Recognition: 2 theorem links
· Lean TheoremSignMAE: Segmentation-Driven Self-Supervised Learning for Sign Language Recognition
Pith reviewed 2026-05-08 19:16 UTC · model grok-4.3
The pith
Segmentation-driven masking in self-supervised pretraining yields state-of-the-art sign language recognition with fewer frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
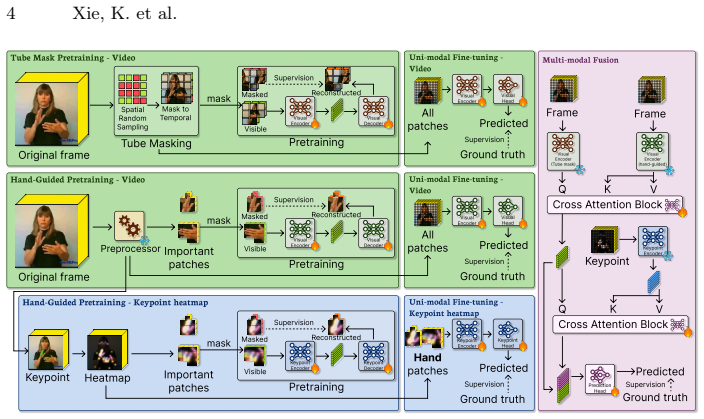
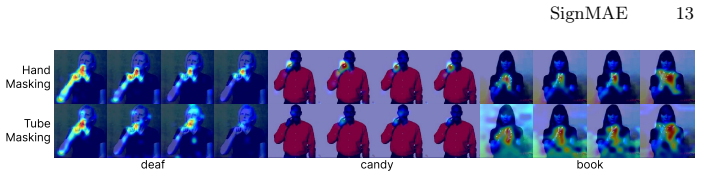
The central claim is that segmentation-based masking within a mask-and-reconstruct self-supervised framework adapts to the motion of critical body parts in sign language videos. This produces encoders that better represent subtle sign differences than those from generic pretraining. On the WLASL, NMFs-CSL, and Slovo datasets the method sets new state-of-the-art results for per-instance and per-class Top-1 accuracy while using fewer frames and modalities.
What carries the argument
The segmentation-guided masking process that informs the mask-and-reconstruct objective for learning sign-specific representations.
If this is right
- The encoder reaches state-of-the-art accuracy on WLASL, NMFs-CSL, and Slovo.
- Performance improves for both per-instance and per-class Top-1 metrics.
- The model works with fewer input frames and modalities than prior encoders.
Where Pith is reading between the lines
- This masking strategy may help in other tasks involving detailed human motion like dance or sports analysis.
- It points toward pretraining techniques that incorporate domain-specific priors such as body segmentation without needing full supervision.
- The efficiency gains suggest viability for deployment in resource-limited settings like mobile sign translation apps.
Load-bearing premise
Segmentation of body parts accurately identifies the regions whose detailed motion carries the meaning of each sign, and reconstructing those masked regions forces the model to learn more useful features than alternative pretraining methods.
What would settle it
An ablation study that replaces the segmentation-based masking with random masking or with masking derived from generic action pretraining and checks whether the accuracy advantage on the sign recognition benchmarks vanishes.
Figures

read the original abstract
Subtle hand differences make sign language recognition challenging, yet many existing methods rely on encoders pretrained on generic action datasets that poorly capture such fine-grained cues. We propose a self-supervised pretraining method for sign language recognition that uses segmentation-based masking to adapt to the presence and motion of key body parts, rather than treating hand poses as static visual tokens. The resulting mask-and-reconstruct objective improves fine-grained sign representation learning. On WLASL, NMFs-CSL, and Slovo, our encoder achieves state-of-the-art performance, improving per-instance and per-class Top-1 accuracy while using fewer input frames and modalities than comparable encoders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SignMAE, a self-supervised pretraining method for sign language recognition that employs segmentation-based masking to adapt to the presence and motion of key body parts such as hands. This mask-and-reconstruct objective is claimed to improve fine-grained sign representation learning. The method achieves state-of-the-art per-instance and per-class Top-1 accuracy on the WLASL, NMFs-CSL, and Slovo datasets, while using fewer input frames and modalities than comparable encoders.
Significance. If the reported gains can be attributed to the segmentation-driven masking strategy, this work could significantly advance self-supervised learning for sign language by providing a way to focus pretraining on subtle, fine-grained cues that generic action pretraining misses. This has potential implications for improving accessibility technologies and reducing the need for extensive labeled data in sign language recognition.
major comments (2)
- [Experimental Results] The central claim that segmentation-based masking directly causes the SOTA improvements requires an ablation study that fixes the pretraining corpus, model architecture, input modalities, and fine-tuning protocol while only changing the masking strategy from segmentation-driven to random or uniform. No such controlled experiment is described, leaving open the possibility that gains stem from sign-language-specific pretraining data or other unisolated factors.
- [Abstract] The abstract states improvements 'while using fewer input frames and modalities' but does not specify the exact frame counts or modalities used by the proposed method versus the baselines, making it difficult to assess the resource efficiency claim.
minor comments (1)
- Ensure that all baseline implementations are detailed with hyperparameters to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Experimental Results] The central claim that segmentation-based masking directly causes the SOTA improvements requires an ablation study that fixes the pretraining corpus, model architecture, input modalities, and fine-tuning protocol while only changing the masking strategy from segmentation-driven to random or uniform. No such controlled experiment is described, leaving open the possibility that gains stem from sign-language-specific pretraining data or other unisolated factors.
Authors: We agree that a controlled ablation isolating only the masking strategy is necessary to substantiate the central claim. While our experiments compare against other self-supervised baselines, they do not hold the pretraining corpus, architecture, modalities, and fine-tuning protocol completely fixed while varying only the masking approach. In the revised manuscript, we will add this ablation study using the same sign-language pretraining data and model setup for both segmentation-driven and random masking, reporting the resulting differences in downstream recognition accuracy. revision: yes
-
Referee: [Abstract] The abstract states improvements 'while using fewer input frames and modalities' but does not specify the exact frame counts or modalities used by the proposed method versus the baselines, making it difficult to assess the resource efficiency claim.
Authors: We thank the referee for highlighting this lack of specificity. We will revise the abstract to explicitly state the input frame counts and modalities employed by SignMAE (e.g., 16 frames with RGB and pose) alongside the corresponding values for the compared baselines, thereby clarifying the efficiency advantages. revision: yes
Circularity Check
No significant circularity; standard self-supervised reconstruction with novel masking heuristic
full rationale
The paper introduces a segmentation-driven masking strategy within a standard masked autoencoder (MAE) pretraining framework for sign language videos. The claimed improvement in fine-grained representations is evaluated via downstream accuracy on WLASL, NMFs-CSL, and Slovo benchmarks after finetuning. No equations or results reduce by construction to fitted parameters defined by the target metric; the masking heuristic is an input choice, not derived from the evaluation outcomes. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the central claims. The derivation chain (pretrain with custom masks → finetune encoder → report Top-1) remains independent of the reported numbers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reconstruction of masked segments teaches fine-grained motion and shape features useful for sign classification
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (Jcost = ½(x+x⁻¹)−1)Jcost_unit0 / cost_alpha_one_eq_jcost unclearL = (1/Ω) Σ |I(p) − Î(p)|² ... mean squared error loss based only on masked patches
Reference graph
Works this paper leans on
- [1]
-
[2]
In: Proceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision Workshops
Boháček, M., Hrúz, M.: Sign Pose-Based Transformer for Word-Level Sign Lan- guage Recognition. In: Proceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision Workshops. pp. 182–191 (2022)
2022
- [3]
-
[4]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021), https://arxiv.org/abs/2010.11929
work page Pith review arXiv 2021
- [5]
-
[6]
In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Hosain, A.A., Santhalingam, P.S., Pathak, P., Rangwala, H., Kosecka, J.: Hand Pose Guided 3D Pooling for Word-Level Sign Language Recognition. In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 3429–3439 (2021)
2021
- [7]
-
[8]
Proceedings of the AAAI Conference on Artificial Intelligence 35(2), 1558–1566 (May 2021)
Hu, H., Zhou, W., Li, H.: Hand-model-aware sign language recogni- tion. Proceedings of the AAAI Conference on Artificial Intelligence 35(2), 1558–1566 (May 2021). https://doi.org/10.1609/aaai.v35i2.16247, https://ojs.aaai.org/index.php/AAAI/article/view/16247
-
[9]
ACM Transactions on Multi- media Computing, Communications, and Applications17(3), 1–19 (2021)
Hu, H., Zhou, W., Pu, J., Li, H.: Global-Local Enhancement Network for NMF-Aware Sign Language Recognition. ACM Transactions on Multi- media Computing, Communications, and Applications17(3), 1–19 (2021). https://doi.org/10.1145/3436754, http://dx.doi.org/10.1145/3436754
- [10]
-
[11]
Jiang, S., Sun, B., Wang, L., Bai, Y., Li, K., Fu, Y.: Skeleton Aware Multi-Modal SignLanguageRecognition.In:ProceedingsoftheIEEE/CVFConferenceonCom- puter Vision and Pattern Recognition Workshops. pp. 3413–3423 (2021) SignMAE 15
2021
-
[12]
Kapitanov, A., Karina, K., Nagaev, A., Elizaveta, P.: Slovo: Russian Sign Language Dataset, p. 63–73. Springer Nature Switzerland (2023). https://doi.org/10.1007/978-3-031-44137-0_6, http://dx.doi.org/10.1007/978-3- 031-44137-0_6
-
[13]
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., Suleyman, M., Zisserman, A.: The kinetics human action video dataset (2017), https://arxiv.org/abs/1705.06950
work page internal anchor Pith review arXiv 2017
- [14]
- [15]
- [16]
- [17]
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Li, Y., Chen, X., Li, H., Pu, X., Jin, P., Ren, Y.: Vsnet: Focusing on the linguis- tic characteristics of sign language. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 24320–24330 (June 2025)
2025
- [19]
- [20]
-
[21]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization (2019), https://arxiv.org/abs/1711.05101
work page internal anchor Pith review arXiv 2019
- [22]
- [23]
-
[24]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops
Vazquez-Enriquez, M., Alba-Castro, J.L., Docio-Fernandez, L., Rodriguez-Banga, E.: Isolated Sign Language Recognition With Multi-Scale Spatial-Temporal Graph Convolutional Networks. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops. pp. 3462–3471 (2021)
2021
- [25]
-
[26]
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: mixup: Beyond empirical risk minimization (2018), https://arxiv.org/abs/1710.09412
work page internal anchor Pith review arXiv 2018
- [27]
- [28]
- [29]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.