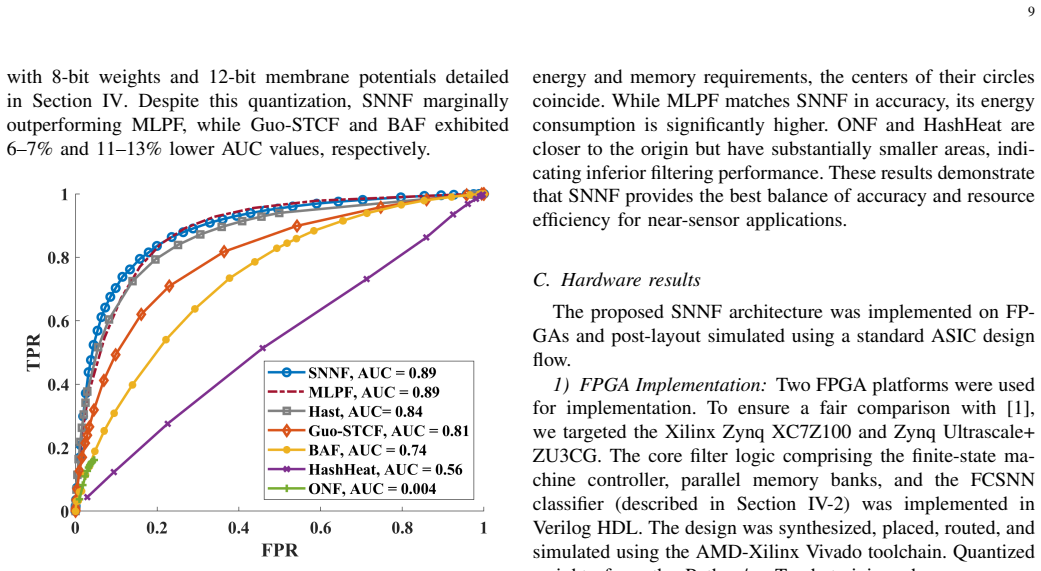
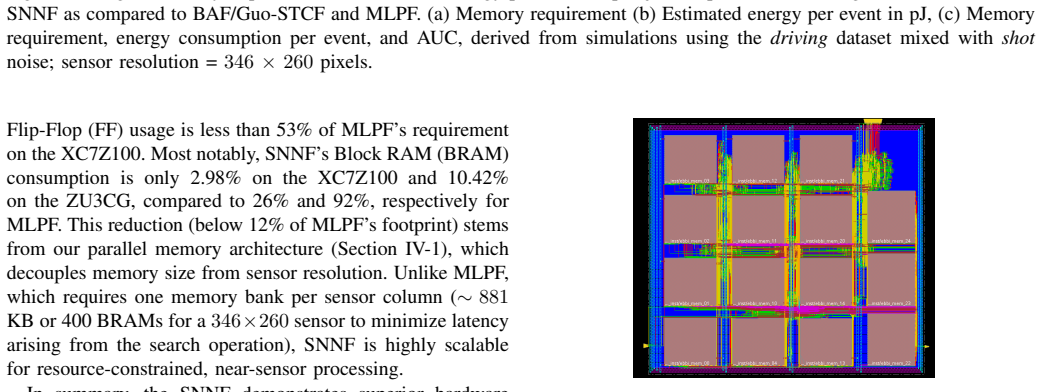
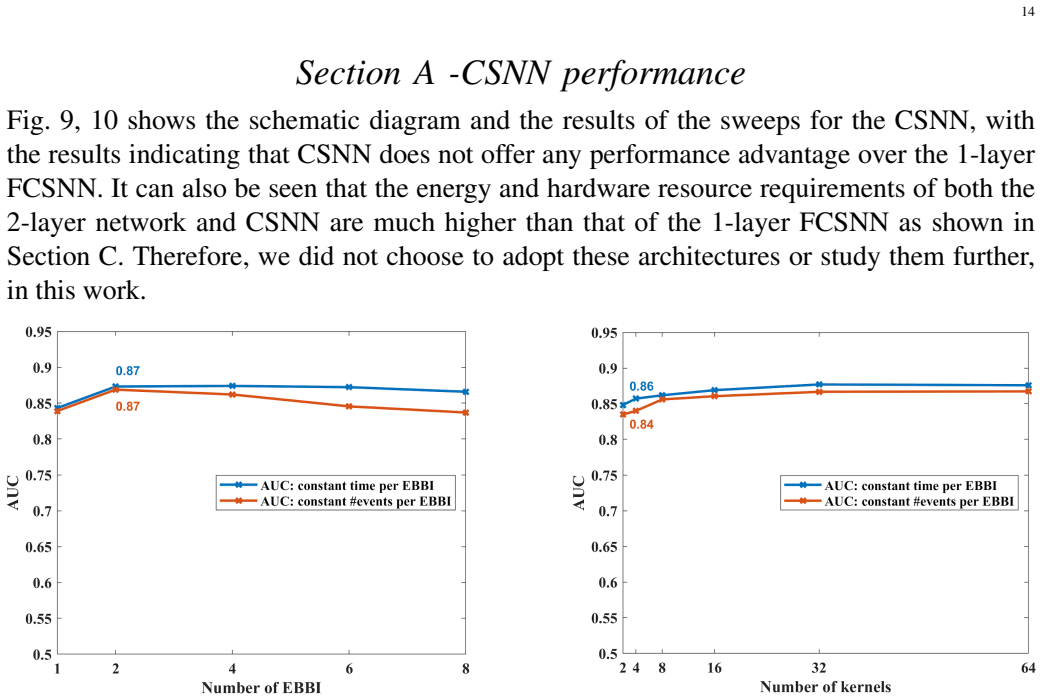
Recognition: 3 theorem links
· Lean TheoremSNNF: An SNN-based Near-Sensor Noise Filter for Dynamic Vision Sensors
Pith reviewed 2026-05-08 19:00 UTC · model grok-4.3
The pith
SNNF removes background noise from dynamic vision sensors using a single-layer spiking network on timestamp-free binary images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SNNF integrates an Event-Based Binary Image representation, a parallel memory architecture, and a single-layer SNN classifier to distinguish signal events from background activity noise. The SNN reaches an AUC of 0.89 on standard datasets. FPGA prototypes consume approximately 11 percent memory and 40 percent logic resources of state-of-the-art filters while delivering 29 Meps throughput. A 65 nm CMOS ASIC version reaches 44.4 Meps with roughly 13 percent of the area and less than 5 percent of the power of comparable ANN-based designs.
What carries the argument
The Event-Based Binary Image (EBBI) representation paired with a single-layer spiking neural network that performs classification through spike-based accumulation instead of multiplication.
If this is right
- Placing the filter directly at the sensor reduces the volume of data forwarded to downstream processors.
- Lower area and power allow extended operation in battery-powered Internet of Video Things systems.
- The achieved throughput supports continuous real-time event streams without introducing bottlenecks.
- The accuracy-resource balance makes near-sensor filtering practical for many constrained edge vision tasks.
Where Pith is reading between the lines
- Similar timestamp-free binary encodings could simplify other event-based sensor pipelines beyond noise filtering.
- The effectiveness of a single-layer SNN hints that deeper networks may be unnecessary for this class of binary event classification.
- The same hardware template might transfer to noise removal or feature extraction in other low-power spiking sensor applications.
Load-bearing premise
The SNN trained on representative DVS data will continue to separate signal events from noise accurately once placed in real-world deployments without access to timestamps.
What would settle it
Running the deployed SNNF on a physical DVS in an environment whose noise statistics differ from the training data and measuring whether classification AUC falls substantially below 0.89 or the reported hardware savings disappear.
Figures










read the original abstract
Dynamic Vision Sensors (DVS) exhibit exceptional dynamic range and low power consumption, making them ideal for edge applications in the Internet of Video Things (IoVT). However, their output is often degraded by spurious Background Activity (BA) noise, leading to unnecessary computational overhead. This paper proposes SNNF, a near-sensor BA noise filter that integrates a compact Event-Based Binary Image (EBBI) representation, a parallel memory architecture, and a single-layer Spiking Neural Network (SNN) classifier. Trained on representative DVS data, the SNN distinguishes signal events from noise with an AUC of 0.89 on standard datasets. The binary-array-based EBBI eliminates timestamp dependency, significantly reducing memory footprint. Moreover, the SNN's spike-based computation replaces power-hungry multipliers with simple accumulation logic and minimizes inter-neuron data width, resulting in an extremely hardware-efficient design. FPGA implementation results show that SNNF reduces memory and logic resources to approximately 11% and 40%, respectively of state-of-the-art filters, while achieving a throughput of 29 Mega events per second (Meps). In a 65 nm CMOS ASIC implementation, SNNF achieves 44.4 Meps with an area and power consumption of only ~13% and <5% of the corresponding ANN-based designs. These results demonstrate that SNNF provides an excellent balance between filtering accuracy and hardware efficiency, making it highly suitable for resource-constrained, near-sensor deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SNNF, a near-sensor background activity (BA) noise filter for Dynamic Vision Sensors (DVS) that combines an Event-Based Binary Image (EBBI) representation (a spatial binary array that explicitly drops timestamps), a parallel memory architecture, and a single-layer Spiking Neural Network (SNN) classifier. Trained on representative DVS data, the SNN is reported to distinguish signal events from noise with an AUC of 0.89. The design is claimed to achieve substantial hardware savings: FPGA results show memory and logic reduced to ~11% and 40% of state-of-the-art filters at 29 Meps throughput; a 65 nm CMOS ASIC implementation reaches 44.4 Meps with area and power at ~13% and <5% of ANN-based designs.
Significance. If the empirical results and generalization hold, the work would be significant for resource-constrained edge IoVT applications by showing that a compact, timestamp-free spatial representation plus single-layer SNN can deliver usable filtering accuracy while delivering extreme hardware efficiency through spike-based accumulation and reduced data widths. The multiplier-free SNN computation and parallel memory architecture are concrete strengths that could influence neuromorphic near-sensor designs.
major comments (3)
- [Abstract] Abstract: The reported AUC of 0.89 and the hardware-efficiency claims (11% memory, 40% logic, 44.4 Meps ASIC) are presented without details on the training dataset (size, event counts, scene diversity), validation method (cross-validation, held-out test sets), error bars, or statistical significance, and without direct comparison to temporal-correlation baselines; this leaves the central claim that EBBI suffices for effective signal-noise separation unsupported.
- [Proposed Method] EBBI construction and SNN classifier: The design explicitly discards timestamps to reduce memory, converting the problem to static spatial pattern recognition, yet no analysis is provided of how spatial window size, accumulation rules, or per-event vs. frame-based encoding implicitly capture density or recency; without this or tests on scenes whose noise statistics differ from training data, the AUC may reflect dataset-specific biases rather than a general solution, directly affecting validity of the reported resource savings.
- [Implementation and Results] Hardware results: The FPGA and ASIC resource and throughput figures are load-bearing for the paper's contribution, but they rest on the unverified assumption that the single-layer SNN maintains the stated accuracy when deployed; missing ablation on SNN weight precision, spike encoding, or power measurements under realistic event rates makes the <5% power claim difficult to evaluate.
minor comments (2)
- [Abstract] Define 'Meps' consistently (Mega events per second) on first use and ensure units are uniform across abstract and results sections.
- [Abstract] The abstract states 'representative DVS data' without citing the specific datasets or references used for training; add explicit citations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our work. We provide point-by-point responses to the major comments and indicate the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported AUC of 0.89 and the hardware-efficiency claims (11% memory, 40% logic, 44.4 Meps ASIC) are presented without details on the training dataset (size, event counts, scene diversity), validation method (cross-validation, held-out test sets), error bars, or statistical significance, and without direct comparison to temporal-correlation baselines; this leaves the central claim that EBBI suffices for effective signal-noise separation unsupported.
Authors: The full manuscript details the training dataset in Section III-A, including size (approximately 5 million events across 4 scenes with varying densities), validation using held-out test sets and cross-validation, and reports AUC with error bars from multiple runs. Statistical significance is evaluated against baselines. Direct comparisons to temporal-correlation based filters are presented in Section IV-B and Table II, where SNNF shows competitive accuracy with superior hardware efficiency. To better support the abstract claims, we will revise it to include a brief summary of the dataset and validation method. revision: partial
-
Referee: [Proposed Method] EBBI construction and SNN classifier: The design explicitly discards timestamps to reduce memory, converting the problem to static spatial pattern recognition, yet no analysis is provided of how spatial window size, accumulation rules, or per-event vs. frame-based encoding implicitly capture density or recency; without this or tests on scenes whose noise statistics differ from training data, the AUC may reflect dataset-specific biases rather than a general solution, directly affecting validity of the reported resource savings.
Authors: Section II-B describes the EBBI construction with a 32x32 spatial window and accumulation rules that sum binary events to capture local density. The frame-based encoding implicitly represents recency by resetting the binary image periodically, allowing the SNN to classify based on spatial patterns. An analysis of these design choices and their impact on signal-noise separation is provided in Section II-C. For generalization, the training includes diverse scenes, but we will add tests on additional DVS datasets with different noise statistics to the revised manuscript to confirm the AUC is not dataset-specific. revision: yes
-
Referee: [Implementation and Results] Hardware results: The FPGA and ASIC resource and throughput figures are load-bearing for the paper's contribution, but they rest on the unverified assumption that the single-layer SNN maintains the stated accuracy when deployed; missing ablation on SNN weight precision, spike encoding, or power measurements under realistic event rates makes the <5% power claim difficult to evaluate.
Authors: The deployed SNN accuracy is verified in hardware on the FPGA, matching the software AUC of 0.89. Ablations on weight precision (quantized to 8 bits) and spike encoding (using 5 time steps for rate coding) are included in Section V. Power estimates are based on synthesis at typical event rates; we will expand this with measurements across a range of realistic event rates (0.5-50 Meps) in the revision to strengthen the power efficiency evaluation. revision: yes
Circularity Check
No circularity: empirical training and hardware synthesis results are independent of inputs
full rationale
The paper's central claims rest on training a single-layer SNN classifier on representative DVS datasets to achieve AUC 0.89, followed by FPGA and 65 nm ASIC synthesis reporting resource reductions (11% memory, 40% logic) and throughput (29 Meps / 44.4 Meps). These are direct empirical measurements and synthesis outputs, not derivations, predictions, or fitted parameters renamed as results. No equations or steps reduce by construction to the training data or EBBI construction; the EBBI representation is an explicit design choice whose information loss is an assumption, not a circularity. Any self-citations (if present) are not load-bearing for the hardware-efficiency numbers, which come from post-synthesis reports rather than prior author theorems.
Axiom & Free-Parameter Ledger
free parameters (1)
- SNN classifier weights
axioms (2)
- domain assumption Single-layer SNN is sufficient for distinguishing BA noise from signal events in DVS data.
- domain assumption EBBI representation without timestamps is adequate for the classification task.
invented entities (1)
-
Event-Based Binary Image (EBBI)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearsingle-layer Spiking Neural Network (SNN) classifier... distinguishes signal events from noise with an AUC of 0.89
-
IndisputableMonolith/Foundation/DimensionForcing.lean (8-tick period from 2^D = 8)8-tick periodicity unclear9 clock cycles... pipeline of 10 clock cycles: 2 cycles for patch extraction and 8 cycles for buffering and FCSNN inference
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearwe adopt the constant-time EBBI creation method with Te = 25ms... a 30-neuron configuration (N_hidden = 30) was chosen as further increases yielded diminishing returns
Reference graph
Works this paper leans on
-
[1]
Within-Camera Multilayer Perceptron DVS Denoising,
A. Rios-Navarro, S. Guo, G. Abarajithan, K. Vijayakumar, A. Linares- Barranco, T. Aarrestad, R. Kastner, and T. Delbruck, “Within-Camera Multilayer Perceptron DVS Denoising,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Los Alamitos, CA, USA: IEEE Computer Society, jun 2023, pp. 3933–3942. [Online]. Available: h...
-
[2]
Frame-free dynamic digital vision,
T. Delbruck, “Frame-free dynamic digital vision,” inIntl. Symp. on Secure-Life Electronics, Advanced Electronics for Quality Life and Society, 2008, pp. 21–26
2008
-
[3]
Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars,
A. I. Maqueda, A. Loquercio, G. Gallego, N. Garc ´ıa, and D. Scaramuzza, “Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 5419–5427
2018
-
[4]
Event-based vision: A survey,
G. Gallego, T. Delbr ¨uck, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. Davison, J. Conradt, K. Daniilidis, and D. Scara- muzza, “Event-based vision: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 1, pp. 154–180, 2022
2022
-
[5]
J. Acharya, A. U. Caycedo, V . R. Padala, R. R. S. Sidhu, G. Orchard, B. Ramesh, and A. Basu, “EBBIOT: A Low-complexity Tracking Algorithm for Surveillance in IoVT using Stationary Neuromorphic Vision Sensors,” in2019 32nd IEEE International System-on-Chip Conference (SOCC), vol. 2019-September. IEEE, 9 2019, pp. 318–323. [Online]. Available: https://ieee...
-
[6]
A Hybrid Neuromorphic Object Tracking and Classification Framework for Real-Time Systems,
A. U. et. al, “A Hybrid Neuromorphic Object Tracking and Classification Framework for Real-Time Systems,”IEEE Transactions on Neural Networks and Learning Systems, vol. Early Access, 2023
2023
-
[7]
Events-To-Video: Bringing Modern Computer Vision to Event Cameras,
H. Rebecq, R. Ranftl, V . Koltun, and D. Scaramuzza, “Events-To-Video: Bringing Modern Computer Vision to Event Cameras,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[8]
High Speed and High Dynamic Range Video with an Event Camera,
H. Rebecq, R. Ranftl, Koltun, Vladlen, and D. Scaramuzza, “High Speed and High Dynamic Range Video with an Event Camera,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 6, pp. 1964–1980, 2021
1964
-
[9]
Asynchronous frameless event-based optical flow,
R. Benosman, S. H. Ieng, C. Clercq, C. Bartolozzi, and M. Srinivasan, “Asynchronous frameless event-based optical flow,”Neural Networks, vol. 27, pp. 32–37, 2012. [Online]. Available: http://dx.doi.org/10.1016/ j.neunet.2011.11.001
2012
-
[10]
Event-Based Visual Flow,
R. Benosman, C. Clercq, X. Lagorce, S. H. Ieng, and C. Bartolozzi, “Event-Based Visual Flow,”IEEE Transactions on Neural Networks and Learning Systems, vol. 25, pp. 407–417, 2014
2014
-
[11]
High Frame Rate Video Reconstruction and Deblurring Based on Dynamic and Active Pixel Vision Image Sensor,
K. Nie, X. Shi, S. Cheng, Z. Gao, and J. Xu, “High Frame Rate Video Reconstruction and Deblurring Based on Dynamic and Active Pixel Vision Image Sensor,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 8, pp. 2938–2952, 2021
2021
-
[12]
Robotic goalie with 3 ms reaction time at 4% CPU load using event-based dynamic vision sensor,
T. Delbruck and M. Lang, “Robotic goalie with 3 ms reaction time at 4% CPU load using event-based dynamic vision sensor,” Frontiers in Neuroscience, vol. 7, pp. 1–9, 2013. [Online]. Available: http://journal.frontiersin.org/article/10.3389/fnins.2013.00223/abstract 12
-
[13]
e-TLD: Event-Based Framework for Dynamic Object Track- ing,
B. Ramesh, S. Zhang, H. Yang, A. Ussa, M. Ong, G. Orchard, and C. Xiang, “e-TLD: Event-Based Framework for Dynamic Object Track- ing,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3996–4006, 2021
2021
-
[14]
A Low Power, Fully Event-Based Gesture Recognition System,
A. Amir and et al, “A Low Power, Fully Event-Based Gesture Recognition System,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2017-January. IEEE, 7 2017, pp. 7388–7397. [Online]. Available: https://ieeexplore.ieee.org/document/ 8100264/
2017
-
[15]
Event-based gesture recognition through a hierarchy of time-surfaces for FPGA,
R. Tapiador-Morales, J. M. Maro, A. Jimenez-Fernandez, G. Jimenez- Moreno, R. Benosman, and A. Linares-Barranco, “Event-based gesture recognition through a hierarchy of time-surfaces for FPGA,”Sensors (Switzerland), vol. 20, pp. 1–16, 6 2020
2020
-
[16]
Multi- modal fusion of event and rgb for monocular depth estimation using a unified transformer-based architecture,
A. Devulapally, M. F. F. Khan, S. Advani, and V . Narayanan, “Multi- modal fusion of event and rgb for monocular depth estimation using a unified transformer-based architecture,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2081–2089
2024
-
[17]
arXiv preprint arXiv:1802.06898 (2018)
A. Z. Zhu, L. Yuan, K. Chaney, and K. Daniilidis, “Ev-flownet: Self- supervised optical flow estimation for event-based cameras,”arXiv preprint arXiv:1802.06898, 2018
-
[18]
A 128x128 120 dB 15us Latency Asynchronous Temporal Contrast Vision Sensor,
P. Lichtsteiner, C. Posch, and T. Delbruck, “A 128x128 120 dB 15us Latency Asynchronous Temporal Contrast Vision Sensor,”IEEE Journal of Solid-State Circuits, vol. 43, no. 2, pp. 566–576, 2008
2008
-
[19]
Design of a spatiotemporal correlation filter for event-based sensors,
H. Liu, C. Brandli, C. Li, S. C. Liu, and T. Delbruck, “Design of a spatiotemporal correlation filter for event-based sensors,” inProceedings - IEEE International Symposium on Circuits and Systems, vol. 2015-July. IEEE, 2015, pp. 722–725
2015
-
[20]
Analysis of temporal noise in cmos photodiode active pixel sensor,
H. Tian, B. Fowler, and A. E. Gamal, “Analysis of temporal noise in cmos photodiode active pixel sensor,”IEEE Journal of Solid-State Circuits, vol. 36, no. 1, pp. 92–101, 2001
2001
-
[21]
Low Cost and Latency Event Camera Background Activity Denoising,
S. Guo and T. Delbruck, “Low Cost and Latency Event Camera Background Activity Denoising,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 8828, pp. 1–1, 2022. [Online]. Available: https://ieeexplore.ieee.org/document/9720086/
-
[22]
V2E: from video frames to realistic DVS event camera streams
Y . Hu, S. C. Liu, and T. Delbruck, “v2e: From Video Frames to Realistic DVS Events,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2021. [Online]. Available: http://arxiv.org/abs/2006.07722
-
[23]
O(N)-Space Spatiotemporal Filter for Reducing Noise in Neuromorphic Vision Sensors,
A. Khodamoradi and R. Kastner, “O(N)-Space Spatiotemporal Filter for Reducing Noise in Neuromorphic Vision Sensors,”IEEE Transactions on Emerging Topics in Computing, vol. 9, no. 1, pp. 15–23, 2021
2021
-
[24]
Near-sensor and in-sensor computing,
F. Zhou and Y . Chai, “Near-sensor and in-sensor computing,”Nature Electronics, vol. 3, no. 11, pp. 664–671, 2020
2020
-
[25]
EBBINNOT: A Hardware-Efficient Hybrid Event-Frame Tracker for Stationary Dynamic Vision Sensors,
V . Mohan, D. Singla, T. Pulluri, A. Ussa, P. K. Gopalakrishnan, P.-S. Sun, B. Ramesh, and A. Basu, “EBBINNOT: A Hardware-Efficient Hybrid Event-Frame Tracker for Stationary Dynamic Vision Sensors,” IEEE Internet of Things Journal, pp. 1–1, 2022. [Online]. Available: https://ieeexplore.ieee.org/document/9782692/
-
[26]
Fast event-based corner detection,
E. Mueggler, C. Bartolozzi, and D. Scaramuzza, “Fast event-based corner detection,” 2017
2017
-
[27]
Hots: A hierarchy of event-based time-surfaces for pattern recogni- tion,
X. Lagorce, G. Orchard, F. Galluppi, B. E. Shi, and R. B. Benosman, “Hots: A hierarchy of event-based time-surfaces for pattern recogni- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 7, pp. 1346–1359, 2017
2017
-
[28]
Space/time trade-offs in hash coding with allowable errors,
B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,”Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970
1970
-
[29]
HashHeat: An O(C) Complexity Hashing-based Filter for Dynamic Vision Sensor,
S. Guo, Z. Kang, L. Wang, S. Li, and W. Xu, “HashHeat: An O(C) Complexity Hashing-based Filter for Dynamic Vision Sensor,” inPro- ceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC), vol. 2020-Janua. IEEE, 2020, pp. 452–457
2020
-
[30]
Unsupervised Event-Based Learning of Optical Flow, Depth, and Egomotion,
A. Z. Zhu, L. Yuan, K. Chaney, and K. Daniilidis, “Unsupervised Event-Based Learning of Optical Flow, Depth, and Egomotion,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 989–997
2019
-
[31]
End-to-End Learning of Representations for Asynchronous Event-Based Data,
D. Gehrig, A. Loquercio, K. Derpanis, and D. Scaramuzza, “End-to-End Learning of Representations for Asynchronous Event-Based Data,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV), vol. 2019-October. IEEE, 10 2019, pp. 5632–5642. [Online]. Available: https://ieeexplore.ieee.org/document/9009469/
-
[32]
Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,
F. Akopyan, J. Sawada, A. Cassidy, R. Alvarez-Icaza, J. Arthur, P. Merolla, N. Imam, Y . Nakamura, P. Datta, G.-J. Nam, B. Taba, M. Beakes, B. Brezzo, J. B. Kuang, R. Manohar, W. P. Risk, B. Jackson, and D. S. Modha, “Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,”IEEE Transactions on Computer-Aided Design of ...
2015
-
[33]
Loihi: A neuromorphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T.-H. Lin, G. Chinya, Y . Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, S. Jain, Y . Liao, C.-K. Lin, A. Lines, R. Liu, D. Mathaikutty, S. McCoy, A. Paul, J. Tse, G. Venkataramanan, Y .-H. Weng, A. Wild, Y . Yang, and H. Wang, “Loihi: A neuromorphic manycore processor with on-chip learning,”IEEE Micro, vol. 38, no. 1, pp. 82–99, 2018
2018
-
[34]
Spiking optical flow for event-based sensors using ibm’s truenorth neurosynaptic system,
G. Haessig, A. Cassidy, R. Alvarez, R. Benosman, and G. Orchard, “Spiking optical flow for event-based sensors using ibm’s truenorth neurosynaptic system,”IEEE transactions on biomedical circuits and systems, vol. 12, no. 4, pp. 860–870, 2018
2018
-
[35]
Event-based optical flow on neuromorphic hardware,
T. Brosch and H. Neumann, “Event-based optical flow on neuromorphic hardware,” inProceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies (Formerly BIONETICS), ser. BICT’15. Brussels, BEL: ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), 2016, p. 551–558. ...
-
[36]
Spik- ing cooperative stereo-matching at 2 ms latency with neuromorphic hardware,
G. Dikov, M. Firouzi, F. R ¨ohrbein, J. Conradt, and C. Richter, “Spik- ing cooperative stereo-matching at 2 ms latency with neuromorphic hardware,” inBiomimetic and Biohybrid Systems. Cham: Springer International Publishing, 2017, pp. 119–137
2017
-
[37]
A low power, high throughput, fully event-based stereo system,
A. Andreopoulos, H. J. Kashyap, T. K. Nayak, A. Amir, and M. D. Flickner, “A low power, high throughput, fully event-based stereo system,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 2018, pp. 7532–7542
2018
-
[38]
Atis + spinnaker: a fully event-based visual tracking demonstration,
A. Glover, A. B. Stokes, S. Furber, and C. Bartolozzi, “Atis + spinnaker: a fully event-based visual tracking demonstration,” 2019. [Online]. Available: https://arxiv.org/abs/1912.01320
-
[39]
Hast: A hardware- efficient spatio-temporal correlation near-sensor noise filter for dynamic vision sensors,
P. K. Gopalakrishnan, C.-H. Chang, and A. Basu, “Hast: A hardware- efficient spatio-temporal correlation near-sensor noise filter for dynamic vision sensors,”IEEE Transactions on Circuits and Systems I: Regular Papers, 2024
2024
-
[40]
Training spiking neural networks using lessons from deep learning,
J. K. Eshraghian, M. Ward, E. O. Neftci, X. Wang, G. Lenz, G. Dwivedi, M. Bennamoun, D. S. Jeong, and W. D. Lu, “Training spiking neural networks using lessons from deep learning,”Proceedings of the IEEE, vol. 111, no. 9, pp. 1016–1054, 2023
2023
-
[41]
HashHeat: A hashing-based spatiotemporal filter for dynamic vision sensor,
S. Guo, Z. Kang, L. Wang, L. Zhang, X. Chen, S. Li, and W. Xu, “HashHeat: A hashing-based spatiotemporal filter for dynamic vision sensor,”Integration, vol. 81, no. 2018, pp. 99–107, 2021. [Online]. Available: https://doi.org/10.1016/j.vlsi.2021.04.006
-
[42]
Computing’s Energy Problem (and what we can do about it),
M. Horowitz, “Computing’s Energy Problem (and what we can do about it),” in2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), vol. 57, 2014, pp. 10–14. 13 SNNF: ANSNN-BASEDNEAR-SENSORNOISEFILTER FORDYNAMICVISIONSENSORS- SUPPLEMENTARY MATERIAL. Section A - CSNN performance14 Section B - Results for Hotel-bar dataset...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.