Recognition: 3 theorem links
· Lean TheoremMIRA: A Score for Conditional Distribution Accuracy and Model Comparison
Pith reviewed 2026-05-08 19:02 UTC · model grok-4.3
The pith
Mira is a sample-based score that checks how well any candidate conditional distribution matches the true data-generating process using only joint samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Distributions coincide when they assign equal probability mass to all regions; the paper derives the corresponding analytic Mira statistic from joint samples alone, shows that its expectation equals a known constant under perfect match, and demonstrates that the resulting score ranks candidate conditionals by fidelity to the true process, thereby enabling Bayesian model comparison through posterior validation rather than marginal likelihood computation.
What carries the argument
The Mira statistic obtained by enforcing equal probability mass assignment across regions and averaging the resulting expression over joint samples.
If this is right
- Model comparison reduces to ranking candidates by their Mira scores against the same joint samples.
- Bayesian posterior validation becomes possible without any evidence calculation.
- Reference values and uncertainty bands are available whenever the candidate matches the true conditional.
- The method applies directly to any setting that supplies joint samples, including toy problems and full Bayesian inference tasks.
Where Pith is reading between the lines
- The approach could be applied to select among neural-network conditionals in high-dimensional inverse problems where evidence is intractable.
- It might serve as a calibration check for conditional generative models trained on observational data.
- Extensions could test whether Mira remains stable under different region-partitioning schemes or when samples are noisy.
Load-bearing premise
That matching probability mass on every region is enough to certify two conditional distributions as equivalent, and that the derived statistic stays reliable when estimated from finite joint samples.
What would settle it
In a simulation where the true conditional is known exactly, generate many joint samples, compute Mira scores for both the true conditional and deliberately misspecified alternatives, and check whether the score for the true conditional consistently equals its theoretical reference value while the misspecified ones fall outside the predicted uncertainty range.
Figures







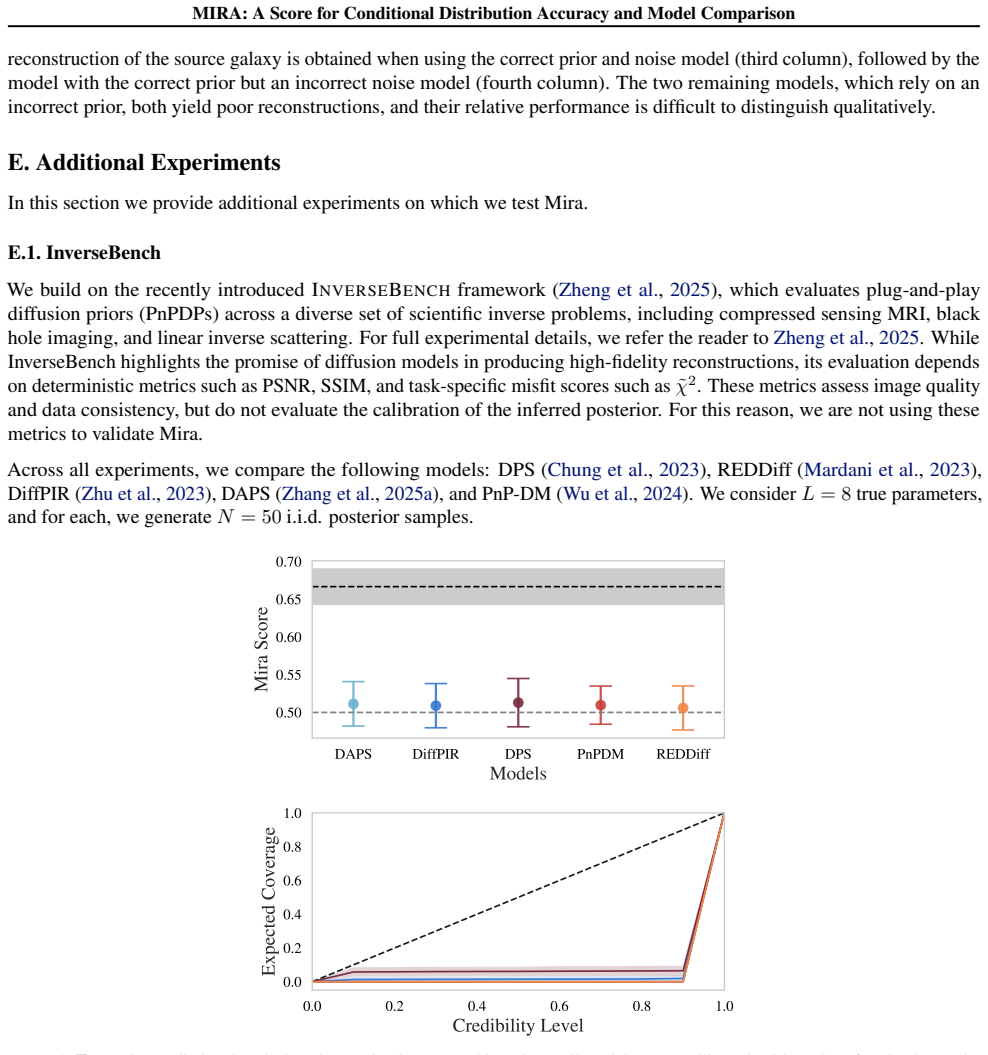





read the original abstract
We introduce Mira, a sample-based score for assessing the accuracy of a candidate conditional distribution using only joint samples from the true data-generating process. Relying on the principle that distributions coincide if they assign equal probability mass to all regions, we derive an analytic expression for the Mira statistic, whose average defines the Mira score. This formulation further allows us to compute theoretical reference values and uncertainty estimates when the candidate distribution matches the true one. This framework enables model comparison by quantifying the alignment between the conditional distribution of a candidate model and the true data generating process. Consequently, Mira enables Bayesian model comparison through direct posterior validation, bypassing the challenging evidence computation. We demonstrate its effectiveness across several toy problems and Bayesian inference tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MIRA, a sample-based score for assessing the accuracy of a candidate conditional distribution q(y|x) using only joint samples from the true data-generating process p(x,y). It relies on the principle that distributions coincide when they assign equal probability mass to all regions, derives an analytic expression for the Mira statistic whose average yields the score, and supplies theoretical reference values plus uncertainty estimates for the case when the candidate matches the true conditional. The framework is positioned for model comparison and, specifically, for Bayesian model comparison via direct posterior validation that bypasses evidence computation. Effectiveness is shown on toy problems and Bayesian inference tasks.
Significance. If the analytic derivation holds and the finite-sample estimator preserves the claimed reference values, MIRA would provide a practical, calibrated tool for conditional distribution assessment and Bayesian model comparison without requiring marginal likelihoods. The explicit provision of theoretical reference values and uncertainty estimates when q equals the true conditional is a clear strength that enables interpretable use. The approach directly addresses a common pain point in Bayesian workflows by offering a sample-based posterior check.
major comments (2)
- [§3] §3 (Analytic Derivation): The manuscript asserts an analytic expression for the Mira statistic derived from equal probability mass on regions, yet the explicit formula, the definition of the regions in the joint space, and the proof that the expectation equals the stated reference value (zero discrepancy) when the candidate matches the true conditional are not shown. Without these, it is impossible to verify that the statistic is independent of the target result or that the reference values remain valid.
- [§4] §4 (Finite-Sample Estimator): The central claim requires that the sample-based Mira statistic, computed from empirical joint samples, yields the theoretical reference value when the candidate conditional equals the true one. However, the estimator replaces the true joint with the empirical joint while using the candidate to induce p(x)q(y|x); no derivation or simulation demonstrates that region counts under finite sampling preserve the zero-discrepancy reference or the uncertainty quantification. This directly undermines the use for reliable model comparison.
minor comments (2)
- The abstract and introduction refer to 'several toy problems' and 'Bayesian inference tasks' without naming the specific models, dimensions, or quantitative baselines (e.g., against KL divergence or posterior predictive checks) used for comparison.
- Figure captions should explicitly state what the plotted Mira scores represent (e.g., deviation from the theoretical reference) and whether error bars are the derived uncertainty estimates.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We appreciate the recognition of MIRA's potential significance for conditional distribution assessment and Bayesian model comparison without evidence computation. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and supporting material.
read point-by-point responses
-
Referee: [§3] §3 (Analytic Derivation): The manuscript asserts an analytic expression for the Mira statistic derived from equal probability mass on regions, yet the explicit formula, the definition of the regions in the joint space, and the proof that the expectation equals the stated reference value (zero discrepancy) when the candidate matches the true conditional are not shown. Without these, it is impossible to verify that the statistic is independent of the target result or that the reference values remain valid.
Authors: We agree that Section 3 did not present the derivation with sufficient explicitness. In the revised manuscript we have expanded this section to include the full analytic expression for the Mira statistic, the precise definition of the regions in the joint space (constructed as a partition where each region receives equal probability mass under the true joint p(x,y)), and a complete proof that the expectation of the statistic is exactly zero whenever the candidate conditional equals the true conditional. The proof proceeds by showing that equal mass assignment implies zero discrepancy and that this holds independently of the particular target values, thereby validating the reference values. revision: yes
-
Referee: [§4] §4 (Finite-Sample Estimator): The central claim requires that the sample-based Mira statistic, computed from empirical joint samples, yields the theoretical reference value when the candidate conditional equals the true one. However, the estimator replaces the true joint with the empirical joint while using the candidate to induce p(x)q(y|x); no derivation or simulation demonstrates that region counts under finite sampling preserve the zero-discrepancy reference or the uncertainty quantification. This directly undermines the use for reliable model comparison.
Authors: We acknowledge that the finite-sample properties were insufficiently justified in the original submission. The revised manuscript now contains an explicit derivation establishing that, when the candidate conditional matches the true one, the expected region counts under the empirical joint still yield the zero-discrepancy reference value, together with the corresponding analytic uncertainty quantification. We have also added simulation studies (now reported in the supplementary material) that confirm convergence to the theoretical reference and preservation of the uncertainty estimates for moderate sample sizes, supporting reliable use in model comparison. revision: yes
Circularity Check
No significant circularity in Mira derivation
full rationale
The paper derives the Mira statistic analytically from the principle that coinciding distributions assign equal probability mass to all regions, yielding an explicit expression whose average is the score. Theoretical reference values (including zero discrepancy when candidate matches true) and uncertainty estimates follow directly as the null distribution of this statistic. This is a standard construction of a discrepancy measure and its calibration, not a reduction by definition or fit. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior work are invoked; finite-sample estimation is presented as a practical step separate from the population derivation. The model-comparison use case follows immediately from the score without circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distributions coincide if they assign equal probability mass to all regions
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Constants (J-cost, φ)washburn_uniqueness_aczel; phi_fixed_point unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PN converges in distribution to a Beta(2,1) random variable as N → ∞. ... E[PN] → 2/3 ... Var[PN] → 1/18
-
Foundation.LogicAsFunctionalEquationJ(x) = ½(x + x⁻¹) − 1 forced by Aristotelian conditions unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
p(k|n) = (n+1)/(N+2)·1(k=1) + (N−n+1)/(N+2)·1(k=0) (Laplace's rule of succession)
-
Foundation.AlphaCoordinateFixation / BranchSelectionalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
λ_n | x*, c ~ U[0,1] via probability integral transform
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
2020 , eprint=
A complement to the Chebyshev integral inequality , author=. 2020 , eprint=
2020
-
[3]
ATT Labs [Online]
The MNIST database of handwritten digits , author=. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist , volume=
-
[4]
Shaoyan Pan and Chih-Wei Chang and Zhen Tian and Tonghe Wang and Marian Axente and Joseph Shelton and Tian Liu and Justin Roper and Xiaofeng Yang , abstract =. Data-Driven Volumetric Computed Tomography Image Generation From Surface Structures Using a Patient-Specific Deep Leaning Model , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.ijrobp.2024...
-
[5]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
X2CT-GAN: Reconstructing CT From Biplanar X-Rays With Generative Adversarial Networks , author=. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2019
-
[6]
Astronomy & Astrophysics , keywords =
Probabilistic mass-mapping with neural score estimation. Astronomy & Astrophysics , keywords =. doi:10.1051/0004-6361/202243054 , archivePrefix =. 2201.05561 , primaryClass =
-
[7]
and Smith, Jamie and Rubinstein, Michael and Chang, Huiwen and Bouman, Katherine L
Feng, Berthy T. and Smith, Jamie and Rubinstein, Michael and Chang, Huiwen and Bouman, Katherine L. and Freeman, William T. , booktitle=. Score-Based Diffusion Models as Principled Priors for Inverse Imaging , year=
-
[8]
Posterior samples of source galaxies in strong gravitational lenses with score-based priors. Machine Learning and the Physical Sciences Workshop , year = 2022, month = jan, pages =. doi:10.48550/arXiv.2211.03812 , archivePrefix =. 2211.03812 , primaryClass =
-
[9]
Monthly Notices of the Royal Astronomical Society , keywords =
Posterior sampling of the initial conditions of the universe from non-linear large scale structures using score-based generative models. Monthly Notices of the Royal Astronomical Society , keywords =. doi:10.1093/mnrasl/slad152 , archivePrefix =. 2304.03788 , primaryClass =
-
[10]
Marco Bellagente and Anja Butter and Gregor Kasieczka and Tilman Plehn and Ramon Winterhalder , journal=. 2020 , publisher=. doi:10.21468/SciPostPhys.8.4.070 , url=
-
[11]
Physical Review D , keywords =
Improving generative model-based unfolding with Schr \"o dinger bridges. Physical Review D , keywords =. doi:10.1103/PhysRevD.109.076011 , archivePrefix =. 2308.12351 , primaryClass =
-
[12]
Camila Pazos and Shuchin Aeron and Pierre-Hugues Beauchemin and Vincent Croft and Zhengyan Huan and Martin Klassen and Taritree Wongjirad , journal=. 2025 , publisher=. doi:10.21468/SciPostPhysCore.8.4.064 , url=
-
[13]
MCVD - Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation , volume =
Voleti, Vikram and Jolicoeur-Martineau, Alexia and Pal, Chris , booktitle =. MCVD - Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation , volume =
-
[14]
and Ecker, Alexander S
Gatys, Leon A. and Ecker, Alexander S. and Bethge, Matthias , booktitle=. Image Style Transfer Using Convolutional Neural Networks , year=
-
[15]
2023 , eprint=
L-C2ST: Local Diagnostics for Posterior Approximations in Simulation-Based Inference , author=. 2023 , eprint=
2023
-
[16]
2018 , eprint=
Revisiting Classifier Two-Sample Tests , author=. 2018 , eprint=
2018
-
[17]
Borgwardt and Malte J
Arthur Gretton and Karsten M. Borgwardt and Malte J. Rasch and Bernhard Sch. A Kernel Two-Sample Test , journal =. 2012 , volume =
2012
-
[18]
Radhakrishna Rao , journal =
C. Radhakrishna Rao , journal =. Tests of Significance in Multivariate Analysis , urldate =
-
[19]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[20]
International conference on machine learning , pages=
How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[21]
Advances in neural information processing systems , volume=
Assessing generative models via precision and recall , author=. Advances in neural information processing systems , volume=
-
[22]
Advances in neural information processing systems , volume=
Improved techniques for training gans , author=. Advances in neural information processing systems , volume=
-
[23]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[24]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[25]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[26]
Advances in Neural Information Processing Systems , volume=
Learning diffusion priors from observations by expectation maximization , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
2019 , eprint=
Sequential Neural Likelihood: Fast Likelihood-free Inference with Autoregressive Flows , author=. 2019 , eprint=
2019
-
[28]
2016 , eprint=
Approximating Likelihood Ratios with Calibrated Discriminative Classifiers , author=. 2016 , eprint=
2016
-
[29]
2018 , eprint=
Fast -free Inference of Simulation Models with Bayesian Conditional Density Estimation , author=. 2018 , eprint=
2018
-
[30]
2021 , eprint=
Benchmarking Simulation-Based Inference , author=. 2021 , eprint=
2021
-
[31]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[32]
M. J. Kearns , title =
-
[33]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[34]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[35]
Suppressed for Anonymity , author=
-
[36]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[37]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[38]
Cosmological parameters from SDSS and WMAP. Physical Review D , keywords =. doi:10.1103/PhysRevD.69.103501 , archivePrefix =. astro-ph/0310723 , primaryClass =
-
[39]
2025 , eprint=
Field-Level Comparison and Robustness Analysis of Cosmological N-Body Simulations , author=. 2025 , eprint=
2025
-
[40]
Carzon, James and Abreu, Bruno and Regayre, Leighton and Carslaw, Kenneth and Deaconu, Lucia and Stier, Philip and Gordon, Hamish and Kuusela, Mikael , year=. Statistical constraints on climate model parameters using a scalable cloud-based inference framework , volume=. doi:10.1017/eds.2023.12 , journal=
-
[41]
Orozco Valero, A and Rodríguez-González, V and Montobbio, N and Casal, M. A and Tlaie, A and Pelayo, F and Morillas, C and Poza, J and Gómez, C and Martínez-Cañada, P , title =. NPJ Systems Biology and Applications , year =. doi:10.1038/s41540-025-00527-9 , pmid =
-
[42]
Tolley, N and Rodrigues, P. L. C and Gramfort, A and Jones, S. R , title =. PLoS Computational Biology , year =. doi:10.1371/journal.pcbi.1011108 , pmid =
-
[43]
Howland, Michael F. and Dunbar, Oliver R. A. and Schneider, Tapio , title =. Journal of Advances in Modeling Earth Systems , volume =. doi:https://doi.org/10.1029/2021MS002735 , url =. https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2021MS002735 , note =
-
[44]
Validating Bayesian Inference Algorithms with Simulation-Based Calibration. arXiv e-prints , keywords =. doi:10.48550/arXiv.1804.06788 , archivePrefix =. 1804.06788 , primaryClass =
-
[45]
2023 , eprint=
Sampling-Based Accuracy Testing of Posterior Estimators for General Inference , author=. 2023 , eprint=
2023
-
[46]
2025 , eprint=
PQMass: Probabilistic Assessment of the Quality of Generative Models using Probability Mass Estimation , author=. 2025 , eprint=
2025
-
[47]
Journal of Computational and Graphical Statistics , volume=
Validation of software for Bayesian models using posterior quantiles , author=. Journal of Computational and Graphical Statistics , volume=. 2006 , publisher=
2006
-
[48]
The American Statistician , volume=
Methods for calculating highest posterior density intervals , author=. The American Statistician , volume=. 1999 , publisher=
1999
-
[49]
Statistica Sinica , pages=
Posterior predictive assessment of model fitness via realized discrepancies , author=. Statistica Sinica , pages=. 1996 , publisher=
1996
-
[50]
Journal of the American Statistical Association , volume=
Bayes factors , author=. Journal of the American Statistical Association , volume=. 1995 , publisher=
1995
-
[51]
IEEE Transactions on Automatic Control , volume=
A new look at the statistical model identification , author=. IEEE Transactions on Automatic Control , volume=. 1974 , publisher=
1974
-
[52]
Annals of Statistics , volume=
Estimating the dimension of a model , author=. Annals of Statistics , volume=
-
[53]
Statistics and Computing , volume=
Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC , author=. Statistics and Computing , volume=. 2017 , publisher=
2017
-
[54]
Journal of Machine Learning Research , volume=
Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory , author=. Journal of Machine Learning Research , volume=
-
[55]
R. B. O'Hara and M. J. Sillanp. Bayesian Analysis , number =. 2009 , doi =
2009
-
[56]
, title=
Kiessler, Peter C. , title=. Journal of the American Statistical Association , year=2007, volume=. doi:, abstract=
2007
-
[57]
Barco, Gabriel Missael and Adam, Alexandre and Stone, Connor and Hezaveh, Yashar and Perreault-Levasseur, Laurence , year=. Tackling the Problem of Distributional Shifts: Correcting Misspecified, High-dimensional Data-driven Priors for Inverse Problems , volume=. The Astrophysical Journal , publisher=. doi:10.3847/1538-4357/ad9b92 , number=
-
[58]
Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =
Yang Song and Jascha Sohl. Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =. 2021 , url =
2021
-
[59]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[60]
Posterior samples of source galaxies in strong gravitational lenses with score-based priors. Machine Learning and the Physical Sciences Workshop, NeurIPS 2022 , year = 2022, month = jan, archivePrefix =. 2211.03812 , primaryClass =
-
[61]
2024 , eprint=
Caustics: A Python Package for Accelerated Strong Gravitational Lensing Simulations , author=. 2024 , eprint=
2024
-
[62]
Kingma and Max Welling , journal=
Diederik P. Kingma and Max Welling , journal=. Auto-Encoding Variational
-
[63]
Neural Information Processing Systems (NIPS) , year=
Generative adversarial nets , author=. Neural Information Processing Systems (NIPS) , year=
-
[64]
2014 , eprint=
Stochastic Backpropagation and Approximate Inference in Deep Generative Models , author=. 2014 , eprint=
2014
-
[65]
International Conference on Machine Learning (ICML) , year=
Variational inference with normalizing flows , author=. International Conference on Machine Learning (ICML) , year=
-
[66]
International Conference on Learning Representations (ICLR) , year=
A note on the evaluation of generative models , author=. International Conference on Learning Representations (ICLR) , year=
-
[67]
Entropy , volume=
Perfect density models cannot guarantee anomaly detection , author=. Entropy , volume=. 2021 , publisher=
2021
-
[68]
International Conference on Image Processing (ICIP) , year=
Empirical analysis of overfitting and mode drop in gan training , author=. International Conference on Image Processing (ICIP) , year=
-
[69]
Nowozin, Sebastian and Cseke, Botond and Tomioka, Ryota , journal=
-
[70]
International Conference on Learning Representations (ICLR) , year=
Do deep generative models know what they don't know? , author=. International Conference on Learning Representations (ICLR) , year=
-
[71]
Neural Information Processing Systems (NeurIPS) , year=
Denoising diffusion probabilistic models , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[72]
International Conference on Learning Representations (ICLR) , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations (ICLR) , year=
-
[73]
Evidence Networks: simple losses for fast, amortized, neural Bayesian model comparison , volume=
Jeffrey, Niall and Wandelt, Benjamin D , year=. Evidence Networks: simple losses for fast, amortized, neural Bayesian model comparison , volume=. Machine Learning: Science and Technology , publisher=. doi:10.1088/2632-2153/ad1a4d , number=
-
[74]
2003, MNRAS, 340, 1214, doi: 10.1046/j.1365-8711.2003.06380.x
Slosar, A. and Carreira, P. and Cleary, K. and Davies, R. D. and Davis, R. J. and Dickinson, C. and Genova-Santos, R. and Grainge, K. and Gutierrez, C. M. and Hafez, Y. A. and Hobson, M. P. and Jones, M. E. and Kneissl, R. and Lancaster, K. and Lasenby, A. and Leahy, J. P. and Maisinger, K. and Marshall, P. J. and Pooley, G. G. and Rebolo, R. and Rubino-M...
-
[75]
Comparison of Bayesian predictive methods for model selection , volume=
Piironen, Juho and Vehtari, Aki , year=. Comparison of Bayesian predictive methods for model selection , volume=. Statistics and Computing , publisher=. doi:10.1007/s11222-016-9649-y , number=
-
[76]
Ka-Veng Yuen , keywords =. Recent developments of Bayesian model class selection and applications in civil engineering , journal =. 2010 , note =. doi:https://doi.org/10.1016/j.strusafe.2010.03.011 , url =
-
[77]
Neural Information Processing Systems (NeurIPS) , year=
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[78]
Neural Information Processing Systems (NeurIPS) , year=
Feature Likelihood Score: Evaluating Generalization of Generative Models Using Samples , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[79]
Massive optimal data compression and density estimation for scalable, likelihood-free inference in cosmology. Monthly Notices of the Royal Astronomical Society , keywords =. doi:10.1093/mnras/sty819 , archivePrefix =. 1801.01497 , primaryClass =
-
[80]
Bayesian model comparison for simulation-based inference , volume=
Spurio Mancini, A and Docherty, M M and Price, M A and McEwen, J D , year=. Bayesian model comparison for simulation-based inference , volume=. RAS Techniques and Instruments , publisher=. doi:10.1093/rasti/rzad051 , number=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.