Recognition: 3 theorem links
· Lean TheoremInfoLaw: Information Scaling Laws for Large Language Models with Quality-Weighted Mixture Data and Repetition
Pith reviewed 2026-05-08 18:42 UTC · model grok-4.3
The pith
InfoLaw predicts LLM performance by modeling pretraining as the accumulation of information whose density is set by data quality and whose returns diminish with scale-dependent repetition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
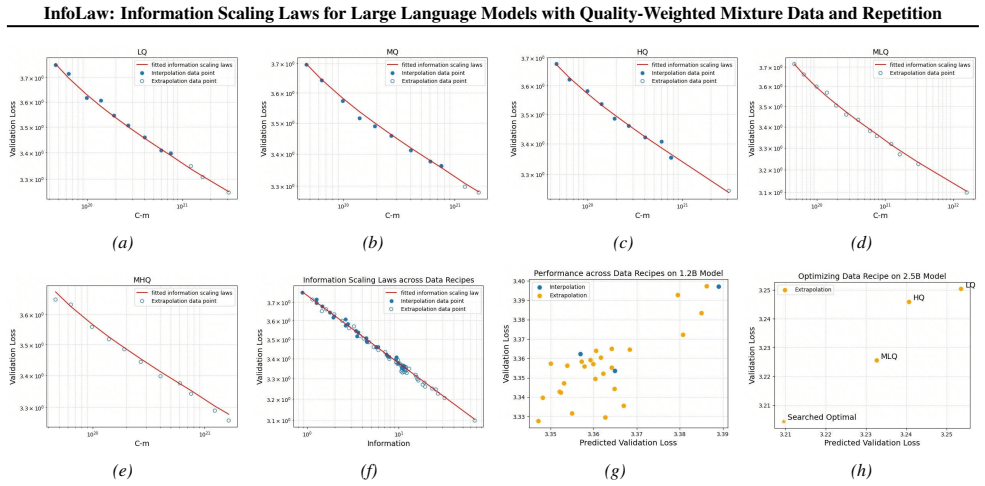
By representing pretraining as information accumulation in which quality sets information density per token and repetition induces scale-dependent diminishing returns, InfoLaw produces loss predictions that match observed values on unseen data mixtures and larger scales (up to 7B parameters, 425B tokens) with 0.15 percent mean and 0.96 percent maximum absolute error while remaining reliable under varying degrees of overtraining.
What carries the argument
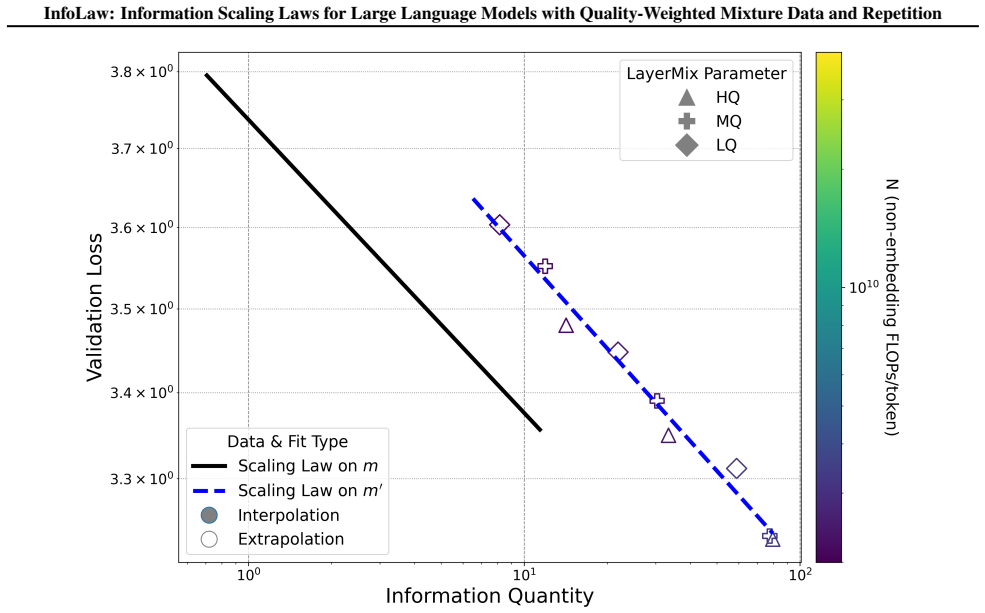
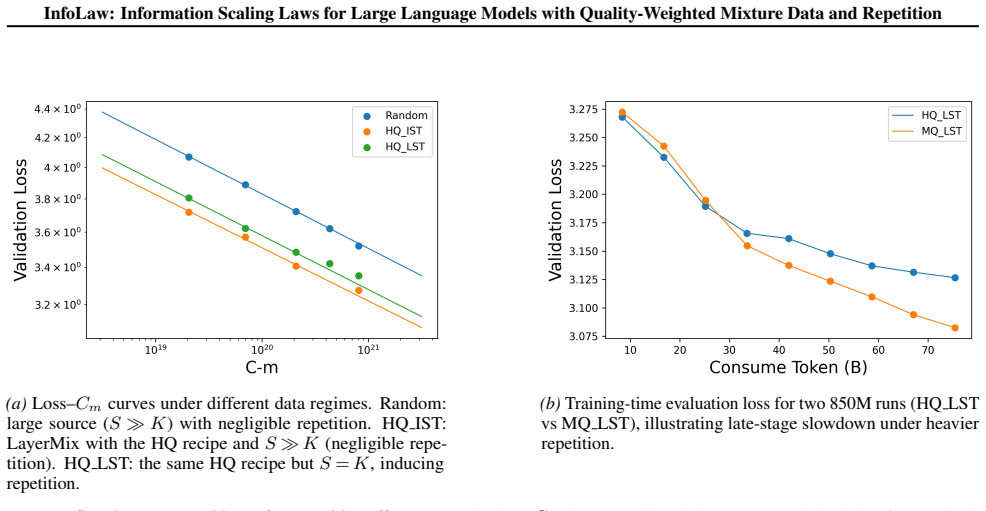
The information accumulation model that separates quality-controlled information density from scale-dependent repetition effects and converts total accumulated information into predicted loss.
If this is right
- Data-recipe selection for any compute budget can be performed by maximizing predicted information per token rather than by exhaustive search over mixtures.
- The same functional form extrapolates loss across overtraining levels, allowing reliable forecasts even when training runs exceed the point of optimal data efficiency.
- Mixture weights and repetition schedules can be optimized jointly with model size and total tokens inside a single predictive equation.
- New data sources can be incorporated by measuring their quality-derived information density and inserting the value into the existing accumulation equation without refitting the entire law.
Where Pith is reading between the lines
- The same information-density logic could be tested on continued pretraining or domain-adaptation runs to predict how much new data is required to reach a target loss.
- If quality can be estimated cheaply for web-scale corpora, InfoLaw supplies an objective function for automatic data filtering that directly targets training efficiency.
- Extending the repetition term to account for semantic rather than exact duplication might improve accuracy when training on synthetic or paraphrased data.
Load-bearing premise
The fitted relationship between accumulated information and loss continues to hold for data distributions, model architectures, and scales outside the range of the experiments used to build the model.
What would settle it
Train a 13B model on a previously untested high-repetition mixture whose predicted loss under InfoLaw differs by more than 1 percent from the measured loss after 400 billion tokens.
Figures

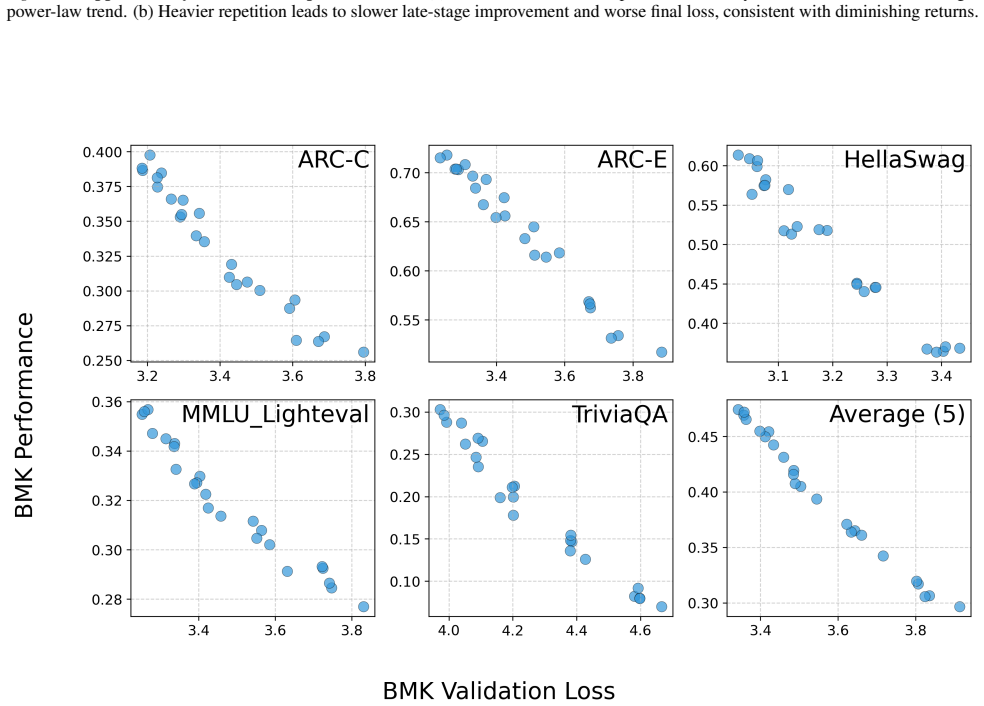





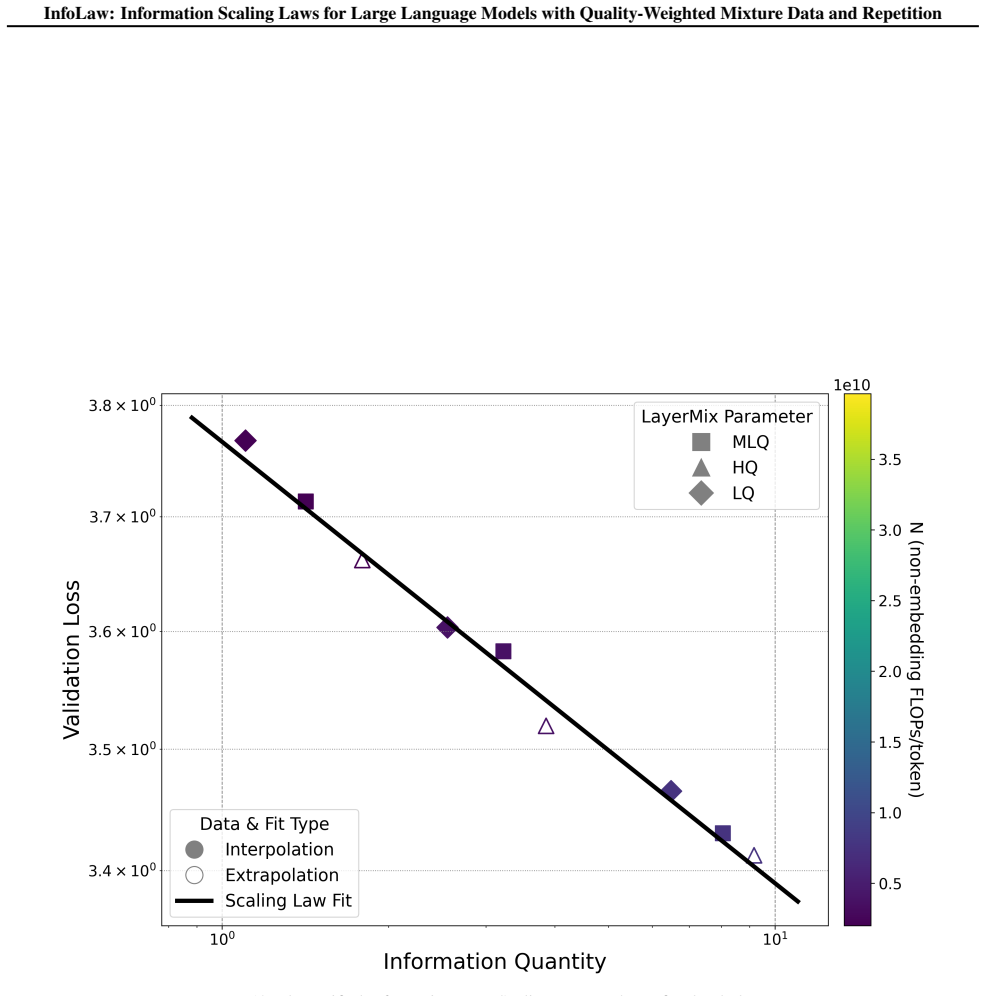
read the original abstract
Upweighting high-quality data in LLM pretraining often improves performance, but in datalimited regimes, especially under overtraining, stronger upweighting increases repetition and can degrade performance. However, standard scaling laws do not reliably extrapolate across mixture recipes or under repetitions, making the selection for optimal data recipes at scaling underdetermined. To solve this, we introduce InfoLaw (Information Scaling Laws), a data-aware scaling framework that predicts loss from consumed tokens, model size, data mixture weights, and repetition. The key idea is to model pretraining as information accumulation, where quality controls information density and repetition induces scaledependent diminishing returns. We first collect the model performance after training on datasets that vary in scale, quality distribution, and repetition level. Then we build up the modeling for information so that information accurately predicts those model performance. InfoLaw predicts performance on unseen data recipes and larger scale runs (up to 7B, 425B tokens) with 0.15% mean and 0.96% max absolute error in loss, and it extrapolates reliably across overtraining levels, enabling efficient data-recipe selection under varying compute budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InfoLaw, a data-aware scaling framework for LLMs that models pretraining loss as information accumulation. Quality controls information density while repetition induces scale-dependent diminishing returns; parameters for these effects are calibrated on collected performance data across scales, quality tiers, and repetition levels. The central claim is that the resulting model predicts loss on unseen data recipes and larger-scale runs (up to 7B parameters and 425B tokens) with 0.15% mean and 0.96% maximum absolute error, enabling reliable data-recipe selection under overtraining where standard scaling laws fail.
Significance. If the low reported errors reflect genuine out-of-sample generalization rather than in-sample fitting, InfoLaw would address a practical gap in LLM training by allowing principled optimization of quality-weighted mixtures under repetition constraints. This could improve compute efficiency in data-limited regimes. The work is credited for explicitly incorporating quality and repetition effects into a scaling model and for attempting extrapolation beyond the training distribution, though the strength of the supporting evidence remains limited by missing experimental details.
major comments (3)
- [Abstract] Abstract: the claim that InfoLaw 'predicts performance on unseen data recipes' with 0.15% mean error lacks any description of the validation protocol, including how recipes were partitioned, whether the density and repetition parameters were fitted on the full dataset or held-out subsets, data exclusion rules, or error-bar computation. This is load-bearing for the generalization claim because the model contains free parameters (information density coefficients per quality tier and scale-dependent repetition decay factor) that are calibrated directly on the collected performance data.
- [Modeling and results sections] Modeling and results sections: because the functional forms for quality-controlled density and scale-dependent diminishing returns are fitted to the same performance data used for validation, the low error on 'unseen' recipes may reflect interpolation within the fitted parameter space rather than independent extrapolation. No ablation or sensitivity analysis is described that would demonstrate the forms remain accurate for out-of-range mixtures, new architectures, or higher overtraining levels where standard scaling laws already break.
- [Extrapolation claims] Extrapolation claims: the reported success on runs up to 7B/425B tokens is presented without evidence that the repetition decay factor was held fixed (rather than re-tuned) when moving beyond the scales used for calibration, nor are confidence intervals or failure cases for the extrapolation provided.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight the need for greater transparency in our validation protocol, supporting analyses, and extrapolation procedure. We agree that these clarifications will strengthen the manuscript and will revise accordingly to address the points raised while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that InfoLaw 'predicts performance on unseen data recipes' with 0.15% mean error lacks any description of the validation protocol, including how recipes were partitioned, whether the density and repetition parameters were fitted on the full dataset or held-out subsets, data exclusion rules, or error-bar computation. This is load-bearing for the generalization claim because the model contains free parameters (information density coefficients per quality tier and scale-dependent repetition decay factor) that are calibrated directly on the collected performance data.
Authors: We agree that the abstract should be self-contained on this point. The parameters were fitted on a training subset of the performance data (smaller scales and a subset of mixture weights), with validation performed on held-out recipes that vary in quality distribution and repetition levels not used in fitting. Partitioning was done by reserving specific mixture compositions and higher repetition counts for testing; data exclusion rules removed certain low-quality tiers from the fitting set to test generalization. Error bars reflect standard deviation across three independent runs per configuration. We will revise the abstract to include a concise description of this protocol. revision: yes
-
Referee: [Modeling and results sections] Modeling and results sections: because the functional forms for quality-controlled density and scale-dependent diminishing returns are fitted to the same performance data used for validation, the low error on 'unseen' recipes may reflect interpolation within the fitted parameter space rather than independent extrapolation. No ablation or sensitivity analysis is described that would demonstrate the forms remain accurate for out-of-range mixtures, new architectures, or higher overtraining levels where standard scaling laws already break.
Authors: The functional forms were derived from information-theoretic considerations and fitted only on data from scales up to 1B parameters and moderate repetition; held-out validation includes out-of-range mixtures with higher repetition and different quality weightings. However, we acknowledge the absence of a dedicated ablation study or sensitivity analysis for new architectures and extreme overtraining. We will add an ablation subsection showing prediction error on progressively more extrapolated held-out mixtures and discuss limitations for new architectures and higher overtraining regimes. revision: partial
-
Referee: [Extrapolation claims] Extrapolation claims: the reported success on runs up to 7B/425B tokens is presented without evidence that the repetition decay factor was held fixed (rather than re-tuned) when moving beyond the scales used for calibration, nor are confidence intervals or failure cases for the extrapolation provided.
Authors: The repetition decay factor was calibrated exclusively on the smaller-scale data and applied without re-tuning to the 7B/425B-token runs. This procedure is described in the results section but will be made more explicit with the exact fitted value and a statement that no re-calibration occurred. We will also add confidence intervals derived from the parameter fitting covariance and a short discussion of observed failure modes, such as under-prediction when repetition exceeds the calibrated range. revision: yes
Circularity Check
No significant circularity: InfoLaw fits an empirical model to training data then validates predictions on held-out recipes and scales.
full rationale
The paper collects performance measurements across scales, quality distributions, and repetition levels, then posits an information-accumulation functional form (quality sets density; repetition adds scale-dependent diminishing returns) whose two parameters are calibrated to those measurements. It then reports 0.15% mean / 0.96% max absolute loss error on explicitly unseen data recipes and on larger runs (7B models, 425B tokens). Because the reported predictions are extrapolations to held-out points rather than re-statements of the fitted points themselves, and because no self-citation, uniqueness theorem, or ansatz-smuggling step is invoked to justify the functional form, the derivation chain does not reduce to its inputs by construction. The low held-out error constitutes independent empirical support rather than a tautology.
Axiom & Free-Parameter Ledger
free parameters (2)
- information density coefficients per quality tier
- scale-dependent repetition decay factor
axioms (1)
- domain assumption Pretraining loss can be modeled as accumulation of information whose density is controlled by data quality and whose marginal gain decreases with repetition in a scale-dependent manner
Lean theorems connected to this paper
-
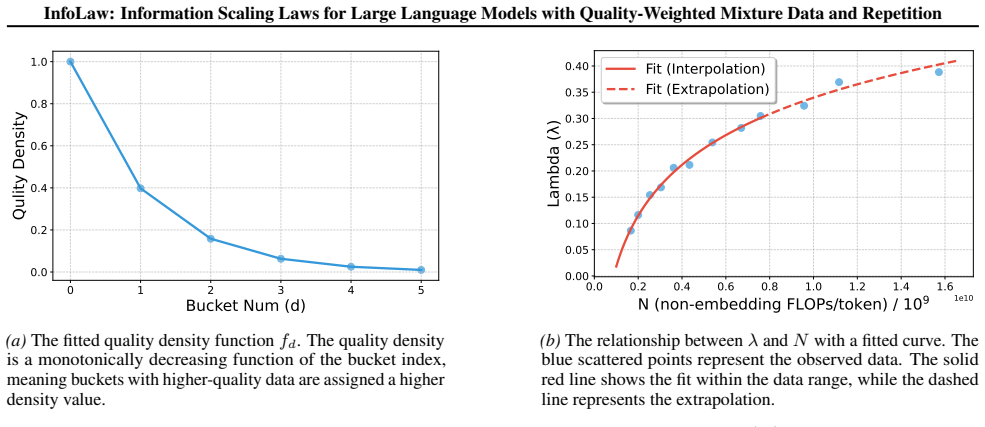
IndisputableMonolith.Cost (Jcost), IndisputableMonolith.Foundation.AxiomDischargePlanwashburn_uniqueness_aczel / dAlembert_cosh_solution_aczel unclearI_total = I_i · log(K) · (1 − e^{−λ(N)T/log(K)}); λ(N) = a·ln(N) + b; f_d = e^{−θd}; L = α · info^{−β}
-
IndisputableMonolith.Foundation.RealityFromDistinctionreality_from_one_distinction (parameter-free forcing) unclearWe first collect the model performance after training on datasets that vary in scale, quality distribution, and repetition level. Then we build up the modeling for information so that information accurately predicts those model performance.
-
IndisputableMonolith.Constants (phi, c, ℏ, G as φ-powers)phi_fixed_point / phi_golden_ratio unclearθ* = 0.922, a* = 0.140, b* = 0.018, α = 3.7373, β = 0.0441 (fitted empirically)
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[5]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[6]
Few-shot Learning with Multilingual Generative Language Models
Lin, Xi Victoria and Mihaylov, Todor and Artetxe, Mikel and Wang, Tianlu and Chen, Shuohui and Simig, Daniel and et al. Few-shot Learning with Multilingual Generative Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.616
-
[7]
2025 , eprint=
Scaling Laws for Downstream Task Performance in Machine Translation , author=. 2025 , eprint=
2025
-
[8]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
-
[9]
2023 , eprint=
Are Emergent Abilities of Large Language Models a Mirage? , author=. 2023 , eprint=
2023
-
[10]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Sardana, Nikhil and Portes, Jacob and Doubov, Sasha and Frankle, Jonathan , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[11]
2024 , eprint=
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism , author=. 2024 , eprint=
2024
-
[12]
Scaling Laws for Neural Language Models
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. CoRR , volume =. 2020 , url =. 2001.08361 , timestamp =
work page internal anchor Pith review arXiv 2020
-
[13]
2025 , eprint=
DataComp-LM: In search of the next generation of training sets for language models , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. 2024 , eprint=
2024
-
[15]
2023 , eprint=
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only , author=. 2023 , eprint=
2023
-
[16]
and Sifre, Laurent , title =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
2022
-
[17]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[18]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Villalobos, Pablo and Ho, Anson and Sevilla, Jaime and Besiroglu, Tamay and Heim, Lennart and Hobbhahn, Marius , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[19]
2024 , eprint=
Scaling Parameter-Constrained Language Models with Quality Data , author=. 2024 , eprint=
2024
-
[20]
2024 , eprint=
D-CPT Law: Domain-specific Continual Pre-Training Scaling Law for Large Language Models , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
CMR Scaling Law: Predicting Critical Mixture Ratios for Continual Pre-training of Language Models , author=. 2024 , eprint=
2024
-
[22]
2025 , eprint=
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
AutoScale: Scale-Aware Data Mixing for Pre-Training LLMs , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Sub-Scaling Laws: On the Role of Data Density and Training Strategies in LLMs , author=. 2025 , eprint=
2025
-
[25]
and Barak, Boaz and Le Scao, Teven and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin , title =
Muennighoff, Niklas and Rush, Alexander M. and Barak, Boaz and Le Scao, Teven and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[26]
2022 , eprint=
Scaling Laws and Interpretability of Learning from Repeated Data , author=. 2022 , eprint=
2022
-
[27]
Deduplicating training data makes language models better
Lee, Katherine and Ippolito, Daphne and Nystrom, Andrew and Zhang, Chiyuan and Eck, Douglas and Callison-Burch, Chris and Carlini, Nicholas. Deduplicating Training Data Makes Language Models Better. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.577
-
[28]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus and Barret Zoph and Noam Shazeer , title =. CoRR , volume =. 2021 , url =. 2101.03961 , timestamp =
work page internal anchor Pith review arXiv 2021
-
[29]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[30]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness and Sharan Narang and Newsha Ardalani and Gregory F. Diamos and Heewoo Jun and Hassan Kianinejad and Md. Mostofa Ali Patwary and Yang Yang and Yanqi Zhou , title =. CoRR , volume =. 2017 , url =. 1712.00409 , timestamp =
work page internal anchor Pith review arXiv 2017
-
[31]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[32]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W. Rae and Sebastian Borgeaud and Trevor Cai and Katie Millican and Jordan Hoffmann and H. Francis Song and John Aslanides and Sarah Henderson and Roman Ring and Susannah Young and Eliza Rutherford and et al , title =. CoRR , volume =. 2021 , url =. 2112.11446 , timestamp =
work page internal anchor Pith review arXiv 2021
-
[33]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and et al , booktitle =. Language Models are Few-Shot Learners , url =
-
[34]
Language Models are Unsupervised Multitask Learners , url =
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , biburl =. Language Models are Unsupervised Multitask Learners , url =. OpenAI , keywords =
-
[35]
, title =
Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and et al. , title =. Journal of Machine Learning Research , year =
-
[36]
, booktitle =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and et al. , booktitle =. Language Models are Few-Shot Learners , url =
-
[37]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[38]
RoFormer: Enhanced transformer with Rotary Position Embedding , journal =
Jianlin Su and Murtadha Ahmed and Yu Lu and Shengfeng Pan and Wen Bo and Yunfeng Liu , keywords =. RoFormer: Enhanced transformer with Rotary Position Embedding , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.neucom.2023.127063 , url =
-
[39]
2020 , eprint=
GLU Variants Improve Transformer , author=. 2020 , eprint=
2020
-
[40]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Deepseek llm: Scaling open-source language models with longtermism , author=. arXiv preprint arXiv:2401.02954 , year=
work page internal anchor Pith review arXiv
-
[41]
Language models scale reliably with over-training and on downstream tasks , author=. arXiv preprint arXiv:2403.08540 , year=
-
[42]
arXiv preprint arXiv:2504.16511 , year=
Quadmix: Quality-diversity balanced data selection for efficient llm pretraining , author=. arXiv preprint arXiv:2504.16511 , year=
-
[43]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[44]
Measuring Massive Multitask Language Understanding
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , biburl =. Measuring Massive Multitask Language Understanding. , url =. ICLR , ee =
-
[45]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[46]
H ella S wag: Can a Machine Really Finish Your Sentence?
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin. H ella S wag: Can a Machine Really Finish Your Sentence?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1472
-
[47]
Advances in Neural Information Processing Systems , volume=
Observational scaling laws and the predictability of langauge model performance , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2506.13216 , year=
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law , author=. arXiv preprint arXiv:2506.13216 , year=
-
[49]
Regmix: Data mixture as regression for language model pre-training , author=. arXiv preprint arXiv:2407.01492 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
To repeat or not to repeat: Insights from scaling llm under token-crisis , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.