Recognition: 3 theorem links
· Lean TheoremSharpness-Aware Pretraining Mitigates Catastrophic Forgetting
Pith reviewed 2026-05-08 18:28 UTC · model grok-4.3
The pith
Sharpness-aware pretraining produces base models that retain more capabilities after post-training and quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
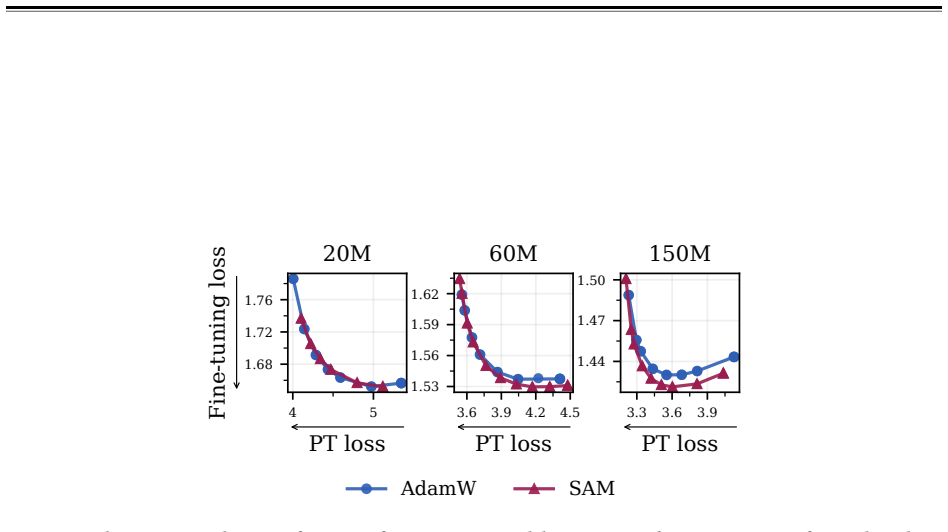
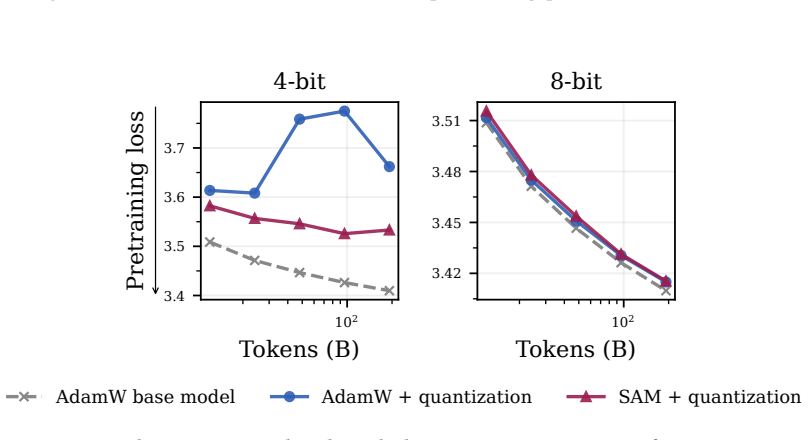
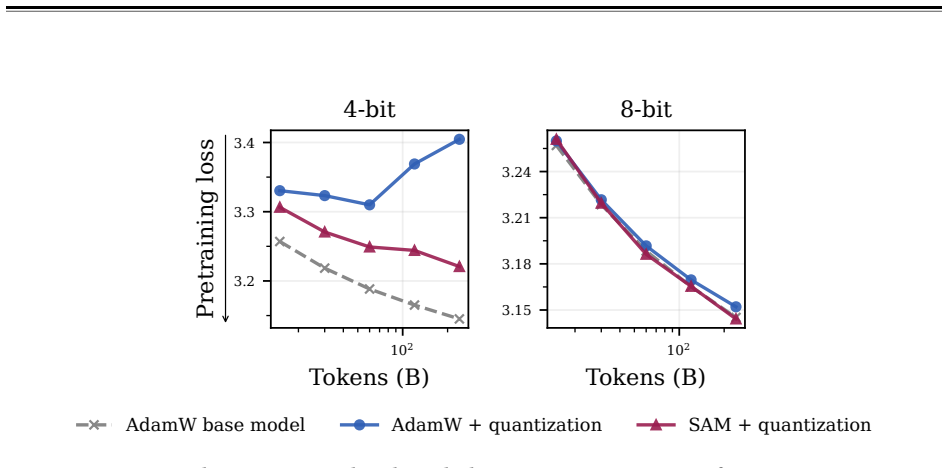
Pretraining optimization approaches that bias toward flatter minima—Sharpness-Aware Minimization (SAM), large learning rates, and shortened learning rate annealing periods—produce base models whose capabilities survive subsequent parameter updates better, leading to improved downstream performance with substantially less forgetting. Across model sizes ranging from 20M to 150M parameters, these interventions consistently improve downstream performance after post-training on five common datasets with up to 80% less forgetting. These principles hold at scale: a short SAM mid-training phase applied to an existing OLMo-2-1B checkpoint reduces forgetting by 31% after MetaMath post-training and by
What carries the argument
The flatness of the loss minimum reached during pretraining, achieved via SAM or related interventions, which governs how much of the base model's performance is preserved under later updates.
If this is right
- Base models trained with these methods show consistent downstream gains after post-training on multiple datasets.
- The retention benefit appears across scales from 20M to 150M parameters and extends to 1B-parameter models via a short mid-training phase.
- The same interventions reduce forgetting during both fine-tuning and quantization.
- A short SAM phase can be inserted into existing pretraining runs without restarting from scratch.
Where Pith is reading between the lines
- Standard pretraining may routinely converge to sharp minima that are unnecessarily fragile for the multi-stage pipelines now common in large models.
- The approach could be combined with other geometry-aware techniques such as weight averaging or regularization that also favor flat regions.
- If the effect scales further, it would imply that current scaling laws for pretraining compute may need adjustment to account for downstream retention rather than pretraining loss alone.
- The result suggests testing whether flatter base models also exhibit better zero-shot generalization before any post-training occurs.
Load-bearing premise
That flatter minima directly cause the observed retention gains rather than arising alongside other unmeasured factors in the training trajectory.
What would settle it
Train two base models to identical pretraining validation loss, one using SAM and one using standard optimization, then apply identical post-training and measure forgetting rates; equal rates would falsify the claim that flatness controls retention.
Figures

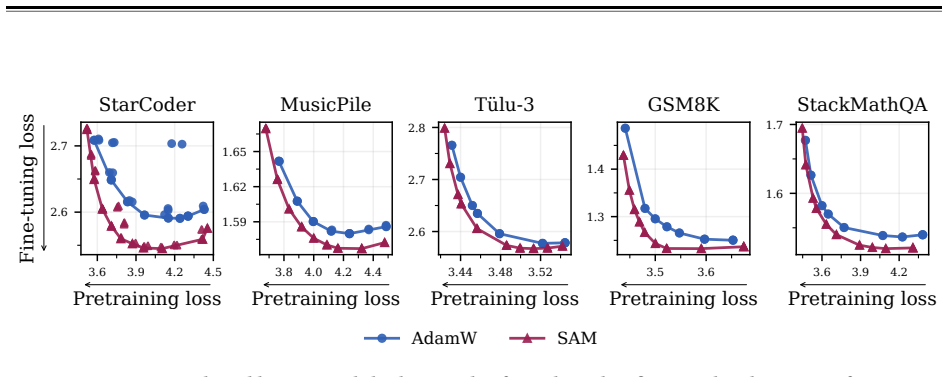
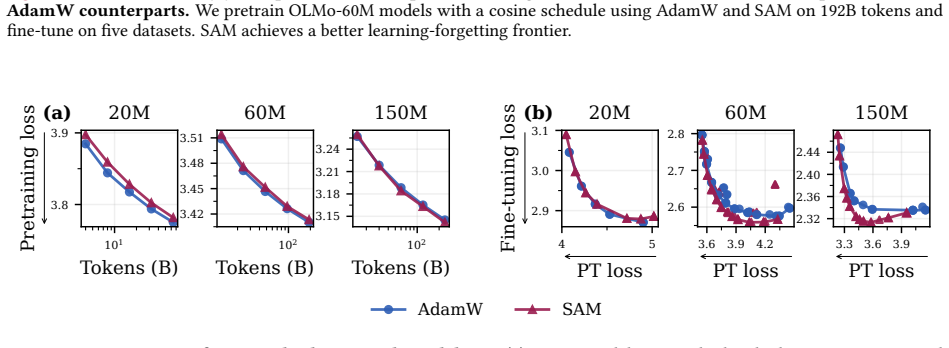

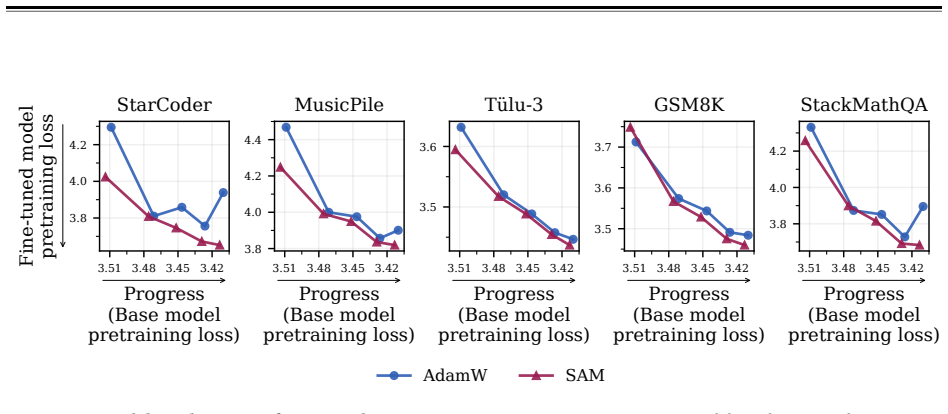
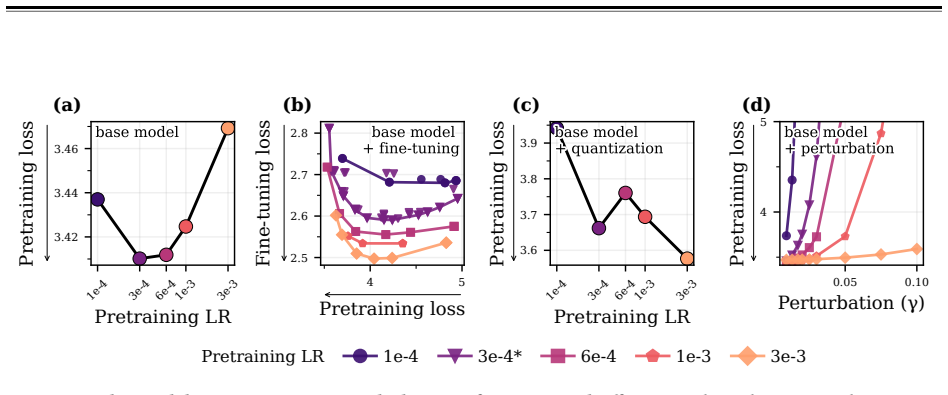








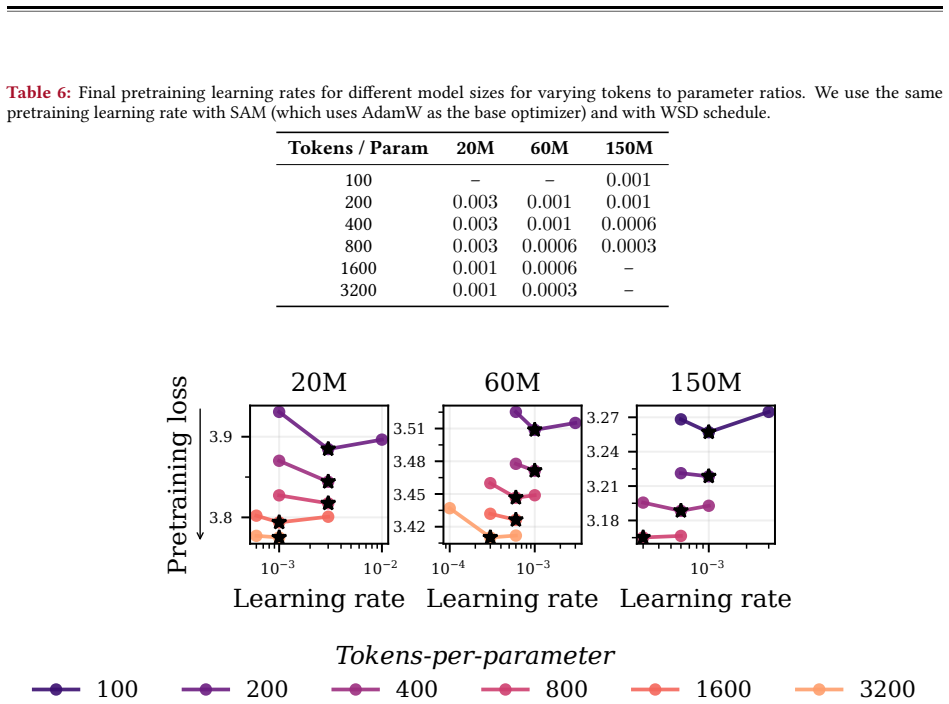






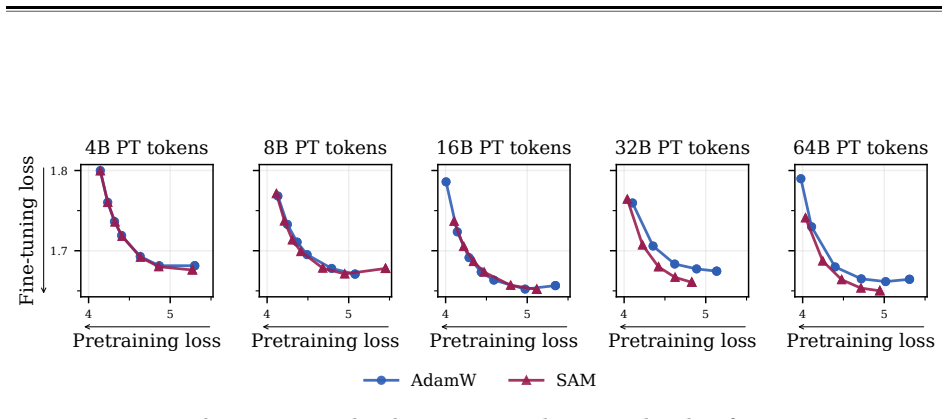
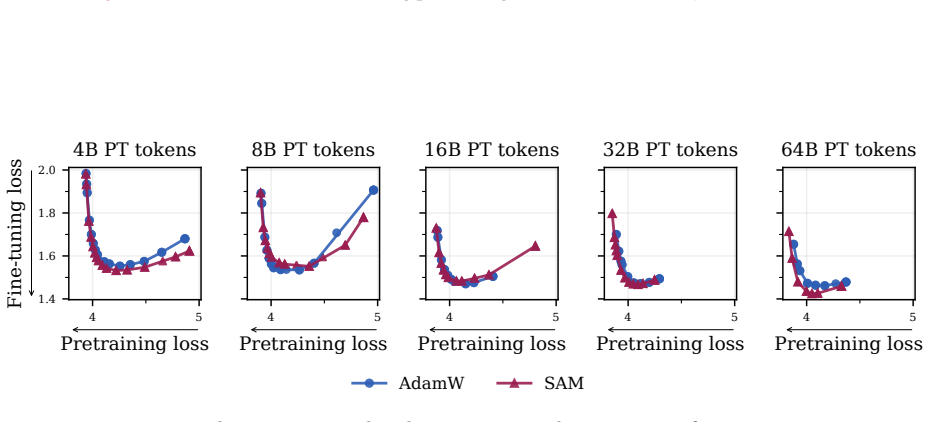
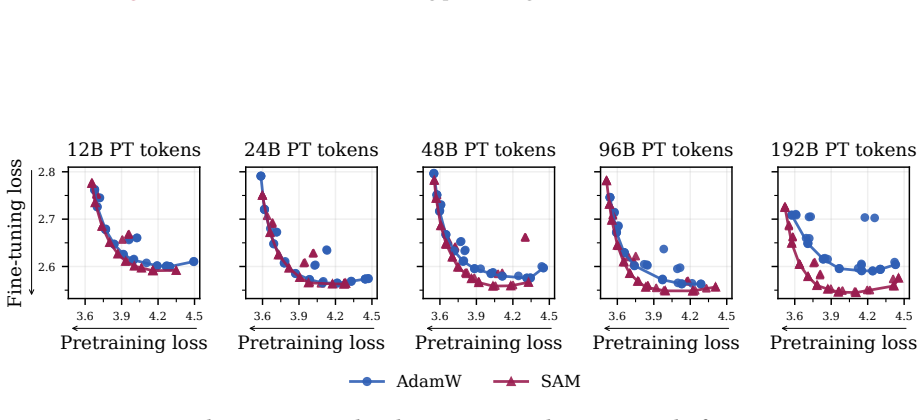




















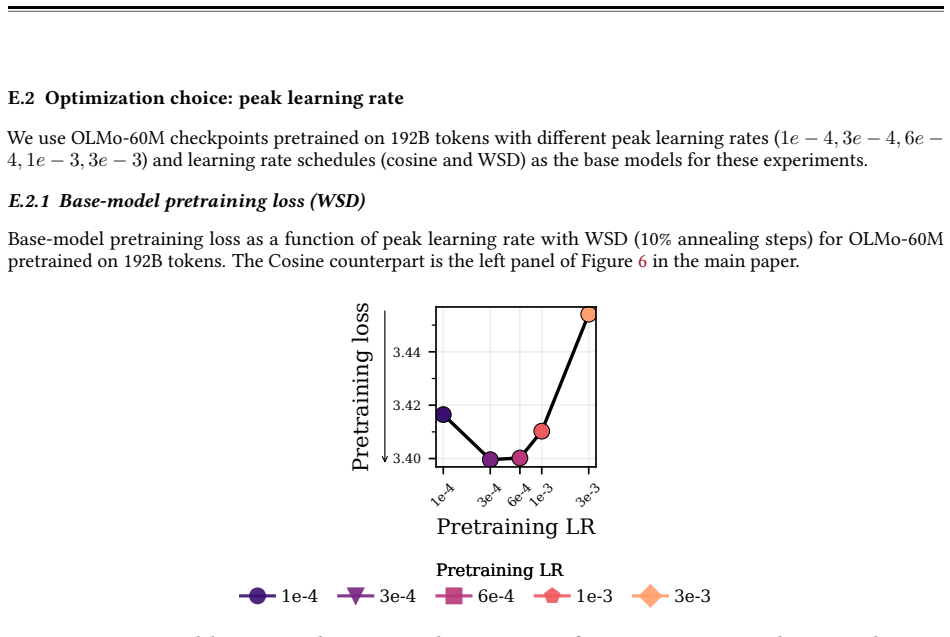





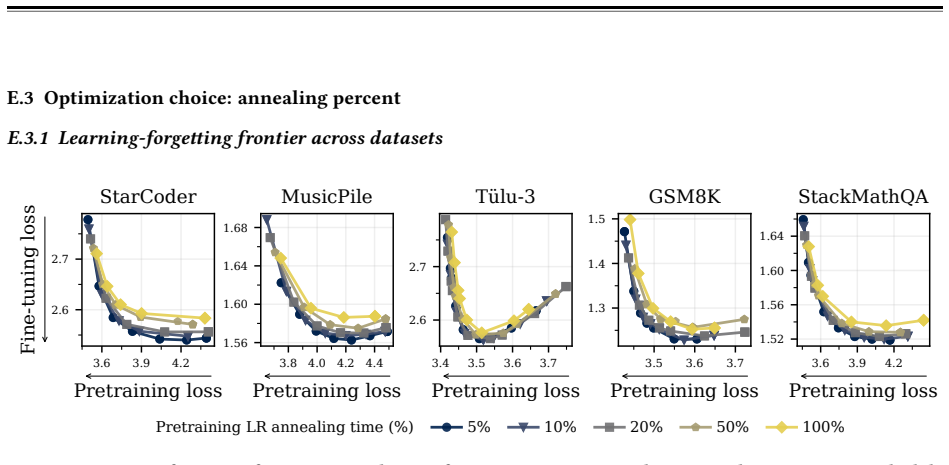
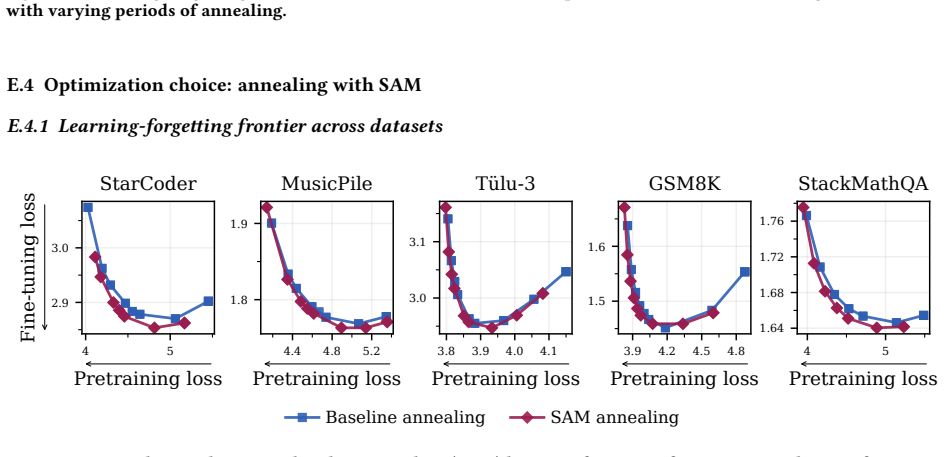


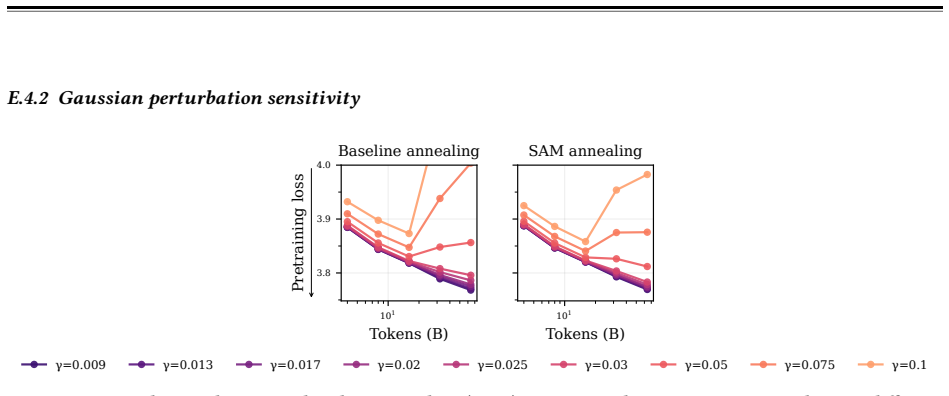
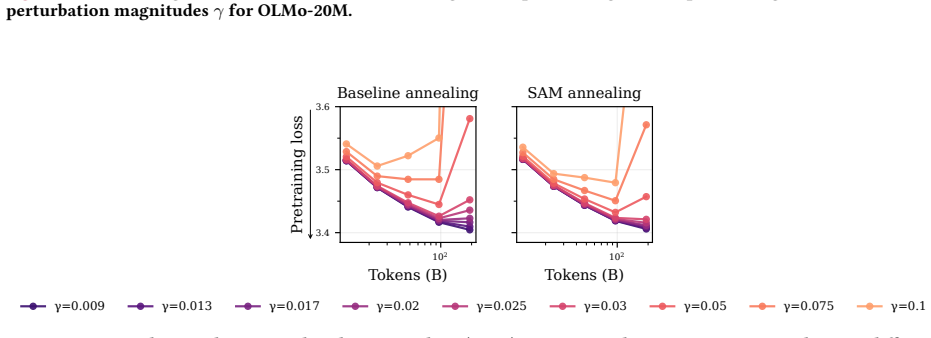


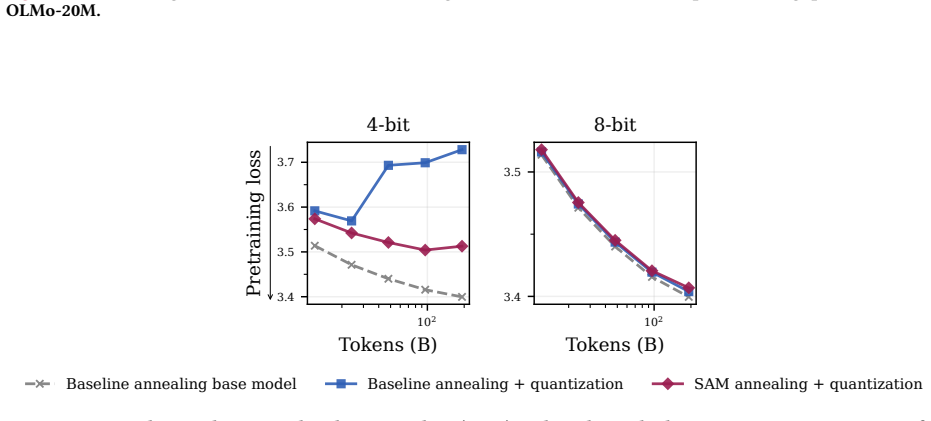
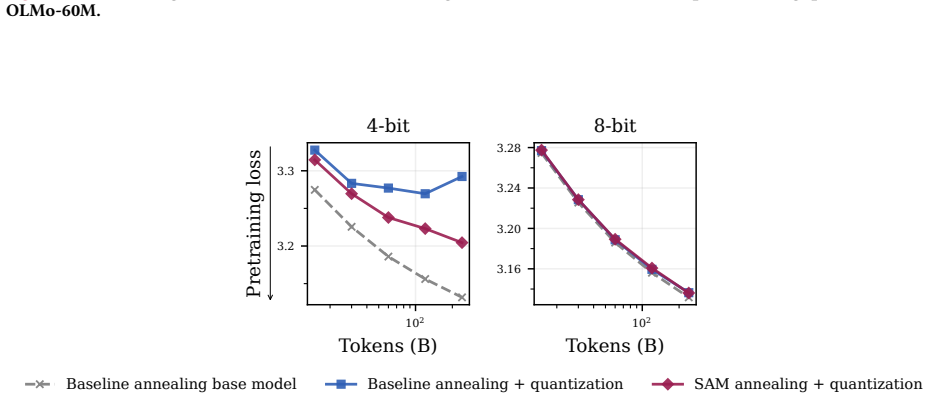
read the original abstract
Pretraining optimizers are tuned to produce the strongest possible base model, on the assumption that a stronger starting point yields a stronger model after subsequent changes like post-training and quantization. This overlooks the geometry of the base model which controls how much of the base model's capabilities survive subsequent parameter updates. We study three pretraining optimization approaches that bias optimization toward flatter minima: Sharpness-Aware Minimization (SAM), large learning rates, and shortened learning rate annealing periods. Across model sizes ranging from 20M to 150M parameters, we find that these interventions consistently improve downstream performance after post-training on five common datasets with up to 80% less forgetting. These principles hold at scale: a short SAM mid-training phase applied to an existing OLMo-2-1B checkpoint reduces forgetting by 31% after MetaMath post-training and by 40% after 4-bit quantization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
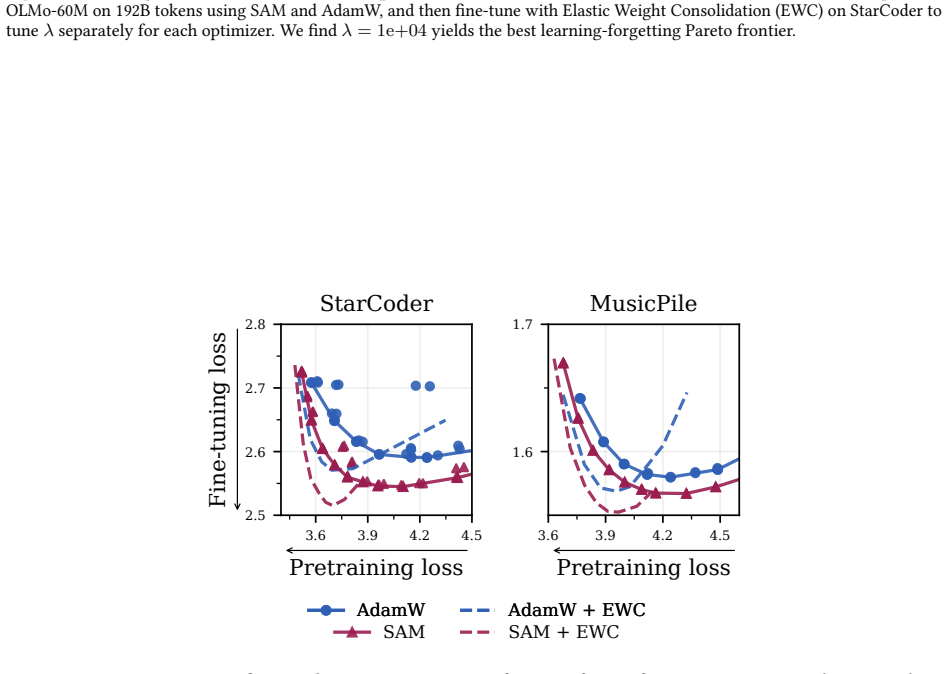
Summary. The paper claims that pretraining with Sharpness-Aware Minimization (SAM), large learning rates, or shortened annealing biases models toward flatter minima, which in turn reduces catastrophic forgetting during subsequent post-training and quantization. It reports consistent downstream gains across 20M–150M parameter models on five datasets (up to 80% less forgetting) and shows the approach scales to a 1B model, where a brief SAM mid-training phase cuts forgetting by 31% after MetaMath and 40% after 4-bit quantization.
Significance. If the central mechanism is isolated and the empirical gains replicate under standard controls, the result would be significant for LLM pretraining pipelines: it offers a low-cost way to improve base-model retention without changing post-training recipes, potentially affecting how large-scale checkpoints are produced and maintained.
major comments (3)
- [Abstract and §3] Abstract and §3 (Methods): the claim that the three interventions 'bias optimization toward flatter minima' is presented without any reported sharpness measurements (Hessian trace, SAM sharpness, or perturbation robustness) on the resulting checkpoints, so it is impossible to confirm that geometry, rather than correlated optimizer effects, drives the retention gains.
- [§4 and Table 2] §4 (Experiments) and Table 2: the 80% forgetting reduction is reported without statistical tests, explicit baseline definitions, or ablation tables that hold effective regularization and loss-curve shape fixed while varying only flatness; the 1B-scale mid-training result similarly lacks a direct comparison of sharpness before and after the SAM phase.
- [§5] §5 (Scaling): the statement that 'these principles hold at scale' rests on a single 1B checkpoint experiment; without multiple runs, variance estimates, or controls for the original OLMo-2 training recipe, the 31% and 40% reductions cannot be confidently attributed to the SAM intervention alone.
minor comments (2)
- [Figure 1 and §2] Figure 1 caption and §2: the notation for 'forgetting' is introduced without an explicit equation; adding a short definition (e.g., ΔAcc = Acc_base − Acc_post) would improve readability.
- [References] References: several recent works on sharpness-aware training for LLMs (e.g., 2023–2024 SAM variants) are not cited; adding them would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate additional evidence and controls where feasible.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods): the claim that the three interventions 'bias optimization toward flatter minima' is presented without any reported sharpness measurements (Hessian trace, SAM sharpness, or perturbation robustness) on the resulting checkpoints, so it is impossible to confirm that geometry, rather than correlated optimizer effects, drives the retention gains.
Authors: We agree that the original submission would have been strengthened by direct sharpness measurements to support the geometric interpretation. Although the three interventions are established in the literature as promoting flatter minima, we did not report explicit metrics such as Hessian trace or perturbation robustness. In the revised manuscript we have added these measurements (Hessian trace approximations and SAM sharpness) for the 20M–150M checkpoints in a new subsection of §3; the results confirm flatter landscapes and show correlation with the observed retention gains. For the 1B model we note the limitation below. revision: yes
-
Referee: [§4 and Table 2] §4 (Experiments) and Table 2: the 80% forgetting reduction is reported without statistical tests, explicit baseline definitions, or ablation tables that hold effective regularization and loss-curve shape fixed while varying only flatness; the 1B-scale mid-training result similarly lacks a direct comparison of sharpness before and after the SAM phase.
Authors: We accept that additional statistical rigor and controls are warranted. The revised §4 now includes paired statistical tests across random seeds for the reported forgetting reductions, clearer baseline definitions, and a new ablation table that holds regularization strength and loss-curve shape approximately fixed while varying the flatness-inducing factors. For the 1B mid-training result we have added a direct before/after sharpness comparison using the same metrics introduced in §3. revision: yes
-
Referee: [§5] §5 (Scaling): the statement that 'these principles hold at scale' rests on a single 1B checkpoint experiment; without multiple runs, variance estimates, or controls for the original OLMo-2 training recipe, the 31% and 40% reductions cannot be confidently attributed to the SAM intervention alone.
Authors: We acknowledge that a single 1B-scale experiment limits the strength of the scaling claim. The revised §5 now explicitly discusses this limitation, provides available variance estimates from the smaller-scale runs, and clarifies the controls relative to the original OLMo-2 recipe. We were unable to obtain multiple independent 1B pretraining runs. revision: partial
- Obtaining multiple independent full 1B-scale pretraining runs (or additional 1B checkpoints) to supply variance estimates and stronger controls, which exceeds available computational resources.
Circularity Check
No circularity: purely empirical measurements of retention gains
full rationale
The paper reports experimental results comparing pretraining interventions (SAM, large LR, shortened annealing) on downstream forgetting after post-training and quantization. No mathematical derivation, first-principles prediction, or equation chain exists that could reduce to fitted inputs or self-citations. Claims rest on measured performance deltas across model scales (20M-150M and 1B), not on any self-referential definition or imported uniqueness theorem. Self-citations, if present, are not load-bearing for the central empirical finding.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.LogicAsFunctionalEquationwashburn_uniqueness_aczel (J = ½(x+x⁻¹)−1) unclearL(θ+Δ) ≈ L(θ) + ∇L(θ)ᵀΔ + ½ΔᵀHΔ … forgetting is determined by … the distance moved ‖Δ_FT‖² and the curvature in the direction of fine-tuning κ(Δ_FT; H).
-
Foundation.BranchSelection / Foundation.AlphaCoordinateFixationRCLCombiner_isCoupling_iff; alpha_pin_under_high_calibration unclearSAM with a batch size of 1 is thought to minimize the trace of the Hessian … full-batch SAM tracks the worst-case directional curvature λ_max(H).
Reference graph
Works this paper leans on
-
[1]
Forty-second International Conference on Machine Learning , year=
Overtrained Language Models Are Harder to Fine-Tune , author=. Forty-second International Conference on Machine Learning , year=
-
[2]
Editing Conceptual Knowledge for Large Language Models
Wang, Xiaohan and Mao, Shengyu and Deng, Shumin and Yao, Yunzhi and Shen, Yue and Liang, Lei and Gu, Jinjie and Chen, Huajun and Zhang, Ningyu. Editing Conceptual Knowledge for Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.40
-
[3]
doi: 10.18653/V1/2021.EMNLP-MAIN.522
De Cao, Nicola and Aziz, Wilker and Titov, Ivan. Editing Factual Knowledge in Language Models. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.522
-
[4]
Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A
Dohare, Shibhansh and Hernandez-Garcia, J. Fernando and Lan, Qingfeng and Rahman, Parash and Mahmood, A. Rupam and Sutton, Richard S. , title =. Nature , year =. doi:10.1038/s41586-024-07711-7 , url =
-
[5]
Lee , title =
Alex Damian and Eshaan Nichani and Jason D. Lee , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[6]
Make Continual Learning Stronger via C-Flat , url =
Bian, Ang and Li, Wei and Yuan, Hangjie and Yu, Chengrong and Wang, Mang and Zhao, Zixiang and Lu, Aojun and Ji, Pengliang and Feng, Tao , booktitle =. Make Continual Learning Stronger via C-Flat , url =. doi:10.52202/079017-0244 , editor =
-
[7]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[8]
2026 , eprint=
Olmo 3 , author=. 2026 , eprint=
2026
-
[9]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi and Eunsol Choi and Daniel S. Weld and Luke Zettlemoyer , title =. CoRR , volume =. 2017 , url =. 1705.03551 , timestamp =
work page internal anchor Pith review arXiv 2017
-
[10]
2024 , eprint=
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark , author=. 2024 , eprint=
2024
-
[11]
2023 , eprint=
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models , author=. 2023 , eprint=
2023
-
[12]
Transactions of the Association for Computational Linguistics , author =
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[13]
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Dheeru Dua and Yizhong Wang and Pradeep Dasigi and Gabriel Stanovsky and Sameer Singh and Matt Gardner , title =. CoRR , volume =. 2019 , url =. 1903.00161 , timestamp =
work page Pith review arXiv 2019
-
[14]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Keisuke Sakaguchi and Ronan Le Bras and Chandra Bhagavatula and Yejin Choi , title =. CoRR , volume =. 2019 , url =. 1907.10641 , timestamp =
work page internal anchor Pith review arXiv 2019
-
[15]
Measuring Massive Multitask Language Understanding
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. CoRR , volume =. 2020 , url =. 2009.03300 , timestamp =
work page internal anchor Pith review arXiv 2020
-
[16]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , title =. CoRR , volume =. 2019 , url =. 1905.07830 , timestamp =
work page internal anchor Pith review arXiv 2019
-
[17]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark and Kenton Lee and Ming. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , journal =. 2019 , url =. 1905.10044 , timestamp =
work page internal anchor Pith review arXiv 2019
-
[18]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. CoRR , volume =. 2018 , url =. 1803.05457 , timestamp =
work page Pith review arXiv 2018
-
[19]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , author=. arXiv preprint arXiv:2309.12284 , year=
work page internal anchor Pith review arXiv
-
[20]
The Fourteenth International Conference on Learning Representations , year=
Training Dynamics Impact Post-Training Quantization Robustness , author=. The Fourteenth International Conference on Learning Representations , year=
-
[21]
2025 , eprint=
Sharpness-Aware Minimization Efficiently Selects Flatter Minima Late in Training , author=. 2025 , eprint=
2025
-
[22]
The Fourteenth International Conference on Learning Representations , year=
How does the optimizer implicitly bias the model merging loss landscape? , author=. The Fourteenth International Conference on Learning Representations , year=
-
[23]
Maksym Andriushchenko and Aditya Vardhan Varre and Loucas Pillaud-Vivien and Nicolas Flammarion , year=
-
[24]
Yuanzhi Li and Colin Wei and Tengyu Ma , title =. CoRR , volume =. 2019 , url =. 1907.04595 , timestamp =
-
[25]
2024 , eprint=
Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning , author=. 2024 , eprint=
2024
-
[26]
Sharpness Minimization Algorithms Do Not Only Minimize Sharpness To Achieve Better Generalization , url =
Wen, Kaiyue and Li, Zhiyuan and Ma, Tengyu , booktitle =. Sharpness Minimization Algorithms Do Not Only Minimize Sharpness To Achieve Better Generalization , url =
-
[27]
2023 , eprint=
How Does Sharpness-Aware Minimization Minimize Sharpness? , author=. 2023 , eprint=
2023
-
[28]
2023 , eprint=
Sharpness-Aware Training for Free , author=. 2023 , eprint=
2023
-
[29]
2022 , eprint=
Surrogate Gap Minimization Improves Sharpness-Aware Training , author=. 2022 , eprint=
2022
-
[30]
ASAM: adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks
Jungmin Kwon and Jeongseop Kim and Hyunseo Park and In Kwon Choi , title =. CoRR , volume =. 2021 , url =. 2102.11600 , timestamp =
-
[31]
Entropy-sgd: Biasing gradient descent into wide valleys
Pratik Chaudhari and Anna Choromanska and Stefano Soatto and Yann LeCun and Carlo Baldassi and Christian Borgs and Jennifer T. Chayes and Levent Sagun and Riccardo Zecchina , title =. CoRR , volume =. 2016 , url =. 1611.01838 , timestamp =
-
[32]
Proceedings of the National Academy of Sciences , volume =
Carlo Baldassi and Fabrizio Pittorino and Riccardo Zecchina , title =. Proceedings of the National Academy of Sciences , volume =. 2020 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.1908636117 , abstract =
-
[33]
International Conference on Learning Representations , year=
Fantastic Generalization Measures and Where to Find Them , author=. International Conference on Learning Representations , year=
-
[34]
2023 , eprint=
A Modern Look at the Relationship between Sharpness and Generalization , author=. 2023 , eprint=
2023
-
[35]
2022 , eprint=
Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models , author=. 2022 , eprint=
2022
-
[36]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[37]
International Conference on Learning Representations , year=
Sharpness-aware Minimization for Efficiently Improving Generalization , author=. International Conference on Learning Representations , year=
-
[38]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[39]
The Twelfth International Conference on Learning Representations , year=
Understanding Catastrophic Forgetting in Language Models via Implicit Inference , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
2026 , eprint=
Replaying pre-training data improves fine-tuning , author=. 2026 , eprint=
2026
-
[41]
2025 , eprint=
OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling , author=. 2025 , eprint=
2025
-
[42]
International Conference on Learning Representations , year=
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability , author=. International Conference on Learning Representations , year=
-
[43]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[44]
Shengding Hu and Yuge Tu and Xu Han and Ganqu Cui and Chaoqun He and Weilin Zhao and Xiang Long and Zhi Zheng and Yewei Fang and Yuxiang Huang and Xinrong Zhang and Zhen Leng Thai and Chongyi Wang and Yuan Yao and Chenyang Zhao and Jie Zhou and Jie Cai and Zhongwu Zhai and Ning Ding and Chao Jia and Guoyang Zeng and dahai li and Zhiyuan Liu and Maosong Su...
2024
-
[45]
The Thirteenth International Conference on Learning Representations , year=
Scaling Laws for Precision , author=. The Thirteenth International Conference on Learning Representations , year=
-
[46]
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , year=. Overcoming catastrophic forgetting in neural networks , vol...
-
[47]
2017 , eprint=
Continual Learning with Deep Generative Replay , author=. 2017 , eprint=
2017
-
[48]
2019 , eprint=
Episodic Memory in Lifelong Language Learning , author=. 2019 , eprint=
2019
-
[49]
Scaling Optimal
Johan Bjorck and Alon Benhaim and Vishrav Chaudhary and Furu Wei and Xia Song , booktitle=. Scaling Optimal. 2025 , url=
2025
-
[50]
2020 , eprint=
On Warm-Starting Neural Network Training , author=. 2020 , eprint=
2020
-
[51]
2022 , eprint=
The Primacy Bias in Deep Reinforcement Learning , author=. 2022 , eprint=
2022
-
[52]
Hochreiter, Sepp and Schmidhuber, J\". Flat minima , year =. doi:10.1162/neco.1997.9.1.1 , journal =
-
[53]
2017 , eprint=
SGDR: Stochastic Gradient Descent with Warm Restarts , author=. 2017 , eprint=
2017
-
[54]
2023 , eprint=
A Model or 603 Exemplars: Towards Memory-Efficient Class-Incremental Learning , author=. 2023 , eprint=
2023
-
[55]
2026 , eprint=
Midtraining Bridges Pretraining and Posttraining Distributions , author=. 2026 , eprint=
2026
-
[56]
Don`t Stop Pretraining: Adapt Language Models to Domains and Tasks
Gururangan, Suchin and Marasovi \'c , Ana and Swayamdipta, Swabha and Lo, Kyle and Beltagy, Iz and Downey, Doug and Smith, Noah A. Don ' t Stop Pretraining: Adapt Language Models to Domains and Tasks. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.740
-
[57]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Mitigating Plasticity Loss in Continual Reinforcement Learning by Reducing Churn , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[58]
Journal of Machine Learning Research , year =
Sanket Vaibhav Mehta and Darshan Patil and Sarath Chandar and Emma Strubell , title =. Journal of Machine Learning Research , year =
-
[59]
Guoxiong Gao, Haocheng Ju, Jiedong Jiang, Zihan Qin, and Bin Dong
Robert M. French , keywords =. Catastrophic forgetting in connectionist networks , journal =. 1999 , issn =. doi:https://doi.org/10.1016/S1364-6613(99)01294-2 , url =
-
[60]
Jeffrey Li and Alex Fang and Georgios Smyrnis and Maor Ivgi and Matt Jordan and Samir Yitzhak Gadre and Hritik Bansal and Etash Kumar Guha and Sedrick Keh and Kushal Arora and Saurabh Garg and Rui Xin and Niklas Muennighoff and Reinhard Heckel and Jean Mercat and Mayee F Chen and Suchin Gururangan and Mitchell Wortsman and Alon Albalak and Yonatan Bitton ...
2024
-
[61]
2024 , eprint=
OLMo: Accelerating the Science of Language Models , author=. 2024 , eprint=
2024
-
[62]
2023 , eprint=
StarCoder: may the source be with you! , author=. 2023 , eprint=
2023
-
[63]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[64]
Zhang, Yifan , year=
-
[65]
2025 , eprint=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. 2025 , eprint=
2025
-
[66]
2024 , eprint=
ChatMusician: Understanding and Generating Music Intrinsically with LLM , author=. 2024 , eprint=
2024
-
[67]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale , author=. arXiv preprint arXiv:2208.07339 , year=
work page internal anchor Pith review arXiv
-
[68]
QLoRA: Efficient Finetuning of Quantized LLMs
Qlora: Efficient finetuning of quantized llms , author=. arXiv preprint arXiv:2305.14314 , year=
work page internal anchor Pith review arXiv
-
[69]
An empirical investigation of catastrophic forgetting in gradient-based neural networks , author=. arXiv preprint arXiv:1312.6211 , year=
-
[70]
International conference on machine learning , pages=
Continual learning through synaptic intelligence , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[71]
Proceedings of the European conference on computer vision (ECCV) , pages=
Memory aware synapses: Learning what (not) to forget , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[72]
Advances in neural information processing systems , volume=
Gradient episodic memory for continual learning , author=. Advances in neural information processing systems , volume=
-
[73]
Efficient Lifelong Learning with A-GEM
Efficient lifelong learning with a-gem , author=. arXiv preprint arXiv:1812.00420 , year=
-
[74]
Progressive neural networks , author=. arXiv preprint arXiv:1606.04671 , year=
work page internal anchor Pith review arXiv
-
[75]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
On large-batch training for deep learning: Generalization gap and sharp minima , author=. arXiv preprint arXiv:1609.04836 , year=
work page internal anchor Pith review arXiv
-
[76]
International Conference on Machine Learning , pages=
Sharp minima can generalize for deep nets , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[77]
Understanding warmup-stable-decay learning rates: A river valley loss landscape perspective , author=. arXiv preprint arXiv:2410.05192 , year=
-
[78]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Robust fine-tuning of zero-shot models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[79]
International conference on machine learning , pages=
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[80]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Gptq: Accurate post-training quantization for generative pre-trained transformers , author=. arXiv preprint arXiv:2210.17323 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.