Recognition: unknown
Retrieval and Multi-Hop Reasoning in 1M-Token Context Windows: Evaluating LLMs on Classical Chinese Text
Pith reviewed 2026-05-09 16:41 UTC · model grok-4.3
The pith
Single-needle retrieval at 1M tokens succeeds for top LLMs while multi-hop reasoning reveals three distinct decay patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
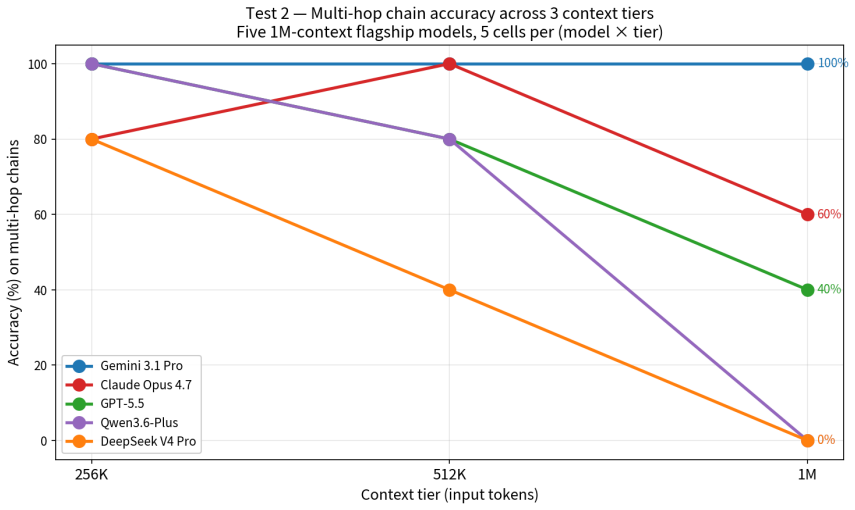
While single-needle retrieval at 1M tokens reaches 100% for Gemini 3.1 Pro, Claude Opus 4.7, and GPT-5.5 on both training-consistent and contradicting biographical facts from classical Chinese texts, three-hop chain traversal performance across 256K, 512K, and 1M contexts divides into a stable regime for Gemini and Claude, a late-cliff regime for GPT-5.5 and Qwen3.6-plus, and a smooth-decline regime for DeepSeek V4 Pro. This demonstrates that nominal context-window length is a poor proxy for usable long-context multi-hop capability, with the 512K-to-1M transition serving as the sharpest discriminator.
What carries the argument
The three-hop chain traversal test, which requires retrieving and connecting three planted biographical facts across the context to answer queries, using real and altered needle variants to confirm in-context retrieval.
If this is right
- Single-needle retrieval at the full 1M-token length is achievable by the current strongest models.
- Multi-hop reasoning does not scale uniformly with increasing context size across different models.
- The transition between 512K and 1M tokens exposes the largest gaps in capability.
- Models exhibit either stable, sudden, or gradual loss of multi-hop accuracy at longer contexts.
- Advertised context window size alone cannot be used to judge suitability for multi-step reasoning tasks.
Where Pith is reading between the lines
- Optimizing for the 512K-1M range could improve practical multi-hop performance in applications.
- Long-document reasoning systems may benefit from techniques that break chains into shorter segments.
- Testing on other languages or domains could verify if these decay signatures are widespread.
- Benchmarks should include multi-hop tests at full context lengths to better reflect real usability.
Load-bearing premise
The classical Chinese texts and the planted facts are not present in the models' training data, allowing the tests to measure genuine in-context retrieval and reasoning.
What would settle it
Re-running the single-needle retrieval at 1M tokens with the altered needles and finding that the top models score well below 100% would falsify the claim that this capability is solved.
Figures





read the original abstract
We evaluate the long-context retrieval and reasoning capabilities of five frontier large language models with advertised 1M-token context windows on a classical Chinese corpus. Two complementary studies are reported. Test 1 measures single-needle retrieval at 1M tokens of input, with three biographical needles planted at three depths and pairs of real (training-prior-consistent) and altered (training-prior-contradicting) variants to separate genuine in-context retrieval from reliance on memorised training data. Test 2, a follow-up designed to probe whether long-context capability degrades when retrieval requires intermediate reasoning, measures three-hop chain traversal across three context tiers (256K, 512K, and 1M tokens). We find that single-needle retrieval at 1M is essentially solved for the strongest models - Gemini 3.1 Pro, Claude Opus 4.7, and GPT-5.5 each achieve 100% - but that multi-hop performance reveals three distinct decay signatures: a stable regime (Gemini Pro, Claude) maintaining greater than 80% accuracy through 512K with modest degradation at 1M; a late-cliff regime (GPT-5.5, Qwen3.6-plus) collapsing sharply between 512K and 1M; and a smooth-decline regime (DeepSeek V4 Pro) decaying gradually across the entire range. The findings suggest that nominal context-window length is a poor proxy for usable long-context multi-hop capability, and that the sharpest discriminator between current 1M-context flagships is the 512K-to-1M transition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates five frontier LLMs with advertised 1M-token contexts on a classical Chinese biographical corpus. Test 1 plants single biographical needles at three depths in 1M-token inputs using both real (training-consistent) and altered (contradicting) variants to isolate in-context retrieval from memorization. Test 2 measures three-hop chain traversal at 256K, 512K, and 1M tokens. Results indicate that single-needle retrieval at 1M is solved for Gemini 3.1 Pro, Claude Opus 4.7, and GPT-5.5 (100% accuracy), while multi-hop performance shows three decay patterns: stable (>80% through 512K with modest drop at 1M for Gemini and Claude), late-cliff (sharp drop 512K-to-1M for GPT-5.5 and Qwen3.6-plus), and smooth-decline (gradual across range for DeepSeek V4 Pro). The authors conclude that nominal context length is a poor proxy for usable multi-hop capability.
Significance. If the empirical results hold after verification of methods and controls, the work provides a concrete demonstration that 1M context windows do not uniformly deliver long-context multi-hop reasoning, with the 512K-to-1M transition emerging as a key differentiator. The memorization-control design using real/altered variants is a methodological strength that strengthens the interpretation of in-context performance. The decay-signature taxonomy offers a practical lens for future benchmarking and model comparison in the long-context regime.
major comments (3)
- [Test 1] Test 1 description: while real vs. altered needle variants are used to separate retrieval from memorization, the manuscript provides no details on the exact alteration procedure, semantic distance metrics, or verification that altered needles remain sufficiently dissimilar to block partial pretraining recall in three-hop chains. This is load-bearing for the central claim that performance differences reflect in-context reasoning rather than contamination.
- [Test 2] Test 2 results: the three distinct decay signatures are presented as the key finding, yet the text does not include per-model accuracy tables, confidence intervals, or statistical tests comparing the regimes (e.g., whether the late-cliff collapse for GPT-5.5 is significantly steeper than the smooth decline for DeepSeek). Without these, the claim that the signatures are reliably distinct cannot be evaluated.
- [Methods] Methods overview: the abstract and results reference specific models and context tiers but omit exact prompt templates, chain-construction algorithm, success criteria for multi-hop traversal, and any ablation on needle placement or corpus selection. These omissions prevent independent replication and assessment of whether the reported 100% single-needle scores and decay patterns are robust to implementation choices.
minor comments (2)
- [Abstract] The abstract states 'modest degradation at 1M' for the stable regime without quantifying the drop (e.g., from >80% to what value), which reduces precision when comparing to the late-cliff regime.
- [Test 1] Model names (Gemini 3.1 Pro, Claude Opus 4.7, GPT-5.5) appear to be stylized or future-dated; the manuscript should clarify the exact versions evaluated and any access dates or API parameters used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to enhance clarity, rigor, and replicability.
read point-by-point responses
-
Referee: [Test 1] Test 1 description: while real vs. altered needle variants are used to separate retrieval from memorization, the manuscript provides no details on the exact alteration procedure, semantic distance metrics, or verification that altered needles remain sufficiently dissimilar to block partial pretraining recall in three-hop chains. This is load-bearing for the central claim that performance differences reflect in-context reasoning rather than contamination.
Authors: We agree that the current manuscript lacks sufficient detail on the needle alteration process, which is critical for interpreting the results as in-context retrieval. In the revised version, we will add a dedicated subsection in the Test 1 description that fully specifies the alteration procedure (e.g., targeted changes to key biographical facts while preserving syntactic structure), the semantic distance metrics used (such as embedding-based cosine similarity thresholds below a set cutoff), and verification steps confirming that altered variants contradict training priors without permitting partial recall. This addition will directly support the claim that performance differences arise from in-context processing rather than contamination. revision: yes
-
Referee: [Test 2] Test 2 results: the three distinct decay signatures are presented as the key finding, yet the text does not include per-model accuracy tables, confidence intervals, or statistical tests comparing the regimes (e.g., whether the late-cliff collapse for GPT-5.5 is significantly steeper than the smooth decline for DeepSeek). Without these, the claim that the signatures are reliably distinct cannot be evaluated.
Authors: We acknowledge that the manuscript would benefit from quantitative support to substantiate the distinctness of the three decay patterns. The revised manuscript will include full per-model accuracy tables for all context lengths (256K, 512K, 1M), 95% bootstrap confidence intervals, and statistical comparisons (e.g., tests for differences in performance drops or fitted regression slopes between regimes) to demonstrate that the stable, late-cliff, and smooth-decline signatures differ reliably. These additions will allow rigorous evaluation of the taxonomy. revision: yes
-
Referee: [Methods] Methods overview: the abstract and results reference specific models and context tiers but omit exact prompt templates, chain-construction algorithm, success criteria for multi-hop traversal, and any ablation on needle placement or corpus selection. These omissions prevent independent replication and assessment of whether the reported 100% single-needle scores and decay patterns are robust to implementation choices.
Authors: We recognize that the omissions in the Methods section hinder replicability and robustness assessment. In the major revision, we will expand the Methods section to include the exact prompt templates, a detailed description or pseudocode of the chain-construction algorithm, explicit success criteria for three-hop traversal, and ablation results on needle placement and corpus selection. These will confirm the robustness of the 100% single-needle retrieval scores and the observed multi-hop decay patterns across implementation variations. revision: yes
Circularity Check
No circularity: purely empirical measurement study with no derivations or self-referential reductions
full rationale
The paper is an empirical evaluation reporting measured accuracy of frontier LLMs on single-needle retrieval and three-hop reasoning tasks over a classical Chinese biographical corpus at 256K–1M token scales. It defines no equations, performs no parameter fitting, invokes no uniqueness theorems, and contains no self-citations that serve as load-bearing premises for any claimed result. The distinction between real and altered needles is a direct experimental control to isolate in-context behavior from memorization; the reported decay signatures (stable, late-cliff, smooth-decline) are raw performance observations across context tiers, not quantities derived from or equivalent to any prior fitted input or self-referential definition. The study is therefore self-contained against external benchmarks and exhibits no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cao, J., Liu, Y., Shi, Y., Ding, K., & Jin, L. (2024). WenMind: A Comprehensive Bench- mark for Evaluating Large Language Models in Chinese Classical Literature and Language Arts. Advances in Neural Information Processing Systems 37 (NeurIPS
2024
-
[2]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Datasets and Benchmarks Track . Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R. O., & Larson, J. (2024). From Local to Global: A GraphRAG Approach to Query-Focused Summarization. arXiv preprint arXiv:2404.16130. Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y., & Gins...
work page internal anchor Pith review arXiv 2024
-
[3]
RULER: What's the Real Context Size of Your Long-Context Language Models?
arXiv:2404.06654. Kamradt, G. (2023). Needle In A Haystack — Pressure Testing LLMs. GitHub repository, https://github.com/gkamradt/LLMTest_NeedleInAHaystack. Kuratov, Y., Bulatov, A., Anokhin, P., Rodkin, I., Sorokin, D., Sorokin, A., & Burtsev, M. (2024). BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a- Haystack. Advances in Neural ...
work page internal anchor Pith review arXiv 2023
-
[4]
Datasets and Benchmarks Track . arXiv:2406.10149. Li, K., Zhang, L., Jiang, Y., Xie, P., Huang, F., Wang, S., & Cheng, M. (2025b). LaRA: Bench- marking Retrieval-Augmented Generation and Long-Context LLMs — No Silver Bullet for LC or RAG Routing. Proceedings of the 42nd International Conference on Machine Learn- ing (ICML
-
[5]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
arXiv:2502.09977. Li, M., Zhang, S., Zhang, T., Duan, H., Liu, Y., & Chen, K. (2024). NeedleBench: Evaluating LLM Retrieval and Reasoning Across Varying Information Densities. Transactions on Machine Learning Research (TMLR), 09/2025 . arXiv:2407.11963. Li, X., Cao, Y., Ma, Y., & Sun, A. (2025a). Long Context vs. RAG for LLMs: An Evaluation and Revisits. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.