-V microarchitectures. All RTL sources and benchmark configurations are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RV-IM100, a family of 10 incremental FPGA-implemented RISC-V microarchitectures derived from a common 5-stage RV32I baseline. It systematically varies ISA (I to IM), datapath width (RV32 to RV64), and pipeline depth (5 to 8 stages), reporting empirical measurements of maximum frequency, Dhrystone and CoreMark throughput, per-MHz efficiency, and FPGA resource utilization (LUTs, FFs, DSPs). Key findings include benchmark-dependent effects of the M extension, a 71% throughput gain from pipeline deepening in RV32IM (with 41% efficiency drop), a throughput regression at the 6-to-7 stage transition in RV64, and substantial resource savings for RV32 over RV64 at 8 stages, positioning the results as a quantitative reference for RISC-V design-space exploration. All RTL sources are made publicly available.
Significance. If the reported measurements hold, the work supplies a controlled, incremental empirical dataset on RISC-V microarchitectural trade-offs that is scarce in the literature. The public release of RTL and benchmark configurations is a clear strength that enables reproducibility and further exploration by others. The results usefully illustrate interactions such as benchmark dependence and frequency-headroom effects, providing concrete numbers that can inform early-stage design decisions, though their value as a general reference is constrained by the single-platform, two-benchmark scope.
major comments (2)
- Abstract: the positioning of the quantified results (e.g., 71% throughput increase from 5-to-8 stage deepening, 59% LUT reduction for RV32) as 'a quantitative reference for design-space exploration' is load-bearing for the contribution. All data come from a single FPGA target, one synthesis flow, and iterative timing closure; no cross-technology validation, sensitivity analysis to synthesis settings, or discussion of how device-specific timing paths affect the observed frequency scaling and resource mappings is provided, weakening the reference claim.
- Results on pipeline deepening (abstract and associated figures/tables): the reported throughput regression at the 6-to-7 stage transition in RV64 despite higher frequency is presented as evidence that 'the outcome depends on available frequency headroom,' but lacks accompanying data on critical-path changes, per-stage overheads, or instruction-mix interactions. This detail is needed to substantiate the trade-off interpretation and its generality.
minor comments (3)
- The abstract and text should explicitly define 'per-MHz efficiency' (DMIPS/MHz vs. CoreMark/MHz) and how throughput is normalized, to avoid ambiguity when comparing across configurations.
- A summary table listing all 10 configurations with their exact parameters (width, ISA, stages) alongside key metrics would improve readability and cross-reference.
- Methodology details on benchmark execution (e.g., number of iterations, warm-up, measurement windows) and synthesis constraints should be expanded to allow independent reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and strengthen the presentation of our results.
read point-by-point responses
-
Referee: Abstract: the positioning of the quantified results (e.g., 71% throughput increase from 5-to-8 stage deepening, 59% LUT reduction for RV32) as 'a quantitative reference for design-space exploration' is load-bearing for the contribution. All data come from a single FPGA target, one synthesis flow, and iterative timing closure; no cross-technology validation, sensitivity analysis to synthesis settings, or discussion of how device-specific timing paths affect the observed frequency scaling and resource mappings is provided, weakening the reference claim.
Authors: We agree that the results are obtained from a single FPGA platform (Xilinx Artix-7) using one synthesis flow and iterative timing closure, and that the manuscript does not include cross-technology validation or sensitivity analysis. The phrasing in the abstract was intended to position the work as an empirical reference for similar FPGA-based RISC-V explorations rather than a universal claim. We will revise the abstract, introduction, and conclusions to explicitly qualify the scope as platform-specific, add a short discussion of how device timing characteristics and synthesis settings can influence the observed frequency and resource numbers, and soften the 'quantitative reference' language to reflect these limitations. These changes will be incorporated in the revised manuscript. revision: yes
-
Referee: Results on pipeline deepening (abstract and associated figures/tables): the reported throughput regression at the 6-to-7 stage transition in RV64 despite higher frequency is presented as evidence that 'the outcome depends on available frequency headroom,' but lacks accompanying data on critical-path changes, per-stage overheads, or instruction-mix interactions. This detail is needed to substantiate the trade-off interpretation and its generality.
Authors: The throughput regression at the 6-to-7 stage transition in RV64 is an empirical observation from our benchmark runs and frequency measurements. We interpret it as a consequence of limited frequency headroom relative to added pipeline overheads, but we acknowledge that the current manuscript provides limited supporting detail on critical-path evolution or per-stage overheads. In the revision we will incorporate additional synthesis report data (where available from our design logs) on critical path locations and delays across the 5-to-8 stage configurations for the RV64IM design, and expand the discussion of how these changes interact with the benchmark instruction mixes. If certain granular per-stage breakdowns are not retrievable, we will note this as a limitation and clarify that the headroom explanation remains an inference from the measured frequency-throughput trade-off. revision: partial
Circularity Check
No circularity: purely empirical hardware measurements
full rationale
The paper presents incremental FPGA implementations of RISC-V cores and reports direct measurements of frequency, throughput (Dhrystone/CoreMark), per-MHz efficiency, and resource counts (LUTs/FFs/DSPs) under controlled variations of width, ISA, and pipeline depth. No equations, fitted parameters, predictions, or self-citations are used to derive the headline results; all numbers come from synthesis and benchmark execution on the target platform. The central claims are therefore self-contained empirical observations rather than reductions to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption FPGA synthesis tools and the chosen flow produce reliable frequency and resource utilization estimates for the incremental designs.
- domain assumption Dhrystone and CoreMark are representative workloads for evaluating the microarchitectural trade-offs.
Reference graph
Works this paper leans on
-
[1]
The RISC-V instruction set manual, V olume I: Base user-level ISA,
A. Waterman, Y . Lee, D. A. Patterson, and K. Asanovi ´c, “The RISC-V instruction set manual, V olume I: Base user-level ISA,” Univ. California, Berkeley, CA, USA, Tech. Rep. UCB/EECS-2011-62, May 2011
2011
-
[2]
D. A. Patterson and J. L. Hennessy,Computer Organization and Design RISC-V Edition: The Hardware Software Interface, 2nd ed. San Francisco, CA, USA: Morgan Kaufmann, 2020
2020
-
[3]
riscv-sodor,
UC Berkeley Architecture Research, “riscv-sodor,” GitHub. Accessed: May 2, 2026. [Online]. Available: https://github.com/ucb-bar/riscv-sodor
2026
-
[4]
MicroRV32: An open source RISC-V cross-level platform for education and research,
S. Ahmadi-Pour, V . Herdt, and R. Drechsler, “MicroRV32: An open source RISC-V cross-level platform for education and research,” inProc. Workshop Design Autom. CPS IoT (Destion ’21), Nashville, TN, USA, May 2021, pp. 30–35
2021
-
[5]
VexRiscv,
C. Papon, “VexRiscv,” GitHub. Accessed: May 2, 2026. [Online]. Available: https://github.com/SpinalHDL/VexRiscv
2026
-
[6]
The Rocket Chip generator,
K. Asanovi ´cet al., “The Rocket Chip generator,” Univ. California, Berkeley, CA, USA, Tech. Rep. UCB/EECS-2016-17, Apr. 2016
2016
-
[7]
The cost of application-class processing: Energy and performance analysis of a Linux-ready 1.7-GHz 64-bit RISC-V core in 22-nm FDSOI technology,
F. Zaruba and L. Benini, “The cost of application-class processing: Energy and performance analysis of a Linux-ready 1.7-GHz 64-bit RISC-V core in 22-nm FDSOI technology,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 27, no. 11, pp. 2629–2640, Nov. 2019
2019
-
[8]
The Berkeley Out- of-Order Machine (BOOM): An industry-competitive, synthesizable, parameterized RISC-V processor,
C. Celio, D. A. Patterson, and K. Asanovi ´c, “The Berkeley Out- of-Order Machine (BOOM): An industry-competitive, synthesizable, parameterized RISC-V processor,” Univ. California, Berkeley, CA, USA, Tech. Rep. UCB/EECS-2015-167, Jun. 2015
2015
-
[9]
Xuantie-910: A commercial multi-core 12-stage pipeline out-of-order 64-bit high performance RISC-V processor with vector extension: Industrial product,
C. Chenet al., “Xuantie-910: A commercial multi-core 12-stage pipeline out-of-order 64-bit high performance RISC-V processor with vector extension: Industrial product,” inProc. ACM/IEEE 47th Annu. Int. Symp. Comput. Archit. (ISCA), 2020, pp. 52–64. 1Available at: https://github.com/T410N/RV-IM100
2020
-
[10]
A comparative survey of open-source application- class RISC-V processor implementations,
A. D ¨orflingeret al., “A comparative survey of open-source application- class RISC-V processor implementations,” inProc. 18th ACM Int. Conf. Comput. Frontiers (CF), 2021, pp. 12–20
2021
-
[11]
Accessed: May 2, 2026
RISC-V International, “learn,” GitHub. Accessed: May 2, 2026. [On- line]. Available: https://github.com/riscv/learn
2026
-
[12]
Waterman and K
A. Waterman and K. Asanovi ´c, Eds.,The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Document Version 20191213, RISC- V Foundation, Dec. 2019. [Online]. Available: https://riscv.org/technical/ specifications/
2019
-
[13]
Design and implementation of a RISC-V RV64IM pipelined processor with AXI4-Lite support for high- performance computing,
Y . Kim, K. Kim, and J. Moon, “Design and implementation of a RISC-V RV64IM pipelined processor with AXI4-Lite support for high- performance computing,”J. Semicond. Display Technol., vol. 24, no. 3, pp. 102–108, 2025
2025
-
[14]
picorv32,
C. Wolf, “picorv32,” GitHub. Accessed: May 2, 2026. [Online]. Avail- able: https://github.com/YosysHQ/picorv32
2026
-
[15]
Wildcat: Educational RISC-V microprocessors,
M. Schoeberl, “Wildcat: Educational RISC-V microprocessors,” inProc. 38th Int. Conf. Archit. Comput. Syst. (ARCS)(Lecture Notes in Computer Science). Cham, Switzerland: Springer, 2025, pp. 189–202
2025
-
[16]
A catalog and in- hardware evaluation of open-source drop-in compatible RISC-V soft- core processors,
C. Heinz, Y . Lavan, J. Hofmann, and A. Koch, “A catalog and in- hardware evaluation of open-source drop-in compatible RISC-V soft- core processors,” inProc. Int. Conf. ReConFigurable Comput. FPGAs (ReConFig), 2019, pp. 1–8
2019
-
[17]
Open-source RISC-V processor IP cores for FPGAs — Overview and evaluation,
R. H ¨oller, D. Haselberger, D. Ballek, P. R ¨ossler, M. Krapfenbauer, and M. Linauer, “Open-source RISC-V processor IP cores for FPGAs — Overview and evaluation,” inProc. 8th Mediterranean Conf. Embedded Comput. (MECO), 2019, pp. 1–6
2019
-
[18]
RVCoreP: An optimized RISC-V soft processor of five-stage pipelining,
H. Miyazaki, T. Kanamori, M. A. Islam, and K. Kise, “RVCoreP: An optimized RISC-V soft processor of five-stage pipelining,”IEICE Trans. Inf. Syst., vol. E103.D, no. 12, pp. 2494–2503, Dec. 2020
2020
-
[19]
M. A. Islam, H. Miyazaki, and K. Kise, “RVCoreP-32IM: An effective architecture to implement mul/div instructions for five stage RISC-V soft processors,” 2020,arXiv:2010.16171
-
[20]
RVCoreP-32IC: An optimized RISC-V soft processor supporting the compressed instructions,
T. Kanamori and K. Kise, “RVCoreP-32IC: An optimized RISC-V soft processor supporting the compressed instructions,” inProc. IEEE 14th Int. Symp. Embedded Multicore/Many-core Syst.-on-Chip (MCSoC), 2021, pp. 38–45, doi: 10.1109/MCSoC51149.2021.00014
-
[21]
Quick-Div: Rethinking integer divider design for FPGA-based soft-processors,
E. Matthews, A. Lu, Z. Fang, and L. Shannon, “Quick-Div: Rethinking integer divider design for FPGA-based soft-processors,”ACM Trans. Reconfigurable Technol. Syst., vol. 15, no. 3, Sep. 2022, Art. no. 32
2022
-
[22]
A soft RISC-V processor IP with high-performance and low-resource consumption for FPGA,
T. Zheng, G. Cai, and Z. Huang, “A soft RISC-V processor IP with high-performance and low-resource consumption for FPGA,” inProc. IEEE Int. Symp. Circuits Syst. (ISCAS), 2022, pp. 2538–2541
2022
-
[23]
BRISC-V: An open-source architecture design space exploration toolbox,
S. Bandara, A. Ehret, D. Kava, and M. Kinsy, “BRISC-V: An open-source architecture design space exploration toolbox,” inProc. ACM/SIGDA Int. Symp. Field-Programmable Gate Arrays (FPGA), Seaside, CA, USA, 2019, p. 306, doi: 10.1145/3289602.3293991
-
[24]
SCOoOTER: A RISC-V processor framework and tool flow for an architecture-to-layout design course,
M. Scheck, Y . Lavan, C. Spang, and A. Koch, “SCOoOTER: A RISC-V processor framework and tool flow for an architecture-to-layout design course,” inProc. Workshop Comput. Archit. Educ. (WCAE), Tokyo, Japan, Oct. 2025, Art. no. 5
2025
-
[25]
SHAKTI processors: An open-source hardware initiative,
N. Gala, A. Menon, R. Bodduna, G. S. Madhusudan, and V . Kamakoti, “SHAKTI processors: An open-source hardware initiative,” inProc. 29th Int. Conf. VLSI Design 15th Int. Conf. Embedded Syst. (VLSID), 2016, pp. 7–8
2016
-
[26]
Dhrystone: A synthetic systems programming bench- mark,
R. P. Weicker, “Dhrystone: A synthetic systems programming bench- mark,”Commun. ACM, vol. 27, no. 10, pp. 1013–1030, Oct. 1984, doi: 10.1145/358274.358283
-
[27]
Two-level adaptive training branch prediction,
T.-Y . Yeh and Y . N. Patt, “Two-level adaptive training branch prediction,” inProc. 24th Annu. Int. Symp. Microarchit. (MICRO), Albuquerque, NM, USA, Nov. 1991, pp. 51–61
1991
-
[28]
Combining branch predictors,
S. McFarling, “Combining branch predictors,” Digital Equipment Corp. Western Research Lab., Palo Alto, CA, USA, Tech. Note TN-36, Jun. 1993
1993
-
[29]
The optimum pipeline depth for a microprocessor,
A. Hartstein and T. R. Puzak, “The optimum pipeline depth for a microprocessor,” inProc. 29th Annu. Int. Symp. Comput. Ar- chit. (ISCA), Anchorage, AK, USA, May 2002, pp. 7–13, doi: 10.1109/ISCA.2002.1003557
-
[30]
Exploring CoreMark: A benchmark maxi- mizing simplicity and efficacy,
S. Gal-On and M. Levy, “Exploring CoreMark: A benchmark maxi- mizing simplicity and efficacy,” EEMBC, White Paper, 2012. [Online]. Available: https://www.eembc.org/coremark/
2012
-
[31]
A study of branch prediction strategies,
J. E. Smith, “A study of branch prediction strategies,” inProc. 8th Annu. Symp. Comput. Archit. (ISCA), Minneapolis, MN, USA, May 1981, pp. 135–148
1981
-
[32]
BASIC RV32s: An open-source microar- chitectural roadmap for RISC-V RV32I,
H. W. Kang and J. W. Choi, “BASIC RV32s: An open-source microar- chitectural roadmap for RISC-V RV32I,” inProc. 22nd Int. SoC Design Conf. (ISOCC), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.