Recognition: 3 theorem links
· Lean TheoremChannel-Level Relation to Attentive Aggregation with Neighborhood-Homogeneity Constraint for Point Cloud Analysis
Pith reviewed 2026-05-11 02:04 UTC · model grok-4.3
The pith
PointCRA adds temporal trend variation and neighborhood homogeneity constraints to stop information loss from weight collapse in point cloud attention mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
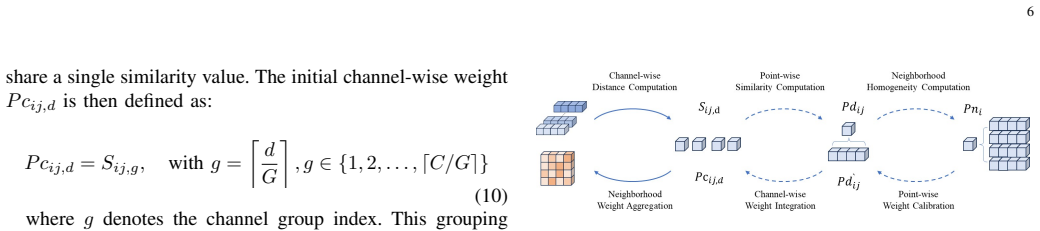
PointCRA is a network architecture whose central mechanism evaluates channel-level relations by adding temporal trend variation to existing spatial and channel responses. It then applies a neighborhood-homogeneity-guided multi-level calibration framework to adjust attention weights and introduces a dedicated loss that increases channel discriminability. This combination prevents the weight dimension collapse that otherwise discards information in deeper layers of multi-scale point cloud models and enables adaptive, prior-driven feature aggregation.
What carries the argument
Channel-level metric enhancement that incorporates temporal trend variation as an extra evaluation axis, combined with a neighborhood-homogeneity-guided multi-level weight calibration framework.
If this is right
- Semantic segmentation on S3DIS reaches 77.5 percent mIoU.
- Object classification on ScanObjectNN reaches 90.4 percent overall accuracy.
- Part segmentation on ShapeNetPart reaches 87.4 percent instance mIoU.
- The calibration module transfers to other multi-scale point cloud backbones with low parameter cost.
- The calibration process itself supplies an interpretable view of how weights are adjusted.
Where Pith is reading between the lines
- The same temporal-trend axis could be tested in other attention-heavy 3D pipelines where collapse has been observed.
- Neighborhood homogeneity as a calibration prior might transfer to mesh or voxel-based networks that currently lack channel-level corrections.
- The low-overhead design suggests the method could be inserted into real-time pipelines for autonomous driving without retraining the entire backbone.
Load-bearing premise
Adding a temporal trend dimension and a neighborhood homogeneity constraint will reliably block weight collapse and information loss in deeper layers without creating new failure modes in feature aggregation.
What would settle it
Running PointCRA on deeper variants of the same backbone networks and finding that attention weights still collapse or that accuracy falls below the unmodified baseline on S3DIS.
Figures










read the original abstract
In 3D point cloud understanding, the core challenge lies in accurately capturing discriminative features within complex neighborhoods, which directly affects the execution precision of downstream tasks such as embodied AI and autonomous driving. Existing methods explore feature correlation discrimination but are limited to point-level spatial distribution or channel responses, enabling only coarse-grained level evaluation. For modern multi-scale point cloud networks, such coarse-grained metrics inevitably incur significant information loss in deeper layers. To address this, we propose PointCRA, a novel network with a channel-level metric-based enhancement mechanism. Our core idea is to introduce temporal trend variation as a new evaluation dimension to avoid the information loss caused by weight dimension collapse in existing spatial and channel attention mechanisms. On this basis, we construct a multi-level calibration framework guided by neighborhood homogeneity for weight calibration, and design a dedicated loss function to enhance channel discriminability.PointCRA leverages intrinsic feature priors to adaptively correct feature aggregation, offering interpretability with low parameter overhead. Our method is transferable, interpretable, and efficient. We validate the proposed method on diverse datasets and benchmark models, and further demonstrate its rationality through extensive analytical experiments. Our PointCRA achieves 77.5\% mIoU on the S3DIS dataset, 90.4\% OA on the ScanObjectNN dataset, and 87.4\% instance mIoU on the ShapeNetPart dataset. The code and pretrained weights are publicly available on GitHub: https://github.com/AGENT9717/PointCRA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PointCRA, a network for point cloud analysis that introduces temporal trend variation as a new dimension to prevent information loss from weight dimension collapse in spatial/channel attention mechanisms. It adds a neighborhood-homogeneity-guided multi-level calibration framework and a dedicated loss function to enhance channel discriminability, claiming low parameter overhead, interpretability, and transferability. Reported results include 77.5% mIoU on S3DIS, 90.4% OA on ScanObjectNN, and 87.4% instance mIoU on ShapeNetPart, with public code release.
Significance. If the performance gains are causally linked to the temporal trend variation and homogeneity calibration (rather than other factors), the approach could provide a lightweight, interpretable way to improve attention mechanisms in multi-scale point cloud networks. Public code and weights support reproducibility, which strengthens the contribution if the core mechanism is validated.
major comments (3)
- [Abstract / Method] Abstract and Method section: the central claim attributes gains to temporal trend variation preventing weight dimension collapse, but no equations define this dimension, no attention-weight diagnostics (rank, entropy, or collapse metrics in deeper layers) are shown, and no ablation isolates its contribution from the calibration or loss function.
- [Experiments] Experiments section: reported benchmark numbers lack error bars, multiple runs, or comparisons against ablated variants (e.g., without temporal trend or without homogeneity constraint), so it is unclear whether the improvements stem from the proposed components or from hyperparameter tuning of the dedicated loss.
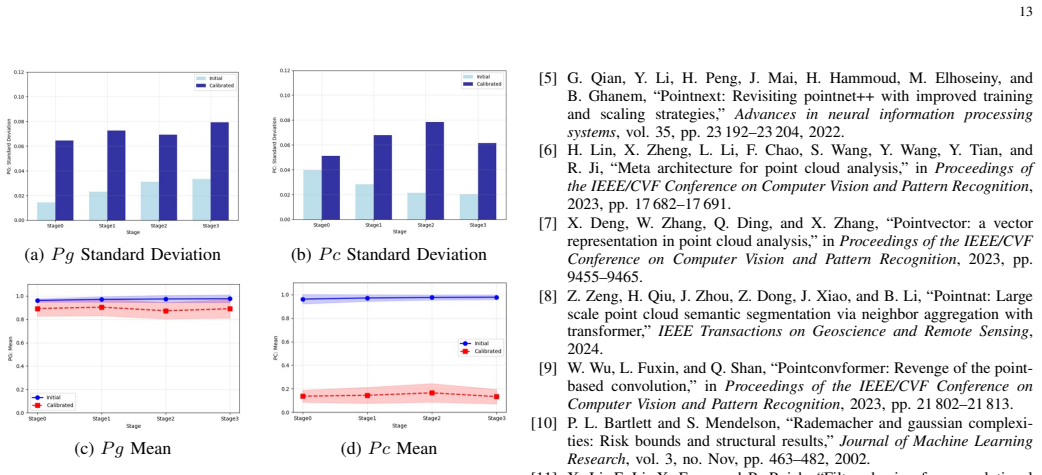
- [Method] The neighborhood-homogeneity calibration is described as increasing effective discriminability, yet no analysis demonstrates that it avoids introducing new collapse modes or distribution shifts in deeper layers of the multi-scale network.
minor comments (2)
- [Method] Notation for 'temporal trend variation' should be formalized with an equation early in the method to clarify its orthogonality to spatial and channel attentions.
- [Experiments] Figure captions and table legends could more explicitly link visual results to the claimed interpretability of the calibration framework.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment point-by-point below. The referee correctly identifies gaps in formalization, empirical validation, and analysis; we have revised the manuscript accordingly by adding definitions, ablations, error bars, and targeted diagnostics. All changes are detailed in the responses.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and Method section: the central claim attributes gains to temporal trend variation preventing weight dimension collapse, but no equations define this dimension, no attention-weight diagnostics (rank, entropy, or collapse metrics in deeper layers) are shown, and no ablation isolates its contribution from the calibration or loss function.
Authors: We agree that the original manuscript lacked explicit formalization. In the revised version we introduce Equation (3) in Section 3.2 that defines temporal trend variation as the layer-wise differential of the channel attention weight tensor: ΔW_t = W_{t+1} - W_t. We also add a new diagnostic subsection (4.3) reporting matrix rank, Shannon entropy, and Frobenius-norm collapse metrics computed on attention weights at layers 3, 6, and 9 of the backbone. Finally, we include a dedicated ablation table (Table 5) that isolates the temporal-trend term from both the homogeneity calibration and the dedicated loss, confirming its independent contribution. revision: yes
-
Referee: [Experiments] Experiments section: reported benchmark numbers lack error bars, multiple runs, or comparisons against ablated variants (e.g., without temporal trend or without homogeneity constraint), so it is unclear whether the improvements stem from the proposed components or from hyperparameter tuning of the dedicated loss.
Authors: We accept this criticism. The revised experiments section now reports all main results (Tables 1–3) with mean ± standard deviation over five independent random seeds. We have added three new ablation rows per benchmark: (i) PointCRA without temporal trend variation, (ii) without neighborhood-homogeneity calibration, and (iii) without the dedicated loss. These controlled variants demonstrate that each component contributes measurably beyond hyper-parameter effects of the loss alone. revision: yes
-
Referee: [Method] The neighborhood-homogeneity calibration is described as increasing effective discriminability, yet no analysis demonstrates that it avoids introducing new collapse modes or distribution shifts in deeper layers of the multi-scale network.
Authors: We have added a new analysis subsection (4.5) that tracks channel-wise feature variance, attention entropy, and Wasserstein distance between pre- and post-calibration distributions at every scale and depth. The results show that homogeneity calibration reduces intra-class variance while preserving inter-class separation and does not increase collapse indicators (rank or entropy) in deeper layers. We also include a short theoretical note explaining why the homogeneity prior is orthogonal to the temporal-trend mechanism and therefore does not create new collapse modes. revision: yes
Circularity Check
No significant circularity; new attention dimensions and constraints are independently defined
full rationale
The paper proposes PointCRA by introducing temporal trend variation as an additional evaluation dimension and a neighborhood-homogeneity-guided calibration framework with a dedicated loss, all presented as novel design choices built on existing attention mechanisms. No equations or steps in the provided description reduce the claimed performance gains to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation chain; the method is described as transferable and interpretable with low overhead, and results are validated on external benchmarks without the central claims collapsing to tautological inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- hyperparameters of the dedicated loss function
axioms (1)
- domain assumption Neighborhood homogeneity provides a reliable signal for weight calibration in point cloud feature aggregation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
introduce temporal trend variation as a new evaluation dimension... channel-wise distance computation based on layer-wise feature transformation trends... cosθ(l)ij,d = Δ(l)i,d · Δ(l)j,d / ... Sij,d = sum cosθ
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-level calibration framework guided by neighborhood homogeneity... Pn_i = 1 - exp(-vi / vmax_i)... wij,d = Pd'_ij · Pc'_ij,d
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lorth = 1/C(C-1) sum |wd1 · wd2| / (||wd1|| ||wd2||)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. Zhang, C. Wang, L. Yu, S. Tian, X. Ning, and J. Rodrigues, “Pointgt: A method for point-cloud classification and segmentation based on local geometric transformation,”IEEE Transactions on Multimedia, vol. 26, pp. 8052–8062, 2024
work page 2024
-
[2]
Sgg-nets: Generic rotation-invariant plugin networks for point cloud analysis,
J. Zhu, J. Yan, J. Huang, Y . Nie, B. Sheng, and T. Y . Lee, “Sgg-nets: Generic rotation-invariant plugin networks for point cloud analysis,” IEEE Transactions on Multimedia, 2025
work page 2025
-
[3]
Y . Chen, X. Zheng, Z. Yang, X. Li, J. Zhou, and Y . Li, “Dupmam: An efficient dual perception framework equipped with a sharp testing strategy for point cloud analysis,”IEEE Transactions on Multimedia, vol. 27, pp. 1760–1771, 2025
work page 2025
-
[4]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660
work page 2017
-
[5]
Pointnext: Revisiting pointnet++ with improved training and scaling strategies,
G. Qian, Y . Li, H. Peng, J. Mai, H. Hammoud, M. Elhoseiny, and B. Ghanem, “Pointnext: Revisiting pointnet++ with improved training and scaling strategies,”Advances in neural information processing systems, vol. 35, pp. 23 192–23 204, 2022
work page 2022
-
[6]
Meta architecture for point cloud analysis,
H. Lin, X. Zheng, L. Li, F. Chao, S. Wang, Y . Wang, Y . Tian, and R. Ji, “Meta architecture for point cloud analysis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 682–17 691
work page 2023
-
[7]
Pointvector: a vector representation in point cloud analysis,
X. Deng, W. Zhang, Q. Ding, and X. Zhang, “Pointvector: a vector representation in point cloud analysis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9455–9465
work page 2023
-
[8]
Pointconvformer: Revenge of the point- based convolution,
W. Wu, L. Fuxin, and Q. Shan, “Pointconvformer: Revenge of the point- based convolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21 802–21 813
work page 2023
-
[9]
Rademacher and gaussian complexi- ties: Risk bounds and structural results,
P. L. Bartlett and S. Mendelson, “Rademacher and gaussian complexi- ties: Risk bounds and structural results,”Journal of Machine Learning Research, vol. 3, no. Nov, pp. 463–482, 2002
work page 2002
-
[10]
Filter shaping for convolutional neural networks,
X. Li, F. Li, X. Fern, and R. Raich, “Filter shaping for convolutional neural networks,” inInternational Conference on Learning Representa- tions, 2017
work page 2017
-
[11]
M.-H. Guo, J.-X. Cai, Z.-N. Liu, T.-J. Mu, R. R. Martin, and S.-M. Hu, “Pct: Point cloud transformer,”Computational Visual Media, vol. 7, pp. 187–199, 2021
work page 2021
-
[12]
H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V . Koltun, “Point transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16 259–16 268
work page 2021
-
[13]
Point transformer v2: Grouped vector attention and partition-based pooling,
X. Wu, Y . Lao, L. Jiang, X. Liu, and H. Zhao, “Point transformer v2: Grouped vector attention and partition-based pooling,”Advances in Neural Information Processing Systems, vol. 35, pp. 33 330–33 342, 2022
work page 2022
-
[14]
Point transformer v3: Simpler faster stronger,
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao, “Point transformer v3: Simpler faster stronger,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4840–4851
work page 2024
-
[15]
X-3d: Explicit 3d structure modeling for point cloud recognition,
S. Sun, Y . Rao, J. Lu, and H. Yan, “X-3d: Explicit 3d structure modeling for point cloud recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5074–5083
work page 2024
-
[16]
J. Shi, J. Xiao, X. Hu, B. Song, H. Jiang, T. Chen, and B. Zhang, “Enhancing point cloud analysis via neighbor aggregation correction based on cross-stage structure correlation: J. shi et al.”The Visual Computer, pp. 1–17, 2025
work page 2025
-
[17]
Pointhop: An explainable machine learning method for point cloud classification,
M. Zhang, H. You, P. Kadam, S. Liu, and C.-C. J. Kuo, “Pointhop: An explainable machine learning method for point cloud classification,” IEEE Transactions on Multimedia, vol. 22, no. 7, pp. 1744–1755, 2020
work page 2020
-
[18]
J. Lin, J. Zou, K. Chen, J. Chai, and J. Zuo, “Ca-net: a context- awareness and cross-channel attention-based network for point cloud understanding,”Measurement Science and Technology, vol. 36, no. 4, p. 045207, 2025
work page 2025
-
[19]
Overlapping point cloud registration algorithm based on knn and the channel attention mechanism,
Y . Chen, F. Guo, J. Liu, S. Dai, J. Huang, and X. Cai, “Overlapping point cloud registration algorithm based on knn and the channel attention mechanism,”Plos one, vol. 20, no. 6, p. e0325261, 2025
work page 2025
-
[20]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[21]
Pointconv: Deep convolutional networks on 3d point clouds,
W. Wu, Z. Qi, and L. Fuxin, “Pointconv: Deep convolutional networks on 3d point clouds,” inProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2019, pp. 9621–9630
work page 2019
-
[22]
Pointnat: Large scale point cloud semantic segmentation via neighbor aggregation with transformer,
Z. Zeng, H. Qiu, J. Zhou, Z. Dong, J. Xiao, and B. Li, “Pointnat: Large scale point cloud semantic segmentation via neighbor aggregation with transformer,”IEEE Transactions on Geoscience and Remote Sensing, 2024
work page 2024
-
[23]
Pointcnn: Convolution on x-transformed points,
Y . Li, R. Bu, M. Sun, W. Wu, X. Di, and B. Chen, “Pointcnn: Convolution on x-transformed points,”Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[24]
Kpconv: Flexible and deformable convolution for point clouds,
H. Thomas, C. R. Qi, J.-E. Deschaud, B. Marcotegui, F. Goulette, and L. J. Guibas, “Kpconv: Flexible and deformable convolution for point clouds,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6411–6420
work page 2019
-
[25]
Kpconvx: Modernizing kernel point convolution with kernel attention,
H. Thomas, Y .-H. H. Tsai, T. D. Barfoot, and J. Zhang, “Kpconvx: Modernizing kernel point convolution with kernel attention,” inPro- 10 ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5525–5535
work page 2024
-
[26]
Paconv: Position adaptive convo- lution with dynamic kernel assembling on point clouds,
M. Xu, R. Ding, H. Zhao, and X. Qi, “Paconv: Position adaptive convo- lution with dynamic kernel assembling on point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3173–3182
work page 2021
-
[27]
Point attention network for semantic segmentation of 3d point clouds,
M. Feng, L. Zhang, X. Lin, S. Z. Gilani, and A. Mian, “Point attention network for semantic segmentation of 3d point clouds,”Pattern Recog- nition, vol. 107, p. 107446, 2020
work page 2020
-
[28]
Spiking point transformer for point cloud classification,
P. Wu, B. Chai, H. Li, M. Zheng, Y . Peng, Z. Wang, X. Nie, Y . Zhang, and X. Sun, “Spiking point transformer for point cloud classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 20, 2025, pp. 21 563–21 571
work page 2025
-
[29]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141
work page 2018
-
[30]
Fcanet: Frequency channel attention networks,
Z. Qin, P. Zhang, F. Wu, and X. Li, “Fcanet: Frequency channel attention networks,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 783–792
work page 2021
-
[31]
Distance guided channel weighting for semantic segmentation,
X. Liu, L. Zhu, S. Zhu, and L. Luo, “Distance guided channel weighting for semantic segmentation,”arXiv preprint arXiv:2004.12679, 2020
-
[32]
Eca-net: Efficient channel attention for deep convolutional neural networks,
Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, and Q. Hu, “Eca-net: Efficient channel attention for deep convolutional neural networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 534–11 542
work page 2020
-
[33]
3d semantic parsing of large-scale indoor spaces,
I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, and S. Savarese, “3d semantic parsing of large-scale indoor spaces,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1534–1543
work page 2016
-
[34]
ShapeNet: An Information-Rich 3D Model Repository
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Suet al., “Shapenet: An information- rich 3d model repository,”arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review arXiv 2015
-
[35]
M. A. Uy, Q.-H. Pham, B.-S. Hua, T. Nguyen, and S.-K. Yeung, “Re- visiting point cloud classification: A new benchmark dataset and clas- sification model on real-world data,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1588–1597
work page 2019
-
[36]
Window normalization: enhancing point cloud understanding by unifying inconsistent point densities,
Q. Wang, S. Shi, J. Li, W. Jiang, and X. Zhang, “Window normalization: enhancing point cloud understanding by unifying inconsistent point densities,”Image and Vision Computing, p. 105789, 2025
work page 2025
-
[37]
Sat: size-aware transformer for 3d point cloud semantic segmentation,
J. Zhou, Y . Xiong, C. Chiu, F. Liu, and X. Gong, “Sat: size-aware transformer for 3d point cloud semantic segmentation,”arXiv preprint arXiv:2301.06869, 2023
-
[38]
Hgca: Hypergraph neural network with cross-attention for point cloud analysis,
X. Hou, H. Feng, Z. Li, S. Zhou, J. Wang, Z. Fang, and X.-Q. Jiang, “Hgca: Hypergraph neural network with cross-attention for point cloud analysis,”Neurocomputing, p. 132874, 2026
work page 2026
-
[39]
Pointhr: Exploring high- resolution architectures for 3d point cloud segmentation,
H. Qiu, B. Yu, Y . Chen, and D. Tao, “Pointhr: Exploring high- resolution architectures for 3d point cloud segmentation,”arXiv preprint arXiv:2310.07743, 2023
-
[40]
Cloudmamba: Grouped selective state spaces for point cloud analysis,
K. Qu, P. Gao, Q. Dai, Z. Ye, R. Ye, and Y . Sun, “Cloudmamba: Grouped selective state spaces for point cloud analysis,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 11, 2026, pp. 8659–8667
work page 2026
-
[41]
DINO in the room: Leveraging 2D foundation models for 3D segmentation,
K. Knaebel, K. Yilmaz, D. de Geus, A. Hermans, D. Adrian, T. Linder, and B. Leibe, “DINO in the room: Leveraging 2D foundation models for 3D segmentation,” in2026 International Conference on 3D Vision (3DV), 2026
work page 2026
-
[42]
K. Qu, P. Gao, Q. Dai, and Y . Sun, “Point-focused attention meets context-scan state space: Robust biological visual perception for point cloud representation,” inThe Fourteenth International Conference on Learning Representations
-
[43]
X. Ning, L. Jiang, X. Zhang, Z. Wang, L. Zhang, Y . Yan, T. Wang, B. Lu, Y . Wang, and W. Li, “Hsbnet: Fusing semantics and anisotropic thermal diffusion fields for boundary-aware point cloud segmentation,” Information Fusion, p. 104246, 2026
work page 2026
-
[44]
Sonata: Self-supervised learning of reliable point representations,
X. Wu, D. DeTone, D. Frost, T. Shen, C. Xie, N. Yang, J. Engel, R. Newcombe, H. Zhao, and J. Straub, “Sonata: Self-supervised learning of reliable point representations,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 193–22 204
work page 2025
-
[45]
Decoupled local aggregation for point cloud learning
B. Chen, Y . Xia, Y . Zang, C. Wang, and J. Li, “Decoupled local aggregation for point cloud learning,”arXiv preprint arXiv:2308.16532, 2023
-
[46]
Ddgcn: graph convolution network based on direction and distance for point cloud learning,
L. Chen and Q. Zhang, “Ddgcn: graph convolution network based on direction and distance for point cloud learning,”The visual computer, vol. 39, no. 3, pp. 863–873, 2023
work page 2023
-
[47]
Advanced feature learning on point clouds using multi-resolution features and learnable pooling,
K. T. Wijaya, D.-H. Paek, and S.-H. Kong, “Advanced feature learning on point clouds using multi-resolution features and learnable pooling,” Remote Sensing, vol. 16, no. 11, p. 1835, 2024
work page 2024
-
[48]
Adacross- net: Adaptive dynamic loss weighting for cross-modal contrastive point cloud learning
O. V . Putra, K. Ogata, E. M. Yuniarno, and M. H. Purnomo, “Adacross- net: Adaptive dynamic loss weighting for cross-modal contrastive point cloud learning.”International Journal of Intelligent Engineering & Systems, vol. 18, no. 1, 2025
work page 2025
-
[49]
Point could mamba: Point cloud learning via state space model,
T. Zhang, X. Li, H. Yuan, S. Ji, and S. Yan, “Point could mamba: Point cloud learning via state space model,”arXiv preprint arXiv:2403.00762, 2024
-
[50]
Point geometrical coulomb force: An explicit and robust embedding for point cloud analysis,
H. Xu, L. Hu, Q. Li, S. Liu, D. M. Yan, and X. Liu, “Point geometrical coulomb force: An explicit and robust embedding for point cloud analysis,”Pattern Recognition, vol. 170, p. 112025, 2026
work page 2026
-
[51]
Mvformer: Multi-view point cloud transformer for 3d mechanical component recognition,
R. Wang, X. Ying, and B. Xing, “Mvformer: Multi-view point cloud transformer for 3d mechanical component recognition,”International Journal of Computer Vision, vol. 134, no. 1, p. 7, 2026
work page 2026
-
[52]
Cpg: Contrastive patch-graph learning for 3d point cloud,
J. Zhou, Y . Song, C. Chiuet al., “Cpg: Contrastive patch-graph learning for 3d point cloud,”Pattern Recognition, vol. 169, p. 111954, 2026
work page 2026
-
[53]
Spatially-enhanced spiking neural network for efficient point cloud analysis,
Y . Lu, Z. Pan, R. Zhanget al., “Spatially-enhanced spiking neural network for efficient point cloud analysis,”Neural Networks, p. 108190, 2025
work page 2025
-
[54]
Pointgl: A simple global-local framework for efficient point cloud analysis,
J. Li, J. Wang, and T. Xu, “Pointgl: A simple global-local framework for efficient point cloud analysis,”IEEE Transactions on Multimedia, vol. 26, pp. 6931–6942, 2024. VII. BIOGRAPHYSECTION Jiaqi ShiHe is currently pursuing the Ph.D. degree with the School of Automation Science and Electrical Engineering at Beihang University. His research interests inclu...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.