Recognition: unknown
CADFS: A Big CAD Program Dataset and Framework for Computer-Aided Design with Large Language Models
Pith reviewed 2026-05-09 17:14 UTC · model grok-4.3
The pith
A FeatureScript representation and dataset of 450k real CAD models let vision-language models generate complex designs from text or images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce CADFS, a data-centric framework that enables large vision-language models to generate complex CAD design histories. Existing generative CAD systems are restricted to sketch-extrude operations due to simplified representations and limited datasets. We address this by introducing a FeatureScript-based representation and constructing a dataset of 450k real-world CAD models spanning 15 modeling operations. We obtain the dataset via a new pipeline that reconstructs clean, executable FeatureScript programs and provides multimodal annotations. Fine-tuning a VLM on this representation yields state-of-the-art results in text-conditioned CAD generation and image-based reconstruction, with
What carries the argument
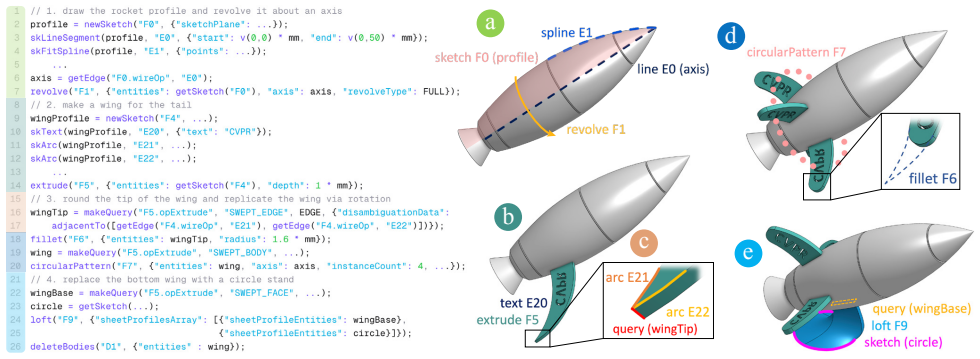
The FeatureScript-based representation that encodes CAD design histories as clean, executable sequences of 15 modeling operations reconstructed from real models.
If this is right
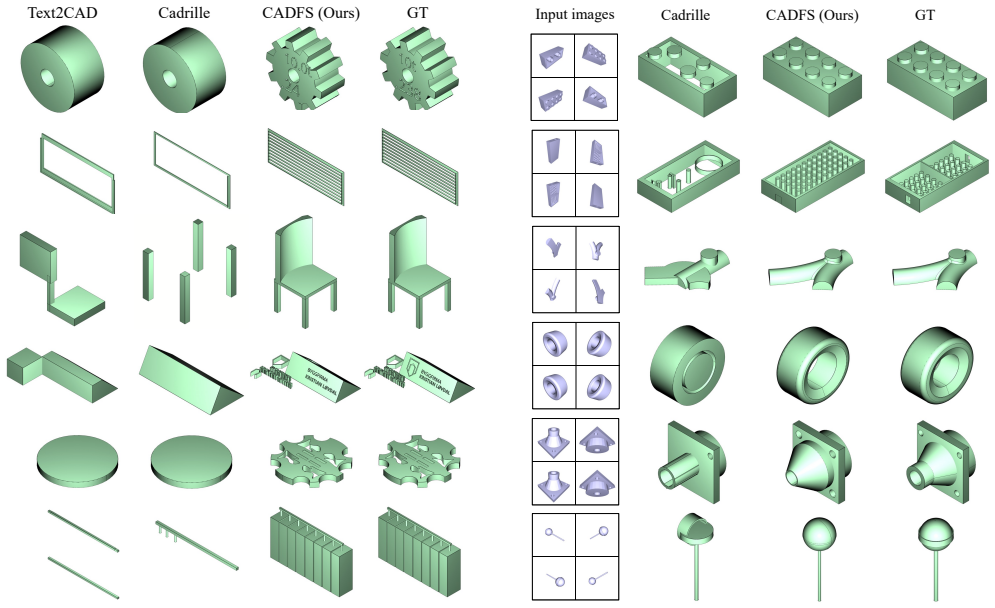
- Text-conditioned generation produces more accurate and diverse CAD designs than prior methods.
- Image-based reconstruction yields models with richer features that better match the input images.
- Each framework component—the FeatureScript representation, the extended operation set, and representation-aligned descriptions—individually improves results.
- Generative CAD systems can now achieve substantially higher complexity and realism.
Where Pith is reading between the lines
- The same reconstruction method could be applied to other CAD file formats to enlarge training data further.
- Professional CAD software might incorporate these models to auto-generate editable starting programs from rough descriptions or photos.
- Running the outputs in commercial tools would provide a practical test of whether the generated programs remain usable for engineering workflows.
- Combining the approach with simulation feedback loops could enable iterative design optimization beyond single-step generation.
Load-bearing premise
The reconstruction pipeline produces clean, executable FeatureScript programs that faithfully capture the original real-world CAD models without significant loss of fidelity or introduction of artifacts.
What would settle it
Generated FeatureScript programs either fail to run in a CAD interpreter or produce outputs whose structure and features deviate substantially from the input text or image prompts.
Figures









read the original abstract
We introduce CADFS, a data-centric framework that enables large vision-language models to generate complex CAD design histories. Existing generative CAD systems are restricted to sketch-extrude operations due to simplified representations and limited datasets. We address this by introducing a FeatureScript-based representation and constructing a dataset of 450k real-world CAD models spanning 15 modeling operations. We obtain the dataset via a new pipeline that reconstructs clean, executable FeatureScript programs and provides multimodal annotations. Fine-tuning a VLM on this representation yields state-of-the-art results in text-conditioned CAD generation and image-based reconstruction, producing more accurate, diverse, and feature-rich designs than prior frameworks. Ablations show that each individual component of our framework, i.e., the FeatureScript representation, the extended operation set, and representation-aligned textual descriptions, significantly improves performance. Our framework substantially broadens the complexity and realism achievable in generative CAD. The CADFS framework and the new dataset are available at https://voyleg.github.io/cadfs/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CADFS, a data-centric framework and dataset of 450k real-world CAD models represented as executable FeatureScript programs spanning 15 modeling operations. It presents a reconstruction pipeline that converts models into clean programs with multimodal annotations, then shows that fine-tuning a vision-language model on this representation achieves state-of-the-art results on text-conditioned CAD generation and image-based reconstruction, outperforming prior sketch-extrude baselines in accuracy, diversity, and feature richness. Ablations demonstrate the contribution of the FeatureScript representation, extended operation set, and aligned textual descriptions. The dataset and framework are released publicly.
Significance. If the central results hold, the work would meaningfully advance generative CAD by moving beyond simplified sketch-extrude representations to richer, executable program histories, enabling more complex and realistic designs. The public release of the large-scale dataset and the empirical ablations on representation choices are concrete strengths that could support follow-on research in program-based generative modeling.
major comments (2)
- [Dataset Construction] Dataset Construction section: The abstract and methods claim that the reconstruction pipeline produces 'clean, executable FeatureScript programs' that faithfully capture real-world models, yet no quantitative metrics are reported on reconstruction success rate, execution failure rate, geometric fidelity (e.g., deviation from original B-rep), or feature-preservation statistics. Without these, it is impossible to assess whether a non-negligible fraction of the 450k programs contain artifacts or omissions, which directly affects the reliability of the downstream SOTA claims and the attribution of gains to the new representation rather than data quality.
- [Experiments] Experiments section (text-to-CAD and image-to-CAD results): The reported improvements over prior frameworks are presented without error bars, statistical significance tests, or detailed failure-case analysis. Given that the central claim rests on the fidelity of the training data, the absence of these controls makes it difficult to determine whether the gains are robust or sensitive to the unquantified reconstruction errors.
minor comments (2)
- [Representation] The description of the 15 modeling operations and how they map to FeatureScript primitives could be expanded with a table or explicit list for reproducibility.
- [Figures] Figure captions and axis labels in the qualitative results could more clearly indicate which method corresponds to each column to aid visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on dataset construction and experimental reporting. The comments identify areas where additional quantitative details can strengthen the manuscript. We address each point below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset Construction section: The abstract and methods claim that the reconstruction pipeline produces 'clean, executable FeatureScript programs' that faithfully capture real-world models, yet no quantitative metrics are reported on reconstruction success rate, execution failure rate, geometric fidelity (e.g., deviation from original B-rep), or feature-preservation statistics. Without these, it is impossible to assess whether a non-negligible fraction of the 450k programs contain artifacts or omissions, which directly affects the reliability of the downstream SOTA claims and the attribution of gains to the new representation rather than data quality.
Authors: We agree that explicit quantitative metrics on reconstruction quality would improve transparency and allow better assessment of data fidelity. While the pipeline was designed to produce executable programs (verified by successful execution in the Onshape environment for all retained models), aggregate statistics were not included in the original submission. In the revised manuscript, we will add a new subsection to the Dataset Construction section that reports: reconstruction success rate (fraction of input models converted to valid executable FeatureScript), execution failure rates by operation type, geometric fidelity measures (e.g., average surface deviation or volume error on a held-out validation subset of B-rep models), and feature-preservation rates (percentage of original modeling features retained). These will be derived from our construction logs and validation runs. This addition will directly support the reliability of the dataset and the attribution of performance gains to the FeatureScript representation. revision: yes
-
Referee: [Experiments] Experiments section (text-to-CAD and image-to-CAD results): The reported improvements over prior frameworks are presented without error bars, statistical significance tests, or detailed failure-case analysis. Given that the central claim rests on the fidelity of the training data, the absence of these controls makes it difficult to determine whether the gains are robust or sensitive to the unquantified reconstruction errors.
Authors: We concur that error bars, statistical significance testing, and failure-case analysis would enhance the rigor of the experimental claims. In the revised Experiments section, we will include: error bars (standard deviation across multiple training seeds or evaluation splits) for all primary metrics such as accuracy, diversity, and feature richness; statistical significance tests (e.g., paired t-tests) with p-values comparing our method to baselines; and a dedicated failure-case analysis subsection providing both quantitative breakdowns (e.g., rates of incomplete feature generation) and qualitative examples. These additions will demonstrate robustness and address potential sensitivity to any residual reconstruction issues. Our existing ablations already isolate the contributions of the representation and operation set, but the new controls will further substantiate the SOTA results. revision: yes
Circularity Check
No significant circularity in empirical dataset and fine-tuning pipeline
full rationale
The paper describes an empirical data-centric framework: a reconstruction pipeline converts real-world CAD models into FeatureScript programs to build a 450k dataset, followed by VLM fine-tuning for generation tasks. No mathematical derivations, equations, or first-principles predictions are present that could reduce to inputs by construction. Claims of SOTA performance rest on experimental ablations and comparisons, not on self-definitional fits or self-citation chains. The reconstruction step is a constructive process, not a predictive derivation that loops back to its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can be fine-tuned on CAD program representations to perform text-to-CAD and image-to-CAD generation
Reference graph
Works this paper leans on
-
[1]
https://cad.onshape.com/FsDoc/
FeatureScript, CAD scripting language. https://cad.onshape.com/FsDoc/. 2
-
[2]
Available at: https://www.onshape.com/en/
Onshape, 2025. Available at: https://www.onshape.com/en/. 2, 3
2025
-
[3]
GenCAD: Image- Conditioned Computer-Aided Design Generation with Transformer-Based Contrastive Representation and Diffusion Priors, 2024
Md Ferdous Alam and Faez Ahmed. GenCAD: Image- Conditioned Computer-Aided Design Generation with Transformer-Based Contrastive Representation and Diffusion Priors, 2024. 1
2024
-
[4]
Generating CAD Code with Vision-Language Models for 3D Designs
Kamel Alrashedy, Pradyumna Tambwekar, Zulfiqar Haider Zaidi, Megan Langwasser, Wei Xu, and Matthew Gombolay. Generating CAD Code with Vision-Language Models for 3D Designs. InThe Thirteenth International Conference on Learning Representations, 2024. 1, 2
2024
-
[5]
Query2CAD: Generating CAD models using natu- ral language queries, 2024
Akshay Badagabettu, Sai Sravan Yarlagadda, and Amir Barati Farimani. Query2CAD: Generating CAD models using natu- ral language queries, 2024. 2
2024
-
[6]
Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An Information-Rich 3D Model Repos- itory, 2015. 3
2015
-
[7]
Img2CAD: Conditioned 3D CAD Model Generation from Single Image with Structured Visual Geom- etry, 2024
Tianrun Chen, Chunan Yu, Yuanqi Hu, Jing Li, Tao Xu, Run- long Cao, Lanyun Zhu, Ying Zang, Yong Zhang, Zejian Li, and Linyun Sun. Img2CAD: Conditioned 3D CAD Model Generation from Single Image with Structured Visual Geom- etry, 2024. 1, 2
2024
-
[8]
Pvde- conv: Point-V oxel Deconvolution for Autoencoding CAD Construction in 3D
Kseniya Cherenkova, Djamila Aouada, and Gleb Gusev. Pvde- conv: Point-V oxel Deconvolution for Autoencoding CAD Construction in 3D. In2020 IEEE International Conference on Image Processing (ICIP), pages 2741–2745, 2020. 3
2020
-
[9]
Cadquery, 2025
CadQuery contributors. Cadquery, 2025. 3
2025
-
[10]
FlashAttention-2: Faster attention with better paral- lelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better paral- lelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024. 12
2024
-
[11]
Doris, Md Ferdous Alam, Amin Heyrani Nobari, and Faez Ahmed
Anna C. Doris, Md Ferdous Alam, Amin Heyrani Nobari, and Faez Ahmed. CAD-Coder: An Open-Source Vision- Language Model for Computer-Aided Design Code Genera- tion, 2025. 2, 3
2025
-
[12]
CADOps-Net: Jointly Learning CAD Operation Types and Steps from Boundary-Representations
Elona Dupont, Kseniya Cherenkova, Anis Kacem, Sk Aziz Ali, Ilya Arzhannikov, Gleb Gusev, and Djamila Aouada. CADOps-Net: Jointly Learning CAD Operation Types and Steps from Boundary-Representations. In2022 International Conference on 3D Vision (3DV), pages 114–123, 2022. 3
2022
-
[13]
TransCAD: A Hier- archical Transformer for CAD Sequence Inference from Point Clouds
Elona Dupont, Kseniya Cherenkova, Dimitrios Mallis, Gleb Gusev, Anis Kacem, and Djamila Aouada. TransCAD: A Hier- archical Transformer for CAD Sequence Inference from Point Clouds. InComputer Vision – ECCV 2024, pages 19–36, Cham, 2025. Springer Nature Switzerland. 1, 2
2024
-
[14]
CAD-Coder: Text-to-CAD Generation with Chain-of-Thought and Geometric Reward, 2025
Yandong Guan, Xilin Wang, Xingxi Ming, Jing Zhang, Dong Xu, and Qian Yu. CAD-Coder: Text-to-CAD Generation with Chain-of-Thought and Geometric Reward, 2025. 1, 2, 3
2025
-
[15]
Liger- kernel: Efficient triton kernels for LLM training
Pin-Lun Hsu, Yun Dai, Vignesh Kothapalli, Qingquan Song, Shao Tang, Siyu Zhu, Steven Shimizu, Shivam Sahni, Haowen Ning, Yanning Chen, and Zhipeng Wang. Liger- kernel: Efficient triton kernels for LLM training. InCham- pioning Open-source DEvelopment in ML Workshop @ ICML25, 2025. 12
2025
-
[16]
Text2CAD: Generating sequential CAD designs from beginner-to-expert level text prompts
Mohammad Sadil Khan, Sankalp Sinha, Talha Uddin Sheikh, Didier Stricker, Sk Aziz Ali, and Muhammad Zeshan Afzal. Text2CAD: Generating sequential CAD designs from beginner-to-expert level text prompts. InProceedings of the 38th International Conference on Neural Information Pro- cessing Systems, pages 7552–7579, Red Hook, NY , USA,
-
[17]
1, 2, 3, 5, 6, 7, 9
Curran Associates Inc. 1, 2, 3, 5, 6, 7, 9
-
[18]
A Large-Scale Annotated Mechanical Com- ponents Benchmark for Classification and Retrieval Tasks with Deep Neural Networks
Sangpil Kim, Hyung-gun Chi, Xiao Hu, Qixing Huang, and Karthik Ramani. A Large-Scale Annotated Mechanical Com- ponents Benchmark for Classification and Retrieval Tasks with Deep Neural Networks. InComputer Vision – ECCV 2020, pages 175–191, Cham, 2020. Springer International Publishing. 3
2020
-
[19]
ABC: A Big CAD Model Dataset for Geometric Deep Learning
Sebastian Koch, Albert Matveev, Zhongshi Jiang, Francis Williams, Alexey Artemov, Evgeny Burnaev, Marc Alexa, Denis Zorin, and Daniele Panozzo. ABC: A Big CAD Model Dataset for Geometric Deep Learning. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9593–9603, 2019. 3, 5, 7
2019
-
[20]
Cadrille: Multi-modal CAD Reconstruction with Reinforce- ment Learning
Maksim Kolodiazhnyi, Denis Tarasov, Dmitrii Zhemchuzh- nikov, Alexander Nikulin, Ilya Zisman, Anna V orontsova, Anton Konushin, Vladislav Kurenkov, and Danila Rukhovich. Cadrille: Multi-modal CAD Reconstruction with Reinforce- ment Learning. InThe Fourteenth International Conference on Learning Representations, 2025. 1, 2, 3, 6, 7, 11
2025
-
[21]
CAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation
Jiahao Li, Weijian Ma, Xueyang Li, Yunzhong Lou, Guichun Zhou, and Xiangdong Zhou. CAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1, 2
2025
-
[22]
SECAD-Net: Self-Supervised CAD Reconstruction by Learn- ing Sketch-Extrude Operations
Pu Li, Jianwei Guo, Xiaopeng Zhang, and Dong-Ming Yan. SECAD-Net: Self-Supervised CAD Reconstruction by Learn- ing Sketch-Extrude Operations. In2023 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 16816–16826, 2023. 7
2023
-
[23]
Mamba-CAD: State Space Model for 3D Computer-Aided Design Generative Modeling.Proceedings of the AAAI Con- ference on Artificial Intelligence, 39(5):5013–5021, 2025
Xueyang Li, Yunzhong Lou, Yu Song, and Xiangdong Zhou. Mamba-CAD: State Space Model for 3D Computer-Aided Design Generative Modeling.Proceedings of the AAAI Con- ference on Artificial Intelligence, 39(5):5013–5021, 2025. 3
2025
-
[24]
CADDreamer: CAD Object Generation from Single- view Images
Yuan Li, Cheng Lin, Yuan Liu, Xiaoxiao Long, Chenxu Zhang, Ningna Wang, Xin Li, Wenping Wang, and Xiaohu Guo. CADDreamer: CAD Object Generation from Single- view Images. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1, 3
2025
-
[25]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Draw Step by Step: Reconstructing CAD Construction Sequences from Point Clouds via Multimodal Diffusion
Weijian Ma, Shuaiqi Chen, Yunzhong Lou, Xueyang Li, and Xiangdong Zhou. Draw Step by Step: Reconstructing CAD Construction Sequences from Point Clouds via Multimodal Diffusion. In2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 27144–27153,
-
[27]
VideoCAD: A Dataset and Model for Learning Long- Horizon 3D CAD UI Interactions from Video, 2025
Brandon Man, Ghadi Nehme, Md Ferdous Alam, and Faez Ahmed. VideoCAD: A Dataset and Model for Learning Long- Horizon 3D CAD UI Interactions from Video, 2025. 3 20
2025
-
[28]
Don’t Mesh with Me: Generating Constructive Solid Geometry Instead of Meshes by Fine- Tuning a Code-Generation LLM, 2025
Maximilian Mews, Ansar Aynetdinov, Vivian Schiller, Peter Eisert, and Alan Akbik. Don’t Mesh with Me: Generating Constructive Solid Geometry Instead of Meshes by Fine- Tuning a Code-Generation LLM, 2025. 2
2025
-
[29]
Chang, Li Yi, Subarna Tripathi, Leonidas J
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. PartNet: A Large- Scale Benchmark for Fine-Grained and Hierarchical Part- Level 3D Object Understanding. In2019 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 909–918, 2019. 3
2019
-
[30]
OpenAI, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, Vlad...
2025
-
[31]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yux- iong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InPro- ceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, page 3505–3506, New York, NY , USA, 2020. Association for Computing Ma- chinery. 12
2020
-
[32]
CAD- Recode: Reverse Engineering CAD Code from Point Clouds,
Danila Rukhovich, Elona Dupont, Dimitrios Mallis, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. CAD- Recode: Reverse Engineering CAD Code from Point Clouds,
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Text-to- CAD Generation Through Infusing Visual Feedback in Large Language Models
Ruiyu Wang, Yu Yuan, Shizhao Sun, and Jiang Bian. Text-to- CAD Generation Through Infusing Visual Feedback in Large Language Models. InProceedings of the 42th International Conference on Machine Learning, 2025. 1, 2, 5
2025
-
[35]
Karl D. D. Willis, Yewen Pu, Jieliang Luo, Hang Chu, Tao Du, Joseph G. Lambourne, Armando Solar-Lezama, and Woj- ciech Matusik. Fusion 360 gallery: A dataset and environment for programmatic CAD construction from human design se- quences.ACM Trans. Graph., 40(4):54:1–54:24, 2021. 3
2021
-
[36]
CMT: A Cascade MAR with Topology Predic- tor for Multimodal Conditional CAD Generation
Jianyu Wu, Yizhou Wang, Xiangyu Yue, Xinzhu Ma, Jingyang Guo, Dongzhan Zhou, Wanli Ouyang, and Shix- iang Tang. CMT: A Cascade MAR with Topology Predic- tor for Multimodal Conditional CAD Generation. In2025 IEEE/CVF International Conference on Computer Vision (ICCV), pages 7014–7024, 2025. 1, 3
2025
-
[37]
DeepCAD: A Deep Generative Network for Computer-Aided Design Models
Rundi Wu, Chang Xiao, and Changxi Zheng. DeepCAD: A Deep Generative Network for Computer-Aided Design Models. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6752–6762, 2021. 2, 3, 5, 6, 7, 11, 14
2021
-
[38]
3D ShapeNets: A deep representation for volumetric shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Lin- guang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3D ShapeNets: A deep representation for volumetric shapes. In2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1912–1920, 2015. 3
1912
-
[39]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 21469–21480, 2025. 6, 11
2025
-
[40]
Text-to-CadQuery: A New Paradigm for CAD Generation with Scalable Large Model Capabilities, 2025
Haoyang Xie and Feng Ju. Text-to-CadQuery: A New Paradigm for CAD Generation with Scalable Large Model Capabilities, 2025. 1, 2, 3
2025
-
[41]
CAD-MLLM: Unifying Multimodality- Conditioned CAD Generation With MLLM, 2024
Jingwei Xu, Chenyu Wang, Zibo Zhao, Wen Liu, Yi Ma, and Shenghua Gao. CAD-MLLM: Unifying Multimodality- Conditioned CAD Generation With MLLM, 2024. 1, 2, 3, 5, 11
2024
-
[42]
Xiang Xu, Karl D. D. Willis, Joseph G. Lambourne, Chin-Yi Cheng, Pradeep Kumar Jayaraman, and Yasutaka Furukawa. SkexGen: Autoregressive Generation of CAD Construction Sequences with Disentangled Codebooks. InProceedings of the 39th International Conference on Machine Learning, pages 24698–24724. PMLR, 2022. 2
2022
-
[43]
Xiang Xu, Pradeep Kumar Jayaraman, Joseph George Lam- bourne, Karl D. D. Willis, and Yasutaka Furukawa. Hierarchi- cal Neural Coding for Controllable CAD Model Generation. InProceedings of the 40th International Conference on Ma- chine Learning, pages 38443–38461. PMLR, 2023. 2
2023
-
[44]
Brep- Gen: A B-rep Generative Diffusion Model with Structured Latent Geometry.ACM Trans
Xiang Xu, Joseph Lambourne, Pradeep Jayaraman, Zhengqing Wang, Karl Willis, and Yasutaka Furukawa. Brep- Gen: A B-rep Generative Diffusion Model with Structured Latent Geometry.ACM Trans. Graph., 43(4):119:1–119:14,
-
[45]
Qwen3 Technical Report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[46]
Img2CAD: Reverse Engi- neering 3D CAD Models from Images through VLM-Assisted Conditional Factorization, 2025
Yang You, Mikaela Angelina Uy, Jiaqi Han, Rahul Thomas, Haotong Zhang, Yi Du, Hansheng Chen, Francis Engelmann, Suya You, and Leonidas Guibas. Img2CAD: Reverse Engi- neering 3D CAD Models from Images through VLM-Assisted Conditional Factorization, 2025. 2
2025
-
[47]
Igor Zacharov, Rinat Arslanov, Maksim Gunin, Daniil Ste- fonishin, Andrey Bykov, Sergey Pavlov, Oleg Panarin, Anton Maliutin, Sergey Rykovanov, and Maxim Fedorov. “Zhores” — Petaflops supercomputer for data-driven modeling, machine learning and artificial intelligence installed in Skolkovo In- stitute of Science and Technology.Open Engineering, 9(1): 512–...
2019
-
[48]
Thingi10K: A Dataset of 10,000 3D-Printing Models, 2016
Qingnan Zhou and Alec Jacobson. Thingi10K: A Dataset of 10,000 3D-Printing Models, 2016. 3
2016
-
[49]
CADParser: A learning approach of sequence modeling for b-rep CAD
Shengdi Zhou, Tianyi Tang, and Bin Zhou. CADParser: A learning approach of sequence modeling for b-rep CAD. In Proceedings of the Thirty-Second International Joint Confer- ence on Artificial Intelligence, IJCAI-23, pages 1804–1812. International Joint Conferences on Artificial Intelligence Or- ganization, 2023. 7, 11 22
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.