Recognition: 2 theorem links
· Lean TheoremProtoFair: Fair Self-Supervised Contrastive Learning via Pseudo-Counterfactual Pairs
Pith reviewed 2026-05-08 19:34 UTC · model grok-4.3
The pith
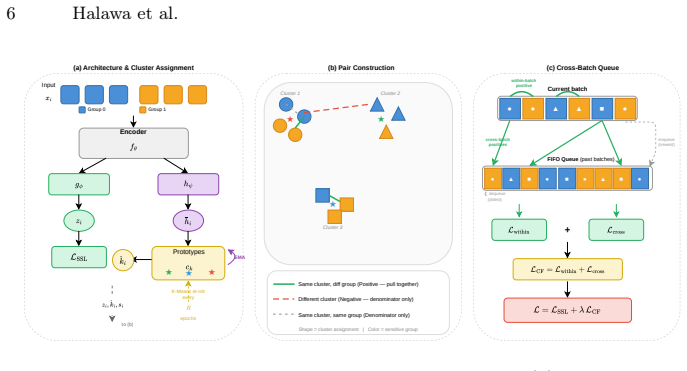
ProtoFair introduces a fairness-aware contrastive loss that uses unsupervised prototype clustering to create pseudo-counterfactual pairs, encouraging representations invariant to sensitive attributes while integrating with standard SSL frameworks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By pulling these content-matched, cross-group samples together in the embedding space, ProtoFair encourages the encoder to learn representations that are invariant to the sensitive attribute.
Load-bearing premise
That unsupervised prototype clustering reliably identifies samples sharing the same content but belonging to different sensitive groups, making the cluster assignments independent of the sensitive attribute.
Figures

read the original abstract
Self-supervised learning methods learn high-quality visual representations, yet recent studies show that these representations often capture demographic biases present in the training data. Existing fairness-aware methods address this by redesigning the self-supervised objective itself, limiting portability across the rapidly evolving landscape of self-supervised learning (SSL) frameworks. We propose ProtoFair, a fairness-aware contrastive loss designed to work alongside existing SSL objectives without modifying them. ProtoFair leverages unsupervised prototype clustering to identify pseudo-counterfactual pairs: samples sharing the same cluster assignment but belonging to different sensitive groups. By pulling these content-matched, cross-group samples together in the embedding space, ProtoFair encourages the encoder to learn representations that are invariant to the sensitive attribute. The method requires only sensitive attribute annotations, no target labels, and integrates seamlessly with both SimCLR and SupCon. Experiments on CelebA and UTKFace demonstrate consistent fairness improvements while maintaining competitive accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ProtoFair, a plug-in fairness-aware contrastive loss for self-supervised learning frameworks. It uses unsupervised prototype clustering to form pseudo-counterfactual pairs (same cluster assignment, different sensitive groups) and adds a loss term that pulls their embeddings together, with the goal of learning representations invariant to the sensitive attribute. The approach requires only sensitive-attribute labels (no target labels), integrates with SimCLR and SupCon without modifying their objectives, and is evaluated on CelebA and UTKFace where it reportedly yields consistent fairness gains alongside competitive accuracy.
Significance. If the pseudo-counterfactual pairs are verifiably content-matched and cross-group, the method would provide a portable fairness module that avoids redesigning core SSL objectives, a practical advantage given the rapid evolution of contrastive and other self-supervised techniques. This could facilitate bias mitigation in vision tasks with demographic data while preserving the benefits of existing SSL pipelines.
major comments (2)
- [§3] §3 (Method): The central claim that unsupervised prototype clustering reliably produces assignments independent of the sensitive attribute is not supported by any analysis or regularization in the manuscript. In face datasets such as CelebA and UTKFace, where demographic cues are visually prominent, the initial SSL representations commonly encode sensitive attributes; without explicit measures (e.g., adversarial decorrelation or post-clustering checks), clusters can align with sensitive groups rather than content, rendering the added loss term ineffective or counterproductive for invariance.
- [§4] §4 (Experiments): The reported fairness improvements on CelebA and UTKFace are presented without ablation on the clustering component, without quantification of cluster-sensitive-attribute correlation, and without statistical significance tests or multiple random seeds for the prototype assignments. This leaves the load-bearing assumption untested and the quantitative claims only weakly grounded.
minor comments (2)
- The abstract and method description would benefit from explicit notation for the prototype update schedule and the precise form of the ProtoFair loss term (e.g., temperature scaling, weighting relative to the base SSL loss).
- Table or figure captions should clarify the exact fairness metrics used (e.g., demographic parity gap, equal opportunity) and the baseline SSL models against which gains are measured.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key assumptions in our method and gaps in experimental validation. We address each point below and will make substantial revisions to strengthen the manuscript, including new analyses and ablations.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that unsupervised prototype clustering reliably produces assignments independent of the sensitive attribute is not supported by any analysis or regularization in the manuscript. In face datasets such as CelebA and UTKFace, where demographic cues are visually prominent, the initial SSL representations commonly encode sensitive attributes; without explicit measures (e.g., adversarial decorrelation or post-clustering checks), clusters can align with sensitive groups rather than content, rendering the added loss term ineffective or counterproductive for invariance.
Authors: We acknowledge that the manuscript provides no explicit analysis or regularization to ensure cluster assignments are independent of the sensitive attribute, and that this is a load-bearing assumption for the pseudo-counterfactual pairs. While ProtoFair does not claim the clustering step itself enforces independence (it relies on the contrastive loss to promote invariance), we agree that without verification, clusters may capture demographic cues in face data. In the revised version, we will add a post-clustering analysis quantifying the correlation between assignments and sensitive attributes (e.g., via normalized mutual information and per-cluster demographic distributions). We will also discuss this as a limitation and explore adding a lightweight decorrelation regularizer if warranted by the results. revision: yes
-
Referee: [§4] §4 (Experiments): The reported fairness improvements on CelebA and UTKFace are presented without ablation on the clustering component, without quantification of cluster-sensitive-attribute correlation, and without statistical significance tests or multiple random seeds for the prototype assignments. This leaves the load-bearing assumption untested and the quantitative claims only weakly grounded.
Authors: We agree that the current experiments lack these critical elements, leaving the clustering assumptions insufficiently tested. In the revision, we will incorporate: (i) ablations on the number of prototypes, clustering algorithm variants, and their impact on fairness/accuracy; (ii) explicit quantification of cluster-sensitive attribute correlation using the metrics noted above; and (iii) results over at least five random seeds for prototype initialization, with statistical significance testing (e.g., paired t-tests and standard deviations) on the fairness metrics. These changes will provide stronger empirical grounding. revision: yes
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unsupervised prototype clustering produces groups whose assignments are independent of the sensitive attribute
invented entities (1)
-
pseudo-counterfactual pairs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: European Conference on Computer Vision (ECCV) (2018) 3
Caron, M., Bojanowski, P., Joulin, A., Douze, M.: Deep clustering for unsupervised learning of visual features. In: European Conference on Computer Vision (ECCV) (2018) 3
2018
-
[2]
In: Advances in Neural Information Processing Systems (NeurIPS) (2020) 3
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., Joulin, A.: Unsuper- vised learning of visual features by contrasting cluster assignments. In: Advances in Neural Information Processing Systems (NeurIPS) (2020) 3
2020
-
[3]
Advances in Neural Information Processing Systems35, 27100–27113 (2022) 4
Chai,J.,Wang,X.:Self-supervisedfairrepresentationlearningwithoutdemograph- ics. Advances in Neural Information Processing Systems35, 27100–27113 (2022) 4
2022
-
[4]
In: Proceedings of the 37th International Conference on Machine Learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: Proceedings of the 37th International Conference on Machine Learning. ICML’20, JMLR.org (2020) 1, 2, 6, 12
2020
-
[5]
CoRRabs/2301.02989(2023),https://arxiv
Chiu, C.H., Chung, H.W., Chen, Y.J., Shi, Y., Ho, T.Y.: Fair multi-exit framework for facial attribute classification. CoRRabs/2301.02989(2023),https://arxiv. org/abs/2301.029894
-
[6]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
D’Incà, M., Tzelepis, C., Patras, I., Sebe, N.: Improving fairness using vision- language driven image augmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 4695–4704 (2024) 4
2024
-
[7]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Do- ersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., Piot, B., Kavukcuoglu, K., Munos, R., Valko, M.: Bootstrap your own latent a new approach to self-supervised learn- ing. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20...
2020
-
[8]
In: Advances in Neural Information Processing Systems
Hardt, M., Price, E., Srebro, N.: Equality of opportunity in supervised learning. In: Advances in Neural Information Processing Systems. vol. 29, pp. 3315–3323 (2016) 2, 4, 10
2016
-
[9]
Momentum contrast for unsupervised visual representation learning
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning (2019),http : / / arxiv . org / abs / 1911.05722, cite arxiv:1911.05722Comment: CVPR 2020 camera-ready. Code: https://github.com/facebookresearch/moco 1, 3
-
[10]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 770–778 (2015),https://api.semanticscholar.org/CorpusID:20659469210
2016
-
[11]
In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–778. IEEE (2016).https://doi.org/10.1109/CVPR.2016.9010, 11
-
[12]
Taming Transformers for High-Resolution Image Synthesis , booktitle =
Jung, S., Lee, D., Park, T., Moon, T.: Fair Feature Distillation for Visual Recognition . In: 2021 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR). pp. 12110–12119. IEEE Computer Society, Los Alami- tos, CA, USA (Jun 2021).https://doi.org/10.1109/CVPR46437.2021.01194, https://doi.ieeecomputersociety.org/10.1109/CVPR46437.2021.0119411
-
[13]
In: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2021) 4
Karkkainen, K., Joo, J.: Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. In: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2021) 4
2021
-
[14]
In: Larochelle, H., 16 Halawa et al
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. In: Larochelle, H., 16 Halawa et al. Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Infor- mation Processing Systems. vol. 33, pp. 18661–18673. Curran Associates, Inc. (2020),https : / / procee...
2020
-
[15]
Kim,B.,Kim,H.,Kim,K.,Kim,S.,Kim,J.: LearningNottoLearn:TrainingDeep Neural Networks With Biased Data . In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9004–9012. IEEE Computer Soci- ety, Los Alamitos, CA, USA (Jun 2019).https://doi.org/10.1109/CVPR.2019. 00922,https://doi.ieeecomputersociety.org/10.1109/CVPR.2019.009221...
-
[16]
In: Ad- vances in Neural Information Processing Systems (NeurIPS) (2017) 2, 5
Kusner, M.J., Loftus, J., Russell, C., Silva, R.: Counterfactual fairness. In: Ad- vances in Neural Information Processing Systems (NeurIPS) (2017) 2, 5
2017
-
[17]
In: International Conference on Learning Representations (ICLR) (2021) 3, 8
Li, J., Zhou, P., Xiong, C., Hoi, S.: Prototypical contrastive learning of unsuper- vised representations. In: International Conference on Learning Representations (ICLR) (2021) 3, 8
2021
-
[18]
In: Proceedings of International Conference on Computer Vision (ICCV) (December
Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: Proceedings of International Conference on Computer Vision (ICCV) (December
-
[19]
Journal of Machine Learning Research9, 2579–2605 (2008) 13
van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of Machine Learning Research9, 2579–2605 (2008) 13
2008
-
[20]
Confidence in Assurance 2.0 Cases
Noroozi, M., Favaro, P.: Unsupervised learning of visual representations by solving jigsaw puzzles. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VI. Lecture Notes in Computer Science, vol. 9910, pp. 69–84. Springer (2016).ht...
-
[21]
Park, S., Hwang, S., Kim, D., Byun, H.: Learning disentangled representation for fair facial attribute classification via fairness-aware information alignment. Pro- ceedings of the AAAI Conference on Artificial Intelligence35(3), 2403–2411 (May 2021).https://doi.org/10.1609/aaai.v35i3.16341,https://ojs.aaai.org/ index.php/AAAI/article/view/163414, 11
-
[22]
Park, S., Lee, J., Lee, P., Hwang, S., Kim, D., Byun, H.: Fair contrastive learning for facial attribute classification. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10379–10388 (2022).https://doi. org/10.1109/CVPR52688.2022.010141, 2, 4, 5, 10, 11, 12
-
[23]
Radford, A., Narasimhan, K.: Improving language understanding by generative pre-training (2018),https://api.semanticscholar.org/CorpusID:4931324514
2018
-
[24]
In: 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA)
Raff, E., Sylvester, J.: Gradient reversal against discrimination: A fair neural net- work learning approach. In: 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA). pp. 189–198. IEEE (2018).https: //doi.org/10.1109/DSAA.2018.0002911, 12
-
[25]
Sirotkin, K., Carballeira, P., Escudero-Viñolo, M.: A study on the distribution of social biases in self-supervised learning visual models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10442–10451 (2022).https://doi.org/10.1109/CVPR52688.2022.010191, 3
-
[26]
In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency
Steed, R., Caliskan, A.: Image representations learned with unsupervised pre- training contain human-like biases. In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. p. 701–713. FAccT ’21, Association for Computing Machinery, New York, NY, USA (2021).https://doi.org/10. 1145/3442188.3445932,https://doi.org/10.1145/344...
-
[27]
In: Proceedings of the 11th International Conference on Learning Representations (ICLR) (2023), https://openreview.net/forum?id=woa783QMul1, 5
Zhang, F., Kuang, K., Chen, L., Liu, Y., Wu, C., Xiao, J.: Fairness-aware con- trastive learning with partially annotated sensitive attributes. In: Proceedings of the 11th International Conference on Learning Representations (ICLR) (2023), https://openreview.net/forum?id=woa783QMul1, 5
2023
-
[28]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, Z., Song, Y., Qi, H.: Age progression/regression by conditional adversarial autoencoder. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4352–4360 (2017) 2, 10
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.