Recognition: 3 theorem links
· Lean TheoremCounting as a minimal probe of language model reliability
Pith reviewed 2026-05-08 19:34 UTC · model grok-4.3
The pith
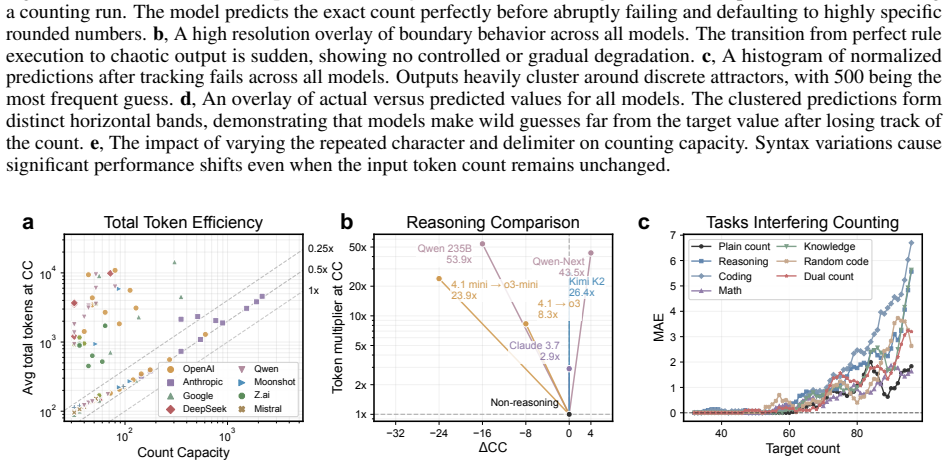
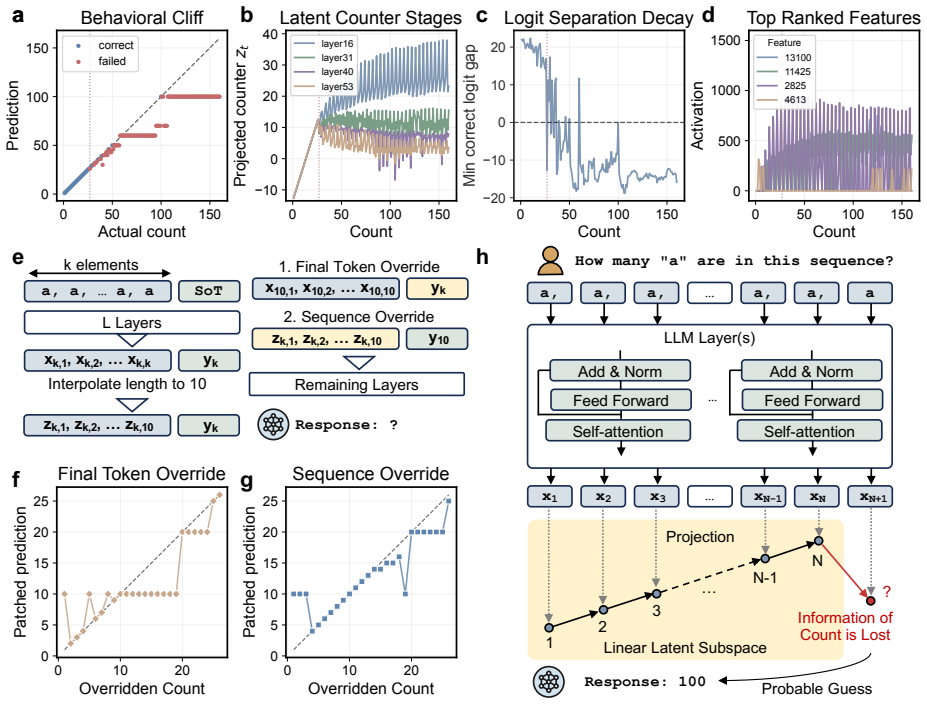
Language models have limited stable counting capacity well below context limits and rely on a finite set of count-like internal states, collapsing to guessing once exhausted.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Model behavior is consistent neither with open-ended logic nor with stable application of a learned rule, but instead with use of a finite set of count-like internal states, analogous to counting on fingers. Once this resource is exhausted, the appearance of rule following disappears and exact execution collapses into guessing.
Load-bearing premise
That the observed collapse in counting performance directly indicates a lack of general logical competence rather than a task-specific limitation in how models represent or maintain count information.
Figures


read the original abstract
Large language models perform strongly on benchmarks in mathematical reasoning, coding and document analysis, suggesting a broad ability to follow instructions. However, it remains unclear whether such success reflects general logical competence, repeated application of learned procedures, or pattern matching that mimics rule execution. We investigate this question by introducing Stable Counting Capacity, an assay in which models count repeated symbols until failure. The assay removes knowledge dependencies, semantics and ambiguity from evaluation, avoids lexical and tokenization confounds, and provides a direct measure of procedural reliability beyond standard knowledge-based benchmarks. Here we show, across more than 100 model variants, that stable counting capacity remains far below advertised context limits. Model behavior is consistent neither with open-ended logic nor with stable application of a learned rule, but instead with use of a finite set of count-like internal states, analogous to counting on fingers. Once this resource is exhausted, the appearance of rule following disappears and exact execution collapses into guessing, even with additional test-time compute. These findings show that fluent performance in current language models does not guarantee general, reliable rule following.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The counting assay removes knowledge dependencies, semantics, ambiguity, and tokenization confounds
invented entities (1)
-
finite set of count-like internal states
no independent evidence
Lean theorems connected to this paper
-
Foundation/ArithmeticFromLogic.leanLogicNat / equivNat (initial Peano object from distinction) unclearmodel behavior is consistent neither with open-ended logic nor with stable application of a learned rule, but instead with use of a finite set of count-like internal states
-
Foundation/ArithmeticOf.leanArithmeticOf.canonical / PeanoSurface unclearStable Counting Capacity (SCC), a purely mechanical assay that utilizes a minimal probe based on homogeneous sequence counting
-
Cost (J-cost), Constants (phi, c, ℏ, G)n/a — no φ-ladder or J-cost structure invoked unclearCounting capacities... spanning a broad range, with newer models often supporting larger CCs
Reference graph
Works this paper leans on
-
[1]
H., Wu, Y ., Le, Q
Trinh, T. H., Wu, Y ., Le, Q. V ., He, H. & Luong, T. Solving olympiad geometry without human demonstrations. Nature625, 476–482 (2024)
2024
-
[2]
URLhttps://aclanthology.org/2024.acl-long.211/
He, C.et al.OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems (2024). URLhttps://aclanthology.org/2024.acl-long.211/
2024
-
[3]
Chen, M.et al.Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page Pith review arXiv 2021
-
[4]
URL https://aclanthology.org/2024.acl-long.172/
Bai, Y .et al.LongBench: A bilingual, multitask benchmark for long context understanding (2024). URL https://aclanthology.org/2024.acl-long.172/
2024
-
[5]
URL https://openreview.net/forum?id= WULjblaCoc
Yehudai, G.et al.When can transformers count to n? (2024). URL https://openreview.net/forum?id= WULjblaCoc
2024
-
[6]
URL https://openreview.net/ forum?id=WbxHAzkeQcn
Delétang, G.et al.Neural networks and the chomsky hierarchy (2023). URL https://openreview.net/ forum?id=WbxHAzkeQcn
2023
-
[7]
URLhttps://aclanthology.org/2025.emnlp-main.511/
Chen, S.et al.Benchmarking large language models under data contamination: A survey from static to dynamic evaluation (2025). URLhttps://aclanthology.org/2025.emnlp-main.511/
2025
-
[8]
& Dascalu, M
Cosma, A., Ruseti, S., Radoi, E. & Dascalu, M. The strawberry problem: Emergence of character-level understanding in tokenized language models (2025)
2025
-
[9]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Rein, D.et al.GPQA: A graduate-level google-proof Q&A benchmark (2023). URL https://arxiv.org/ abs/2311.12022. arXiv:2311.12022
work page internal anchor Pith review arXiv 2023
-
[10]
E.et al.SWE-bench: Can language models resolve real-world GitHub is- sues? (2024)
Jimenez, C. E.et al.SWE-bench: Can language models resolve real-world GitHub is- sues? (2024). URL https://proceedings.iclr.cc/paper_files/paper/2024/hash/ edac78c3e300629acfe6cbe9ca88fb84-Abstract-Conference.html
2024
-
[11]
URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html
Wei, J.et al.Chain-of-thought prompting elicits reasoning in large language mod- els (2022). URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html
2022
-
[12]
S., Reid, M., Matsuo, Y
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y . & Iwasawa, Y . Large language models are zero-shot reasoners (2022). URL https://papers.nips.cc/paper_files/paper/2022/hash/ 8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html
2022
-
[13]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K. & Kumar, A. Scaling LLM test-time compute optimally can be more effective than scaling model parameters (2024). URLhttps://arxiv.org/abs/2408.03314. arXiv:2408.03314
work page Pith review arXiv 2024
-
[14]
URL https://openreview.net/forum?id=iO4LZibEqW
Liang, P.et al.Holistic evaluation of language models.Transactions on Machine Learning Research(2023). URL https://openreview.net/forum?id=iO4LZibEqW
2023
-
[15]
URL https://openreview
Hendrycks, D.et al.Measuring massive multitask language understanding (2021). URL https://openreview. net/forum?id=d7KBjmI3GmQ
2021
-
[16]
URL https://openreview.net/forum?id= uyTL5Bvosj
Srivastava, A.et al.Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research(2023). URL https://openreview.net/forum?id= uyTL5Bvosj
2023
-
[17]
Livebench: A challenging, contamination-free llm benchmark.arXiv preprint arXiv:2406.19314, 2024
White, C.et al.Livebench: A challenging, contamination-free LLM benchmark (2024). URLhttps://arxiv. org/abs/2406.19314. arXiv:2406.19314
-
[18]
Hai, N. L., Nguyen, D. M. & Bui, N. D. Q. REPOEXEC: Evaluate code generation with a repository-level executable benchmark (2024). URLhttps://arxiv.org/abs/2406.11927. arXiv:2406.11927
-
[19]
Wu, Y ., Hee, M. S., Hu, Z. & Lee, R. K.-W. Longgenbench: Benchmarking long-form generation in long context LLMs (2024). URLhttps://arxiv.org/abs/2409.02076. arXiv:2409.02076
-
[20]
URL https://openreview
Yao, S.et al.ReAct: Synergizing reasoning and acting in language models (2023). URL https://openreview. net/forum?id=WE_vluYUL-X. 11
2023
-
[21]
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ d842425e4bf79ba039352da0f658a906-Abstract-Conference.html
Schick, T.et al.Toolformer: Language models can teach themselves to use tools (2023). URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ d842425e4bf79ba039352da0f658a906-Abstract-Conference.html
2023
-
[22]
Arc- agi-2: A new challenge for frontier ai reasoning systems.arXiv preprint arXiv:2505.11831, 2025
Chollet, F., Knoop, M., Kamradt, G., Landers, B. & Pinkard, H. ARC-AGI-2: A new challenge for frontier AI reasoning systems (2025). URLhttps://arxiv.org/abs/2505.11831. arXiv:2505.11831
-
[23]
Barbero, F.et al.Interpreting the repeated token phenomenon in large language models (2024)
2024
-
[24]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
-
[25]
Gemma Team. Gemma 3 technical report (2025). URL https://arxiv.org/abs/2503.19786. arXiv:2503.19786
work page Pith review arXiv 2025
-
[26]
McDougall, C.et al.Gemma scope 2 - technical paper (2025). URL https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/ gemma-scope-2-helping-the-ai-safety-community-deepen-understanding-of-complex-language-model-behavior/ Gemma_Scope_2_Technical_Paper.pdf. Google technical paper
2025
-
[27]
URL https://openreview.net/forum? id=tcsZt9ZNKD
Gao, L.et al.Scaling and evaluating sparse autoencoders (2025). URL https://openreview.net/forum? id=tcsZt9ZNKD
2025
-
[28]
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence
ARC Prize Foundation. ARC-AGI-3: A new challenge for frontier agentic intelligence (2026). arXiv:2603.24621
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
URL https://openreview.net/forum?id=B1ckMDqlg
Shazeer, N.et al.Outrageously large neural networks: The sparsely-gated mixture-of-experts layer (2017). URL https://openreview.net/forum?id=B1ckMDqlg
2017
-
[30]
& Zettlemoyer, L
Dettmers, T., Pagnoni, A., Holtzman, A. & Zettlemoyer, L. QLoRA: Efficient finetuning of quantized LLMs (2023). URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1feb87871436031bdc0f2beaa62a049b-Abstract-Conference.html
2023
-
[31]
URL https://proceedings.mlsys.org/paper_files/paper/2024/hash/ 42a452cbafa9dd64e9ba4aa95cc1ef21-Abstract-Conference.html
Lin, J.et al.AWQ: Activation-aware weight quantization for LLM compression and accel- eration (2024). URL https://proceedings.mlsys.org/paper_files/paper/2024/hash/ 42a452cbafa9dd64e9ba4aa95cc1ef21-Abstract-Conference.html
2024
-
[32]
Theoretical limitations of self-attention in neural sequence models.Transactions of the Association for Computational Linguistics8, 156–171 (2020)
Hahn, M. Theoretical limitations of self-attention in neural sequence models.Transactions of the Association for Computational Linguistics8, 156–171 (2020). URLhttps://aclanthology.org/2020.tacl-1.11/
2020
-
[33]
& Angluin, D
Strobl, L., Merrill, W., Weiss, G., Chiang, D. & Angluin, D. What formal languages can transformers express? a survey.Transactions of the Association for Computational Linguistics12(2024). URL https://aclanthology. org/2024.tacl-1.30/
2024
-
[34]
URL https: //aclanthology.org/P19-1285/
Dai, Z.et al.Transformer-XL: Attentive language models beyond a fixed-length context (2019). URL https: //aclanthology.org/P19-1285/
2019
-
[35]
& Burtsev, M
Bulatov, A., Kuratov, Y . & Burtsev, M. S. Recurrent memory transformer (2022). URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 47e288629a6996a17ce50b90a056a0e1-Abstract-Conference.html
2022
-
[36]
N., Hutchins, D
Wu, Y ., Rabe, M. N., Hutchins, D. & Szegedy, C. Memorizing transformers (2022). URLhttps://openreview. net/forum?id=TrjbxzRcnf-
2022
-
[37]
URL https: //proceedings.mlr.press/v162/borgeaud22a.html
Borgeaud, S.et al.Improving language models by retrieving from trillions of tokens (2022). URL https: //proceedings.mlr.press/v162/borgeaud22a.html
2022
-
[38]
SWE-bench leaderboard and verified subset (2026)
SWE-bench. SWE-bench leaderboard and verified subset (2026). URL https://www.swebench.com/. Official benchmark website
2026
-
[39]
OTIS mock AIME 2024–2025 (2025)
Epoch AI. OTIS mock AIME 2024–2025 (2025). URL https://epoch.ai/benchmarks/ otis-mock-aime-2024-2025. Official benchmark description page
2024
-
[40]
URL https://aclanthology.org/2023.findings-acl.824/
Suzgun, M.et al.Challenging BIG-bench tasks and whether chain-of-thought can solve them (2023). URL https://aclanthology.org/2023.findings-acl.824/
2023
-
[41]
URL https: //proceedings.mlr.press/v235/gu24d.html
Gu, A.et al.CRUXEval: A benchmark for code reasoning, understanding and execution (2024). URL https: //proceedings.mlr.press/v235/gu24d.html
2024
-
[42]
URL https://openreview.net/forum?id=v8L0pN6EOi
Lightman, H.et al.Let’s verify step by step (2024). URL https://openreview.net/forum?id=v8L0pN6EOi
2024
-
[43]
URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ ad236edc564f3e3156e1b2feafb99a24-Abstract-Datasets_and_Benchmarks_Track.html
Wang, Y .et al.MMLU-pro: A more robust and challenging multi-task language understand- ing benchmark (2024). URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ ad236edc564f3e3156e1b2feafb99a24-Abstract-Datasets_and_Benchmarks_Track.html. 12
2024
-
[44]
URL https:// transformer-circuits.pub/2021/framework/index.html
Elhage, N.et al.A mathematical framework for transformer circuits (2021). URL https:// transformer-circuits.pub/2021/framework/index.html. Transformer Circuits thread
2021
-
[45]
Shai, A. S., Marzen, S. E., Teixeira, L., Oldenziel, A. G. & Riechers, P. M. Transformers represent belief state geometry in their residual stream (2024). URLhttps://arxiv.org/abs/2405.15943. arXiv:2405.15943. Acknowledgements This work was funded by the National Science Foundation under Award Number 2103301 and The Packard Foundation under grant number 2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.