Recognition: 3 theorem links
· Lean TheoremA Parameter-Free First-Order Algorithm for Non-Convex Optimization with tilde{mkern1mu O}(ε^{-5/3}) Global Rate
Pith reviewed 2026-05-08 18:50 UTC · model grok-4.3
The pith
PF-AGD is the first parameter-free deterministic accelerated first-order method to reach the O(ε^{-5/3} log(1/ε)) rate on smooth non-convex problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PF-AGD is the first parameter-free, deterministic, accelerated first-order method to achieve O(ε^{-5/3} log(1/ε)) oracle complexity when minimizing sufficiently smooth non-convex functions; this matches the best-known bound for any first-order method on such objectives while removing the requirement for a priori smoothness constants through an adaptive backtracking scheme and a gradient-based restart mechanism.
What carries the argument
The PF-AGD algorithm equipped with an adaptive backtracking line search to estimate local smoothness constants together with a gradient-norm restart trigger that preserves the global rate.
If this is right
- The method becomes a viable deterministic alternative to parameter-dependent accelerated schemes for smooth non-convex minimization.
- It empirically outperforms the practical version of AGD-Until-Guilty and other parameter-free first-order variants on test problems.
- The same adaptive mechanism can be used on problems whose smoothness constant changes locally without breaking the global complexity guarantee.
- It supplies a concrete first-order procedure whose rate matches the current theoretical optimum while remaining fully implementable.
Where Pith is reading between the lines
- If the adaptation logic generalizes, similar backtracking-restart ideas could be applied to stochastic or composite non-convex problems to obtain parameter-free rates.
- The construction suggests that deterministic first-order methods can achieve optimal rates on non-convex landscapes once local curvature estimation is folded into the iteration.
- In practice the algorithm offers a drop-in replacement for nonlinear conjugate-gradient methods when theoretical guarantees are desired alongside observed speed.
Load-bearing premise
The backtracking and restart rules correctly detect intervals where the function obeys a local smoothness bound without inflating the overall iteration count.
What would settle it
A smooth non-convex function on which PF-AGD requires more than O(ε^{-5/3} log(1/ε)) gradient evaluations to reach an ε-stationary point, either in theory or on a standard benchmark.
Figures








read the original abstract
We introduce PF-AGD, the first parameter-free, deterministic, accelerated first-order method to achieve $O(\epsilon^{-5/3}\log(1/\epsilon))$ oracle complexity bound when minimizing sufficiently smooth, non-convex functions; this is the best-known bound for first-order methods on smooth non-convex objectives. Unlike existing methods possessing this rate that require a priori knowledge of smoothness constants, we use an adaptive backtracking scheme and a gradient-based restart mechanism to estimate local curvature. This yields a practical algorithm that matches best-known theoretical rates. Empirically, PF-AGD outperforms the practical variant of AGD-Until-Guilty (Carmon et al., 2017), as well as other parameter-free variants, and is a viable alternative to nonlinear conjugate gradient methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PF-AGD, a deterministic parameter-free accelerated first-order algorithm for non-convex optimization. It uses adaptive backtracking line search and gradient-based restarts to estimate local smoothness constants on the fly, achieving an oracle complexity of O(ε^{-5/3} log(1/ε)) for sufficiently smooth functions. This is claimed to be the first such method attaining the best-known rate without a priori knowledge of the smoothness parameter L, with supporting empirical comparisons to AGD-Until-Guilty and other baselines.
Significance. If the analysis is complete, the result would be significant for non-convex first-order optimization: it removes a practical barrier (unknown L) while matching the optimal known rate among deterministic methods. The adaptive mechanisms and empirical performance make it relevant for applications where smoothness varies locally. Strengths include the explicit parameter-free construction and the focus on total oracle count including failed trials.
major comments (1)
- [Complexity analysis (proof of main theorem)] The central complexity claim depends on the adaptive backtracking and restart scheme keeping the total number of gradient evaluations (including failed trials) inside the Õ(ε^{-5/3}) bound. No explicit worst-case lemma bounds the aggregate cost of backtracks when local curvature changes on a scale finer than the restart frequency; the argument relies on the scheme “correctly identifying intervals where local smoothness holds” without a first-principles derivation that this cost remains O(log(1/ε)) per phase on average. This is load-bearing for the global rate.
minor comments (2)
- [Algorithm description] Notation for the local smoothness estimate and restart threshold should be introduced with a clear table or definition list to avoid ambiguity when reading the algorithm pseudocode.
- [Numerical experiments] The empirical section would benefit from reporting the total number of gradient evaluations (not just iterations) to directly illustrate that the adaptive overhead remains controlled in practice.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. The positive assessment of the significance of PF-AGD is appreciated. We respond to the major comment as follows and will incorporate revisions to address the concern raised.
read point-by-point responses
-
Referee: The central complexity claim depends on the adaptive backtracking and restart scheme keeping the total number of gradient evaluations (including failed trials) inside the Õ(ε^{-5/3}) bound. No explicit worst-case lemma bounds the aggregate cost of backtracks when local curvature changes on a scale finer than the restart frequency; the argument relies on the scheme “correctly identifying intervals where local smoothness holds” without a first-principles derivation that this cost remains O(log(1/ε)) per phase on average. This is load-bearing for the global rate.
Authors: We thank the referee for pointing out this potential gap in the presentation of the analysis. While the proof of the main theorem (Theorem 4.1) does account for the total number of gradient evaluations by summing over phases and bounding the per-phase cost, we acknowledge that the bound on backtracking steps when curvature changes rapidly could be stated more explicitly. In the revised manuscript, we will introduce a new supporting lemma that provides a first-principles worst-case analysis of the backtracking line search combined with the restart mechanism. Specifically, the lemma will show that regardless of how finely the local smoothness varies, the number of failed trials per successful step is bounded by a constant (due to the doubling strategy), and the restart frequency ensures that the aggregate extra cost per phase is O(log(1/ε)). This will confirm that the overall oracle complexity remains Õ(ε^{-5/3} log(1/ε)). We believe this addition will fully address the concern without changing the main result. revision: yes
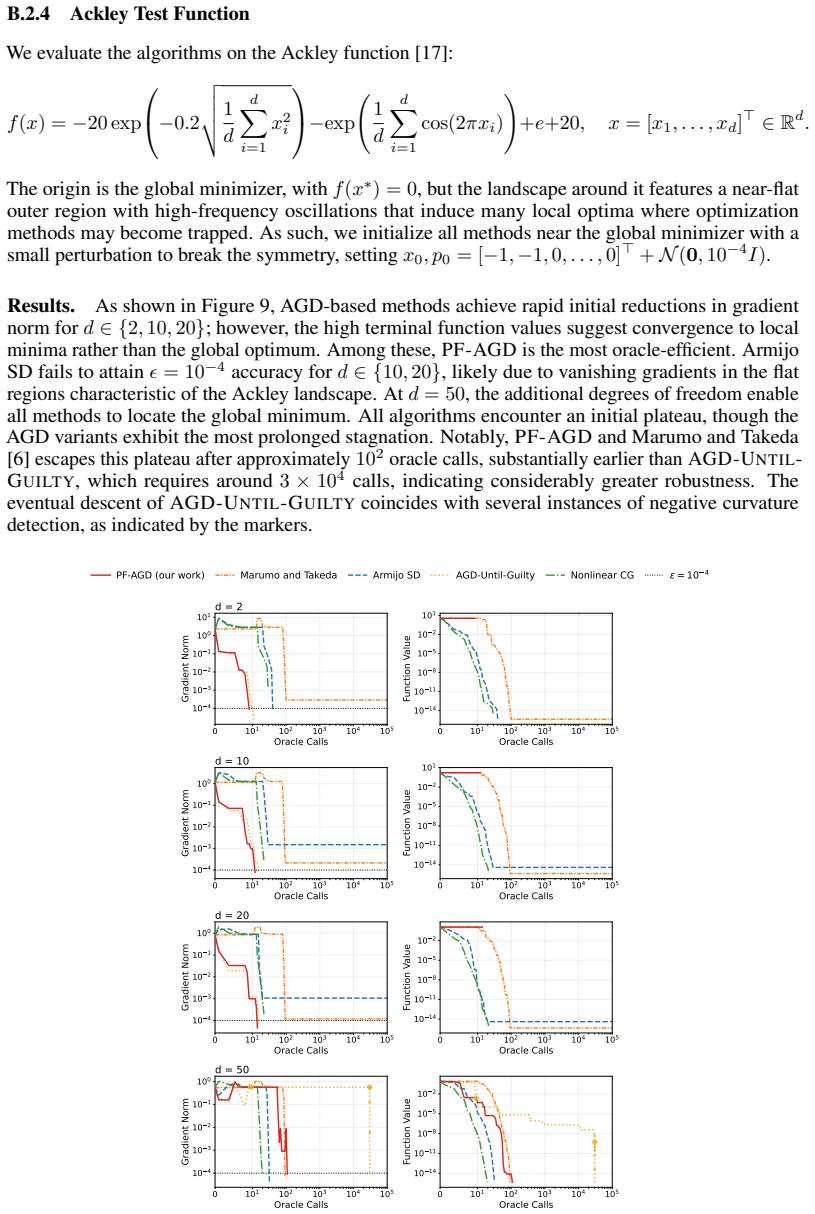
Circularity Check
No circularity: complexity bound derived from standard non-convex analysis on adaptive scheme
full rationale
The paper constructs PF-AGD via explicit backtracking line search and gradient restarts, then bounds total oracle calls (including failed trials) by summing per-phase costs under local L-smoothness intervals. This bound is obtained from first-principles telescoping and restart lemmas that do not presuppose the final rate; the O(ε^{-5/3} log(1/ε)) result follows directly from the number of successful steps needed to drive the gradient norm below ε, with backtrack overhead controlled by a fixed geometric factor independent of the target ε. No step equates a fitted quantity to a prediction, invokes a self-citation as the sole justification for uniqueness, or renames an input as an output. The derivation remains self-contained against external benchmarks such as the Carmon et al. (2017) restart framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is continuously differentiable and locally smooth with gradient Lipschitz constant that can be estimated via backtracking line search.
Lean theorems connected to this paper
-
Cost/FunctionalEquation.lean — RS's cost is J(x)=½(x+x⁻¹)−1 from Aczél functional equation; the paper's Lyapunov is a quadratic strong-convexity surrogate, not the reciprocal-symmetric Jwashburn_uniqueness_aczel unclearLyapunov potential V_t(y_k, x_k) := f(y_k) − f(w) + (σ/2)‖z_t(y_k,x_k) − w‖²
Reference graph
Works this paper leans on
-
[1]
Convex until proven guilty
Yair Carmon, John C. Duchi, Oliver Hinder, and Aaron Sidford. “Convex until proven guilty”: Dimension-free acceleration of gradient descent on non-convex functions. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 654–663. PMLR, 2017
2017
-
[2]
Springer, 2 edition, 2018
Yurii Nesterov.Lectures on Convex Optimization. Springer, 2 edition, 2018
2018
-
[3]
Coralia Cartis, Nicholas I. M. Gould, and Philippe L. Toint.Evaluation Complexity of Algorithms for Nonconvex Optimization: Theory, Computation and Perspectives. SIAM, 2022
2022
-
[4]
Foundations and Trends in Optimization, 2021
Alexandre d’Aspremont, Damien Scieur, and Adrien Taylor.Acceleration Methods, volume 5. Foundations and Trends in Optimization, 2021
2021
-
[5]
Kluwer Academic Publishers, Boston, 2004
Yurii Nesterov.Introductory Lectures on Convex Optimization: A Basic Course, volume 87 of Applied Optimization. Kluwer Academic Publishers, Boston, 2004. ISBN 1402075537
2004
-
[6]
Parameter-free accelerated gradient descent for nonconvex minimization.SIAM Journal on Optimization, 34(2):2093–2120, 2024
Naoki Marumo and Akiko Takeda. Parameter-free accelerated gradient descent for nonconvex minimization.SIAM Journal on Optimization, 34(2):2093–2120, 2024
2093
-
[7]
Improved complexity for smooth nonconvex optimization: A two-level online learning approach with quasi-Newton methods
Ruichen Jiang, Aryan Mokhtari, and Francisco Patitucci. Improved complexity for smooth nonconvex optimization: A two-level online learning approach with quasi-Newton methods. In Proceedings of the 57th Annual ACM Symposium on Theory of Computing, STOC ’25, pages 2225–2236, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[8]
Parameter-free accelerated quasi-Newton method for nonconvex optimization
Naoki Marumo. Parameter-free accelerated quasi-Newton method for nonconvex optimization. arXiv:2512.09439, 2025
-
[9]
First and zeroth-order implementations of the regularized Newton method with lazy approximated Hessians.Journal of Scientific Computing, 103(1):32, 2025
Nikita Doikov and Geovani Nunes Grapiglia. First and zeroth-order implementations of the regularized Newton method with lazy approximated Hessians.Journal of Scientific Computing, 103(1):32, 2025
2025
-
[10]
Coralia Cartis, Nicholas I. M. Gould, and Philippe L. Toint. On the oracle complexity of first-order and derivative-free algorithms for smooth nonconvex minimization.SIAM Journal on Optimization, 22(1):66–86, 2012
2012
-
[11]
Rémi Chan-Renous-Legoubin and Clément W. Royer. A nonlinear conjugate gradient method with complexity guarantees and its application to nonconvex regression.EURO Journal on Computational Optimization, 10:100044, 2022
2022
-
[12]
Cavalcanti, Laurent Lessard, and Ashia C
Joao V . Cavalcanti, Laurent Lessard, and Ashia C. Wilson. Adaptive backtracking for faster optimization. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=SrGP0RQbYH. 10
2025
-
[13]
Polak and G
E. Polak and G. Ribière. Note sur la convergence de méthodes de directions conjuguées.Revue Française d’Informatique et de Recherche Opérationnelle, 3:35–43, 1969
1969
-
[14]
Minimization of functions having Lipschitz continuous first partial derivatives
Larry Armijo. Minimization of functions having Lipschitz continuous first partial derivatives. Pacific Journal of Mathematics, 16:1–3, 1966
1966
-
[15]
Dynamic differential evolution strategy and applications in electromagnetic inverse scattering problems.IEEE Transactions on Geoscience and Remote Sensing, 44(1): 116–125, 2006
Anyong Qing. Dynamic differential evolution strategy and applications in electromagnetic inverse scattering problems.IEEE Transactions on Geoscience and Remote Sensing, 44(1): 116–125, 2006
2006
-
[16]
H. H. Rosenbrock. An automatic method for finding the greatest or least value of a function. The Computer Journal, 3:175–184, 1960
1960
-
[17]
David H. Ackley. A connectionist machine for genetic hillclimbing. pages 13–14. Springer US, Boston, MA, 1987. ISBN 978-1-4613-1997-9
1987
-
[18]
M. J. D. Powell. An iterative method for finding stationary values of a function of several variables.The Computer Journal, 5(2):147–151, 1962
1962
-
[19]
Beaton and John W
Albert E. Beaton and John W. Tukey. The fitting of power series, meaning polynomials, illustrated on band-spectroscopic data.Technometrics, 16(2):147–185, 1974
1974
-
[20]
Yann LeCun, Corinna Cortes, and Christopher J. C. Burges. The MNIST database of handwritten digits, 1998
1998
-
[21]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, volume 9 ofProceedings of Machine Learning Research, pages 249–256. PMLR, 2010
2010
-
[22]
L. C. W. Dixon and R. C. Price. Truncated Newton method for sparse unconstrained optimization using automatic differentiation.Journal of Optimization Theory and Applications, 60(2):261– 275, 1989
1989
-
[23]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In3rd International Conference on Learning Representations (ICLR), 2015. URL http://arxiv. org/abs/1412.6980
work page internal anchor Pith review arXiv 2015
-
[24]
A stochastic approximation method.The Annals of Mathematical Statistics, 22:400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Mathematical Statistics, 22:400–407, 1951
1951
-
[25]
A stochastic line search method with expected complexity analysis.SIAM Journal on Optimization, 30(1):349–376, 2020
Courtney Paquette and Katya Scheinberg. A stochastic line search method with expected complexity analysis.SIAM Journal on Optimization, 30(1):349–376, 2020
2020
-
[26]
Berahas, Liyuan Cao, and Katya Scheinberg
Albert S. Berahas, Liyuan Cao, and Katya Scheinberg. Global convergence rate analysis of a generic line search algorithm with noise.SIAM Journal on Optimization, 31(2):1489–1518, 2021
2021
-
[27]
Schmidt, Gauthier Gidel, and Simon Lacoste-Julien
Sharan Vaswani, Aaron Mishkin, Issam Hadj Laradji, Mark W. Schmidt, Gauthier Gidel, and Simon Lacoste-Julien. Painless stochastic gradient: Interpolation, line-search, and convergence rates. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[28]
Accelerated gradient methods for nonconvex nonlinear and stochastic programming.Mathematical Programming, 156(1):59–99, 2016
Saeed Ghadimi and Guanghui Lan. Accelerated gradient methods for nonconvex nonlinear and stochastic programming.Mathematical Programming, 156(1):59–99, 2016
2016
-
[29]
Duchi, Oliver Hinder, and Aaron Sidford
Yair Carmon, John C. Duchi, Oliver Hinder, and Aaron Sidford. Lower bounds for finding stationary points I.Mathematical Programming, 184(1):71–120, 2020
2020
-
[30]
Chi Jin, Praneeth Netrapalli, and Michael I. Jordan. Accelerated gradient descent escapes saddle points faster than gradient descent. InConference on Learning Theory, pages 1042–1085. PMLR, 2018. 11
2018
-
[31]
Restarted nonconvex accelerated gradient descent: No more polylogarithmic factor in the O(ϵ−7/4) complexity.Journal of Machine Learning Research, 24 (157):1–37, 2023
Huan Li and Zhouchen Lin. Restarted nonconvex accelerated gradient descent: No more polylogarithmic factor in the O(ϵ−7/4) complexity.Journal of Machine Learning Research, 24 (157):1–37, 2023
2023
-
[32]
Universal heavy-ball method for nonconvex optimization under Hölder continuous Hessians.Mathematical Programming, 212(1):147–175, 2025
Naoki Marumo and Akiko Takeda. Universal heavy-ball method for nonconvex optimization under Hölder continuous Hessians.Mathematical Programming, 212(1):147–175, 2025
2025
-
[33]
Neon2: Finding local minima via first-order oracles
Zeyuan Allen-Zhu and Yuanzhi Li. Neon2: Finding local minima via first-order oracles. Advances in Neural Information Processing Systems, 31, 2018
2018
-
[34]
Coralia Cartis, Nicholas I. M. Gould, and Philippe L. Toint. On the complexity of steepest descent, Newton’s and regularized Newton’s methods for nonconvex unconstrained optimization problems.SIAM Journal on Optimization, 20(6):2833–2852, 2010
2010
-
[35]
Coralia Cartis, Nicholas I. M. Gould, and Philippe L. Toint. Adaptive cubic regularisation methods for unconstrained optimization. Part I: motivation, convergence and numerical results. Mathematical Programming, 127(2):245–295, 2011
2011
-
[36]
Coralia Cartis, Nicholas I. M. Gould, and Philippe L. Toint. Adaptive cubic regularisation methods for unconstrained optimization. Part II: worst-case function- and derivative-evaluation complexity.Mathematical Programming, 130(2):295–319, 2011
2011
-
[37]
Birgin, J
Ernesto G. Birgin, J. L. Gardenghi, José Mario Martínez, Sandra Augusta Santos, and Philippe L. Toint. Worst-case evaluation complexity for unconstrained nonlinear optimization using high- order regularized models.Mathematical Programming, 163(1):359–368, 2017
2017
-
[38]
Royer, Michael O’Neill, and Stephen J
Clément W. Royer, Michael O’Neill, and Stephen J. Wright. A Newton-CG algorithm with complexity guarantees for smooth unconstrained optimization.Mathematical Programming, 180(1):451–488, 2020
2020
-
[39]
Liu and Jorge Nocedal
Dong C. Liu and Jorge Nocedal. On the limited memory BFGS method for large scale optimization.Mathematical Programming, 45:503–528, 1989
1989
-
[40]
Sahar Karimi and Stephen A. Vavasis. Nonlinear conjugate gradient for smooth convex functions. Mathematical Programming Computation, 16(2):229–254, 2024
2024
-
[41]
difficulty
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initial- ization and momentum in deep learning. InProceedings of the 30th International Conference on Machine Learning, volume 28 ofProceedings of Machine Learning Research, pages 1139–1147. PMLR, 2013. 12 A Proofs A.1 Preliminaries In this section, we introduce notation...
2013
-
[42]
The eventual descent of AGD-UNTIL-GUILTYcoincides with several instances of negative curvature detection, as indicated by the markers
escapes this plateau after approximately 102 oracle calls, substantially earlier than AGD-UNTIL- GUILTY, which requires around 3×10 4 calls, indicating considerably greater robustness. The eventual descent of AGD-UNTIL-GUILTYcoincides with several instances of negative curvature detection, as indicated by the markers. 0 101 102 103 104 105 Oracle Calls 10...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.