Recognition: 3 theorem links
· Lean TheoremBenchmarking Wireless Representations: High-Dimensional vs. Compressed Embeddings for Efficiency and Robustness
Pith reviewed 2026-05-08 19:19 UTC · model grok-4.3
The pith
Compressed autoencoder representations for wireless channels deliver better noise robustness and lower costs than high-dimensional embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
High-dimensional learned embeddings from a wireless foundation model can succeed in few-shot regimes for certain downstream tasks but incur substantial latency and parameter overhead, while compact latent representations learned by autoencoders demonstrate improved noise robustness, more stable performance across tasks, and significantly reduced computational and transmission costs.
What carries the argument
Direct comparison of high-dimensional embeddings versus low-dimensional autoencoder latent representations, measured on LoS/NLoS classification, beam selection, and power allocation.
If this is right
- High-dimensional embeddings impose measurable latency and memory overhead in deployed systems.
- Autoencoder latents reduce both computational load during inference and data volume for transmission.
- Compressed representations maintain more consistent accuracy when input signals contain noise.
- Introducing power allocation as a downstream task reveals the same efficiency-robustness pattern seen in classification and beam selection.
Where Pith is reading between the lines
- Designers of wireless AI systems could default to compressed representations when operating under strict latency or energy budgets.
- The same compression approach might extend to other wireless tasks such as channel estimation or interference mitigation without retraining large foundation models.
- Lower transmission costs from compressed embeddings could enable more frequent model updates over the air in mobile networks.
Load-bearing premise
The assumption that the chosen tasks, models, and datasets capture the essential trade-offs that would appear in actual wireless deployments with varied hardware and channel conditions.
What would settle it
A new test set with different channel models or hardware impairments where compressed representations lose their measured advantage in noise robustness or where high-dimensional embeddings show no extra latency cost.
Figures



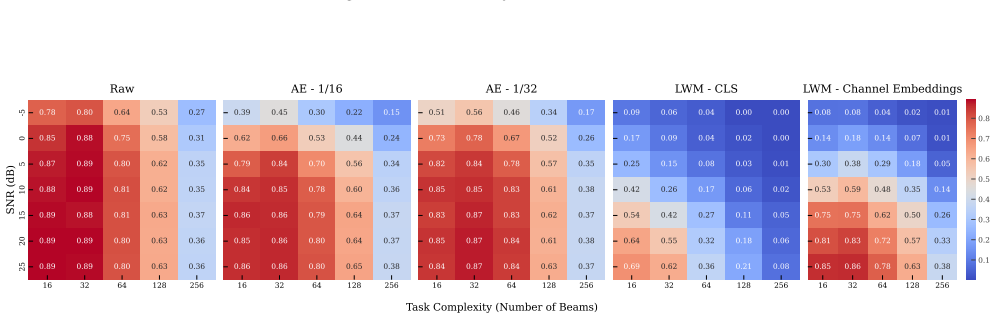
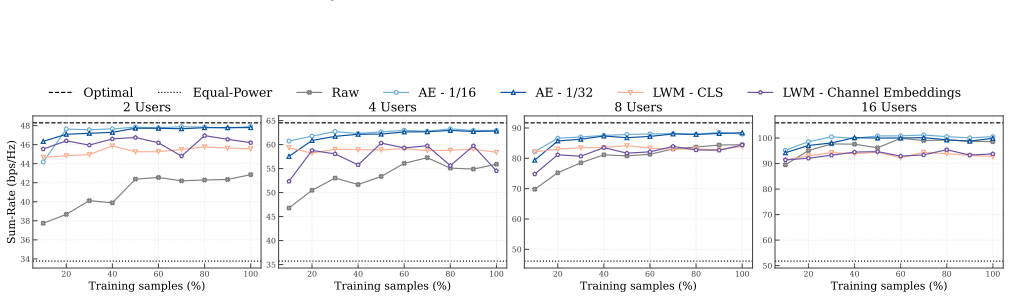
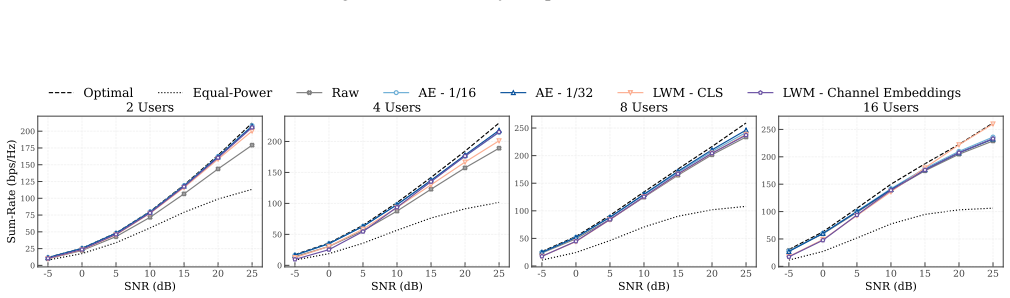
read the original abstract
Building on recent advances in representation learning for wireless channels, this work investigates the cost-benefit trade-offs of high-dimensional channel embeddings in practical systems. We benchmark multiple wireless representations: high-dimensional learned embeddings from a wireless foundation model, compact autoencoder-based representations with significantly lower dimensionality, and raw data baselines, evaluating their performance across diverse downstream tasks. We then systematically analyze data efficiency, noise robustness, and computational complexity, explicitly characterizing the resource overhead associated with high-dimensional embeddings. Beyond standard tasks such as line-of-sight/non-line-of-sight (LoS/NLoS) classification and beam selection, we introduce power allocation as a new downstream task. Our results reveal clear trade-offs: while high-dimensional embeddings can perform well in few-shot regimes for certain tasks, they incur substantial latency and parameter overhead. In contrast, compressed latent representations learned by autoencoders demonstrate improved noise robustness and more stable performance across tasks, while significantly reducing computational and transmission costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks high-dimensional learned embeddings from a wireless foundation model against compact autoencoder-based representations and raw data baselines across downstream wireless tasks. It evaluates data efficiency, noise robustness, and computational complexity on LoS/NLoS classification, beam selection, and a newly introduced power allocation task, concluding that high-dimensional embeddings perform well in few-shot regimes but incur substantial latency and parameter overhead while compressed latent representations offer improved noise robustness, stability, and reduced costs.
Significance. If the empirical results hold under rigorous validation, this work provides actionable insights into representation choices for practical wireless systems, highlighting efficiency-robustness trade-offs that are relevant for resource-constrained deployments. The systematic comparison and introduction of power allocation as a task strengthen the contribution to representation learning in communications.
major comments (2)
- [Results and Experimental Setup] The experimental results sections do not report the number of independent trials, error bars, or statistical significance tests for the performance metrics across tasks. This makes it difficult to assess whether the claimed improvements in noise robustness and stability for compressed representations are reliable or could arise from variability in the specific models and datasets used.
- [Discussion and Conclusion] The generalization claim that the evaluated tasks (LoS/NLoS classification, beam selection, power allocation) and models are sufficient to characterize trade-offs for practical wireless deployments lacks supporting analysis of how representative the chosen datasets and channel conditions are of real-world scenarios.
minor comments (2)
- [Methods] Clarify the exact dimensionality reduction ratios and autoencoder architectures in the methods section for reproducibility.
- [Figures] Ensure all figures include clear legends and axis labels indicating the specific representations compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address the two major comments point by point below, providing clarifications and indicating the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Results and Experimental Setup] The experimental results sections do not report the number of independent trials, error bars, or statistical significance tests for the performance metrics across tasks. This makes it difficult to assess whether the claimed improvements in noise robustness and stability for compressed representations are reliable or could arise from variability in the specific models and datasets used.
Authors: We agree that these details are necessary to substantiate the reliability of the reported improvements. In the revised manuscript, we have added explicit statements that all experiments were conducted over 10 independent trials using different random seeds. Error bars (mean ± one standard deviation) have been included in all performance figures in Sections 4.2–4.4 and 5. We have also added a new subsection on statistical analysis, reporting p-values from paired t-tests that confirm the noise-robustness advantages of the compressed representations are statistically significant (p < 0.05) relative to the high-dimensional and raw baselines across the evaluated SNR range. revision: yes
-
Referee: [Discussion and Conclusion] The generalization claim that the evaluated tasks (LoS/NLoS classification, beam selection, power allocation) and models are sufficient to characterize trade-offs for practical wireless deployments lacks supporting analysis of how representative the chosen datasets and channel conditions are of real-world scenarios.
Authors: We acknowledge that a stronger discussion of dataset representativeness would better support the generalization statements. In the revised Discussion and Conclusion sections, we have added a dedicated paragraph that (i) references the 3GPP TR 38.901 channel model and Sionna simulator used to generate the datasets, (ii) notes their prior adoption in multiple wireless ML studies for urban macro and indoor scenarios, and (iii) explicitly qualifies the scope by highlighting limitations such as the absence of high-mobility or mmWave-specific conditions. This addition provides a more balanced view without altering the core empirical claims. revision: yes
Circularity Check
No significant circularity; empirical benchmarking study
full rationale
The paper is an empirical benchmarking study that compares high-dimensional learned embeddings, compact autoencoder-based representations, and raw data baselines on downstream wireless tasks (LoS/NLoS classification, beam selection, power allocation). It reports observed trade-offs in data efficiency, noise robustness, and computational complexity from experimental results. No mathematical derivations, first-principles predictions, fitted parameters renamed as predictions, or self-citation load-bearing claims appear in the provided abstract or described content. The central claims rest on direct performance measurements against the evaluated models and datasets, remaining self-contained without reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J(x)=½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
max_p sum log2(1 + SINR_k) s.t. sum p_k ≤ P_total — Projected Gradient Descent with supervised warm-up + unsupervised SE maximization.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=
-
[2]
Language Models are Few-Shot Learners , author=. Proc. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[3]
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. Proc. Int. Conf. Learn. Representations (ICLR) , year =
-
[4]
and Han, B
Jiang, W. and Han, B. and Habibi, M. A. and Schotten, H. D. , title =
-
[5]
2025 , volume=
Alikhani, Sadjad and Charan, Gouranga and Alkhateeb, Ahmed , booktitle=. 2025 , volume=
2025
-
[6]
Attention is All You Need , volume =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All You Need , volume =
-
[7]
Ahmed Alkhateeb , title =. Proc. Inf. Theory Appl. Workshop (ITA) , year =
-
[8]
IEEE Wireless Commun
Chao-Kai Wen and Wan-Ting Shih and Shi Jin , title =. IEEE Wireless Commun. Lett. , year =
-
[9]
, title =
Marzetta, Thomas L. , title =. 2010 , publisher=
2010
-
[10]
Proceedings of the
Deep residual learning for image recognition , author =. Proceedings of the
-
[11]
and Swindlehurst, A.L
Spencer, Q.H. and Swindlehurst, A.L. and Haardt, M. , journal=. Zero-Forcing Methods for Downlink Spatial Multiplexing in Multiuser. 2004 , volume=
2004
-
[12]
2018 , publisher=
Learning to optimize: Training deep neural networks for interference management , author=. 2018 , publisher=
2018
-
[13]
2022 , note =
Sionna , author =. 2022 , note =
2022
-
[14]
Catak, Ferhat Ozgur and Kuzlu, Murat and Cali, Umit , year=. 2501.01802 , archivePrefix=
-
[15]
Transformer Empowered
Xu, Yang and Yuan, Mingqi and Pun, Man-On , booktitle=. Transformer Empowered. 2021 , pages=
2021
-
[16]
Eisen, Mark and Zhang, Clark and Chamon, Luiz F. O. and Lee, Daniel D. and Ribeiro, Alejandro , journal=. Learning Optimal Resource Allocations in Wireless Systems , year=
-
[17]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
-
[18]
International Conference on Machine Learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[19]
, journal=
Lo, T.K.Y. , journal=. Maximum Ratio Transmission , year=
-
[20]
Stephen Boyd and Lieven Vandenberghe , title =
-
[21]
Visualizing data using t-
Van der Maaten, Laurens and Hinton, Geoffrey , journal=. Visualizing data using t-
-
[22]
Power of deep learning for channel estimation and signal detection in
Ye, Hao and Li, Geoffrey Ye and Juang, Biing-Hwang , journal=. Power of deep learning for channel estimation and signal detection in. 2018 , publisher=
2018
-
[23]
2017 , publisher=
An introduction to deep learning for the physical layer , author=. 2017 , publisher=
2017
-
[24]
2025 , volume=
Aboulfotouh, Ahmed and Mohammed, Elsayed and Abou-Zeid, Hatem , journal=. 2025 , volume=
2025
-
[25]
2026 , pages=
Zhang, Han and Farzanullah, Mohammad and Ghassemi, Mohammad and Bin Sediq, Akram and Afana, Ali and Erol-Kantarci, Melike , title=. 2026 , pages=
2026
-
[26]
2025 , doi=
Liu, Boxun and Gao, Shijian and Liu, Xuanyu and Cheng, Xiang and Yang, Liuqing , journal=. 2025 , doi=
2025
-
[27]
2026 , eprint=
Multimodal Wireless Foundation Models , author=. 2026 , eprint=
2026
-
[28]
An iteratively weighted
Shi, Qingjiang and Razaviyayn, Meisam and Luo, Zhi-Quan and He, Chen , journal=. An iteratively weighted. 2011 , publisher=
2011
-
[29]
2018 , publisher=
Learning to optimize in systems and control , author=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.