Beyond Known Objects: A Novel Framework for Open-Set Object Detection using Negative-Aware Norm
Pith reviewed 2026-05-09 15:49 UTC · model grok-4.3
The pith
Standard detectors already hold cues for unknown objects via a hidden-layer metric that needs almost no extra training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
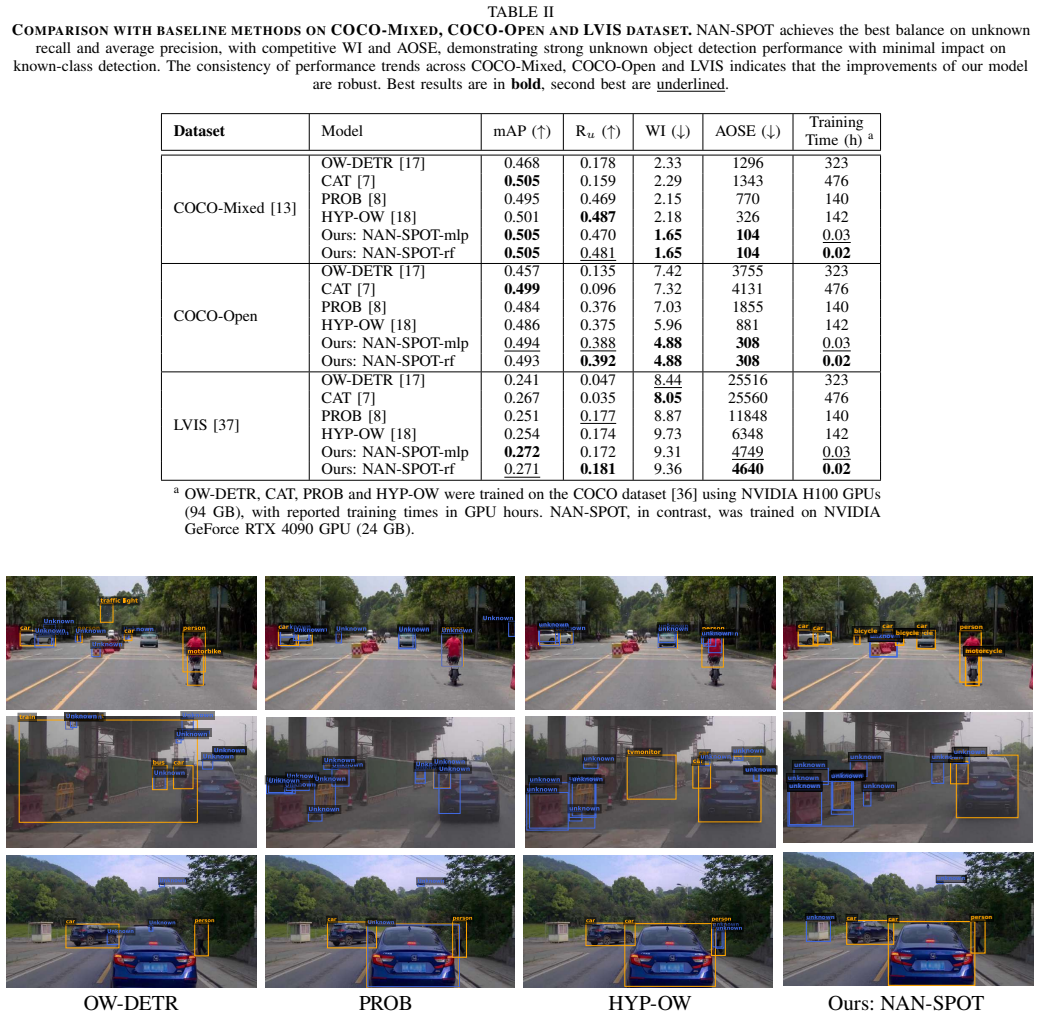
NAN-SPOT shows that computing the Negative-Aware Norm from a hidden layer of a frozen off-the-shelf detector estimates objectness well enough to surpass methods that retrain the detector extensively for open-set detection, while using far less data and time.
What carries the argument
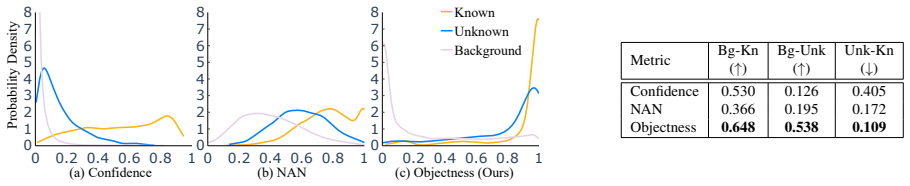
Negative-Aware Norm (NAN), a metric from a hidden layer that gauges objectness by incorporating information from negative samples.
If this is right
- Unknown-object detection exceeds the results of methods that retrain the full detector.
- Accuracy on known objects remains unchanged.
- Training takes minutes and uses only hundreds of images.
- COCO-Open supplies 1853 unknown annotations for more complete evaluation than prior datasets.
Where Pith is reading between the lines
- Many existing deployed detectors could gain open-set ability through a lightweight add-on rather than full replacement.
- Objectness may be a general latent property rather than one tied only to the specific training categories.
- The same norm-based approach could be tested on detectors for robotics or surveillance to check broader applicability.
Load-bearing premise
Training on many known categories has already imprinted useful objectness cues into the hidden layers of standard detectors.
What would settle it
Applying the Negative-Aware Norm to a detector trained on only a narrow set of categories and finding it performs no better than chance at separating unknowns on the expanded COCO-Open set would disprove the central premise.
Figures





read the original abstract
Open-Set Object Detection (OSOD) is crucial for autonomous driving, where perception systems must recognize and localize both known and previously unseen objects in complex, dynamic environments. While recent approaches deliver promising results, they often require retraining the detector extensively to learn objectness, which describes the likelihood that a bounding box tightly encloses a valid object, regardless of whether its category was learned during training. Deviating from existing work, we hypothesize that standard off-the-shelf detectors may already contain helpful cues for objectness, owing to their training on numerous and diverse known categories. Building on this idea, we propose NAN-SPOT, a training-light framework that does not require to retrain the base object detector and estimates objectness by leveraging a hidden layer metric called Negative-Aware Norm (NAN), requiring only minutes of training on just hundreds of images. To support comprehensive evaluation, we introduce COCO-Open, an expanded version of the existing COCO-Mixed dataset, increasing unknown object annotations from 433 to 1853, making it the most exhaustively labeled dataset for OSOD to the best of our knowledge. Experimental results demonstrate that NAN-SPOT achieves even better performance on unknown object detection than methods requiring heavy training, without compromising performance on known objects. This efficiency and robustness make NAN-SPOT a promising step towards open-world perception in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NAN-SPOT, a training-light open-set object detection framework that extracts a Negative-Aware Norm (NAN) metric from a hidden layer of an off-the-shelf detector to estimate objectness without retraining the base model. It introduces the COCO-Open dataset (expanding unknown annotations from 433 to 1853) and claims that NAN-SPOT outperforms heavily retrained OSOD baselines on unknown objects while preserving known-object performance, with only minutes of calibration on a few hundred images.
Significance. If the empirical claims hold, the work would be significant for autonomous driving and open-world perception by demonstrating that category-agnostic objectness cues may already exist in standard detectors, enabling efficient OSOD without the computational cost of full retraining. The expanded COCO-Open dataset is a clear positive contribution for future benchmarking.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that NAN-SPOT 'achieves even better performance on unknown object detection than methods requiring heavy training' is unsupported by any quantitative results, baselines, error bars, or evaluation protocol details in the provided text, preventing verification against the skeptic's concern that gains may be dataset artifacts.
- [§3] §3 (Method): The Negative-Aware Norm is introduced as encoding a category-agnostic objectness signal, but no distribution plots, statistical separation tests, or ablations on hidden-layer choice are described to confirm it distinguishes unknowns from background clutter rather than category-specific features.
- [§4] §4 (Experiments): No ablation on the light calibration set (hundreds of images) is reported to rule out overfitting to the particular unknown instances in COCO-Open, which is load-bearing for the claim that NAN generalizes beyond the calibration data.
minor comments (2)
- [Abstract] The abstract refers to 'COCO-Mixed dataset' without a citation; a reference to the original source should be added.
- [§3] Notation for NAN is introduced without an explicit equation; adding a formal definition (e.g., Eq. (X)) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We address each of the major comments point by point below, and we will incorporate revisions to strengthen the presentation and support for our claims.
read point-by-point responses
-
Referee: [Abstract and §4] The central claim that NAN-SPOT 'achieves even better performance on unknown object detection than methods requiring heavy training' is unsupported by any quantitative results, baselines, error bars, or evaluation protocol details in the provided text, preventing verification against the skeptic's concern that gains may be dataset artifacts.
Authors: We agree that additional quantitative details are necessary to fully substantiate the performance claims. The manuscript does report experimental results in §4, but to address this concern directly, we will revise the abstract and §4 to include explicit comparison tables with baselines, error bars from repeated experiments, and a detailed evaluation protocol description. This will allow readers to verify the results and confirm that improvements on unknown objects are robust. revision: yes
-
Referee: [§3] The Negative-Aware Norm is introduced as encoding a category-agnostic objectness signal, but no distribution plots, statistical separation tests, or ablations on hidden-layer choice are described to confirm it distinguishes unknowns from background clutter rather than category-specific features.
Authors: To provide evidence that NAN represents a category-agnostic objectness signal rather than category-specific features, we will augment §3 with distribution plots of NAN scores across known objects, unknown objects, and background clutter. Additionally, we will include statistical separation tests (e.g., t-tests or KS-tests) and ablations over different hidden layers to demonstrate the generality of the chosen metric. revision: yes
-
Referee: [§4] No ablation on the light calibration set (hundreds of images) is reported to rule out overfitting to the particular unknown instances in COCO-Open, which is load-bearing for the claim that NAN generalizes beyond the calibration data.
Authors: We recognize the value of such an ablation for validating generalization. In the revised manuscript, we will add experiments in §4 that ablate the calibration set size and composition, using varying numbers of images and different selections of unknown instances, to show that performance on unseen unknowns remains consistent and does not rely on overfitting to the calibration data. revision: yes
Circularity Check
No circularity: proposal rests on empirical hypothesis and external evaluation, not self-referential definitions or fitted predictions
full rationale
The paper advances a hypothesis that off-the-shelf detectors already encode objectness cues in hidden layers, then defines NAN as a simple norm-based metric extracted from those layers and evaluates it on an expanded dataset. No equations, derivations, or parameter-fitting steps are described that would reduce the claimed performance gains to the inputs by construction. The central claim is supported by comparative experiments rather than any self-citation chain or ansatz smuggled from prior author work. This is a standard empirical framework paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Negative-Aware Norm (NAN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yolov8: A novel object detection algo- rithm with enhanced performance and robustness,
R. Varghese and M. Sambath, “Yolov8: A novel object detection algo- rithm with enhanced performance and robustness,” in2024 International conference on advances in data engineering and intelligent computing systems. IEEE, 2024, pp. 1–6
work page 2024
-
[2]
Center-based 3d object detection and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793
work page 2021
-
[3]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2020–2036, 2025
work page 2020
-
[4]
Anomaly detection in autonomous driving: A survey,
D. Bogdoll, M. Nitsche, and J. M. Z ¨ollner, “Anomaly detection in autonomous driving: A survey,” inProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2022, pp. 4488–4499
work page 2022
-
[5]
Foundation models in autonomous driving: A survey on scenario generation and scenario analysis,
Y . Gao, M. Piccinini, Y . Zhang, D. Wang, K. Moller, R. Brusnicki, B. Zarrouki, A. Gambi, J. F. Totz, K. Stormset al., “Foundation models in autonomous driving: A survey on scenario generation and scenario analysis,”arXiv preprint arXiv:2506.11526, 2025
-
[6]
On perceptual uncertainty in autonomous driving under consideration of contextual awareness,
A. Saad, N. Bangalore, I. Kurzidem, and P. Schleiss, “On perceptual uncertainty in autonomous driving under consideration of contextual awareness,” in2022 6th International Conference on System Reliability and Safety (ICSRS). IEEE, 2022, pp. 387–393
work page 2022
-
[7]
Cat: Localization and identification cascade detection transformer for open- world object detection,
S. Ma, Y . Wang, Y . Wei, J. Fan, T. H. Li, H. Liu, and F. Lv, “Cat: Localization and identification cascade detection transformer for open- world object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 681–19 690
work page 2023
-
[8]
Prob: Probabilistic objectness for open world object detection,
O. Zohar, K.-C. Wang, and S. Yeung, “Prob: Probabilistic objectness for open world object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 444–11 453
work page 2023
-
[9]
Unknown-aware object detection: Learning what you don’t know from videos in the wild,
X. Du, X. Wang, G. Gozum, and Y . Li, “Unknown-aware object detection: Learning what you don’t know from videos in the wild,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 13 678–13 688
work page 2022
-
[10]
Detecting the unknown in object detection,
D. Fontanel, M. Tarantino, F. Cermelli, and B. Caputo, “Detecting the unknown in object detection,”CoRR, vol. abs/2208.11641, 2022
-
[11]
Uadet: A remarkably simple yet effective uncertainty-aware open-set object detection framework,
S. Cheng, Y . Liu, and K. Han, “Uadet: A remarkably simple yet effective uncertainty-aware open-set object detection framework,”CoRR, vol. abs/2412.09229, 2024
-
[12]
The overlooked elephant of object detection: Open set,
A. Dhamija, M. Gunther, J. Ventura, and T. Boult, “The overlooked elephant of object detection: Open set,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2020, pp. 1021– 1030
work page 2020
-
[13]
Unknown sniffer for object detection: Don’t turn a blind eye to unknown objects,
W. Liang, F. Xue, Y . Liu, G. Zhong, and A. Ming, “Unknown sniffer for object detection: Don’t turn a blind eye to unknown objects,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3230–3239
work page 2023
-
[14]
Novel scenes & classes: Towards adaptive open-set object detection,
W. Li, X. Guo, and Y . Yuan, “Novel scenes & classes: Towards adaptive open-set object detection,” inIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. IEEE, 2023, pp. 15 734–15 744
work page 2023
-
[15]
Opengan: Open-set recognition via open data generation,
S. Kong and D. Ramanan, “Opengan: Open-set recognition via open data generation,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 813–822
work page 2021
-
[16]
To- wards open world object detection,
K. J. Joseph, S. H. Khan, F. S. Khan, and V . N. Balasubramanian, “To- wards open world object detection,” inIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. Computer Vision Foundation / IEEE, 2021, pp. 5830–5840
work page 2021
-
[17]
OW-DETR: open-world detection transformer,
A. Gupta, S. Narayan, K. J. Joseph, S. Khan, F. S. Khan, and M. Shah, “OW-DETR: open-world detection transformer,” inIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 2022, pp. 9225–9234
work page 2022
-
[18]
T. Doan, X. Li, S. Behpour, W. He, L. Gou, and L. Ren, “Hyp- ow: Exploiting hierarchical structure learning with hyperbolic distance enhances open world object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 2, 2024, pp. 1555– 1563
work page 2024
-
[19]
Understanding the feature norm for out-of-distribution detection,
J. Park, J. C. L. Chai, J. Yoon, and A. B. J. Teoh, “Understanding the feature norm for out-of-distribution detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 1557–1567
work page 2023
-
[20]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213– 229
work page 2020
-
[21]
Deformable detr: De- formable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: De- formable transformers for end-to-end object detection,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[22]
Idpd: Improved deformable-detr for crowd pedestrian detection,
W. Han, N. He, X. Wang, F. Sun, and S. Liu, “Idpd: Improved deformable-detr for crowd pedestrian detection,”Signal, Image and Video Processing, vol. 18, no. 3, pp. 2243–2253, 2024
work page 2024
-
[23]
Airport uav and birds detection based on deformable detr,
L. Shanliang, L. Yunlong, Q. Jingyi, and W. Renbiao, “Airport uav and birds detection based on deformable detr,” inJournal of Physics: Conference Series, vol. 2253, no. 1. IOP Publishing, 2022, p. 012024
work page 2022
-
[24]
Y . Chen, C. Zhang, B. Chen, Y . Huang, Y . Sun, C. Wang, X. Fu, Y . Dai, F. Qin, Y . Penget al., “Accurate leukocyte detection based on deformable-detr and multi-level feature fusion for aiding diagnosis of blood diseases,”Computers in biology and medicine, vol. 170, p. 107917, 2024
work page 2024
-
[25]
Detreg: Unsupervised pretraining with region priors for object detection,
A. Bar, X. Wang, V . Kantorov, C. J. Reed, R. Herzig, G. Chechik, A. Rohrbach, T. Darrell, and A. Globerson, “Detreg: Unsupervised pretraining with region priors for object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 14 605–14 615
work page 2022
-
[26]
Dino: Detr with improved denoising anchor boxes for end-to-end object detection,
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,” inThe Eleventh International Conference on Learning Representations
-
[27]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137–1149, 2016
work page 2016
-
[28]
Exploring orthogonality in open world object detection,
Z. Sun, J. Li, and Y . Mu, “Exploring orthogonality in open world object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 302–17 312
work page 2024
-
[29]
Reducing network agnosto- phobia,
A. R. Dhamija, M. G ¨unther, and T. Boult, “Reducing network agnosto- phobia,”Advances in Neural Information Processing Systems, vol. 31, 2018
work page 2018
-
[30]
Out-of-distribution detection for reliable face recognition,
C. Yu, X. Zhu, Z. Lei, and S. Z. Li, “Out-of-distribution detection for reliable face recognition,”IEEE Signal Processing Letters, vol. 27, pp. 710–714, 2020
work page 2020
-
[31]
Norm-aware embedding for efficient person search,
D. Chen, S. Zhang, J. Yang, and B. Schiele, “Norm-aware embedding for efficient person search,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 12 615–12 624
work page 2020
-
[32]
Magface: A universal repre- sentation for face recognition and quality assessment,
Q. Meng, S. Zhao, Z. Huang, and F. Zhou, “Magface: A universal repre- sentation for face recognition and quality assessment,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 225–14 234
work page 2021
-
[33]
Unknown-aware hierarchical object detection in the context of automated driving,
J. Zhou, N. Wandelburg, and J. Beyerer, “Unknown-aware hierarchical object detection in the context of automated driving,” in2023 IEEE 26th International Conference on Intelligent Transportation Systems. IEEE, 2023, pp. 2501–2508
work page 2023
-
[34]
L. Breiman, “Random forests,”Machine learning, vol. 45, pp. 5–32, 2001
work page 2001
-
[35]
Learning repre- sentations by back-propagating errors,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning repre- sentations by back-propagating errors,”nature, vol. 323, no. 6088, pp. 533–536, 1986
work page 1986
-
[36]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision. Springer, 2014, pp. 740–755
work page 2014
-
[37]
Lvis: A dataset for large vocabulary instance segmentation,
A. Gupta, P. Dollar, and R. Girshick, “Lvis: A dataset for large vocabulary instance segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5356– 5364
work page 2019
-
[38]
Expanding low-density latent regions for open-set object detection,
J. Han, Y . Ren, J. Ding, X. Pan, K. Yan, and G. Xia, “Expanding low-density latent regions for open-set object detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 2022, pp. 9581–9590
work page 2022
-
[39]
Dropout sampling for robust object detection in open-set conditions,
D. Miller, L. Nicholson, F. Dayoub, and N. S ¨underhauf, “Dropout sampling for robust object detection in open-set conditions,” in2018 IEEE International Conference on Robotics and Automation. IEEE, 2018, pp. 3243–3249
work page 2018
-
[40]
Coda: A real-world road corner case dataset for object detection in autonomous driving,
K. Li, K. Chen, H. Wang, L. Hong, C. Ye, J. Han, Y . Chen, W. Zhang, C. Xu, D.-Y . Yeunget al., “Coda: A real-world road corner case dataset for object detection in autonomous driving,”arXiv preprint arXiv:2203.07724, 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.