Recognition: 2 theorem links
· Lean TheoremA Treasure Trove of Performance: Analyzing the IO500 Submission Data
Pith reviewed 2026-05-08 18:38 UTC · model grok-4.3
The pith
IO500 submission packages supply detailed logs that expose storage behaviors hidden in aggregate rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
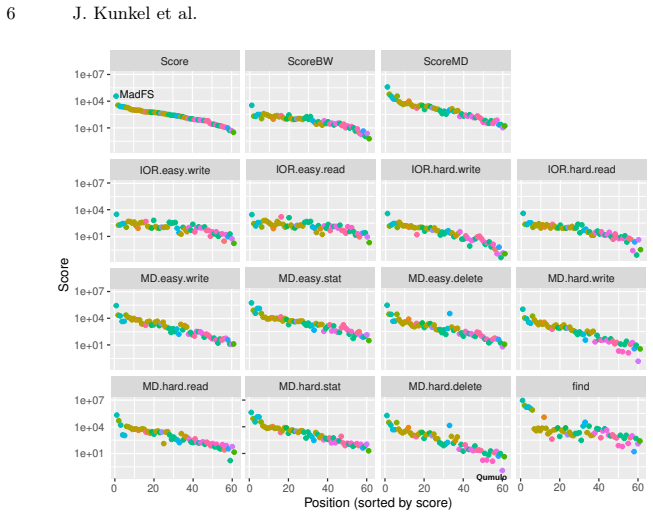
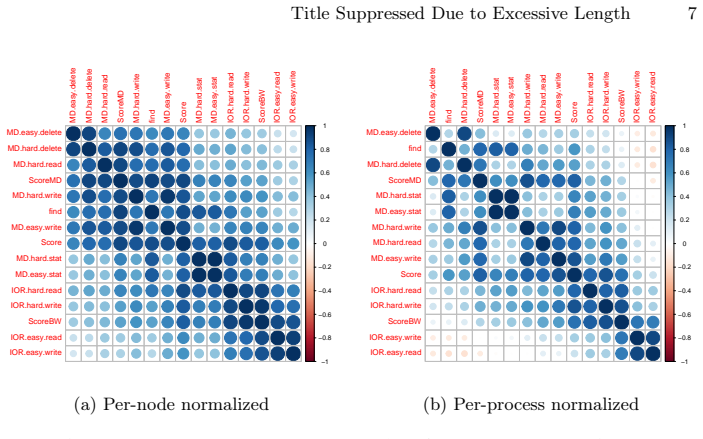
The authors establish that the complete IO500 submission packages, including their accompanying log files, form a valuable research resource for understanding storage system behavior, as shown by the wide score range, strong within-domain correlations (Spearman rs 0.78-0.98 for bandwidth and metadata phases), and concrete log-derived patterns such as IOR close-time overhead and parallel-find imbalance.
What carries the argument
Statistical characterization of submission scores combined with direct inspection of per-submission log files from the IOR and mdtest benchmarks.
If this is right
- IO500 scores vary across four orders of magnitude.
- Bandwidth phases correlate strongly with one another (rs = 0.78 to 0.96) and metadata phases likewise (rs = 0.89 to 0.98).
- Composite sub-scores correlate at rs = 0.92 when measured per node.
- Log analysis isolates IOR close-time overhead, stonewall-phase stragglers, and parallel-find load imbalance that remain invisible at the leaderboard level.
- The full dataset and analysis scripts are released publicly to support further study.
Where Pith is reading between the lines
- Benchmark organizers could add automated log summaries to future IO500 results so participants receive these insights without extra effort.
- The public repository enables direct comparisons of storage behavior across different file systems and installations over time.
- Patterns extracted from the logs could seed predictive models for how storage systems scale with node count or workload size.
Load-bearing premise
The 61 submissions and their log files are representative of typical HPC storage systems and free of systematic reporting bias.
What would settle it
A larger collection of IO500 submissions whose log files show no repeatable file-system-specific patterns or whose aggregate scores alone predict all observed overheads and imbalances would undermine the claim that the packages add unique research value.
Figures






read the original abstract
The IO500 benchmark has become the community standard for evaluating HPC storage system performance, yet the detailed data contained in its submission packages remains largely unexplored beyond aggregate leaderboard rankings. We present a statistical characterization of 61 IO500 submissions from four competition lists (ISC21 through SC22), examining score distributions, inter-phase correlations, and insights derived from detailed log files that accompany each submission. Our analysis reveals that IO500 scores span four orders of magnitude. Spearman correlation analysis shows strong within-domain clustering for both bandwidth (rs = 0.78 to 0.96) and metadata (rs = 0.89 to 0.98) phases, with the composite sub-scores exhibiting rs = 0.92 at per-node level (Pearson r = 0.53). Log-level analysis uncovers file-system-specific patterns in IOR close-time overhead, straggler behavior during the stonewall wear-down phase, and parallel-find load imbalance that are invisible in aggregate scores. These findings demonstrate that IO500 submission packages constitute a valuable research resource for understanding storage system behavior. The full submission dataset is publicly available at https://github.com/IO500/submission-data, and analysis scripts at https://gitlab-ce.gwdg.de/hpc-team/io500-analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a descriptive statistical analysis of 61 IO500 submissions from ISC21–SC22, documenting score spans of four orders of magnitude, strong within-domain Spearman correlations (rs = 0.78–0.98 for bandwidth and metadata phases), a composite sub-score correlation of rs = 0.92 (Pearson r = 0.53) at per-node level, and log-file observations on IOR close-time overhead, stonewall-phase stragglers, and parallel-find load imbalance. The central claim is that IO500 submission packages constitute a valuable research resource for understanding storage system behavior, supported by the public release of the full dataset and analysis scripts.
Significance. If the empirical patterns hold, the work establishes that detailed benchmark submission packages contain system-specific signals invisible in aggregate leaderboards. The explicit release of the dataset at https://github.com/IO500/submission-data and scripts at https://gitlab-ce.gwdg.de/hpc-team/io500-analysis provides a reproducible artifact that directly enables community reuse and further studies, which is a concrete strength.
minor comments (3)
- [correlation analysis] § on correlation analysis: the distinction between the reported Spearman rs = 0.92 and Pearson r = 0.53 for composite sub-scores at per-node level should be explained more explicitly, including the exact aggregation (e.g., how per-node values are computed from the 61 submissions) to avoid ambiguity in interpretation.
- [log-level analysis] Log-level analysis section: while patterns such as IOR close-time overhead and stonewall stragglers are described, the manuscript should include at least one concrete quantitative example (e.g., median overhead percentage or number of affected submissions) tied to specific log excerpts for each observation.
- [data and methods] Data and methods: the description of the 61-submission sample should state the exact inclusion criteria and any filtering steps applied to the public IO500 lists, even if brief, to allow readers to assess potential selection effects.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the recognition of the dataset and script releases as a concrete strength, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The manuscript is a purely descriptive statistical analysis of 61 external IO500 benchmark submissions. It reports score distributions, Spearman correlations (rs values), and log-derived observations such as IOR close-time overhead without any predictive modeling, parameter fitting to subsets, or first-principles derivations. The central claim that submission packages form a valuable research resource rests on the explicit public release of the full dataset and analysis scripts, which are independently verifiable outside the paper. No load-bearing step reduces by construction to fitted inputs, self-definitions, or self-citation chains; all quantitative results are direct computations from the provided external data.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Spearman and Pearson correlation assumptions hold for the observed score distributions
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.LogicAsFunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IO500 scores span four orders of magnitude ... CV exceeds 2.4 ... right-skewed distributions driven by a few high-performance systems.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Benjamini, Y., Hochberg, Y.: Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B (Methodological)57(1), 289–300 (1995).https://doi.org/10.1111/j. 2517-6161.1995.tb02031.x
work page doi:10.1111/j 1995
-
[2]
Carns, P., Harms, K., Allcock, W., Bacon, C., Lang, S., Latham, R., Ross, R.: Understanding and improving computational science storage access through continuous characterization. ACM Transactions on Storage (TOS)7(3), 1– 26 (2011).https://doi.org/10.1145/2027066.2027068,https://doi.org/10. 1145/2027066.2027068
-
[3]
In: Proceedings of the HPC Asia 2023 Workshops
Hennecke, M.: Understanding daos storage performance scalability. In: Proceedings of the HPC Asia 2023 Workshops. pp. 1–14 (2023).https://doi.org/10.1145/ 3581576.3581577,https://doi.org/10.1145/3581576.3581577 Title Suppressed Due to Excessive Length 13
-
[4]
Intel Corporation: DAOS: Distributed asynchronous object storage (2024),https: //docs.daos.io/, accessed: 2025-10-03
2024
-
[5]
com/IO500/submission-data, accessed: 2026-03-24
IO500 Community: IO500 submission data repository (2025),https://github. com/IO500/submission-data, accessed: 2026-03-24
2025
-
[6]
Kruskal, W.H., Wallis, W.A.: Use of ranks in one-criterion variance analysis. Journal of the American Statistical Association47(260), 583–621 (1952).https: //doi.org/10.1080/01621459.1952.10483441
-
[7]
White Paper (2016),https://pdsw.org/pdsw-discs17/wips/ kunkel-wip-pdsw-discs17.pdf
Kunkel, J., Bent, J., Lofstead, J., Markomanolis, G.S.: Establishing the io- 500 benchmark. White Paper (2016),https://pdsw.org/pdsw-discs17/wips/ kunkel-wip-pdsw-discs17.pdf
2016
-
[8]
In: In- ternational Conference on High Performance Computing
Kunkel, J., Betke, E.: Tracking user-perceived i/o slowdown via probing. In: In- ternational Conference on High Performance Computing. pp. 169–182. Springer (2019).https://doi.org/10.1007/978-3-030-34356-9_15,https://doi.org/ 10.1007/978-3-030-34356-9_15
-
[9]
In: High Performance Computing: ISC High Performance 2019 In- ternational Workshops
Kunkel, J., Lofstead, J., Bent, J.: The IO500 – benchmarking the I/O for su- percomputers. In: High Performance Computing: ISC High Performance 2019 In- ternational Workshops. pp. 580–590. Springer (2019).https://doi.org/10.1007/ 978-3-030-34356-9_44
2019
-
[10]
LLNL: mdtest – HPC metadata benchmark (2007),https://github.com/LLNL/ mdtest, available athttps://github.com/LLNL/mdtest
2007
-
[11]
Lockwood, G.K., Yoo, W., Byna, S., Wright, N.J., Snyder, S., Harms, K., Nault, Z., Carns, P.: Umami: a recipe for generating meaningful metrics through holistic i/o performance analysis. In: Proceedings of the 2nd Joint International Workshop on Parallel Data Storage & Data Intensive Scalable Computing Systems. pp. 55– 60 (2017).https://doi.org/10.1145/31...
-
[12]
In: SC’10: Proceedings of the 2010 ACM/IEEE International Confer- ence for High Performance Computing, Networking, Storage and Analysis
Lofstead, J., Zheng, F., Liu, Q., Klasky, S., Oldfield, R., Kordenbrock, T., Schwan, K., Wolf, M.: Managing variability in the io performance of petascale storage systems. In: SC’10: Proceedings of the 2010 ACM/IEEE International Confer- ence for High Performance Computing, Networking, Storage and Analysis. pp. 1–
2010
-
[13]
IEEE (2010).https://doi.org/10.1109/SC.2010.32,https://doi.org/10. 1109/SC.2010.32
-
[14]
Luu, H., Winslett, M., Gropp, W., Ross, R., Carns, P., Harms, K., Prabhat, M., Byna, S., Yao, Y.: A multiplatform study of I/O behavior on petascale su- percomputers. In: Proceedings of the 24th International Symposium on High- Performance Parallel and Distributed Computing. pp. 33–44 (2015).https://doi. org/10.1145/2749246.2749269,https://doi.org/10.1145...
-
[15]
In: 2019 IEEE/ACM Fourth International Parallel Data Sys- tems Workshop (PDSW)
Monnier, N., Lofstead, J., Lawson, M., Curry, M.: Profiling platform storage using io500 and mistral. In: 2019 IEEE/ACM Fourth International Parallel Data Sys- tems Workshop (PDSW). pp. 60–73. IEEE (2019).https://doi.org/10.1109/ PDSW49588.2019.00011,https://doi.org/10.1109/PDSW49588.2019.00011
-
[16]
In: Conference on File and Storage Technologies (FAST 02) (2002),https:// www.usenix.org/legacy/events/fast02/full_papers/schmuck/schmuck_html/
Schmuck, F., Haskin, R.: GPFS: A shared-disk file system for large computing clus- ters. In: Conference on File and Storage Technologies (FAST 02) (2002),https:// www.usenix.org/legacy/events/fast02/full_papers/schmuck/schmuck_html/
2002
-
[17]
In: Pro- ceedings of the 2003 Linux Symposium
Schwan, P., et al.: Lustre: Building a file system for 1000-node clusters. In: Pro- ceedings of the 2003 Linux Symposium. vol. 2003, pp. 380–386 (2003),https: //www.landley.net/kdocs/mirror/ols2003.pdf
2003
-
[18]
Kunkel et al
Shan, H., Shalf, J.: Using ior to analyze the i/o performance for hpc platforms (2007),https://escholarship.org/uc/item/9111c60j 14 J. Kunkel et al
2007
-
[19]
In: 2016 5th Workshop on Extreme-Scale Programming Tools (ESPT)
Snyder, S., Carns, P., Harms, K., Ross, R., Lockwood, G.K., Wright, N.J.: Modular HPC I/O characterization with Darshan. In: 2016 5th Workshop on Extreme-Scale Programming Tools (ESPT). pp. 9–17. IEEE (2016).https://doi.org/10.1109/ ESPT.2016.006,https://doi.org/10.1109/ESPT.2016.006
-
[20]
VI4IO Community: VI4IO: Virtual institute for I/O (2023),https://vi4io.org, accessed: 2025-10-03
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.