Recognition: 2 theorem links
· Lean TheoremTaming Request Imbalance: SLO-Aware Scheduling for Disaggregated LLM Inference
Pith reviewed 2026-05-08 18:24 UTC · model grok-4.3
The pith
Kairos improves TTFT SLO attainment by up to 24% and decode throughput by 19% in disaggregated LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
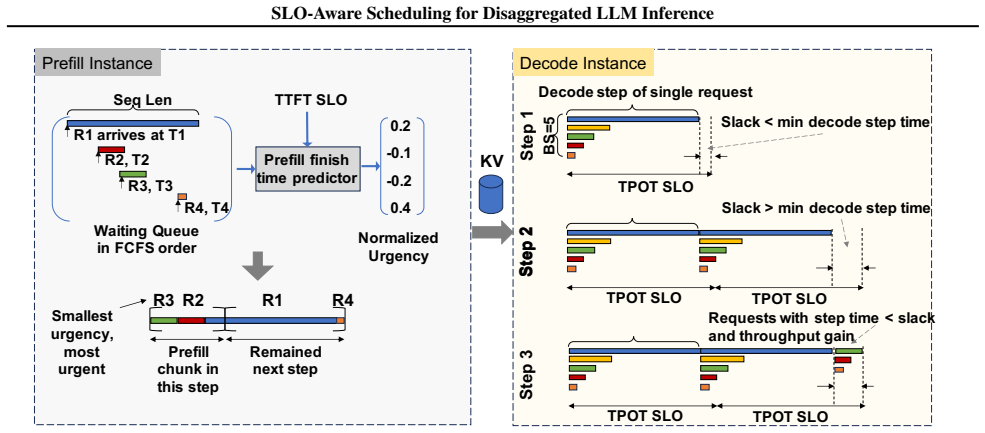
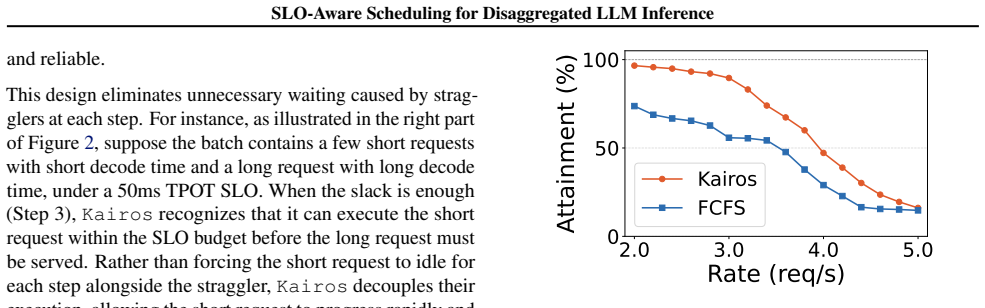
Kairos addresses request imbalance through urgency-based priority scheduling on the prefill side that dynamically selects requests based on predicted completion times to maximize TTFT SLO attainment, paired with slack-guided adaptive batching on the decode side that greedily packs short requests using the time gap to the TPOT SLO to maximize throughput while strictly meeting requirements. Evaluations on an online serving dataset with a state-of-the-art LLM show gains of up to 23.9% in TTFT SLO attainment, 27.1% in TPOT SLO attainment, 33.8% in end-to-end SLO attainment, and 19.3% in decode throughput versus state-of-the-art baselines.
What carries the argument
Kairos scheduling system consisting of urgency-based priority scheduling for prefill requests and slack-guided adaptive batching for decode requests.
If this is right
- Urgency-based selection reduces head-of-line blocking by long prefill requests for time-sensitive queries.
- Slack-guided batching increases decode throughput by allowing more short requests to run in parallel without SLO violations.
- Combined mechanisms improve end-to-end SLO attainment by optimizing both phases of the inference pipeline.
- Decode phase utilization rises as stragglers no longer dictate batch composition.
Where Pith is reading between the lines
- Similar priority and slack mechanisms could be adapted for other disaggregated computing tasks with variable task sizes.
- Improving the accuracy of prefill time predictors would directly amplify the benefits of the urgency scheduling.
- The system might enable serving larger models or higher loads on the same hardware by raising effective throughput.
Load-bearing premise
The prefill completion time predictions must be sufficiently accurate and the evaluation dataset must accurately represent real production request patterns for the scheduling to produce the claimed improvements.
What would settle it
An experiment that replaces the prefill time predictions with random or fixed values and observes that the SLO and throughput gains disappear would show that the prediction-based prioritization is essential to the results.
Figures



read the original abstract
In production environments, large language model (LLM) serving is required to meet stringent service-level objectives (SLOs) amid highly variable request patterns. In practice, request lengths follow a long-tail distribution, which gives rise to head-of-line blocking on the prefill side and underutilization caused by stragglers on the decode side in disaggregated serving architectures. Current systems, which adopt first-come-first-served (FCFS) scheduling for prefill and continuous batching for decode, lack the ability to adapt to this imbalance, resulting in compromised SLO attainment and reduced throughput. To address these challenges, we propose Kairos, an SLO-aware scheduling system equipped with two complementary mechanisms. On the prefill side, Kairos employs urgency-based priority scheduling: it predicts prefill completion times and dynamically selects requests to maximize the attainment of time-to-first-token (TTFT) SLOs. On the decode side, Kairos introduces slack-guided adaptive batching, which leverages the gap between per-step decode time and the time-per-output-token (TPOT) SLO to greedily pack short requests. This approach maximizes throughput while strictly adhering to SLO requirements. We implement Kairos and conduct evaluations using an online serving dataset and a state-of-the-art LLM. Experimental results demonstrate that, compared with state-of-the-art baselines, Kairos improves TTFT SLO attainment by up to 23.9\%, TPOT SLO attainment by up to 27.1\%, end-to-end SLO attainment by up to 33.8\%, and decode throughput by up to 19.3\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Kairos, an SLO-aware scheduler for disaggregated LLM inference serving. It introduces urgency-based priority scheduling on the prefill side that predicts per-request completion times to dynamically prioritize requests and maximize TTFT SLO attainment, and slack-guided adaptive batching on the decode side that uses the gap between per-step decode time and TPOT SLO to greedily pack short requests while maximizing throughput. Experiments on an online serving dataset with a state-of-the-art LLM report improvements over state-of-the-art baselines of up to 23.9% TTFT SLO attainment, 27.1% TPOT SLO attainment, 33.8% end-to-end SLO attainment, and 19.3% decode throughput.
Significance. If the central claims hold, the work addresses a practically important problem in production LLM serving: head-of-line blocking from long-tail request lengths in disaggregated prefill/decode architectures. The two mechanisms are complementary and directly target the FCFS and continuous-batching limitations described. The reported gains are large enough to be relevant for system designers, and the paper ships concrete implementation and evaluation artifacts that could be reproduced.
major comments (2)
- [§3.1] §3.1 (urgency-based priority scheduling): The prefill mechanism sets dynamic priorities from predicted completion times, yet the manuscript provides no quantitative validation of prediction accuracy (MAE, calibration plots, or sensitivity to batch size, KV-cache contention, or hardware jitter). Because the 23.9% TTFT improvement and the claim of outperforming FCFS both depend on the predictions producing a correct priority order, large errors could invert decisions and produce worse head-of-line blocking than the baseline the paper criticizes.
- [§4] §4 (evaluation): The online serving dataset is used to demonstrate the gains, but no statistical characterization of its length distribution, arrival process, or comparison to production traces is supplied. Without this, it is unclear whether the 33.8% end-to-end SLO improvement generalizes beyond the specific trace chosen.
minor comments (2)
- [§1] The definitions of TTFT and TPOT SLOs are introduced in the abstract and §1 but never given explicit mathematical formulations (e.g., as latency thresholds per request) before being used in the mechanisms of §3; adding these would improve clarity.
- [Table 2] Table 2 (or equivalent results table) reports percentage improvements but does not include absolute SLO attainment rates or confidence intervals; adding these would make the magnitude of the gains easier to interpret.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§3.1] §3.1 (urgency-based priority scheduling): The prefill mechanism sets dynamic priorities from predicted completion times, yet the manuscript provides no quantitative validation of prediction accuracy (MAE, calibration plots, or sensitivity to batch size, KV-cache contention, or hardware jitter). Because the 23.9% TTFT improvement and the claim of outperforming FCFS both depend on the predictions producing a correct priority order, large errors could invert decisions and produce worse head-of-line blocking than the baseline the paper criticizes.
Authors: We agree that the manuscript lacks quantitative validation of the prefill completion time predictions. This is a valid concern, as the urgency-based priority scheduling depends on these predictions for correct ordering. In the revised version, we will add an evaluation of prediction accuracy, including mean absolute error, calibration analysis, and sensitivity to batch size, KV-cache contention, and hardware variations. This will demonstrate that the predictions reliably support the priority decisions and the reported TTFT SLO gains. revision: yes
-
Referee: [§4] §4 (evaluation): The online serving dataset is used to demonstrate the gains, but no statistical characterization of its length distribution, arrival process, or comparison to production traces is supplied. Without this, it is unclear whether the 33.8% end-to-end SLO improvement generalizes beyond the specific trace chosen.
Authors: We acknowledge that the manuscript does not provide statistical characterization of the online serving dataset or comparisons to production traces. We will add this analysis in the revision, including details on request length distribution, arrival process, and relevant comparisons to publicly documented production workloads. This will better contextualize the generalizability of the 33.8% end-to-end SLO improvement and other results. revision: yes
Circularity Check
No circularity: empirical system with experimental validation
full rationale
The paper presents Kairos as an implemented scheduling system using urgency-based priority scheduling (via predicted prefill completion times) on the prefill side and slack-guided adaptive batching on the decode side. All performance claims (TTFT/TPOT/end-to-end SLO attainment and throughput gains) are derived from direct implementation, execution on an online serving dataset, and quantitative comparison against state-of-the-art baselines. No equations, derivations, or self-citations are shown that reduce any prediction, uniqueness claim, or result to a fitted input or prior author work by construction. The central mechanisms are design choices whose efficacy is measured externally rather than defined tautologically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Request lengths follow a long-tail distribution in production environments.
invented entities (1)
-
Kairos scheduling system
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (J(x) = ½(x + x⁻¹) − 1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
urgency_R = (SLO_TTFT − (T_finish − T_arrival)) / SLO_TTFT
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills,
Agrawal, A., Panwar, A., Mohan, J., Kwatra, N., Gulavani, B. S., and Ramjee, R. Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills.arXiv preprint arXiv:2308.16369,
- [3]
-
[4]
SageSched: Efficient LLM Scheduling Confronting Demand Uncer- tainty and Hybridity
Gan, Z., Bao, Y ., Liu, Y ., Chen, C., Chen, Q., and Guo, M. Sagesched: Efficient llm scheduling con- fronting demand uncertainty and hybridity.arXiv preprint arXiv:2603.07917,
-
[5]
arXiv preprint arXiv:2406.17565 (2024)
Hu, C., Huang, H., Hu, J., Xu, J., Chen, X., Xie, T., Wang, C., Wang, S., Bao, Y ., Sun, N., et al. Memserve: Con- text caching for disaggregated llm serving with elastic memory pool.arXiv preprint arXiv:2406.17565,
-
[6]
Ascendra: Dynamic request prioritization for efficient llm serving
Ikram, A., Li, X., Elnikety, S., and Bagchi, S. Ascendra: Dynamic request prioritization for efficient llm serving. arXiv preprint arXiv:2504.20828,
-
[7]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
-
[8]
Fast inference for augmented large language models.arXiv preprint arXiv:2410.18248, 2024a
Shahout, R., Liang, C., Xin, S., Lao, Q., Cui, Y ., Yu, M., and Mitzenmacher, M. Fast inference for augmented large language models.arXiv preprint arXiv:2410.18248, 2024a. Shahout, R., Malach, E., Liu, C., Jiang, W., Yu, M., and Mitzenmacher, M. Don’t stop me now: Embedding based scheduling for llms.arXiv preprint arXiv:2410.01035, 2024b. Shan, Y ., Huang...
-
[9]
Efficiently serv- ing large multimodal models using epd disaggregation
Singh, G., Wang, X., Hu, Y ., Yu, T., Xing, L., Jiang, W., Wang, Z., Bai, X., Li, Y ., Xiong, Y ., et al. Efficiently serv- ing large multimodal models using epd disaggregation. arXiv preprint arXiv:2501.05460,
-
[10]
Srivatsa, V ., He, Z., Abhyankar, R., Li, D., and Zhang, Y . Preble: Efficient distributed prompt scheduling for llm serving.arXiv preprint arXiv:2407.00023,
-
[11]
T., Wang, X., Fan, Y ., and Lan, Z
Tao, Y ., Zhang, Y ., Dearing, M. T., Wang, X., Fan, Y ., and Lan, Z. Prompt-aware scheduling for low-latency llm serving.arXiv preprint arXiv:2510.03243,
-
[12]
Wang, Y ., Jin, Z., Xu, J., Lin, W., Chen, Y ., and Chen, W. Augserve: Adaptive request scheduling for augmented large language model inference serving.arXiv preprint arXiv:2512.04013,
-
[13]
Fast distributed inference serving for large language models,
Wu, B., Zhong, Y ., Zhang, Z., Liu, S., Liu, F., Sun, Y ., Huang, G., Liu, X., and Jin, X. Fast distributed infer- ence serving for large language models.arXiv preprint arXiv:2305.05920,
-
[14]
A Survey of Large Language Models
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y ., Min, Y ., Zhang, B., Zhang, J., Dong, Z., et al. A survey of 9 SLO-Aware Scheduling for Disaggregated LLM Inference large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124,
-
[15]
A., Wang, D., Zhang, X., Zhou, H., Wei, H., Cheng, Y ., et al
Zhu, R., Jiang, Z., Jin, C., Wu, P., Stuardo, C. A., Wang, D., Zhang, X., Zhou, H., Wei, H., Cheng, Y ., et al. Megascale- infer: Efficient mixture-of-experts model serving with disaggregated expert parallelism. InProceedings of the ACM SIGCOMM 2025 Conference, pp. 592–608,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.