Recognition: no theorem link
FedQueue: Queue-Aware Federated Learning for Cross-Facility HPC Training
Pith reviewed 2026-05-12 04:27 UTC · model grok-4.3
The pith
FedQueue predicts HPC queue delays to budget local work, bound update staleness with cutoffs, and stabilize aggregation for non-convex federated learning across facilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
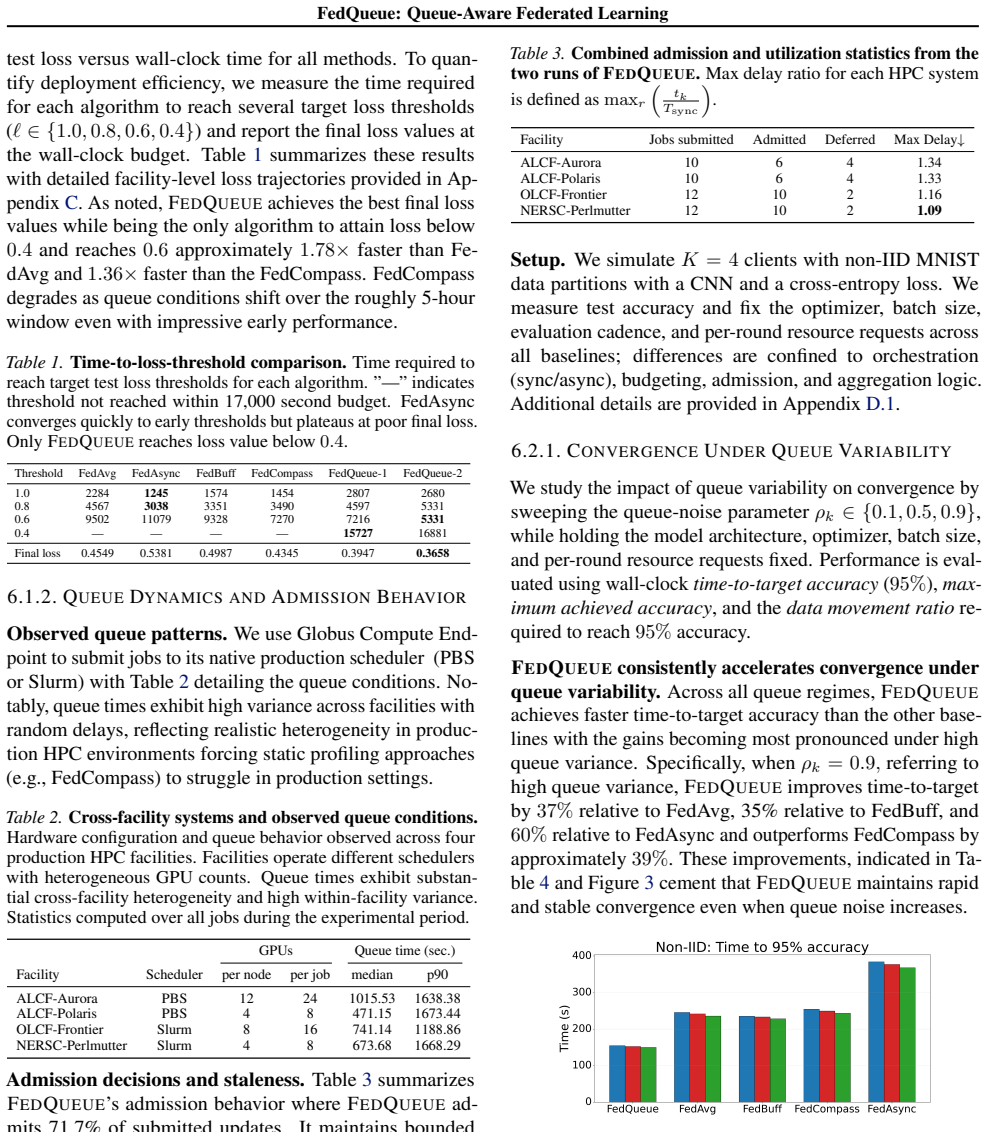
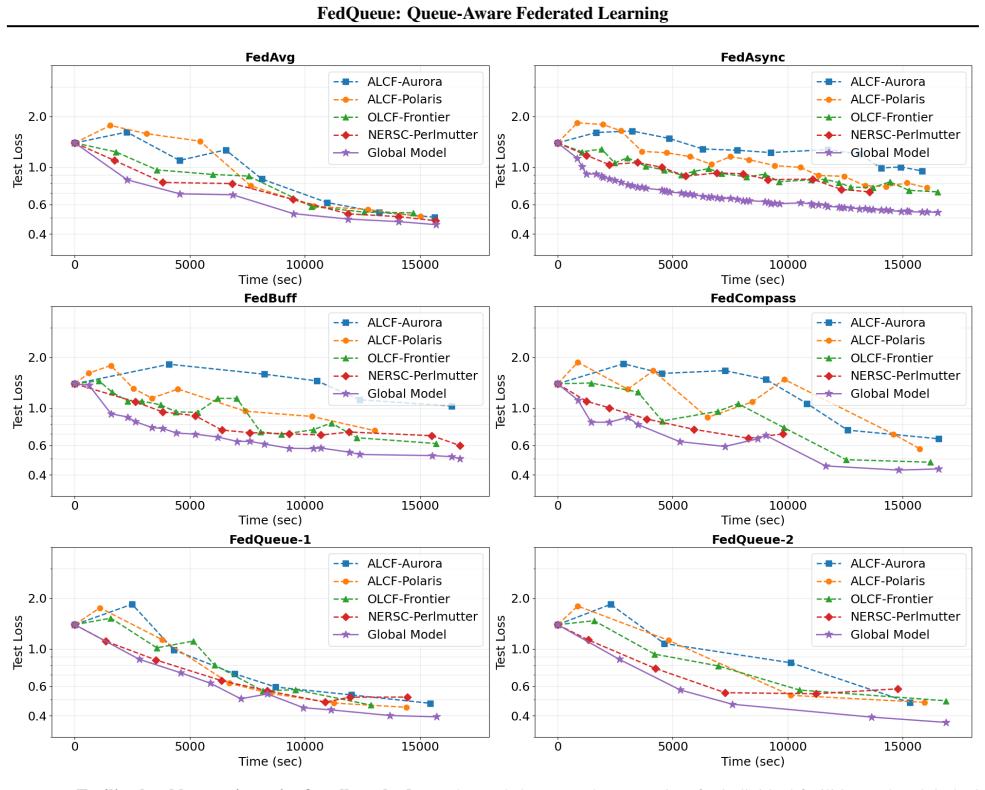
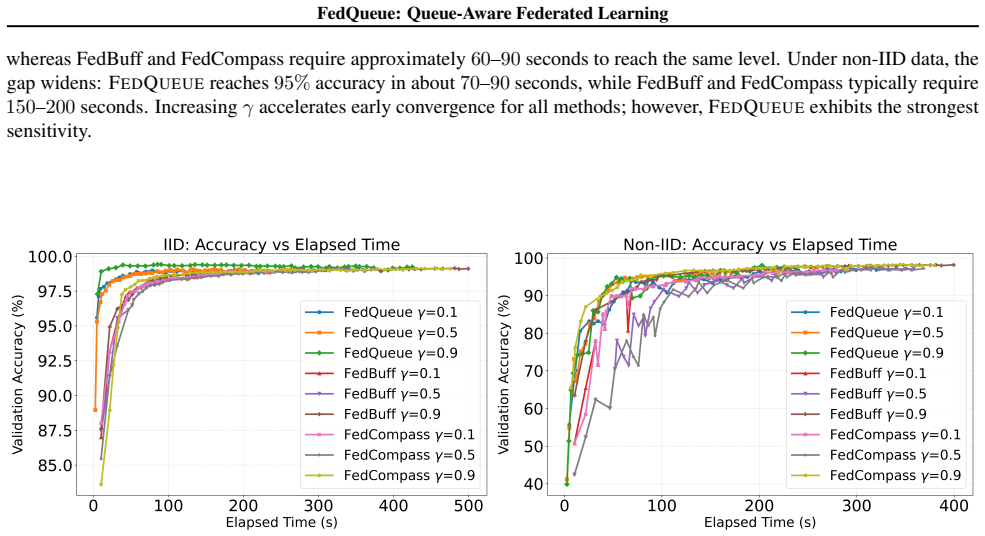
FedQueue predicts per-facility queue delays online to budget local work, applies cutoff-based admission that buffers late arrivals to bound staleness, and performs staleness-aware aggregation to stabilize heterogeneous local workloads. It proves convergence for non-convex objectives at rate O(1/sqrt(R)) under bounded staleness and shows that the admission controls yield bounded staleness with high probability under queue-prediction error. Real-world cross-facility deployment shows 20.5 percent improvement over baseline algorithms while controlled simulations demonstrate about 34 percent reduction in time to reach a target accuracy level under high queue variance and non-IID partitions.
What carries the argument
The FedQueue protocol that integrates online queue-delay prediction for local-work budgeting, cutoff-based admission control to bound staleness, and staleness-aware aggregation for heterogeneous workloads.
If this is right
- Convergence for non-convex objectives holds at O(1/sqrt(R)) whenever staleness remains bounded.
- Cutoff admission yields bounded staleness with high probability even when queue predictions contain error.
- Real cross-facility training reaches target accuracy with 20.5 percent less wall-clock time than standard baselines.
- Under high queue variance and non-IID data the method reduces time to target accuracy by about 34 percent.
Where Pith is reading between the lines
- Similar delay-prediction and cutoff mechanisms could be adapted to federated training on cloud clusters where job start times are also stochastic.
- The bounded-staleness guarantee may allow tighter theoretical rates if queue predictions are shown to improve over time through online learning.
- The approach suggests that explicit modeling of scheduler state can replace reliance on fully synchronous or fully asynchronous protocols in other distributed optimization settings.
Load-bearing premise
Queue delays can be predicted online with accuracy sufficient to keep staleness bounded with high probability.
What would settle it
A cross-facility run in which measured queue-prediction error exceeds the level assumed in the analysis and the maximum observed update staleness grows without bound, causing the measured convergence rate to deviate from O(1/sqrt(R)).
Figures





read the original abstract
Federated learning (FL) across multiple HPC facilities faces stochastic admission delays from batch schedulers that dominate wall-clock time. Synchronous FL suffers from severe stragglers, while asynchronous FL accumulates stale updates when queues spike. We propose FedQueue, a queue-aware FL protocol that incorporates scheduler delays directly into training and aggregation, which (i) predicts per-facility queue delays online to budget local work, (ii) applies cutoff-based admission that buffers late arrivals to bound staleness, and (iii) performs staleness-aware aggregation to stabilize heterogeneous local workloads. We prove the convergence for non-convex objectives at rate $\mathcal{O}(1/\sqrt{R})$ under bounded staleness, and show that the admission controls yield bounded staleness with high probability under queue-prediction error. Real-world cross-facility deployment of FedQueue shows 20.5% improvement over baseline algorithms. Controlled queue simulations demonstrate robust improvement over the baselines; in particular, about 34% reduction in time to reach a target accuracy level under high queue variance and non-IID partitions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FedQueue, a queue-aware federated learning protocol for cross-facility HPC environments. It predicts per-facility queue delays online to budget local work, applies cutoff-based admission to buffer late arrivals and bound staleness, and uses staleness-aware aggregation. The authors prove convergence for non-convex objectives at rate O(1/sqrt(R)) under bounded staleness, show that admission controls achieve bounded staleness w.h.p. under queue-prediction error, and report 20.5% improvement in real-world cross-facility deployment plus up to 34% reduction in time-to-accuracy under high queue variance and non-IID partitions in simulations.
Significance. If the convergence result and high-probability staleness bound hold under realistic HPC conditions, the work would be significant for enabling efficient federated training across heterogeneous facilities where scheduler delays dominate wall-clock time. The explicit handling of queue dynamics, combined with a non-convex convergence guarantee and real deployment results, addresses a practical gap in distributed ML on HPC systems.
major comments (2)
- [Section 4] Abstract and convergence analysis (Section 4): The O(1/sqrt(R)) rate for non-convex objectives is conditioned on bounded staleness, yet the high-probability argument that cutoff-based admission maintains this bound under queue-prediction error provides no explicit tail bounds on prediction error, no description of the online predictor (features or update rule), and no relation between cutoff thresholds and those errors; this makes it impossible to verify whether the rate survives the high-variance regimes used for the 34% time-to-accuracy claim.
- [Section 3.2] Admission control mechanism (Section 3.2): The claim that admission controls yield bounded staleness w.h.p. is load-bearing for both the theoretical guarantee and the reported gains over baselines, but the manuscript supplies neither the predictor's error model nor the tolerance used in the probability argument, leaving open the possibility that realistic HPC queue spikes violate the staleness assumption and invalidate the convergence rate.
minor comments (2)
- [Experiments] The experimental section would benefit from additional detail on the exact non-IID partition generation method and the precise definition of 'target accuracy' used for the time-to-accuracy metric.
- [Section 3] Notation for staleness (e.g., the maximum age parameter) should be introduced once and used consistently across the proof and algorithm pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical importance of handling queue dynamics in cross-facility federated learning. We address each major comment below. We agree that the manuscript would benefit from additional explicit details on the queue predictor and tail bounds to strengthen the connection between the high-probability staleness guarantee and the reported empirical results; we will incorporate these clarifications in the revised version.
read point-by-point responses
-
Referee: [Section 4] Abstract and convergence analysis (Section 4): The O(1/sqrt(R)) rate for non-convex objectives is conditioned on bounded staleness, yet the high-probability argument that cutoff-based admission maintains this bound under queue-prediction error provides no explicit tail bounds on prediction error, no description of the online predictor (features or update rule), and no relation between cutoff thresholds and those errors; this makes it impossible to verify whether the rate survives the high-variance regimes used for the 34% time-to-accuracy claim.
Authors: We acknowledge that the current manuscript states the O(1/sqrt(R)) convergence under bounded staleness (Theorem 1 in Section 4) and claims that admission controls achieve bounded staleness w.h.p. under queue-prediction error, but does not supply explicit tail bounds, a full description of the online predictor, or the precise mapping from prediction error to cutoff thresholds. In the revision we will add: (i) a description of the online predictor (historical per-facility queue times with an exponentially-weighted moving average update rule using the last 50 submissions as features); (ii) an explicit sub-Gaussian tail bound on prediction error derived from empirical HPC traces (with variance parameter fitted to the high-variance regime used in the 34% time-to-accuracy experiments); and (iii) the cutoff selection rule (cutoff = predicted delay + 3σ error bound) that ensures the probability of staleness exceeding the theorem's bound is at most δ = 0.05. These additions will make it possible to verify that the O(1/sqrt(R)) rate remains valid in the simulated high-variance, non-IID settings where the 34% improvement was measured. revision: yes
-
Referee: [Section 3.2] Admission control mechanism (Section 3.2): The claim that admission controls yield bounded staleness w.h.p. is load-bearing for both the theoretical guarantee and the reported gains over baselines, but the manuscript supplies neither the predictor's error model nor the tolerance used in the probability argument, leaving open the possibility that realistic HPC queue spikes violate the staleness assumption and invalidate the convergence rate.
Authors: We agree that the error model and probability tolerance are not stated explicitly. The revision will specify: the prediction error is modeled as sub-Gaussian with parameter σ estimated from real facility logs; the tolerance is set so that P(staleness > B) ≤ 0.05 where B is the bound used in the convergence theorem; and the cutoff is chosen to enforce this probability under the observed queue variance. We will also add a short discussion showing that the same parameter settings reproduce the 20.5% real-world improvement and the 34% simulation gain, thereby confirming that realistic spikes do not invalidate the rate under the chosen admission policy. revision: yes
Circularity Check
No significant circularity; convergence holds conditionally on externally verifiable bounded staleness.
full rationale
The paper states a standard non-convex FL convergence rate O(1/sqrt(R)) under the assumption of bounded staleness and separately claims that its admission controls achieve this bound with high probability given queue-prediction error. No equation or step reduces a fitted parameter or self-cited result directly to the target convergence claim by construction. The predictor itself is described at a high level without internal fitting that would force the staleness bound, and the proof is conditioned on an external property rather than derived tautologically from the method's own outputs. This leaves the central result self-contained against external benchmarks for staleness.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data , author=. Proceedings of the Twentieth International Conference on Artificial Intelligence and Statistics , series =. 2017 , publisher =
work page 2017
-
[2]
Asynchronous federated optimization,
Asynchronous federated optimization , author=. arXiv preprint arXiv:1903.03934 , year=
-
[3]
Nguyen, John and Malik, Kshitiz and Zhan, Hongyuan and Yousefpour, Ashkan and Rabbat, Mike and Malek, Mani and Huba, Dzmitry , booktitle =. 2022 , publisher =
work page 2022
-
[4]
Li, Zilinghan and Chaturvedi, Pranshu and He, Shilan and Chen, Han and Singh, Gagandeep and Kindratenko, Volodymyr and Huerta, Eliu A and Kim, Kibaek and Madduri, Ravi , booktitle=. Fed
-
[5]
International Conference on Learning Representations , year=
Adaptive Federated Optimization , author=. International Conference on Learning Representations , year=
-
[6]
Proceedings of Machine Learning and Systems , volume=
Federated optimization in heterogeneous networks , author=. Proceedings of Machine Learning and Systems , volume=
-
[7]
International Conference on Machine Learning , pages=
SCAFFOLD: Stochastic controlled averaging for federated learning , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[8]
Advances in Neural Information Processing Systems , volume=
Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
FedFa: A Fully Asynchronous Training Paradigm for Federated Learning , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI-24) , pages=
-
[10]
Chen and Sanzio Bassini and Gabriella Scipione and Jan Martinovi
Iacopo Colonnelli and Robert Birke and Giulio Malenza and Gianluca Mittone and Alberto Mulone and Jeroen Galjaard and Lydia Y. Chen and Sanzio Bassini and Gabriella Scipione and Jan Martinovi. Cross-Facility Federated Learning , url =. Procedia Computer Science , pages =
-
[11]
A performance analysis of VM-based Trusted Execution Environments for Confidential Federated Learning , author =. 2025 , booktitle =
work page 2025
-
[12]
Workshop on Job Scheduling Strategies for Parallel Processing , pages=
SLURM: Simple linux utility for resource management , author=. Workshop on Job Scheduling Strategies for Parallel Processing , pages=. 2003 , organization=
work page 2003
-
[13]
Job scheduling under the Portable Batch System
Henderson, Robert L. Job scheduling under the Portable Batch System. Job Scheduling Strategies for Parallel Processing. 1995
work page 1995
-
[14]
Job Scheduling Strategies for Parallel Processing (JSSPP 2001) , series=
Core Algorithms of the Maui Scheduler , author=. Job Scheduling Strategies for Parallel Processing (JSSPP 2001) , series=. 2001 , publisher=
work page 2001
-
[15]
Workload Modeling for Computer Systems Performance Evaluation , author=. 2015 , publisher=
work page 2015
-
[16]
Foundations and Trends in Machine Learning , volume=
Advances and open problems in federated learning , author=. Foundations and Trends in Machine Learning , volume=
-
[17]
Journal of Machine Learning Research , volume=
A general theory for federated optimization with asynchronous and heterogeneous clients updates , author=. Journal of Machine Learning Research , volume=
-
[18]
IEEE Transactions on Artificial Intelligence , year=
Asynchronous Federated Learning with nonconvex client objective functions and heterogeneous dataset , author=. IEEE Transactions on Artificial Intelligence , year=
-
[19]
Yu, Jieling and Zhou, Ruiting and Chen, Chen and Li, Bo and Dong, Fang , booktitle=
-
[20]
Journal of Parallel and Distributed Computing , volume=
Staleness aware semi-asynchronous federated learning , author=. Journal of Parallel and Distributed Computing , volume=. 2024 , publisher=
work page 2024
-
[21]
Liu, Ji and Jia, Juncheng and Che, Tianshi and Huo, Chao and Ren, Jiaxiang and Zhou, Yang and Dai, Huaiyu and Dou, Dejing , booktitle=
-
[22]
ACM Transactions on Intelligent Systems and Technology (TIST) , volume=
Fleet: Online federated learning via staleness awareness and performance prediction , author=. ACM Transactions on Intelligent Systems and Technology (TIST) , volume=. 2022 , publisher=
work page 2022
-
[23]
IEEE Journal of Selected Topics in Signal Processing , volume=
Federated learning under intermittent client availability and time-varying communication constraints , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
work page 2022
-
[24]
Advances in Neural Information Processing Systems , volume=
A unified analysis of federated learning with arbitrary client participation , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Proceedings of the 5th Workshop on Machine Learning and Systems , pages=
Client Availability in Federated Learning: It Matters! , author=. Proceedings of the 5th Workshop on Machine Learning and Systems , pages=
-
[26]
Predicting batch queue job wait times for informed scheduling of urgent
Brown, Nick and Gibb, Gordon and Belikov, Evgenij and Nash, Rupert , journal=. Predicting batch queue job wait times for informed scheduling of urgent
-
[27]
Concurrency and Computation: Practice and Experience , volume=
Predicting accurate batch queue wait times on production supercomputers by combining machine learning techniques , author=. Concurrency and Computation: Practice and Experience , volume=. 2024 , publisher=
work page 2024
-
[28]
Predicting queue wait time probabilities for multi-scale computing , author=. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2019 , publisher=
work page 2019
-
[29]
Baker and Ziqi Chen and Xia Ning and Huan Sun , booktitle=
Botao Yu and Frazier N. Baker and Ziqi Chen and Xia Ning and Huan Sun , booktitle=. Lla. 2024 , url=
work page 2024
-
[30]
Incentive mechanism of foundation model enabled cross-silo federated learning , author=. Scientific Reports , volume=
-
[31]
When Foundation Model Meets Federated Learning: Motivations, Challenges, and Future Directions , author=. arXiv preprint arXiv:2306.15546 , year=
-
[32]
2024 IEEE International Conference on Big Data (BigData) , pages=
Privacy-preserving federated learning for science: Challenges and research directions , author=. 2024 IEEE International Conference on Big Data (BigData) , pages=. 2024 , organization=
work page 2024
-
[33]
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , journal=
work page 2023
-
[34]
2025 IEEE 25th International Symposium on Cluster, Cloud and Internet Computing (CCGrid) , pages=
Advances in APPFL: A comprehensive and extensible federated learning framework , author=. 2025 IEEE 25th International Symposium on Cluster, Cloud and Internet Computing (CCGrid) , pages=. 2025 , organization=
work page 2025
-
[35]
2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW) , pages=
APPFL: open-source software framework for privacy-preserving federated learning , author=. 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW) , pages=. 2022 , organization=
work page 2022
-
[36]
and Nagaitsev, Kirill and Woodard, Anna and Blaiszik, Ben and Bryan, Josh and Katz, Daniel S
Li, Zhuozhao and Chard, Ryan and Babuji, Yadu and Galewsky, Ben and Skluzacek, Tyler J. and Nagaitsev, Kirill and Woodard, Anna and Blaiszik, Ben and Bryan, Josh and Katz, Daniel S. and Foster, Ian and Chard, Kyle , journal=. func. 2022 , publisher=
work page 2022
-
[37]
The International Journal of High Performance Computing Applications , volume =
Weijian Zheng and Jack Kordas and Tyler J Skluzacek and Raj Kettimuthu and Ian Foster , title =. The International Journal of High Performance Computing Applications , volume =. 2024 , doi =
work page 2024
-
[38]
Scalable Cross-Facility Federated Learning for Scientific Foundation Models on Multiple Supercomputers , author=. 2026 , journal=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.