Recognition: unknown
DriftDecode: One-Step Wireless Image Decoding via Drifting-Inspired Detail Recovery
Pith reviewed 2026-05-08 02:27 UTC · model grok-4.3
The pith
A single forward pass through an SNR-conditioned U-Net recovers high-quality wireless images by restoring channel-impaired details with a drifting-inspired texture loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
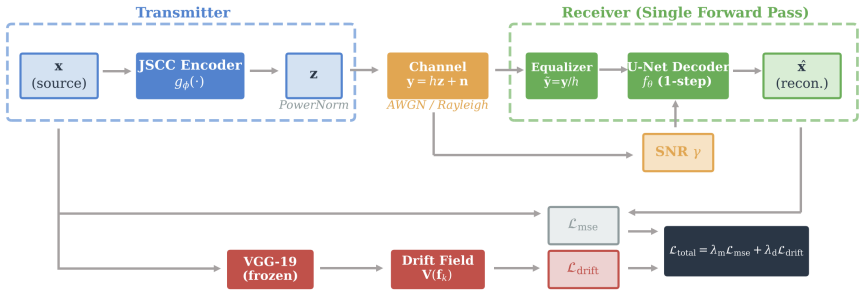
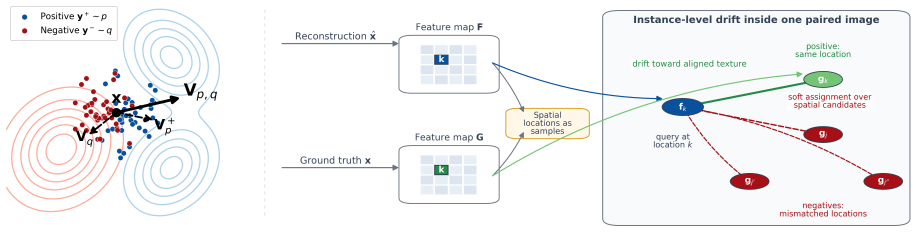
DriftDecode is an SNR-conditioned one-step U-Net decoder paired with a drift-inspired instance-level texture loss that reformulates the drifting-field mechanism from generative drifting models inside perceptual feature space, guiding each reconstructed local feature toward its spatially aligned ground-truth counterpart while suppressing mismatched textures, thereby enabling high-quality wireless image reconstruction at low latency.
What carries the argument
The drift-inspired instance-level texture loss, which transfers the drifting-field alignment mechanism into perceptual feature space to enforce spatially matched texture recovery.
Load-bearing premise
The received signal already preserves the coarse structure of the source image so that a single forward pass plus a drifting-inspired texture loss suffices for high-quality detail recovery without iterative refinement or additional side information.
What would settle it
An experiment in which coarse low-frequency image content is deliberately destroyed by extreme fading or severe noise before feeding the signal to the one-step decoder, then checking whether its PSNR falls below that of a multi-step generative baseline, would falsify the recovery-oriented premise.
Figures

read the original abstract
Generative receivers for wireless image transmission can improve reconstruction quality, but diffusion-based and flow-based decoding relies on iterative inference and therefore incurs substantial latency. In wireless image transmission, however, the received signal already preserves the coarse structure of the source image. Wireless decoding is therefore better viewed as a recovery task than as image generation from scratch, and the main challenge lies in restoring channel-impaired details. Motivated by this recovery-oriented perspective, this paper proposes DriftDecode, a signal-to-noise ratio (SNR)-conditioned one-step decoder for wireless image reconstruction. DriftDecode couples a one-step U-Net decoder with a drift-inspired instance-level texture loss. The loss reformulates the drifting-field mechanism from generative drifting models in perceptual feature space, guiding each reconstructed local feature toward its spatially aligned ground-truth counterpart while suppressing mismatched textures. Experiments on DIV2K and MNIST under additive white Gaussian noise (AWGN) and Rayleigh fading channels show a favorable quality-latency tradeoff. DriftDecode achieves 30~ms decoding latency, providing a 4.8$\times$ speedup over a 10-step flow-matching decoder, while consistently outperforming MSE-only training and yielding up to 1.13~dB PSNR gain on MNIST under Rayleigh fading. These results support recovery-oriented one-step decoding as an effective alternative to iterative generative decoding for low-latency wireless image transmission.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DriftDecode, an SNR-conditioned one-step U-Net decoder paired with a drift-inspired instance-level texture loss reformulated in perceptual feature space. It argues that wireless image decoding should be treated as detail recovery rather than generation from scratch because the received signal preserves coarse image structure. Experiments on DIV2K and MNIST under AWGN and Rayleigh fading report 30 ms latency (4.8× faster than a 10-step flow-matching baseline), consistent outperformance over MSE-only training, and up to 1.13 dB PSNR gain on MNIST under Rayleigh fading.
Significance. If the central recovery-oriented claim and reported gains hold after proper validation, the work provides a concrete low-latency alternative to iterative generative receivers for wireless image transmission. The adaptation of a drifting-field mechanism into a spatially aligned texture loss is a technically interesting contribution that could generalize beyond the tested datasets. The favorable quality-latency tradeoff is practically relevant for real-time applications, though its impact depends on whether the coarse-structure preservation assumption survives rigorous testing under realistic channel conditions.
major comments (3)
- [Abstract and §4] Abstract and §4 (experiments): The central claim that the received signal preserves coarse structure (allowing one-step recovery) is load-bearing yet unquantified. Under Rayleigh fading the multiplicative coefficients can distort low-frequency components even at moderate SNR; the manuscript should report a metric (e.g., low-frequency PSNR or structural similarity on downsampled versions) showing how often and to what degree this preservation holds across the tested SNR range, especially on DIV2K.
- [Abstract] Abstract: The reported 1.13 dB PSNR gain on MNIST under Rayleigh fading and the 4.8× speedup are presented without error bars, number of test samples, or ablation studies isolating the texture loss from the U-Net architecture and SNR conditioning. These omissions make it impossible to determine whether the gains are robust or sensitive to the specific channel realizations.
- [Method] Method description (implied in abstract): The drift-inspired texture loss is described as a reformulation in perceptual feature space, but no explicit equation or training hyper-parameters (e.g., feature extractor, weighting, or how the drifting field is discretized) are supplied. Without these, it is unclear whether the loss introduces new degrees of freedom that could explain the gains over plain MSE.
minor comments (2)
- [Abstract] Abstract: The latency figure of 30 ms should be accompanied by the hardware platform and batch size used for measurement to allow direct comparison with other one-step decoders.
- [Introduction] Notation: The term 'drifting-field mechanism' is introduced without a brief reference to the source generative model or a one-sentence recap of the original formulation, which would aid readers unfamiliar with that literature.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below, along with our plans for revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experiments): The central claim that the received signal preserves coarse structure (allowing one-step recovery) is load-bearing yet unquantified. Under Rayleigh fading the multiplicative coefficients can distort low-frequency components even at moderate SNR; the manuscript should report a metric (e.g., low-frequency PSNR or structural similarity on downsampled versions) showing how often and to what degree this preservation holds across the tested SNR range, especially on DIV2K.
Authors: We agree that providing quantitative evidence for the preservation of coarse structure is essential to substantiate our recovery-oriented approach. In the revised manuscript, we will include additional analysis in Section 4. Specifically, we will report low-frequency PSNR and structural similarity metrics on downsampled versions of the images for both MNIST and DIV2K datasets across the tested SNR ranges under AWGN and Rayleigh fading channels. This will quantify the extent to which coarse structure is preserved despite channel distortions. revision: yes
-
Referee: [Abstract] Abstract: The reported 1.13 dB PSNR gain on MNIST under Rayleigh fading and the 4.8× speedup are presented without error bars, number of test samples, or ablation studies isolating the texture loss from the U-Net architecture and SNR conditioning. These omissions make it impossible to determine whether the gains are robust or sensitive to the specific channel realizations.
Authors: We acknowledge that the current presentation lacks sufficient statistical details and ablations. In the revised version, we will add error bars to the reported PSNR gains and speedup factors, indicating the variability across multiple channel realizations or test runs. We will explicitly state the number of test samples used in the experiments. Furthermore, we will incorporate ablation studies in the experiments section to isolate the effect of the instance-level texture loss, comparing performance with and without it while controlling for the U-Net architecture and SNR conditioning. These additions will demonstrate the robustness of our results. revision: yes
-
Referee: [Method] Method description (implied in abstract): The drift-inspired texture loss is described as a reformulation in perceptual feature space, but no explicit equation or training hyper-parameters (e.g., feature extractor, weighting, or how the drifting field is discretized) are supplied. Without these, it is unclear whether the loss introduces new degrees of freedom that could explain the gains over plain MSE.
Authors: We regret that the explicit formulation and hyperparameters were not included in the initial submission. In the revised manuscript, we will provide the detailed equation for the drift-inspired texture loss in the Method section, showing how the drifting-field mechanism is reformulated in perceptual feature space. We will also specify all relevant training hyperparameters, including the choice of feature extractor (e.g., a pre-trained VGG network), the weighting coefficients for the loss terms, and the discretization strategy for the drifting field. This will clarify the implementation and allow for better assessment of its contribution relative to MSE training. revision: yes
Circularity Check
No significant circularity detected in DriftDecode derivation
full rationale
The paper motivates a recovery-oriented view from the premise that the received signal preserves coarse image structure under wireless channels, then proposes a one-step U-Net decoder paired with a texture loss that reformulates a drifting-field mechanism from generative models into perceptual feature space. All reported metrics (30 ms latency, 4.8× speedup, up to 1.13 dB PSNR gain) are presented as experimental outcomes on DIV2K and MNIST under AWGN and Rayleigh fading, not as quantities forced by internal fitting or self-referential equations. No load-bearing step reduces the central claims to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled without independent justification. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- SNR conditioning scalar
axioms (1)
- domain assumption The received signal preserves the coarse structure of the source image
Reference graph
Works this paper leans on
-
[1]
Deep joint source- channel coding for wireless image transmission,
E. Bourtsoulatze, D. B. Kurka, and D. G ¨und¨uz, “Deep joint source- channel coding for wireless image transmission,”IEEE Trans. Cogn. Commun. Netw., vol. 5, no. 3, pp. 567–579, Sep. 2019
2019
-
[2]
Wireless image transmission using deep source channel coding with attention modules,
J. Xu, B. Ai, W. Chen, A. Yang, P. Sun, and M. Rodrigues, “Wireless image transmission using deep source channel coding with attention modules,”IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 4, pp. 2315–2328, 2022
2022
-
[3]
OFDM-guided deep joint source channel coding for wireless multipath fading channels,
M. Yang, C. Bian, and H.-S. Kim, “OFDM-guided deep joint source channel coding for wireless multipath fading channels,”IEEE Trans. Cogn. Commun. Netw., vol. 8, no. 2, pp. 584–599, 2022
2022
-
[4]
CDDM: Channel denoising diffusion models for wireless semantic communications,
T. Wu, Z. Chen, D. He, L. Qian, Y . Xu, M. Tao, and W. Zhang, “CDDM: Channel denoising diffusion models for wireless semantic communications,”IEEE Trans. Wireless Commun., vol. 23, no. 9, pp. 11 168–11 183, 2024
2024
-
[5]
Land-then-transport: A flow matching-based generative decoder for wireless image transmis- sion,
J. Fu, M. Xiao, M. Skoglund, and D. I. Kim, “Land-then-transport: A flow matching-based generative decoder for wireless image transmis- sion,”arXiv preprint arXiv:2601.07512, 2026
-
[6]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inProc. ICLR, 2023
2023
-
[7]
Computation-resource- efficient task-oriented communications,
J. Fu, M. Xiao, C. Ren, and M. Skoglund, “Computation-resource- efficient task-oriented communications,”IEEE Trans. Commun., 2025
2025
-
[8]
The perception-distortion tradeoff,
Y . Blau and T. Michaeli, “The perception-distortion tradeoff,” inProc. CVPR, 2018
2018
-
[9]
Perceptual losses for real-time style transfer and super-resolution,
J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” inProc. ECCV, 2016, pp. 694–711
2016
-
[10]
Generative modeling via drifting,
W. Deng, R. Feng, and Q. Liu, “Generative modeling via drifting,” in Proc. ICML, 2026
2026
-
[11]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” inProc. ICLR, 2015
2015
-
[12]
U-Net: Convolutional net- works for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional net- works for biomedical image segmentation,” inProc. MICCAI, 2015, pp. 234–241
2015
-
[13]
FiLM: Visual reasoning with a general conditioning layer,
E. P ´erez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inProc. AAAI, 2018
2018
-
[14]
NTIRE 2017 challenge on single image super-resolution: Dataset and study,
E. Agustsson and R. Timofte, “NTIRE 2017 challenge on single image super-resolution: Dataset and study,” inProc. CVPR Workshops, 2017
2017
-
[15]
Multiscale structural sim- ilarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural sim- ilarity for image quality assessment,” inProc. Asilomar Conf. Signals, Syst. Comput., vol. 2, 2003, pp. 1398–1402
2003
-
[16]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. CVPR, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.