Recognition: unknown
SimPB++: Simultaneously Detecting 2D and 3D Objects from Multiple Cameras
Pith reviewed 2026-05-09 17:19 UTC · model grok-4.3
The pith
SimPB++ unifies 2D perspective detection and 3D BEV detection into one end-to-end multi-camera model with interactive decoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
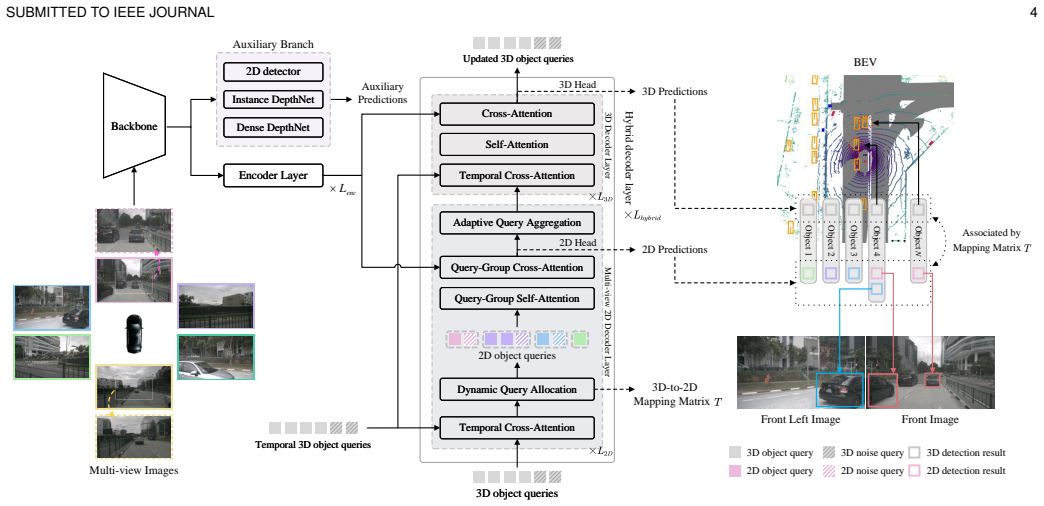
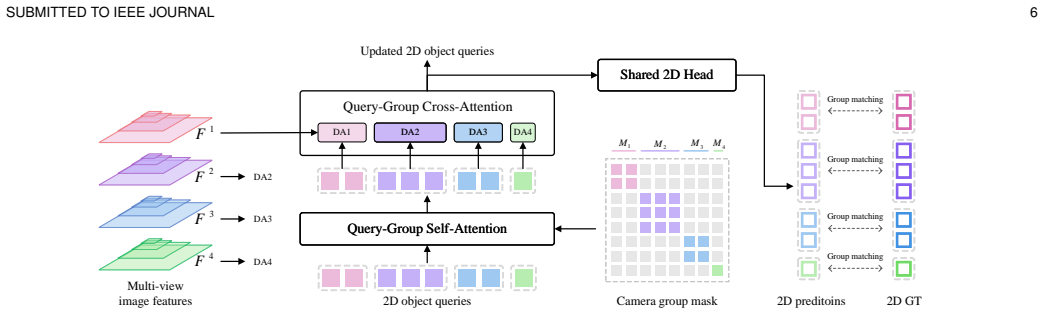
SimPB++ unifies both tasks into an end-to-end model with a hybrid decoder architecture, coupling multi-view 2D and 3D decoders interactively via Dynamic Query Allocation and Adaptive Query Aggregation, forming a cyclic 3D-2D-3D refinement. For multi-view 2D detection, Query-group Attention is used for intra-group communication along with a Crop-and-Scale strategy for long-range perception and a Propagating Denoising strategy with an auxiliary RoI detector. The model supports mixed supervision with 2D-only and fully annotated data.
What carries the argument
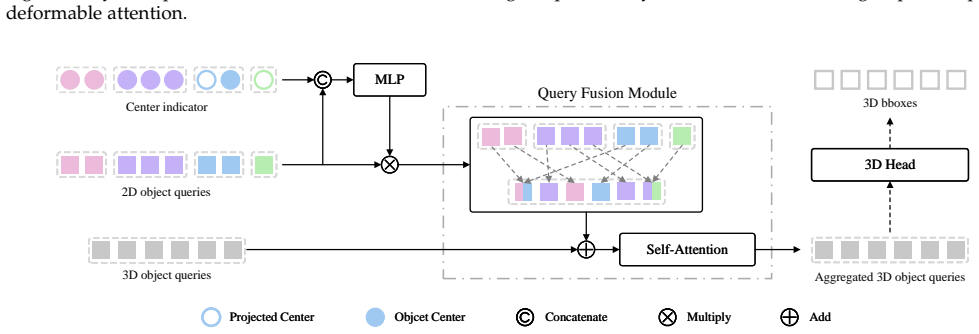
Hybrid decoder with Dynamic Query Allocation that adaptively assigns 2D queries to 3D candidates and Adaptive Query Aggregation that refines 3D representations using multi-view 2D features to enable cyclic refinement.
If this is right
- End-to-end joint training improves accuracy on both 2D perspective and 3D BEV detection compared with two-stage pipelines.
- The model reaches state-of-the-art performance on the nuScenes benchmark for both detection tasks.
- Mixed supervision allows training with cheaper 2D-only labels while still delivering strong 3D results.
- Long-range 3D detection extends reliably to 150 meters on Argoverse2.
Where Pith is reading between the lines
- The query-based interaction pattern could be tested on other coupled tasks such as joint depth estimation and semantic segmentation.
- Lower dependence on full 3D labels might speed up deployment in new geographic regions where only 2D annotations are available.
- The cyclic refinement loop suggests a route to improve robustness under partial occlusions or sensor dropout by letting 2D and 3D streams correct each other.
Load-bearing premise
The Dynamic Query Allocation and Adaptive Query Aggregation modules will create effective deep interactions between the 2D and 3D decoders that produce measurable gains over two-stage pipelines without adding instability.
What would settle it
An ablation experiment on nuScenes in which removing or replacing the Dynamic Query Allocation and Adaptive Query Aggregation modules yields no accuracy gain or a drop in either 2D or 3D detection metrics would falsify the value of the interactive coupling.
Figures










read the original abstract
Simultaneous perception of 2D objects in perspective view and 3D objects in Bird's Eye View (BEV) is challenging for multi-camera autonomous driving. Existing two-stage pipelines use 2D results only as a one-time cue for 3D detection. We propose SimPB++, which simultaneously detects 2D objects in perspective and 3D objects in BEV from multiple cameras. It unifies both tasks into an end-to-end model with a hybrid decoder architecture, coupling multi-view 2D and 3D decoders interactively. Two novel modules enable deep interaction: Dynamic Query Allocation adaptively assigns 2D queries to 3D candidates, and Adaptive Query Aggregation refines 3D representations using multi-view 2D features, forming a cyclic 3D-2D-3D refinement. For multi-view 2D detection, we use Query-group Attention for intra-group communication. We also design a Crop-and-Scale strategy for long-range perception and a Propagating Denoising strategy with an auxiliary RoI detector. SimPB++ supports mixed supervision with 2D-only and fully annotated data, reducing reliance on expensive 3D labels. Experiments show state-of-the-art performance on nuScenes for both tasks and strong long-range detection (up to 150m) on Argoverse2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SimPB++, an end-to-end model for simultaneous multi-view 2D perspective and 3D BEV object detection. It employs a hybrid decoder architecture that interactively couples 2D and 3D decoders using two novel modules—Dynamic Query Allocation for adaptive assignment of 2D queries to 3D candidates and Adaptive Query Aggregation for refining 3D representations with multi-view 2D features—creating a cyclic 3D-2D-3D refinement process. Additional components include Query-group Attention for 2D intra-group communication, a Crop-and-Scale strategy for long-range perception, and a Propagating Denoising strategy with an auxiliary RoI detector. The model supports mixed supervision using 2D-only and fully annotated data, and the authors claim state-of-the-art performance on nuScenes for both tasks along with strong long-range detection results on Argoverse2.
Significance. If the performance claims and the effectiveness of the interactive modules hold, this work could meaningfully advance unified 2D-3D perception pipelines in autonomous driving by moving beyond one-way cueing in two-stage systems and by enabling reduced reliance on costly 3D labels via mixed supervision. The hybrid decoder approach addresses a practical limitation in current multi-camera detectors.
major comments (2)
- [§4.3] §4.3 (Ablation Studies): The central claim that Dynamic Query Allocation and Adaptive Query Aggregation enable deep cyclic interaction and measurable gains over non-interactive hybrids is not load-bearingly demonstrated. No ablation removes only these two modules while retaining the hybrid decoder, Query-group Attention, Crop-and-Scale, and Propagating Denoising; without this control, it remains unclear whether the reported improvements on nuScenes NDS and mAP are carried by the claimed bidirectional coupling or by the overall architecture.
- [§4.4] §4.4 (Mixed Supervision Experiments): The results using 2D-only labels show gains, but the paper does not include a control that applies the auxiliary RoI detector without the 3D-2D-3D cycle. This leaves open whether the unification benefit, rather than the auxiliary detector alone, enables effective use of partial annotations, weakening the argument that the cyclic refinement is key to reducing 3D label dependency.
minor comments (2)
- [Abstract] Abstract: The claim of state-of-the-art performance on nuScenes is stated without any numerical values, baseline names, or dataset splits, which reduces immediate readability even though the full experiments section supplies these details.
- [Figure 2] Figure 2 (Architecture Diagram): The data-flow arrows between the 2D and 3D decoder branches could be labeled more explicitly to highlight the exact points at which Dynamic Query Allocation and Adaptive Query Aggregation operate, aiding readers in tracing the cyclic refinement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point-by-point below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Ablation Studies): The central claim that Dynamic Query Allocation and Adaptive Query Aggregation enable deep cyclic interaction and measurable gains over non-interactive hybrids is not load-bearingly demonstrated. No ablation removes only these two modules while retaining the hybrid decoder, Query-group Attention, Crop-and-Scale, and Propagating Denoising; without this control, it remains unclear whether the reported improvements on nuScenes NDS and mAP are carried by the claimed bidirectional coupling or by the overall architecture.
Authors: We agree that a more targeted control is needed to isolate the contribution of Dynamic Query Allocation and Adaptive Query Aggregation. Our existing §4.3 ablations compare the full model to variants lacking the interactive modules, but they do not hold the remainder of the hybrid decoder and auxiliary components fixed. We will add a new ablation that disables only these two modules while retaining Query-group Attention, Crop-and-Scale, and Propagating Denoising. This will directly test whether the bidirectional 3D-2D-3D coupling accounts for the observed gains on nuScenes. revision: yes
-
Referee: [§4.4] §4.4 (Mixed Supervision Experiments): The results using 2D-only labels show gains, but the paper does not include a control that applies the auxiliary RoI detector without the 3D-2D-3D cycle. This leaves open whether the unification benefit, rather than the auxiliary detector alone, enables effective use of partial annotations, weakening the argument that the cyclic refinement is key to reducing 3D label dependency.
Authors: We acknowledge the validity of this point. The mixed-supervision results in §4.4 demonstrate that our framework can leverage 2D-only data, yet they do not separate the effect of the auxiliary RoI detector from the cyclic refinement. We will add a control experiment that applies the auxiliary RoI detector without Dynamic Query Allocation and Adaptive Query Aggregation (i.e., without the 3D-2D-3D cycle). This will clarify whether the interactive unification is necessary for the observed benefits under partial annotation. revision: yes
Circularity Check
No circularity: architectural description with empirical validation
full rationale
The paper proposes a hybrid decoder architecture for simultaneous 2D/3D detection, introducing modules like Dynamic Query Allocation and Adaptive Query Aggregation to enable interaction. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or description. Claims rest on end-to-end training and benchmark results rather than any reduction to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked in the provided text. This is a standard empirical architecture paper whose central claims are externally falsifiable via ablation and comparison experiments.
Axiom & Free-Parameter Ledger
invented entities (5)
-
Dynamic Query Allocation
no independent evidence
-
Adaptive Query Aggregation
no independent evidence
-
Query-group Attention
no independent evidence
-
Crop-and-Scale strategy
no independent evidence
-
Propagating Denoising strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Simpb: A single model for 2d and 3d object detection from multiple cameras,
Y. Tang, Z. Meng, and E. Cheng, “Simpb: A single model for 2d and 3d object detection from multiple cameras,” inEuropean Conference on Computer Vision, 2024
2024
-
[2]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1137– 1149, 2017
2017
-
[3]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inIEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 779–788
2016
-
[4]
Fcos: Fully convolutional one-stage object detection,
Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: Fully convolutional one-stage object detection,” inIEEE International Conference on Computer Vision, 2019, pp. 9627–9636
2019
-
[5]
Monocular 3d object detection for autonomous driving,
X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun, “Monocular 3d object detection for autonomous driving,” inIEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2147–2156
2016
-
[6]
M3d-rpn: Monocular 3d region proposal network for object detection,
G. Brazil and X. Liu, “M3d-rpn: Monocular 3d region proposal network for object detection,” inIEEE International Conference on Computer Vision, 2019, pp. 9287–9296
2019
-
[7]
Fcos3d: Fully convolutional one-stage monocular 3d object detection,
T. Wang, X. Zhu, J. Pang, and D. Lin, “Fcos3d: Fully convolutional one-stage monocular 3d object detection,” inIEEE International Conference on Computer Vision, 2021, pp. 913–922
2021
-
[8]
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,
Y. Wang, V . Guizilini, T. Zhang, Y. Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” 2021, pp. 180–191
2021
-
[9]
Bevformer: Learning bird’s-eye-view representation from multi- camera images via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi- camera images via spatiotemporal transformers,” inEuropean Con- ference on Computer Vision, 2022, pp. 1–18
2022
-
[10]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean Conference on Computer Vision, 2020, pp. 194–210
2020
-
[11]
Bevdepth: Acquisition of reliable depth for multi-view 3d object detection,
Y. Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y. Shi, J. Sun, and Z. Li, “Bevdepth: Acquisition of reliable depth for multi-view 3d object detection,” inAAAI Conference on Artificial Intelligence, 2023, pp. 1477–1485
2023
-
[12]
Bevnext: Reviving dense bev frameworks for 3d object detection,
Z. Li, S. Lan, J. M. Alvarez, and Z. Wu, “Bevnext: Reviving dense bev frameworks for 3d object detection,” inIEEE Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 113–20 123
2024
-
[13]
Petr: Position embedding transformation for multi-view 3d object detection,
Y. Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding transformation for multi-view 3d object detection,” inEuropean Conference on Computer Vision, 2022, pp. 531–548
2022
-
[14]
arXiv preprint arXiv:2211.10581 (2022)
X. Lin, T. Lin, Z. Pei, L. Huang, and Z. Su, “Sparse4d: Multi-view 3d object detection with sparse spatial-temporal fusion,”arXiv preprint arXiv:2211.10581, 2022
-
[15]
Exploring object- centric temporal modeling for efficient multi-view 3d object detec- tion,
S. Wang, Y. Liu, T. Wang, Y. Li, and X. Zhang, “Exploring object- centric temporal modeling for efficient multi-view 3d object detec- tion,” inIEEE International Conference on Computer Vision, 2023, pp. 3621–3631
2023
-
[16]
Sparsebev: High-performance sparse 3d object detection from multi-camera videos,
H. Liu, Y. Teng, T. Lu, H. Wang, and L. Wang, “Sparsebev: High-performance sparse 3d object detection from multi-camera videos,” inIEEE International Conference on Computer Vision, 2023, pp. 18 580–18 590
2023
-
[17]
End-to-end object detection with transformers,
C. Nicolas, M. Francisco, S. Gabriel, U. Nicolas, K. Alexander, and Z. Sergey, “End-to-end object detection with transformers,” inEuropean Conference on Computer Vision, 2020, pp. 213—-229
2020
-
[18]
Focal-petr: Embracing foreground for efficient multi-camera 3d object detection,
S. Wang, X. Jiang, and Y. Li, “Focal-petr: Embracing foreground for efficient multi-camera 3d object detection,”IEEE Transactions on Intelligent Vehicles, 2023
2023
-
[19]
Object as query: Equipping any 2d object detector with 3d detection ability,
Z. Wang, Z. Huang, J. Fu, N. Wang, and S. Liu, “Object as query: Equipping any 2d object detector with 3d detection ability,” in IEEE International Conference on Computer Vision, 2023, pp. 3791– 3800
2023
-
[20]
Far3d: Expanding the horizon for surround-view 3d object detection,
X. Jiang, S. Li, Y. Liu, S. Wang, F. Jia, T. Wang, L. Han, and X. Zhang, “Far3d: Expanding the horizon for surround-view 3d object detection,” inAAAI Conference on Artificial Intelligence, 2023
2023
-
[21]
arXiv preprint arXiv:2311.11722 (2023)
X. Lin, Z. Pei, T. Lin, L. Huang, and Z. Su, “Sparse4d v3: Ad- vancing end-to-end 3d detection and tracking,”arXiv preprint arXiv:2311.11722, 2023
-
[22]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. Vora, V . E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inIEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 618–11 628
2020
-
[23]
Argoverse 2: Next generation datasets for self-driving perception and forecasting,
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. Pontes, D. Ramanan, P . Carr, and J. Hays, “Argoverse 2: Next generation datasets for self-driving perception and forecasting,” inAdvances in Neural Information Processing Systems, Aug 2021
2021
-
[24]
Cascade r-cnn: Delving into high quality object detection,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” inIEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6154–6162
2018
-
[25]
Libra r-cnn: Towards balanced learning for object detection,
J. Pang, K. Chen, J. Shi, H. Feng, W. Ouyang, and D. Lin, “Libra r-cnn: Towards balanced learning for object detection,” inIEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 821–830
2019
-
[26]
Center- net: Keypoint triplets for object detection,
K. Duan, S. Bai, L. Xie, H. Qi, Q. Huang, and Q. Tian, “Center- net: Keypoint triplets for object detection,” inIEEE International Conference on Computer Vision, 2019, pp. 6569–6578
2019
-
[27]
Deformable detr: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” in International Conference on Learning Representations, 2020
2020
-
[28]
Conditional detr for fast training convergence,
D. Meng, X. Chen, Z. Fan, G. Zeng, H. Li, Y. Yuan, L. Sun, and J. Wang, “Conditional detr for fast training convergence,” inIEEE International Conference on Computer Vision, 2021, pp. 3651–3660
2021
-
[29]
Sparse detr: Efficient end- to-end object detection with learnable sparsity,
B. Roh, J. Shin, W. Shin, and S. Kim, “Sparse detr: Efficient end- to-end object detection with learnable sparsity,” inInternational Conference on Learning Representations, 2021
2021
-
[30]
Dab-detr: Dynamic anchor boxes are better queries for detr,
S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, and L. Zhang, “Dab-detr: Dynamic anchor boxes are better queries for detr,” in International Conference on Learning Representations, 2022
2022
-
[31]
Dino: Detr with improved denoising anchor boxes for end-to-end object detection,
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.- Y. Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,” inInternational Conference on Learning Representations, 2022
2022
-
[32]
Detrs with collaborative hybrid assignments training,
Z. Zong, G. Song, and Y. Liu, “Detrs with collaborative hybrid assignments training,” inIEEE International Conference on Computer Vision, 2023, pp. 6748–6758
2023
-
[33]
J. Huang, G. Huang, Z. Zhu, Y. Ye, and D. Du, “Bevdet: High- performance multi-camera 3d object detection in bird-eye-view,” arXiv preprint arXiv:2112.11790, 2021
-
[34]
arXiv preprint arXiv:2203.17054 (2022)
J. Huang and G. Huang, “Bevdet4d: Exploit temporal cues in multi-camera 3d object detection,”arXiv preprint arXiv:2203.17054, 2022
-
[35]
Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via per- spective supervision,
C. Yang, Y. Chen, H. Tian, C. Tao, X. Zhu, Z. Zhang, G. Huang, H. Li, Y. Qiao, L. Lu, J. Zhou, and J. Dai, “Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via per- spective supervision,” inIEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 830–17 839
2023
-
[36]
Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo,
Y. Li, H. Bao, Z. Ge, J. Yang, J. Sun, and Z. Li, “Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo,” inAAAI Conference on Artificial Intelligence, 2023, pp. 1486–1494
2023
-
[37]
Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection,
J. Park, C. Xu, S. Yang, K. Keutzer, K. Kitani, M. Tomizuka, and W. Zhan, “Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection,” inInternational Conference on Learning Representations, 2023
2023
-
[38]
Exploring recurrent long-term temporal fusion for multi-view 3d perception,
C. Han, J. Yang, J. Sun, Z. Ge, R. Dong, H. Zhou, W. Mao, Y. Peng, and X. Zhang, “Exploring recurrent long-term temporal fusion for multi-view 3d perception,”IEEE Robotics and Automation Letters, vol. 9, no. 7, pp. 6544–6551, 2024
2024
-
[39]
Temporal enhanced training of multi-view 3d object detector via historical object prediction,
Z. Zong, D. Jiang, G. Song, Z. Xue, J. Su, H. Li, and Y. Liu, “Temporal enhanced training of multi-view 3d object detector via historical object prediction,” inIEEE International Conference on Computer Vision, 2023
2023
-
[40]
Geobev: Learning geometric bev representation for multi-view 3d object detection,
J. Zhang, Y. Zhang, Y. Qi, Z. Fu, Q. Liu, and Y. Wang, “Geobev: Learning geometric bev representation for multi-view 3d object detection,” inAAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9960–9968
2025
-
[41]
Petrv2: A unified framework for 3d perception from multi-camera im- ages,
Y. Liu, J. Yan, F. Jia, S. Li, A. Gao, T. Wang, and X. Zhang, “Petrv2: A unified framework for 3d perception from multi-camera im- ages,” inIEEE International Conference on Computer Vision, 2023, pp. 3262–3272
2023
-
[42]
Detr4d: Direct multi- view 3d object detection with sparse attention,
Z. Luo, C. Zhou, G. Zhang, and S. Lu, “Detr4d: Direct multi- view 3d object detection with sparse attention,”arXiv preprint arXiv:2212.07849, 2022
-
[43]
Sparse4d v2: Recurrent temporal fusion with sparse model.arXiv preprint arXiv:2305.14018, 2023
X. Lin, T. Lin, Z. Pei, L. Huang, and Z. Su, “Sparse4d v2: Recurrent temporal fusion with sparse model,”arXiv preprint arXiv:2305.14018, 2023. SUBMITTED TO IEEE JOURNAL 16
-
[44]
Dynamicbev: Leveraging dynamic queries and temporal context for 3d object detection,
J. Yao and Y. Lai, “Dynamicbev: Leveraging dynamic queries and temporal context for 3d object detection,”arXiv preprint arXiv:2310.05989, 2023
-
[45]
Bridging perspectives: Foundation model guided bev maps for 3d object detection and tracking,
M. K ¨appeler, ¨Ozg ¨un C ¸ ic ¸ek, D. Cattaneo, C. Gl¨aser, Y. Miron, and A. Valada, “Bridging perspectives: Foundation model guided bev maps for 3d object detection and tracking,” 2025
2025
-
[46]
Vision-based detec- tion and distance estimation of micro unmanned aerial vehicles,
F. G ¨okc ¸e, G.¨Uc ¸oluk, E. S ¸ahin, and S. Kalkan, “Vision-based detec- tion and distance estimation of micro unmanned aerial vehicles,” Sensors, vol. 15, no. 9, pp. 23 805–23 846, 2015
2015
-
[47]
Disnet: A novel method for distance estimation from monocular camera,
M. A. Haseeb, J. Guan, D. Ristic-Durrant, and A. Gr ¨aser, “Disnet: A novel method for distance estimation from monocular camera,” 10th Planning, Perception and Navigation for Intelligent Vehicles (PP- NIV18), IROS, 2018
2018
-
[48]
Learn- ing object-specific distance from a monocular image,
J. Zhu, Y. Fang, H. Abu-Haimed, K. Lien, D. Fu, and J. Gu, “Learn- ing object-specific distance from a monocular image,”CoRR, 2019
2019
-
[49]
R4d: Utilizing reference objects for long-range distance estimation,
Y. Li, T. Chen, M. Kabkab, R. Yu, L. Jing, Y. You, and H. Zhao, “R4d: Utilizing reference objects for long-range distance estimation,” arXiv preprint arXiv:2206.04831, 2022
-
[50]
Improving distant 3d object detection using 2d box supervision,
Z. Yang, Z. Yu, C. Choy, R. Wang, A. Anandkumar, and J. M. Alvarez, “Improving distant 3d object detection using 2d box supervision,” inIEEE Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 853–14 863
2024
-
[51]
Towards long-range 3d object detection for autonomous vehi- cles,
A. Khoche, L. P . S´anchez, N. Batool, S. S. Mansouri, and P . Jensfelt, “Towards long-range 3d object detection for autonomous vehi- cles,” in2024 IEEE Intelligent Vehicles Symposium. IEEE, 2024, pp. 2206–2212
2024
-
[52]
Sparsefusion: Efficient sparse multi-modal fusion framework for long-range 3d perception,
Y. Li, H. Li, Z. Huang, H. Chang, and N. Wang, “Sparsefusion: Efficient sparse multi-modal fusion framework for long-range 3d perception,”arXiv preprint arXiv:2403.10036, 2024
-
[53]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[54]
An energy and gpu-computation efficient backbone network for real-time object detection,
Y. Lee, J.-w. Hwang, S. Lee, Y. Bae, and J. Park, “An energy and gpu-computation efficient backbone network for real-time object detection,” inIEEE Conference on Computer Vision and Pattern Recognition, 2019
2019
-
[55]
Dn- detr: Accelerate detr training by introducing query denoising,
F. Li, H. Zhang, S. Liu, J. Guo, L. M. Ni, and L. Zhang, “Dn- detr: Accelerate detr training by introducing query denoising,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 619–13 627
2022
-
[56]
Ray denoising: Depth-aware hard negative sampling for multi-view 3d object detection,
F. Liu, T. Huang, Q. Zhang, H. Yao, C. Zhang, F. Wan, Q. Ye, and Y. Zhou, “Ray denoising: Depth-aware hard negative sampling for multi-view 3d object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 200–217
2024
-
[57]
3d bound- ing box estimation using deep learning and geometry,
A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka, “3d bound- ing box estimation using deep learning and geometry,” inIEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 7074–7082
2017
-
[58]
Microsoft coco: Common objects in context,
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ramanan, P . Doll´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean Conference on Computer Vision. Springer, 2014, pp. 740–755
2014
-
[59]
Class-balanced grouping and sampling for point cloud 3d object detection,
B. Zhu, Z. Jiang, X. Zhou, Z. Li, and G. Yu, “Class-balanced grouping and sampling for point cloud 3d object detection,”arXiv preprint arXiv:1908.09492, 2019
-
[60]
Corrbev: Multi- view 3d object detection by correlation learning with multi-modal prototypes,
Z. Xue, M. Guo, H. Fan, S. Zhang, and Z. Zhang, “Corrbev: Multi- view 3d object detection by correlation learning with multi-modal prototypes,” inIEEE Conference on Computer Vision and Pattern Recognition, 2025, pp. 27 413–27 423. SUBMITTED TO IEEE JOURNAL 1 Supplementary Material This supplementary material contains additional details of the main manuscr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.