Recognition: unknown
Cross-Layer Energy Analysis of Multimodal Training on Grace Hopper Superchips
Pith reviewed 2026-05-09 15:55 UTC · model grok-4.3
The pith
Energy efficiency in multimodal training on GH200 superchips depends primarily on data movement and overlap rather than raw compute utilization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Leveraging the high-bandwidth CPU-GPU interconnects and unified memory of the GH200, the cross-layer measurements establish that energy efficiency is governed by data movement patterns and operation overlap rather than by raw compute utilization, and that runtime-optimized configurations are not necessarily energy-optimal.
What carries the argument
Cross-layer characterization of interactions among application-level offloading, runtime parallelism, and hardware interconnect bandwidth on GH200 superchips.
If this is right
- Offloading strategies and sequence parallelism become viable on GH200 because the interconnect reduces transfer costs enough to improve the energy balance.
- Hardware-aware scheduling that overlaps data movement with computation yields better energy results than pure runtime minimization.
- Practitioners can trade modest increases in runtime for lower total energy by adjusting CPU offload fractions and parallelism degrees.
- The same high-bandwidth interconnects allow simultaneous gains in throughput, energy efficiency, and training speed when the three are tuned together.
- Guidelines derived from the measurements give reproducible starting points for balancing the three objectives on similar heterogeneous platforms.
Where Pith is reading between the lines
- The same measurement approach could be applied to other high-bandwidth CPU-GPU pairings to test whether data-movement dominance generalizes beyond GH200.
- Training frameworks could expose an energy-aware mode that automatically searches for overlap-maximizing schedules instead of defaulting to runtime-only optimization.
- For inference workloads the relative weight of data movement versus compute might shift, suggesting a follow-up study on deployment energy.
- Hardware designers might use these energy breakdowns to prioritize even higher interconnect bandwidth or larger unified memory pools in next-generation superchips.
Load-bearing premise
The chosen training configurations and direct energy measurements on GH200 capture the main cross-layer effects without large unmeasured overheads from profiling or data offloading.
What would settle it
Repeating the multimodal training runs on identical GH200 hardware while varying offload ratios and parallelism and finding that energy consumption tracks compute utilization more closely than data-movement volume or overlap would contradict the central claim.
Figures



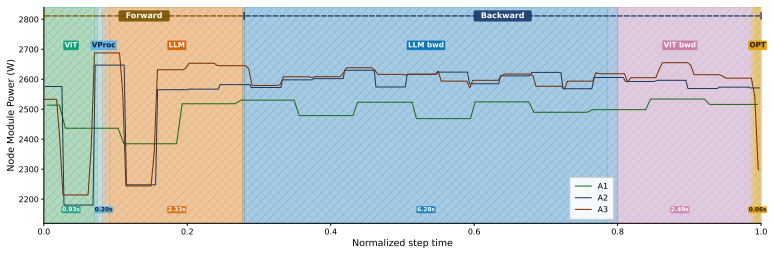





read the original abstract
Multimodal deep learning models enable joint learning across heterogeneous data sources, including text, images, and video, but their rapid scaling introduces significant memory and communication bottlenecks. As model sizes and sequence lengths increase, training performance becomes increasingly impacted by data movement rather than computation. Frameworks such as DeepSpeed mitigate these challenges through CPU offloading, activation checkpointing, and communication optimizations. However, these techniques introduce additional system activity, which may affect energy efficiency. Meanwhile, tightly integrated heterogeneous architectures, such as the NVIDIA Grace Hopper (GH200) superchip, provide high-bandwidth CPU-GPU interconnects and unified memory, thereby reducing data transfer overhead. In this work, we present a cross-layer analysis of energy and performance trade-offs in multimodal training on GH200 systems, explicitly characterizing the interactions between application, runtime, and hardware layers. Leveraging high-bandwidth CPU-GPU interconnects, our results show that energy efficiency is primarily governed by data movement and overlap rather than raw compute utilization, and that configurations optimized for runtime are not necessarily optimal for energy. Based on these findings, we distill a set of actionable guidelines for practitioners that demonstrate how to balance offloading strategies, sequence parallelism, and hardware-aware scheduling to achieve energy-efficient training. Our results demonstrate that leveraging high-bandwidth CPU-GPU interconnects enables offloading strategies and sequence parallelism, achieving a strong balance among energy efficiency, runtime performance, and computational throughput, providing practical guidelines for efficient multimodal training on modern heterogeneous systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a cross-layer empirical analysis of energy consumption and performance trade-offs during multimodal deep learning training on NVIDIA Grace Hopper (GH200) superchips. It examines interactions across application techniques (CPU offloading, activation checkpointing, sequence parallelism), runtime frameworks such as DeepSpeed, and hardware features including high-bandwidth CPU-GPU interconnects and unified memory. The central claims are that energy efficiency is governed primarily by data movement and computation overlap rather than raw compute utilization, and that runtime-optimal configurations are not necessarily energy-optimal; the authors distill these into practical guidelines for balancing offloading strategies and hardware-aware scheduling.
Significance. If the energy measurements prove robust, the work is significant for sustainable AI systems research. It provides hardware-specific, actionable insights for energy-efficient training of large multimodal models on heterogeneous architectures, an area of growing importance given scaling trends. The emphasis on cross-layer effects and practitioner guidelines adds practical value beyond pure performance studies.
major comments (2)
- [§4] §4 (Experimental Methodology): The manuscript does not quantify or validate the overhead introduced by energy profiling mechanisms (e.g., nvidia-smi, DCGM, or equivalent CPU/GPU counters) or offloading instrumentation. Without explicit overhead measurements or cross-checks against external wall-power meters, it is impossible to confirm that observed energy differences across configurations are attributable to data movement and overlap rather than measurement artifacts. This directly undermines the load-bearing claim that energy efficiency is 'primarily governed by data movement and overlap rather than raw compute utilization.'
- [§5] §5 (Results and Analysis): The reported trade-offs between runtime-optimal and energy-optimal points lack baseline comparisons to unoptimized or standard DeepSpeed configurations, error bars on energy readings, or statistical tests for significance. This weakens the assertion that runtime-optimized setups are 'not necessarily optimal for energy' and the derived guidelines, as the magnitude and reliability of the differences cannot be assessed.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicitly naming the multimodal model architectures, parameter counts, and sequence lengths used in the experiments to allow reproducibility assessment.
- [§3] Notation for energy metrics (e.g., energy per token or per iteration) should be defined consistently in §3 before use in figures and guidelines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has identified key areas where the manuscript can be strengthened. We address each major comment below and describe the revisions we will make to improve the rigor of our experimental claims.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Methodology): The manuscript does not quantify or validate the overhead introduced by energy profiling mechanisms (e.g., nvidia-smi, DCGM, or equivalent CPU/GPU counters) or offloading instrumentation. Without explicit overhead measurements or cross-checks against external wall-power meters, it is impossible to confirm that observed energy differences across configurations are attributable to data movement and overlap rather than measurement artifacts. This directly undermines the load-bearing claim that energy efficiency is 'primarily governed by data movement and overlap rather than raw compute utilization.'
Authors: We agree that explicit quantification of profiling overhead is important for validating the central claim. Although the original experiments used consistent instrumentation across all runs (ensuring relative differences remain meaningful), we did not report isolated overhead measurements or external meter cross-checks. In the revised manuscript we will add dedicated micro-benchmarks that isolate the overhead of nvidia-smi, DCGM, and our offloading instrumentation, together with a comparison against wall-power meter readings on a subset of configurations. These additions will directly confirm that the observed energy variations arise from data-movement and overlap effects rather than measurement artifacts. revision: yes
-
Referee: [§5] §5 (Results and Analysis): The reported trade-offs between runtime-optimal and energy-optimal points lack baseline comparisons to unoptimized or standard DeepSpeed configurations, error bars on energy readings, or statistical tests for significance. This weakens the assertion that runtime-optimized setups are 'not necessarily optimal for energy' and the derived guidelines, as the magnitude and reliability of the differences cannot be assessed.
Authors: The referee is correct that the submitted version omitted explicit baseline runs against unmodified DeepSpeed, error bars, and statistical tests. While our configuration sweeps already included standard DeepSpeed settings as reference points, these were not highlighted as such. In the revision we will (1) add clear baseline comparisons to unoptimized DeepSpeed, (2) report error bars derived from repeated runs, and (3) include appropriate statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for the runtime-versus-energy differences. These changes will allow readers to assess both the magnitude and reliability of the trade-offs that support our guidelines. revision: yes
Circularity Check
No circularity: empirical measurement study with independent hardware data
full rationale
The paper reports cross-layer energy and performance measurements from multimodal training runs on GH200 superchips. No mathematical derivation, fitted parameters, or predictive equations are present. Claims rest on direct instrumentation of runtime, energy, and data-movement metrics rather than any self-referential reduction or self-citation chain. The central finding (energy governed by data movement/overlap) is an empirical observation from the collected traces, not a quantity defined or forced by the analysis itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large-scale multi-modal pre-trained models: A comprehensive survey,
X. Wang, G. Chen, G. Qian, P. Gao, X.-Y . Wei, Y . Wang, Y . Tian, and W. Gao, “Large-scale multi-modal pre-trained models: A comprehensive survey,”Machine Intelligence Research, vol. 20, no. 4, pp. 447–482,
-
[2]
Available: https://doi.org/10.1007/s11633-022-1410-8
[Online]. Available: https://doi.org/10.1007/s11633-022-1410-8
-
[3]
MM-LLMs: Recent advances in MultiModal large language models,
D. Zhang, Y . Yu, J. Dong, C. Li, D. Su, C. Chu, and D. Yu, “MM-LLMs: Recent advances in MultiModal large language models,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 12 401–12 430. [Online]. Available: http...
-
[4]
A review of multi-modal large language and vision models,
K. Carolan, L. Fennelly, and A. F. Smeaton, “A review of multi-modal large language and vision models,”arXiv preprint arXiv:2404.01322,
-
[5]
A review of multi-modal large language and vision models,
[Online]. Available: https://doi.org/10.48550/arXiv.2404.01322
-
[6]
In: Al- Onaizan, Y., Bansal, M., Chen, Y.N
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video-LLaV A: Learning united visual representation by alignment before projection,” pp. 5971–5984, 2024. [Online]. Available: https://doi.org/10.18653/v1/2024.emnlp-main.342
-
[7]
Video-LLaMA: An instruction-tuned audio-visual language model for video understanding,
H. Zhang, X. Li, and L. Bing, “Video-LLaMA: An instruction-tuned audio-visual language model for video understanding,” inProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, 2023, pp. 543–553. [Online]. Available: https://doi.org/10.18653/v1/2023.emnlp-demo.49
-
[8]
Generalized Slow Roll for Tensors
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “ZeRO: Memory optimizations toward training trillion parameter models,” inSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16. [Online]. Available: https://doi.org/10.1109/sc41405.2020.00024
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2020
-
[9]
S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V . Korthikantiet al., “Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model,”arXiv preprint arXiv:2201.11990, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2201.11990
-
[10]
T. Hielscher and S. Hadigheh, “Optimizing memory-efficient multimodal networks for image classification using differential evolution,”Applied Soft Computing, vol. 171, p. 112714, 2025. [Online]. Available: https://doi.org/10.1016/j.asoc.2025.112714
-
[11]
Q. Cao, S. Abdulah, H. Ltaief, M. G. Genton, D. Keyes, and G. Bosilca, “Reducing data motion and energy consumption of geospatial modeling applications using automated precision conversion,” in2023 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 2023, pp. 330–342. [Online]. Available: https://doi.org/10.1109/CLUSTER52292.2023.00035
-
[12]
Analyzing energy consumption data to optimize efficiency in high-performance computing centers,
P. Dahule, “Analyzing energy consumption data to optimize efficiency in high-performance computing centers,”The Eastasouth Journal of Information System and Computer Science, vol. 1, no. 03, pp. 199–208,
-
[13]
Available: https://doi.org/10.58812/esiscs.v1i03.514
[Online]. Available: https://doi.org/10.58812/esiscs.v1i03.514
-
[14]
The environmental challenge of hpc: finding green power and cooling solutions for supercomputers,
H. Wang, Y . Su, and Y . Guo, “The environmental challenge of hpc: finding green power and cooling solutions for supercomputers,” Advances in Engineering Innovation, vol. 16, no. 6, pp. 21–34, 2025. [Online]. Available: https://doi.org/0.54254/2977-3903/2025.24598
-
[15]
Sustainably modeling a sustainable future climate,
R. Alomairy, S. Abdulah, Q. Cao, M. G. Genton, D. E. Keyes, and H. Ltaief, “Sustainably modeling a sustainable future climate,” in2025 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 2025, pp. 1–8. [Online]. Available: https://doi.org/10.1109/HPEC67600.2025.11196699
-
[16]
R. Muralidhar, R. Borovica-Gajic, and R. Buyya, “Energy efficient computing systems: Architectures, abstractions and modeling to techniques and standards,”ACM Computing Surveys (CSUR), vol. 54, no. 11s, pp. 1–37, 2022. [Online]. Available: https://doi.org/10.1145/3511094
-
[17]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He, “Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 3505–
2020
-
[18]
[Online]. Available: https://doi.org/10.1145/3394486.3406703
-
[19]
S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y . He, “Zero- infinity: Breaking the GPU memory wall for extreme scale deep learning,” inProceedings of the international conference for high performance computing, networking, storage and analysis, 2021, pp. 1–14. [Online]. Available: https://doi.org/10.1145/3458817.3476205
-
[20]
S. A. Jacobs, M. Tanaka, C. Zhang, M. Zhang, S. L. Song, S. Rajbhandari, and Y . He, “Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models,”arXiv preprint arXiv:2309.14509, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.14509
work page internal anchor Pith review doi:10.48550/arxiv.2309.14509 2023
-
[21]
Training Deep Nets with Sublinear Memory Cost
T. Chen, B. Xu, C. Zhang, and C. Guestrin, “Training deep nets with sublinear memory cost,”arXiv preprint arXiv:1604.06174, 2016. [Online]. Available: https://doi.org/10.48550/arXiv.1604.06174
work page internal anchor Pith review doi:10.48550/arxiv.1604.06174 2016
-
[22]
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . A. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia, “Efficient large-scale language model training on gpu clusters using megatron-lm,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and ...
-
[23]
NVIDIA Hopper GPU and Grace CPU highlights,
A. C. Elster and T. A. Haugdahl, “NVIDIA Hopper GPU and Grace CPU highlights,”Computing in Science & Engineering, vol. 24, no. 2, pp. 95–100, 2022. [Online]. Available: https://doi.org/10.1109/MCSE.2022.3163817
-
[24]
Alternative basis matrix multiplication is fast and stable,
W. Luo, R. Fan, Z. Li, D. Du, Q. Wang, and X. Chu, “Benchmarking and dissecting the NVIDIA Hopper GPU architecture,” in2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2024, pp. 656–667. [Online]. Available: https://doi.org/10.1109/IPDPS57955.2024.00064
-
[25]
Harnessing integrated CPU-GPU system memory for HPC: a first look into Grace Hopper,
G. Schieffer, J. Wahlgren, J. Ren, J. Faj, and I. Peng, “Harnessing integrated CPU-GPU system memory for HPC: a first look into Grace Hopper,” inProceedings of the 53rd International Conference on Parallel Processing, 2024, pp. 199–209. [Online]. Available: https://doi.org/10.1145/3673038.3673110
-
[26]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[27]
OpenAI, J. Achiam, S. Adler, S. Agarwal, and Oth- ers, “GPT-4 technical report,” 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2024
-
[28]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, and Others, “An image is worth 16x16 words: Transformers for image recognition at scale,” in International Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=YicbFdNTTy
2021
-
[29]
MiniGPT-v2: Large language model as a unified interface for vision-language multi-task learning,
J. Chen, D. Zhu, X. Shen, X. Li, Z. Liu, P. Zhang, R. Krishnamoorthi, V . Chandra, Y . Xiong, and M. Elhoseiny, “MiniGPT-v2: Large language model as a unified interface for vision-language multi-task learning,” 2024. [Online]. Available: https://openreview.net/forum?id=nKvGCUoiuW
2024
-
[30]
LLaV A-onevision: Easy visual task transfer,
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, and C. Li, “LLaV A-onevision: Easy visual task transfer,”Transactions on Machine Learning Research, 2025. [Online]. Available: https://openreview.net/forum?id=zKv8qULV6n
2025
-
[31]
LLaV A-video: Video instruction tuning with synthetic data,
Y . Zhang, J. Wu, W. Li, B. Li, Z. MA, Z. Liu, and C. Li, “LLaV A-video: Video instruction tuning with synthetic data,” Transactions on Machine Learning Research, 2025. [Online]. Available: https://openreview.net/forum?id=EElFGvt39K
2025
-
[32]
Reformer: The efficient trans- former,
N. Kitaev, L. Kaiser, and A. Levskaya, “Reformer: The efficient trans- former,” inInternational Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=rkgNKkHtvB
2020
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,” 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2409.12191
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12191 2024
-
[34]
GQA: Training generalized multi-query transformer models from multi-head checkpoints,
J. Ainslie, J. Lee-Thorp, M. de Jong, Y . Zemlyanskiy, F. Lebron, and S. Sanghai, “GQA: Training generalized multi-query transformer models from multi-head checkpoints,” inThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. [Online]. Available: https://openreview.net/forum?id=hmOwOZWzYE
2023
-
[35]
Flashattention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “Flashattention-2: Faster attention with better parallelism and work partitioning,” inThe Twelfth International Confer- ence on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=mZn2Xyh9Ec
2024
-
[36]
Qwen2.5 technical report,
A. Yang, B. Yang, B. Zhang, B. Huiet al., “Qwen2.5 technical report,”
-
[37]
[Online]. Available: https://doi.org/10.48550/arXiv.2412.15115
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115
-
[38]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafaet al., “Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.14786
work page internal anchor Pith review doi:10.48550/arxiv.2502.14786 2025
-
[39]
Revisiting multimodal positional encoding in vision–language models,
J. Huang, X. Liu, S. Song, R. Hou, H. Chang, J. Lin, and S. Bai, “Revisiting multimodal positional encoding in vision–language models,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=sCCF4ygDAw
2026
-
[40]
ZeRO-Offload: Democratizing Billion- Scale model training,
J. Ren, S. Rajbhandari, R. Y . Aminabadi, O. Ruwase, S. Yang, M. Zhang, D. Li, and Y . He, “ZeRO-Offload: Democratizing Billion- Scale model training,” in2021 USENIX Annual Technical Conference (USENIX ATC 21). USENIX Association, 2021, pp. 551–564. [Online]. Available: https://www.usenix.org/conference/atc21/presentation/ren-jie
2021
-
[41]
Radshield: Software radiation protection for commodity hardware in space,
X. Lian, M. Tanaka, O. Ruwase, and M. Zhang, “SuperOffload: Unleashing the power of large-scale llm training on superchips,” inProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2026, pp. 249–264. [Online]. Available: https://doi.org/10.1145/3760250.3762217
-
[42]
J. Zhu, P. Feng, J. Lu, B. Fang, and H. Yang, “ZeROf-Offload: Forward-gradient scheme for efficient full parameter fine-tuning of billion-scale language models,”Machine Learning: Science and Technology, vol. 5, no. 4, p. 045054, 2024. [Online]. Available: https://doi.org/10.1088/2632-2153/ad9667
-
[43]
Training ultra long context language model with fully pipelined distributed transformer,
J. Yao, S. A. Jacobs, M. Tanaka, O. Ruwase, H. Subramoni, and D. Panda, “Training ultra long context language model with fully pipelined distributed transformer,” inProceedings of Machine Learning and Systems, M. Zaharia, G. Joshi, and Y . Lin, Eds., vol. 7. MLSys, 2025
2025
-
[44]
TOP500 Supercomputer Sites,
TOP500 Organization, “TOP500 Supercomputer Sites,” https://www.top500.org/, 2026, accessed: 2026-04-06
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.