Recognition: 3 theorem links
· Lean TheoremHierarchical Cooperative MARL for Joint Downlink PRB and Power Allocation in a 5G System
Pith reviewed 2026-05-08 19:02 UTC · model grok-4.3
The pith
A hierarchical cooperative MARL controller jointly allocates PRBs and transmit power in 5G downlink to raise cell throughput while keeping fairness close to proportional-fair scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
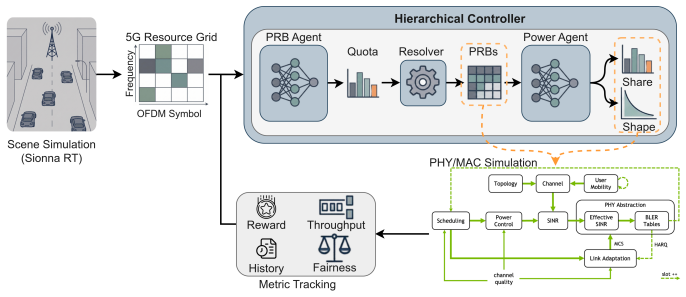
We propose a hierarchical cooperative multi-agent reinforcement learning framework with staged curriculum training for joint downlink PRB and power allocation in a physically grounded 5G environment. The control task is decomposed into a PRB agent that learns user-level resource shares, converted to exact assignments by a deterministic channel-aware resolver, and a power agent that distributes the base-station power budget. Under matched channel realizations, the full PRB and power controller achieves the largest cell-throughput gain with only a modest reduction in Jain's fairness index compared with a PF scheduler and two component ablations.
What carries the argument
Hierarchical decomposition into a PRB-allocation agent followed by a power-allocation agent, linked by a deterministic quota resolver and trained in three curriculum phases inside the Sionna ray-tracing simulator.
If this is right
- Both the learned PRB policy and the learned power policy separately improve throughput distribution over proportional-fair equal-power transmission.
- The combined controller produces the largest throughput increase while the fairness index drops only modestly.
- Curriculum training across PRB allocation, power control, and joint fine-tuning improves stability of the multi-agent learning process.
- The cross-layer loop with adaptive modulation, HARQ feedback, and outer-loop link adaptation remains compatible with the learned policies.
Where Pith is reading between the lines
- The same staged decomposition could be tested on uplink or in multi-cell coordinated multipoint scenarios where inter-cell interference adds another continuous control dimension.
- If the modest fairness loss proves consistent across deployments, operators could adopt the controller for capacity-limited cells while retaining a separate fairness safeguard for edge users.
- Replacing the ray-tracing channel generator with measured field data during fine-tuning would directly test the sim-to-real gap identified as the central assumption.
Load-bearing premise
The assumption that policies trained inside the Sionna ray-tracing simulator will generalize to real 5G deployments whose channel statistics, hardware impairments, and traffic patterns differ from the simulated environment.
What would settle it
Measure cell throughput and Jain fairness when the trained agents are deployed on a live 5G base station under real mobility and interference, then compare the gap to the proportional-fair scheduler under identical traffic loads.
Figures


read the original abstract
Efficient downlink radio resource management in 5G requires jointly optimizing user scheduling and transmit-power allocation under time-varying wireless conditions. This is challenging in OFDMA systems because PRB assignment is combinatorial, power allocation is continuous, and performance depends on channel evolution, link adaptation, and long-term fairness. We propose a hierarchical cooperative multi-agent reinforcement learning framework with staged curriculum training for joint downlink PRB and power allocation in a physically grounded 5G environment. System-level simulation is implemented in Sionna, while Sionna RT supports wireless scene construction and mobility-aware ray-traced channel generation. The control task is decomposed into two sequential stages: a PRB agent learns user-level resource shares, which are converted to exact PRB assignments by a deterministic channel-aware quota resolver, and a power agent distributes the base-station power budget across users and their assigned PRB-symbol resources. The framework operates in a cross-layer loop with adaptive modulation and coding, HARQ feedback, outer-loop link adaptation, and a fairness-aware reward based on smoothed throughput and Jain's fairness index. Training stability is improved through a three-phase curriculum for PRB allocation, power control, and joint fine-tuning. Under matched channel realizations, we compare against a PF scheduler with equal-power transmission and two ablations isolating the learned PRB and power-control components. Results show that both learned components improve throughput distribution relative to PF, while the full PRB and power controller achieves the largest cell-throughput gain with only a modest reduction in Jain's fairness index.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical cooperative multi-agent RL framework for joint downlink PRB and power allocation in 5G OFDMA systems. It decomposes control into a PRB agent whose outputs are resolved by a deterministic channel-aware quota resolver, followed by a power agent, all trained end-to-end with a three-phase curriculum inside the Sionna ray-tracing simulator. The framework closes the loop with AMC, HARQ, outer-loop link adaptation, and a reward combining smoothed throughput and Jain fairness. Under matched channel realizations the full controller is reported to outperform PF scheduling with equal power and two ablations that isolate the learned PRB and power components.
Significance. If the quantitative claims hold and the sim-to-real gap is addressed, the work would demonstrate a practical way to apply hierarchical MARL to a combinatorially hard, cross-layer RRM problem while preserving fairness. The staged curriculum, deterministic resolver, and integration with existing 5G mechanisms (AMC/HARQ) are constructive contributions that could be reused in other resource-allocation settings.
major comments (3)
- [Abstract] Abstract: the headline claim that the full PRB-and-power controller 'achieves the largest cell-throughput gain with only a modest reduction in Jain's fairness index' is stated without any numerical deltas, confidence intervals, number of independent runs, or statistical tests. This absence prevents assessment of effect size and reproducibility.
- [Results] Results section (and abstract): all training and evaluation occur exclusively inside Sionna RT under matched channel realizations; no experiments, sensitivity analysis, or discussion address transfer to real 5G deployments whose channel statistics, mobility, hardware impairments, and traffic differ from the simulator. This directly undercuts the claim of applicability to a '5G system'.
- [§4] §4 (framework description): the reward weights the throughput and Jain-fairness terms; because these weights are free parameters chosen by the authors, the reported fairness-throughput trade-off is not parameter-free and the 'modest reduction' claim depends on the specific weighting chosen.
minor comments (2)
- A table or plot summarizing absolute throughput values, Jain indices, and run statistics for all methods (PF, PRB-only, power-only, joint) would make the comparison concrete.
- The state and action representations for the two agents are described only at a high level; a compact diagram or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract, evaluation scope, and reward design. We address each major comment below and will revise the manuscript accordingly to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the full PRB-and-power controller 'achieves the largest cell-throughput gain with only a modest reduction in Jain's fairness index' is stated without any numerical deltas, confidence intervals, number of independent runs, or statistical tests. This absence prevents assessment of effect size and reproducibility.
Authors: We agree that the abstract should provide quantitative support for the headline claim. In the revised manuscript we will insert the specific cell-throughput gains and Jain fairness reductions observed across our experiments, along with the number of independent runs (multiple random seeds) and associated confidence intervals. This will allow readers to directly assess effect size and reproducibility. revision: yes
-
Referee: [Results] Results section (and abstract): all training and evaluation occur exclusively inside Sionna RT under matched channel realizations; no experiments, sensitivity analysis, or discussion address transfer to real 5G deployments whose channel statistics, mobility, hardware impairments, and traffic differ from the simulator. This directly undercuts the claim of applicability to a '5G system'.
Authors: We acknowledge that all reported results are obtained inside the Sionna RT simulator under matched channel realizations. The manuscript frames the contribution as a simulation study that employs a physically grounded ray-tracing model. In the revision we will update the abstract, introduction, and conclusion to explicitly qualify the results as simulation-based, state the matched-channel condition, and add a dedicated paragraph discussing the sim-to-real gap together with the limitations this imposes for direct claims about real 5G deployments. No new hardware experiments are added in this revision. revision: partial
-
Referee: [§4] §4 (framework description): the reward weights the throughput and Jain-fairness terms; because these weights are free parameters chosen by the authors, the reported fairness-throughput trade-off is not parameter-free and the 'modest reduction' claim depends on the specific weighting chosen.
Authors: The reward is indeed a weighted sum of smoothed throughput and Jain's fairness index, with weights chosen to achieve a practical operating point during curriculum training. We will revise Section 4 to report the exact weight values employed in the presented experiments. We will also add a brief sensitivity discussion or table showing how modest changes in the weights affect the observed throughput-fairness trade-off, thereby clarifying the dependence on the chosen parameters. revision: yes
Circularity Check
No circularity in the hierarchical MARL derivation chain
full rationale
The paper presents an empirical MARL framework trained end-to-end on Sionna ray-tracing rollouts for joint PRB and power allocation, with performance evaluated against an external proportional-fair scheduler baseline and ablations. No mathematical derivations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the described chain; the throughput and fairness results are obtained from simulation comparisons under matched conditions rather than by construction from the inputs themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward weighting between throughput and Jain fairness
axioms (2)
- domain assumption The Sionna ray-tracing channel model sufficiently approximates real 5G propagation for policy learning and transfer
- standard math The Markov decision process formulation captures the essential state transitions for PRB and power decisions
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (Jcost)Jcost_unit0 / washburn_uniqueness_aczel uncleara PRB agent learns user-level resource shares ... and a power agent distributes the base-station power budget ... a fairness-aware reward based on smoothed throughput and Jain's fairness index
-
IndisputableMonolith.Foundation.AlphaCoordinateFixationcostAlphaLog_high_calibrated_iff unclearω_{t,ℓ,ρ,u} = exp(−κ_{t,u}(m−1)) ... exponential shaping weights
Reference graph
Works this paper leans on
-
[1]
NR; Physical Channels and Modulation,
3GPP, “NR; Physical Channels and Modulation,” 3rd Generation Partnership Project (3GPP), Technical Specification TS 38.211, 2025, Release 18, Version 18.7.0
2025
-
[2]
NR; Physical Layer Procedures for Data,
3GPP, “NR; Physical Layer Procedures for Data,” 3rd Generation Partnership Project (3GPP), Technical Specification TS 38.214, 2025, Release 17, Version 17.14.0
2025
-
[3]
NR; Base Station (BS) Radio Transmission and Reception,
3GPP, “NR; Base Station (BS) Radio Transmission and Reception,” 3rd Generation Partnership Project (3GPP), Technical Specification TS 38.104, 2025, Release 18, Version 18.10.0
2025
-
[4]
NR; Medium Access Control (MAC) Protocol Specification,
3GPP, “NR; Medium Access Control (MAC) Protocol Specification,” 3rd Generation Partnership Project (3GPP), Technical Specification TS 38.321, 2025, Release 18
2025
-
[5]
Rate control for communication networks: Shadow prices, proportional fairness and stability,
F. P. Kelly, A. K. Maulloo, and D. K. H. Tan, “Rate control for communication networks: Shadow prices, proportional fairness and stability,”Journal of the Operational Research Society, vol. 49, no. 3, pp. 237–252, 1998
1998
-
[6]
Data throughput of cdma-hdr: A high efficiency-high data rate personal communication wireless system,
A. Jalali, R. Padovani, and R. Pankaj, “Data throughput of cdma-hdr: A high efficiency-high data rate personal communication wireless system,” inProc. IEEE V ehicular Technology Conference (VTC), 2000, pp. 1854– 1858
2000
-
[7]
Convergence of proportional-fair sharing algorithms under general conditions,
H. J. Kushner and P. A. Whiting, “Convergence of proportional-fair sharing algorithms under general conditions,”IEEE Transactions on Wireless Communications, vol. 3, no. 4, pp. 1250–1259, 2004
2004
-
[8]
Joint PRB and power allocation for slicing eMBB and URLLC services in 5G C-RAN,
M. Setayesh, S. Bahrami, and V . W. S. Wong, “Joint PRB and power allocation for slicing eMBB and URLLC services in 5G C-RAN,” in Proc. IEEE Global Communications Conference (GLOBECOM), 2020
2020
-
[9]
Joint resource block and power allocation for eMBB and URLLC coexistence in 5G H- CRAN,
Q. Cheng, K. Li, P. Zhu, J. Li, Y . Jiang, and D. Wang, “Joint resource block and power allocation for eMBB and URLLC coexistence in 5G H- CRAN,” inProc. International Conference on Wireless Communications and Signal Processing (WCSP), 2023
2023
-
[10]
Reinforcement learning-based joint power and resource allocation for URLLC in 5G,
M. Elsayed and M. Erol-Kantarci, “Reinforcement learning-based joint power and resource allocation for URLLC in 5G,” inProc. IEEE Global Communications Conference (GLOBECOM), 2019
2019
-
[11]
Joint subcarrier and power allocation in mobile scenario of the OFDM systems based on deep reinforcement learning,
X. Li, W. Zhou, H. Zhang, J. Zhao, D. Zhao, and Z. Dong, “Joint subcarrier and power allocation in mobile scenario of the OFDM systems based on deep reinforcement learning,” inProc. International Conference on Computer , Communication and Control Systems (IC- CCS), 2023, pp. 209–214
2023
-
[12]
Joint scheduling and resource allocation based on reinforcement learning in integrated access and backhaul networks,
J. Kim, Y . Jeon, J. Lee, M. Lee, and T. Kwon, “Joint scheduling and resource allocation based on reinforcement learning in integrated access and backhaul networks,”ICT Express, vol. 11, no. 3, pp. 536–541, 2025
2025
-
[13]
J. Jang, H. Lyu, D. J. Love, and H. J. Yang, “Joint optimization of user association and resource allocation for load balancing with multi-level fairness,”arXiv preprint arXiv:2505.08573, 2025
-
[14]
Dora: Dynamic o-ran resource allocation for multi-slice 5g networks,
A. E. Dorcheh, T. Seyfi, and F. Afghah, “Dora: Dynamic o-ran resource allocation for multi-slice 5g networks,” in2025 IEEE Middle East Conference on Communications and Networking (MECOM), 2025, pp. 1–6
2025
-
[15]
P. Tarafder, Z. Hassan, I. Ahmed, D. B. Rawat, K. Hasan, and C. Pu, “Digital-twin empowered deep reinforcement learning for site-specific radio resource management in nextg wireless aerial corridor,”arXiv preprint arXiv:2602.03801, 2026, submitted for possible publication to IEEE
-
[16]
Uplink radio resource block and power coordination in open ran-digital twin-integrated multi- cell internet of drone networks,
M. Elloumi, M. Z. Hassan, and G. Kaddoum, “Uplink radio resource block and power coordination in open ran-digital twin-integrated multi- cell internet of drone networks,”TechRxiv, Feb. 2026, posted on 2 Feb 2026; preprint
2026
-
[17]
Digital twin- assisted reinforcement learning for resource-aware microservice offload- ing in edge computing,
X. Chen, J. Cao, Z. Liang, Y . Sahni, and M. Zhang, “Digital twin- assisted reinforcement learning for resource-aware microservice offload- ing in edge computing,” in2023 IEEE 20th International Conference on Mobile Ad Hoc and Smart Systems (MASS), 2023
2023
-
[18]
Continual reinforcement learning for digital twin synchronization optimization,
H. Tong, M. Chen, J. Zhao, Y . Hu, Z. Yang, Y . Liu, and C. Yin, “Continual reinforcement learning for digital twin synchronization optimization,”IEEE Transactions on Mobile Computing, vol. 24, no. 8, pp. 6843–6857, 2025
2025
-
[19]
Data-driven cellular mobility management via bayesian optimization and reinforcement learning,
M. Benzaghta, S. Ammar, D. L ´opez-P´erez, B. Shihada, and G. Geraci, “Data-driven cellular mobility management via bayesian optimization and reinforcement learning,”arXiv preprint arXiv:2505.21249, 2025
-
[20]
Real: Reinforcement learning-enabled xapps for experimental closed-loop optimization in o- ran with osc ric and srsran,
R. Barker, A. E. Dorcheh, T. Seyfi, and F. Afghah, “Real: Reinforcement learning-enabled xapps for experimental closed-loop optimization in o- ran with osc ric and srsran,” in2025 IEEE International Conference on Communications Workshops (ICC Workshops), 2025, pp. 389–395
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.