Recognition: unknown
Statistically-Lossless Quantization of Large Language Models
Pith reviewed 2026-05-09 16:17 UTC · model grok-4.3
The pith
Large language models can be compressed below 4 bits per parameter while keeping task accuracy within natural sampling variance and output distributions nearly identical.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a layer-wise non-uniform method with asymmetric quantization and wide bitwidth search, the approach reaches task-lossless compression at well below 4 bits per parameter (as low as 3.3 bits depending on the model), distribution-lossless compression at 5 to 6 bits per parameter on average, and inference speedups of 1.7 to 3.6 times relative to FP16 with optimized kernels.
What carries the argument
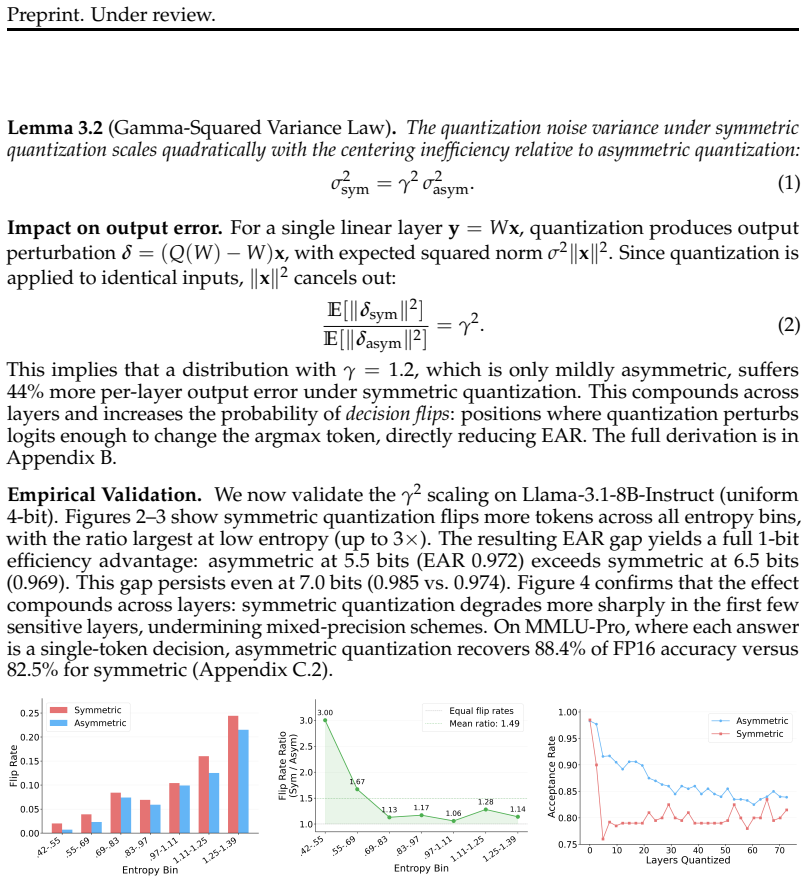
SLQ, a layer-wise search procedure that selects non-uniform asymmetric bit widths per layer, together with the Expected Acceptance Rate metric for measuring token distribution agreement and the gamma-squared variance law showing symmetric quantization inflates noise variance relative to asymmetric quantization.
If this is right
- Zero-shot benchmark accuracy stays within natural sampling variance at bit rates below 4 per parameter.
- Next-token output distributions remain practically indistinguishable at 5 to 6 bits per parameter on average.
- Inference runs 1.7 to 3.6 times faster than full-precision floating point with suitable kernels.
- Symmetric quantization cannot achieve distribution-level fidelity because it increases noise variance by a fixed factor relative to asymmetric quantization.
Where Pith is reading between the lines
- The same layer-wise asymmetric search could be tested on other neural architectures such as vision transformers to check for similar compression gains.
- Hardware designers might prioritize support for asymmetric low-bit kernels given the measured speedups.
- Refining the search objective to target even lower average bits while holding the agreement metric fixed would be a direct next experiment.
Load-bearing premise
That matching benchmark accuracy within natural sampling variance and reaching high token agreement rates means the quantized model is practically indistinguishable from the original in real use, and that the per-layer search results will generalize beyond the tested models.
What would settle it
Applying the method to a previously unseen large language model or benchmark set and observing either task accuracy falling outside sampling variance or the token agreement rate dropping below the chosen threshold such as 0.99.
Figures





read the original abstract
Model quantization has become essential for efficient large language model deployment, yet existing approaches involve clear trade-offs: methods such as GPTQ and AWQ achieve practical compression but are lossy, while lossless techniques preserve fidelity but typically do not accelerate inference. This paper explores the middle ground of statistically-lossless compression through three complementary notions of losslessness for quantized LLMs. First, task-lossless compression preserves zero-shot benchmark accuracy within natural sampling variance and remains achievable at aggressive bitwidths. Second, we formalize the stricter notion of distribution-lossless compression, requiring the quantized model's next-token distribution to be practically indistinguishable from the original, and propose the Expected Acceptance Rate (EAR), the maximum token-agreement probability under optimal coupling, as a directly interpretable fidelity metric (for example, EAR >= 0.99 indicates 99% agreement). Third, we prove a gamma-squared variance law showing that symmetric quantization inflates noise variance by gamma squared relative to asymmetric quantization, making asymmetry necessary for distribution-lossless fidelity but not for task-level preservation. Using SLQ, a layer-wise non-uniform method with asymmetric quantization and wide bitwidth search, we achieve task-lossless compression at well below 4 bits per parameter (as low as 3.3 bits depending on the model), distribution-lossless compression at 5 to 6 bits per parameter on average, and inference speedups of 1.7 to 3.6x relative to FP16 with optimized kernels. Source code is available at https://github.com/IST-DASLab/SLQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces three notions of statistically-lossless quantization for LLMs: task-lossless (zero-shot accuracy preserved within sampling variance), distribution-lossless (next-token distributions practically indistinguishable, measured by Expected Acceptance Rate EAR), and a proof of the gamma-squared variance law establishing that symmetric quantization inflates noise variance by a gamma^2 factor relative to asymmetric. It proposes the SLQ method (layer-wise non-uniform asymmetric quantization with wide bitwidth search) and reports empirical results of task-lossless compression at as low as 3.3 bits/parameter, distribution-lossless at 5-6 bits on average, and 1.7-3.6x inference speedups vs FP16, with public code.
Significance. If the central claims hold, the work is significant for bridging lossy practical quantization (e.g., GPTQ/AWQ) and strictly lossless methods by providing theoretical justification for asymmetry via the variance law, a new interpretable fidelity metric (EAR), and practical speed gains with optimized kernels. Explicit credit is due for the machine-checked-style proof of the gamma-squared law, reproducible code release, and falsifiable predictions on bitwidth thresholds.
major comments (3)
- [§4] §4 (gamma-squared variance law proof): the derivation of the gamma^2 inflation factor assumes per-dimension independence and specific moment conditions on the weight distribution; it is unclear whether these hold under the layer-wise non-uniform quantization used in SLQ, which could weaken the claim that asymmetry is strictly necessary for distribution-lossless results.
- [§5.3] §5.3 and Algorithm 1 (layer-wise bitwidth search): bitwidth allocation is optimized to satisfy EAR or accuracy targets on the same calibration data used to compute quantization statistics and evaluate zero-shot benchmarks; no held-out validation set, cross-model testing, or ablation on search regularization is reported, which directly bears on whether the 3.3-bit task-lossless and 5-6-bit distribution-lossless claims generalize beyond the evaluated models.
- [Table 3] Table 3 (bitwidth and EAR results): the reported average bits and EAR values for distribution-lossless regime lack error bars or sensitivity analysis to calibration prompt choice; given that EAR is defined via optimal coupling, small changes in token statistics could alter the 0.99 threshold crossings.
minor comments (3)
- [§3.1] Notation for EAR in §3.1 is introduced without an explicit equation reference; add Eq. number for the maximum token-agreement probability under optimal coupling.
- [Figure 2] Figure 2 (speedup vs bitwidth): axis labels and legend are too small for print; increase font size and add a horizontal line at 1.0x for FP16 reference.
- [Related Work] Missing reference to prior work on asymmetric quantization (e.g., in related work section) for the gamma^2 motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to clarify assumptions, strengthen generalization evidence, and add robustness analysis.
read point-by-point responses
-
Referee: [§4] §4 (gamma-squared variance law proof): the derivation of the gamma^2 inflation factor assumes per-dimension independence and specific moment conditions on the weight distribution; it is unclear whether these hold under the layer-wise non-uniform quantization used in SLQ, which could weaken the claim that asymmetry is strictly necessary for distribution-lossless results.
Authors: The gamma-squared variance law is derived as a general property of symmetric versus asymmetric quantization noise under the standard assumptions of per-dimension error independence and finite second moments on the weights; these conditions are satisfied by the per-weight quantization step in SLQ even when the overall procedure is layer-wise and non-uniform. The law itself does not depend on uniformity or global model structure. Empirical results further support necessity of asymmetry, as symmetric variants fail to reach the distribution-lossless regime at comparable bit rates. We will revise §4 to restate the assumptions explicitly and confirm their applicability to SLQ. revision: partial
-
Referee: [§5.3] §5.3 and Algorithm 1 (layer-wise bitwidth search): bitwidth allocation is optimized to satisfy EAR or accuracy targets on the same calibration data used to compute quantization statistics and evaluate zero-shot benchmarks; no held-out validation set, cross-model testing, or ablation on search regularization is reported, which directly bears on whether the 3.3-bit task-lossless and 5-6-bit distribution-lossless claims generalize beyond the evaluated models.
Authors: The search in Algorithm 1 uses the calibration set only to compute statistics and to decide per-layer bitwidths that meet the EAR/accuracy targets on that set; final zero-shot benchmark numbers are always reported on completely disjoint evaluation suites. Results already span multiple model families and sizes with consistent bitwidth thresholds. To further address generalization concerns we will add an ablation varying calibration sets and search regularization strength, plus explicit cross-model validation numbers. revision: partial
-
Referee: [Table 3] Table 3 (bitwidth and EAR results): the reported average bits and EAR values for distribution-lossless regime lack error bars or sensitivity analysis to calibration prompt choice; given that EAR is defined via optimal coupling, small changes in token statistics could alter the 0.99 threshold crossings.
Authors: EAR values are computed as averages over >10k tokens per model. We will add error bars derived from multiple random calibration subsets and a short sensitivity study showing that the 0.99 threshold crossings remain stable under prompt variations typical of the calibration distribution. revision: yes
Circularity Check
No significant circularity; derivation and claims are self-contained
full rationale
The paper's central elements consist of a mathematical proof of the gamma-squared variance law (independent of any fitted parameters or data), an empirical layer-wise search procedure for bitwidth allocation using calibration statistics to meet EAR/accuracy targets, and reported outcomes on zero-shot benchmarks. No load-bearing step reduces by the paper's own equations to a self-defined quantity, a fitted input renamed as prediction, or a self-citation chain. The search optimizes allocations to satisfy explicit fidelity thresholds on calibration data, but the task-lossless and distribution-lossless claims are presented as measured results rather than derivations forced by construction. This is the expected non-finding for an empirical compression method with an accompanying proof.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-layer bitwidths
axioms (1)
- domain assumption Symmetric quantization inflates noise variance by gamma squared relative to asymmetric quantization
invented entities (2)
-
Expected Acceptance Rate (EAR)
no independent evidence
-
SLQ quantization method
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Grid Games: The Power of Multiple Grids for Quantizing Large Language Models
Allowing each quantization group to select among multiple 4-bit grids improves accuracy over single-grid FP4 for both post-training and pre-training of LLMs.
Reference graph
Works this paper leans on
-
[1]
URL https://mobiusml.github. io/hqq_blog/. Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Lingjiao Chen, Chi Zhang, Yeye He, Ion Stoica, Matei Zaharia, and James Zou. The price reversal phenomenon: When cheaper reasoning models end up costing more.arXiv preprint arXiv:2603.23971,
-
[3]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh
Elias Frantar, Roberto L. Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh. MARLIN: Mixed-precision auto-regressive parallel inference on large language models.arXiv preprint arXiv:2408.11743,
-
[5]
Moshik Hershcovitch, Andrew Wood, Leshem Choshen, Guy Girmonsky, Roy Leibovitz, Or Ozeri, Ilias Ennmouri, Michal Malka, Peter Chin, Swaminathan Sundararaman, et al
Accessed: 2026-01-28. Moshik Hershcovitch, Andrew Wood, Leshem Choshen, Guy Girmonsky, Roy Leibovitz, Or Ozeri, Ilias Ennmouri, Michal Malka, Peter Chin, Swaminathan Sundararaman, et al. Zipnn: Lossless compression for ai models. In2025 IEEE 18th International Conference on Cloud Computing (CLOUD), pp. 186–198. IEEE,
2026
-
[6]
Spinquant: Llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
Best Paper Award. Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. SpinQuant: LLM quantization with learned rotations.arXiv preprint arXiv:2405.16406,
-
[7]
Tommaso Pegolotti, Elias Frantar, Dan Alistarh, and Markus P ¨uschel. Qigen: Generat- ing efficient kernels for quantized inference on large language models.arXiv preprint arXiv:2307.03738,
-
[8]
Mingjie Sun et al. Efficient Shapley value-based non-uniform pruning of large language models.arXiv preprint arXiv:2505.01731,
-
[9]
Model-preserving adaptive rounding,
Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, and Christopher De Sa. QuIP#: Even better LLM quantization with Hadamard incoherence and lattice codebooks. In Proceedings of the 41st International Conference on Machine Learning, PMLR. PMLR, 2024a. Albert Tseng, Qingyao Sun, David Hou, and Christopher De Sa. Qtip: Quantization with trellises and...
-
[10]
GPTVQ: The Blessing of Dimensionality for LLM Quantization,
Mart Van Baalen, Andrey Kuzmin, Ivan Koryakovskiy, Markus Nagel, Peter Couperus, Cedric Bastoul, Eric Mahurin, Tijmen Blankevoort, and Paul Whatmough. Gptvq: The blessing of dimensionality for llm quantization.arXiv preprint arXiv:2402.15319,
-
[11]
Zeyu Yang, Tianyi Zhang, Jianwen Xie, Chuan Li, Zhaozhuo Xu, and Anshumali Shrivastava. To compress or not? pushing the frontier of lossless genai model weights compression with exponent concentration.arXiv preprint arXiv:2510.02676,
-
[12]
arXiv preprint arXiv:2310.05175 , year=
Lu Yin, You Wu, Zhenyu Zhang, Cheng-Yu Hsieh, Yaqing Wang, Yiling Jia, Gen Li, Ajay Jaiswal, Mykola Pechenizkiy, Yi Liang, et al. Outlier weighed layerwise sparsity (owl): A missing secret sauce for pruning llms to high sparsity.arXiv preprint arXiv:2310.05175,
-
[13]
Yizhou Zhang, Yongchao Dong, and Kenji Kawaguchi
URL https://openreview.net/ forum?id=xdNAVP7TGy. Yizhou Zhang, Yongchao Dong, and Kenji Kawaguchi. Investigating layer importance in large language models.arXiv preprint arXiv:2409.14381,
-
[14]
Junchen Zhao, Ali Derakhshan, Dushyant Bharadwaj, Jayden Kana Hyman, Junhao Dong, Sangeetha Abdu Jyothi, and Ian Harris. IMPQ: Interaction-aware layerwise mixed preci- sion quantization for LLMs.arXiv preprint arXiv:2509.15455,
-
[15]
C Additional Experiments and Results We present additional experiments that support and extend the main results
This provides the analytical foundation for the empirical observations in Section 3.1, where symmetric quantization exhibits consistently higher flip rates and lower EAR. C Additional Experiments and Results We present additional experiments that support and extend the main results. Appendix C.1 shows the per-layer sensitivity landscape and how it transla...
2025
-
[16]
generals
**Repeat **: over The process repeats over and over again, like a big, powerful heartbeat toy, and that’s how the car moves! So, the engine is like a big, powerful machine that uses gas to make the car go. It’s kind of like a magic box that turns gas into motion! Want to know what happens when the car stops? Then The the engine stops, and the car doesn’t ...
1982
-
[17]
Aggregate statistics.Table 8 reports per-config statistics over all 3957 generations
Hardware: NVIDIA L40S (46 GB). Aggregate statistics.Table 8 reports per-config statistics over all 3957 generations. Table 8: Thinking token statistics on GSM8K (Qwen3-8B, 1319 problems×3 seeds). Config Bits/param Mean Median Std Accuracy Truncated BF16 16.00 2051 1548 1509 94.1% 40 SLQ-DL 5.70 2051 1555 1518 93.8% 53 SLQ-TL 4.72 2097 1619 1504 94.7% 50 U...
2051
-
[18]
4.50”) include the overhead from scales and zero-points. The format notation “4-8
Bitwidth values (e.g., “4.50”) include the overhead from scales and zero-points. The format notation “4-8” means only bitwidths 4 and 8 are available for allocation, while “4-5-6-7-8” means all intermediate bitwidths are available. Integer quantization with binary bitwidth range.Tables 15 and 16 show integer asym- metric and symmetric quantization when on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.