Recognition: unknown
SpecEdit: Training-Free Acceleration for Diffusion based Image Editing via Semantic Locking
Pith reviewed 2026-05-09 16:46 UTC · model grok-4.3
The pith
SpecEdit accelerates diffusion image editing by using a low-resolution draft to lock most tokens at coarse resolution after checking token discrepancies for semantic changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a low-resolution draft can reliably estimate semantic editing outcomes, after which token-level discrepancies identify precisely which spatial tokens require high-resolution denoising; the remaining tokens can stay at coarse resolution without introducing structural inconsistency or quality loss.
What carries the argument
Draft-and-verify scheme that computes token-level discrepancies between a low-resolution semantic draft and the input image to select only edit-relevant tokens for high-resolution processing.
If this is right
- Up to 10x acceleration on Qwen-Image-Edit while keeping strong editing quality.
- Up to 7x acceleration on FLUX.1-Kontext-dev with comparable results.
- Further gains to 13x when combined with step distillation or other acceleration methods.
- Training-free applicability to existing diffusion editing pipelines without model changes.
Where Pith is reading between the lines
- The same discrepancy check could replace low-level heuristics such as edge detection in other dynamic-resolution sampling methods.
- Real-time or interactive editing interfaces on modest hardware become feasible if the draft step is made even lighter.
- The approach may generalize to video or 3D diffusion editing where spatial token costs dominate.
- Measuring discrepancy reliability across edit types would clarify when the method risks missing subtle changes.
Load-bearing premise
Token discrepancies computed from the low-resolution draft accurately mark every region where semantic editing is needed and do not cause inconsistencies when non-edit tokens remain coarse.
What would settle it
A test case where a required global or subtle semantic change produces no detectable token discrepancies, resulting in visible artifacts or missing edits when high-resolution denoising is skipped on those areas.
Figures
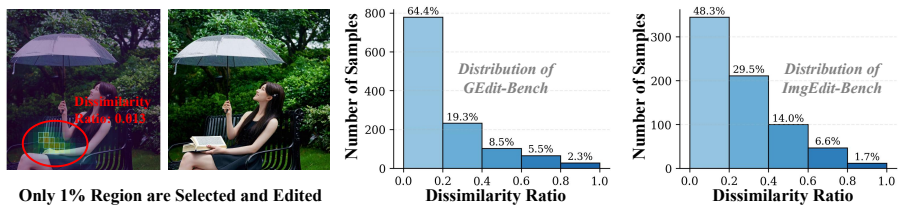



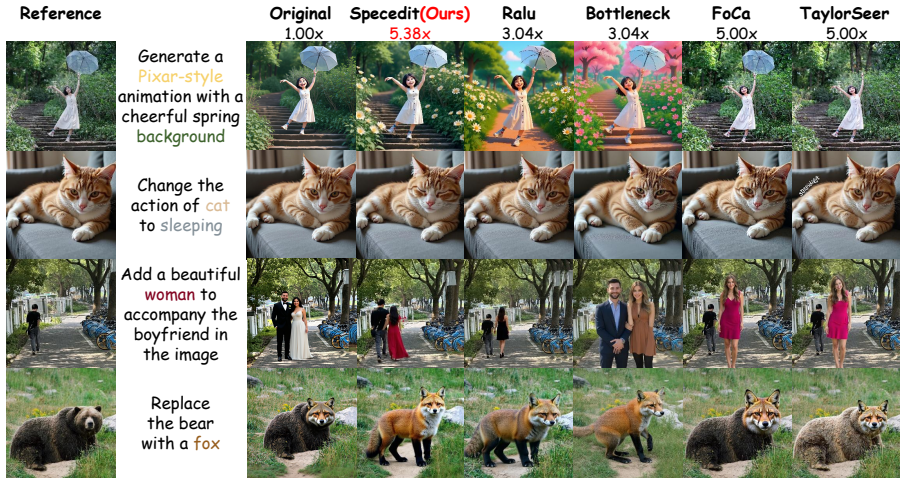





read the original abstract
Diffusion-based image editing offers strong semantic controllability, but remains computationally expensive due to iterative high-resolution denoising over all spatial tokens. Dynamic-resolution sampling reduces this cost by performing early steps at reduced resolution. However, existing approaches prioritize upsampling using low-level heuristics such as edge detection or channel variance, which are weakly aligned with editing semantics and may lead to structural inconsistency. Moreover, spatial regions are often upsampled without verifying whether semantic modification is actually required, resulting in redundant high-resolution computation and accumulated errors. Therefore, we propose SpecEdit, a training-free dynamic-resolution framework tailored for diffusion-based image editing. SpecEdit follows a draft-and-verify scheme: a low-resolution draft first estimates the semantic outcome, after which token-level discrepancies are used to identify edit-relevant tokens for high-resolution denoising, while the remaining tokens stay at a coarse resolution. Experiments on Qwen-Image-Edit and FLUX.1-Kontext-dev demonstrate up to 10x and 7x acceleration, while maintaining strong quality. SpecEdit is complementary to step distillation and other acceleration techniques, achieving up to 13x speedup when combined with existing methods. Our code is in supplementary material and will be released on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SpecEdit, a training-free dynamic-resolution framework for diffusion-based image editing. It follows a draft-and-verify scheme in which a low-resolution forward pass estimates the semantic outcome of the edit prompt; token-level discrepancies between this draft and the input are then used to identify edit-relevant tokens that receive full high-resolution denoising, while non-edit tokens remain at coarse resolution. Experiments on Qwen-Image-Edit and FLUX.1-Kontext-dev are reported to yield up to 10x and 7x acceleration respectively, with quality preserved; the method is also shown to combine with step distillation for up to 13x speedup.
Significance. If the central assumptions hold, SpecEdit would provide a practical, training-free acceleration technique that aligns computational effort with semantic edit regions rather than low-level heuristics, complementing existing distillation and scheduling methods. The approach could meaningfully lower inference costs for controllable image editing without requiring model retraining.
major comments (2)
- [Methods / draft-and-verify scheme] The draft-and-verify core (described in the abstract and methods overview) assumes that a single low-resolution pass produces a per-token discrepancy statistic sufficient to catch every region whose semantics change under the edit prompt and to leave remaining tokens at coarse resolution without introducing structural inconsistencies. No derivation, formal definition of the discrepancy operator, or ablation of this statistic is provided, which is load-bearing for both the acceleration and quality-preservation claims.
- [Abstract and Experiments] The abstract reports concrete speedups and quality preservation on two named models but supplies no details on the discrepancy metric, token selection threshold, exact upsampling schedule, or experimental controls (e.g., how mixed-resolution features are handled inside the U-Net or transformer blocks). This absence prevents verification that the method avoids boundary artifacts or missed edit regions, directly undermining the soundness of the reported 10x/7x/13x figures.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence clarification of how the mixed-resolution schedule is realized in the underlying architecture (Qwen-Image-Edit and FLUX.1-Kontext-dev).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, clarifying the current manuscript content where possible and outlining planned revisions to improve rigor and reproducibility.
read point-by-point responses
-
Referee: [Methods / draft-and-verify scheme] The draft-and-verify core (described in the abstract and methods overview) assumes that a single low-resolution pass produces a per-token discrepancy statistic sufficient to catch every region whose semantics change under the edit prompt and to leave remaining tokens at coarse resolution without introducing structural inconsistencies. No derivation, formal definition of the discrepancy operator, or ablation of this statistic is provided, which is load-bearing for both the acceleration and quality-preservation claims.
Authors: We agree that the manuscript would benefit from a more explicit formal definition and supporting ablation. The discrepancy operator is currently described in Section 3.2 as the token-wise semantic difference computed via cosine distance on projected features from the low-resolution draft versus the input. While the approach is primarily empirical rather than derived from first principles, we will add a formal definition of the operator, a brief motivation for its use in semantic locking, and a new ablation study (including edit-region detection precision/recall and structural consistency metrics) in the revised version. This directly addresses the load-bearing nature of the statistic for the reported speedups and quality claims. revision: yes
-
Referee: [Abstract and Experiments] The abstract reports concrete speedups and quality preservation on two named models but supplies no details on the discrepancy metric, token selection threshold, exact upsampling schedule, or experimental controls (e.g., how mixed-resolution features are handled inside the U-Net or transformer blocks). This absence prevents verification that the method avoids boundary artifacts or missed edit regions, directly undermining the soundness of the reported 10x/7x/13x figures.
Authors: We acknowledge that the current presentation lacks sufficient implementation details for independent verification. In the revised manuscript we will expand Section 3 and the experimental section to specify: the discrepancy metric (cosine similarity on CLIP-aligned token embeddings), the selection threshold (empirically set at 0.25), the progressive upsampling schedule (coarse-to-fine over the initial denoising steps), and the exact interpolation/fusion procedure for mixed-resolution features within transformer blocks. We will also include a short analysis of boundary artifacts and missed-region cases. The abstract will be updated with a concise reference to these parameters while respecting length limits. revision: yes
Circularity Check
No circularity: algorithmic scheduling heuristic with external empirical validation
full rationale
The paper introduces SpecEdit as a training-free dynamic-resolution scheduling method: a low-resolution draft estimates semantics, token-level discrepancies identify edit-relevant regions for high-resolution denoising, and non-edit tokens remain coarse. This is presented as a heuristic without equations that reduce to fitted parameters, self-definitions, or load-bearing self-citations. Claims of acceleration (up to 10x/7x, or 13x combined) rest on experiments with external models (Qwen-Image-Edit, FLUX.1-Kontext-dev) rather than internal fitting or renamed known results. No uniqueness theorems, ansatzes via prior self-work, or predictions-by-construction appear in the derivation. The approach is self-contained as a scheduling policy whose correctness is externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-resolution denoising can approximate the semantic outcome of full-resolution editing sufficiently well for discrepancy-based token selection.
Reference graph
Works this paper leans on
-
[1]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨ uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context imag...
2025
-
[3]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Ying- ming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
From reusing to forecasting: Accelerating diffusion models with taylorseers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerating diffusion models with taylorseers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15853–15863, 2025
2025
-
[6]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7353–7363, 2025
2025
-
[7]
Wongi Jeong, Kyungryeol Lee, Hoigi Seo, and Se Young Chun. Upsample what matters: Region-adaptive latent sampling for accelerated diffusion transformers.arXiv preprint arXiv:2507.08422, 2025
-
[8]
From sketch to fresco: Efficient diffusion transformer with progressive resolution
Shikang Zheng, Guantao Chen, Lixuan He, Jiacheng Liu, Yuqi Lin, Chang Zou, and Linfeng Zhang. From sketch to fresco: Efficient diffusion transformer with progressive resolution. arXiv preprint arXiv:2601.07462, 2026
-
[9]
Training-free diffusion acceleration with bottleneck sampling.arXiv preprint arXiv:2503.18940, 2025
Ye Tian, Xin Xia, Yuxi Ren, Shanchuan Lin, Xing Wang, Xuefeng Xiao, Yunhai Tong, Ling Yang, and Bin Cui. Training-free diffusion acceleration with bottleneck sampling.arXiv preprint arXiv:2503.18940, 2025
-
[10]
Spargeattn: Accurate sparse attention accelerating any model inference
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattn: Accurate sparse attention accelerating any model inference. In International Conference on Machine Learning (ICML), 2025. 13
2025
-
[11]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274– 19286. PMLR, 2023
2023
-
[12]
Adding conditional control to text- to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text- to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[13]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review arXiv 2022
-
[14]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6007–6017, 2023
2023
-
[15]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
2022
-
[17]
Dpm- solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Research, 22(4):730–751, 2025
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm- solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Research, 22(4):730–751, 2025
2025
-
[18]
Dpm-solver-v3: Improved diffusion ode solver with empirical model statistics.Advances in Neural Information Processing Systems, 36:55502–55542, 2023
Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Dpm-solver-v3: Improved diffusion ode solver with empirical model statistics.Advances in Neural Information Processing Systems, 36:55502–55542, 2023
2023
-
[19]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review arXiv 2022
-
[20]
Let features decide their own solvers: Hybrid feature caching for diffusion transformers, 2025
Shikang Zheng, Guantao Chen, Qinming Zhou, Yuqi Lin, Lixuan He, Chang Zou, Peiliang Cai, Jiacheng Liu, and Linfeng Zhang. Let features decide their own solvers: Hybrid feature caching for diffusion transformers, 2025
2025
-
[21]
Jiacheng Liu, Peiliang Cai, Qinming Zhou, Yuqi Lin, Deyang Kong, Benhao Huang, Yupei Pan, Haowen Xu, Chang Zou, Junshu Tang, et al. Freqca: Accelerating diffusion models via frequency-aware caching.arXiv preprint arXiv:2510.08669, 2025
-
[22]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document trans- former.arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[23]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review arXiv 1904
-
[24]
Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33:17283–17297, 2020
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33:17283–17297, 2020
2020
-
[25]
Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23(47):1–33, 2022
Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23(47):1–33, 2022. 14
2022
-
[26]
Srdiff: Single image super-resolution with diffusion probabilistic models
Haoying Li, Yifan Yang, Meng Chang, Shiqi Chen, Huajun Feng, Zhihai Xu, Qi Li, and Yueting Chen. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing, 479:47–59, 2022
2022
-
[27]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[28]
SpotEdit: Selective region editing in diffusion transformers.arXiv preprint arXiv:2512.22323, 2025
Zhibin Qin, Zhenxiong Tan, Zeqing Wang, Songhua Liu, and Xinchao Wang. Spotedit: Selective region editing in diffusion transformers.arXiv preprint arXiv:2512.22323, 2025
-
[29]
Training-free diffusion acceleration with bottleneck sampling, 2025
Ye Tian, Xin Xia, Yuxi Ren, Shanchuan Lin, Xing Wang, Xuefeng Xiao, Yunhai Tong, Ling Yang, and Bin Cui. Training-free diffusion acceleration with bottleneck sampling, 2025
2025
-
[30]
Accelerating diffusion transformers with token-wise feature caching.arXiv preprint arXiv:2410.05317,
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Linfeng Zhang. Accelerating diffu- sion transformers with token-wise feature caching.arXiv preprint arXiv:2410.05317, 2024
-
[31]
Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang. Fora: Fast-forward caching in diffusion transformer acceleration.arXiv preprint arXiv:2407.01425, 2024
-
[32]
Accelerating diffusion transformers with dual feature caching.arXiv preprint arXiv:2412.18911, 2024
Chang Zou, Evelyn Zhang, Runlin Guo, Haohang Xu, Conghui He, Xuming Hu, and Lin- feng Zhang. Accelerating diffusion transformers with dual feature caching.arXiv preprint arXiv:2412.18911, 2024
-
[33]
Shikang Zheng, Liang Feng, Xinyu Wang, Qinming Zhou, Peiliang Cai, Chang Zou, Ji- acheng Liu, Yuqi Lin, Junjie Chen, Yue Ma, et al. Forecast then calibrate: Feature caching as ode for efficient diffusion transformers.arXiv preprint arXiv:2508.16211, 2025. 15 Supplementary Material 7 Additional Ablation Studies Table 10: Ablation Study on FLUX.1-Kontext-de...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.