Recognition: 2 theorem links
· Lean TheoremGrid Games: The Power of Multiple Grids for Quantizing Large Language Models
Pith reviewed 2026-05-13 06:37 UTC · model grok-4.3
The pith
Selecting among multiple 4-bit grids per group improves quantization accuracy for large language models over single-grid formats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
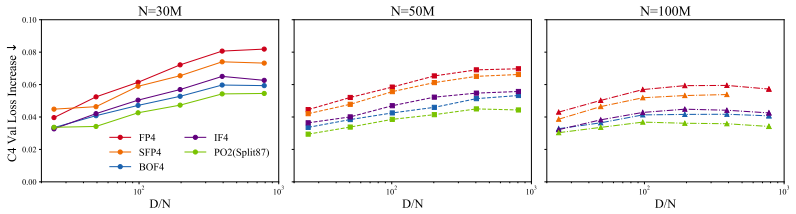
Selecting one of several 4-bit grids per group of values, marked by bits in the scale, yields lower quantization error than any single fixed grid for the group sizes typical in microscaled formats such as MXFP4 and NVFP4. The advantage is proven to vanish once groups become very large. Concrete grid families including PO2(NF4), MPO2, PO2(Split87), and SFP4 are defined and shown to raise accuracy in both post-training and pre-training settings.
What carries the argument
The power-of-two-grids (PO2) selection mechanism that lets each group pick its optimal 4-bit grid from a small family using extra bits in the scale.
Load-bearing premise
The extra bits or logic needed to select among grids per group add negligible overhead and can be implemented efficiently on target hardware without changing the overall bit budget.
What would settle it
Increase group size to several thousand values while keeping two or three grids available and measure whether the accuracy advantage over single-grid baselines disappears.
Figures





read the original abstract
A major recent advance in quantization is given by microscaled 4-bit formats such as NVFP4 and MXFP4, quantizing values into small groups sharing a scale, assuming a fixed floating-point grid. In this paper, we study the following natural extension: assume that, for each group of values, we are free to select the "better" among two or more 4-bit grids marked by one or more bits in the scale value. We formalize the power-of-two-grids (PO2) problem, and provide theoretical results showing that practical small-group formats such as MXFP or NVFP can benefit significantly from PO2 grids, while the advantage vanishes for very large groups. On the practical side, we instantiate several grid families, including 1) PO2(NF4), which pairs the standard NF4 normal grid with a learned grid, 2) MPO2, a grid pair that is fully learned over real weights and activations, 3) PO2(Split87), an explicit-zero asymmetric grid and 4) SFP4, a TensorCore-implementable triple which pairs NVFP4 with two shifted variants. Results for post-training quantization of standard open models and pre-training of Llama-like models show that adaptive grids consistently improve accuracy vs single-grid FP4 under both weight-only and weight+activation. Source code is available at https://github.com/IST-DASLab/GridGames.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Power-of-Two-Grids (PO2) quantization method, which extends microscaled 4-bit formats such as MXFP4 and NVFP4 by allowing per-group selection among multiple 4-bit grids, with the choice encoded using one or more bits within the shared scale value. It formalizes the PO2 problem, derives theoretical results on the group-size dependence of the accuracy benefit (largest for small groups, vanishing for large groups), instantiates several grid families (PO2(NF4), MPO2, PO2(Split87), SFP4), and reports empirical gains versus single-grid FP4 baselines in both post-training quantization of open models and pre-training of Llama-like models under weight-only and weight+activation settings. Source code is released.
Significance. If the accuracy improvements are shown to survive an explicit accounting for any scale-precision penalty incurred by bit reallocation, the work supplies a practical, low-overhead extension to existing microscaled formats that could be adopted on current hardware. The group-size analysis offers a clear, testable prediction about when multi-grid selection is advantageous, and the open-source release aids reproducibility.
major comments (2)
- [§3] §3 (PO2 construction): the description of encoding grid choice inside the per-group scale value does not include an explicit bit-allocation table or closed-form expression showing how many bits are taken from the scale mantissa/exponent; without this, it is impossible to verify that the claimed gains for small groups are not offset by the resulting coarsening of scale precision.
- [§5] §5 (empirical evaluation): the reported accuracy improvements versus single-grid FP4 lack an ablation that isolates the grid-selection benefit from the scale-precision penalty; the theory predicts the largest PO2 advantage precisely where scale accuracy matters most (small groups), yet no such controlled experiment is provided.
minor comments (1)
- [Abstract] Abstract: the summary of empirical results omits error bars, number of runs, and any quantitative overhead figures for the selection logic.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and for the constructive comments that help strengthen the clarity and empirical rigor of the manuscript. We address each major comment below and will revise the paper to incorporate the requested details and experiments.
read point-by-point responses
-
Referee: [§3] §3 (PO2 construction): the description of encoding grid choice inside the per-group scale value does not include an explicit bit-allocation table or closed-form expression showing how many bits are taken from the scale mantissa/exponent; without this, it is impossible to verify that the claimed gains for small groups are not offset by the resulting coarsening of scale precision.
Authors: We agree that an explicit bit-allocation table and closed-form expression are needed for full transparency and verifiability. In the revised manuscript we will add a table in §3 that specifies, for each considered scale format (MXFP4, NVFP4, etc.), exactly how many bits are allocated to grid selection and from which field (mantissa or exponent) they are taken. We will also include a closed-form expression for the resulting effective scale precision under PO2. This addition will allow readers to directly confirm that the reported gains for small groups are not offset by scale coarsening. revision: yes
-
Referee: [§5] §5 (empirical evaluation): the reported accuracy improvements versus single-grid FP4 lack an ablation that isolates the grid-selection benefit from the scale-precision penalty; the theory predicts the largest PO2 advantage precisely where scale accuracy matters most (small groups), yet no such controlled experiment is provided.
Authors: We acknowledge that an explicit ablation isolating the grid-selection benefit from any scale-precision penalty would strengthen the empirical claims, especially given the theory's prediction that the advantage is largest for small groups. In the revision we will add a controlled ablation in §5 that compares PO2 configurations against single-grid FP4 baselines with matched scale precision (i.e., the baseline uses the same reduced number of scale bits after accounting for the bits repurposed for grid selection). This experiment will empirically confirm that the observed accuracy gains are attributable to multi-grid selection rather than any unaccounted scale effects. revision: yes
Circularity Check
Independent extension of MXFP/NVFP with no load-bearing self-citation or definitional reduction
full rationale
The paper formalizes PO2 as an extension of existing microscaled formats (MXFP4/NVFP4) and reports empirical accuracy gains from adaptive grid selection. No equation or result reduces the claimed improvements to a fitted parameter or self-citation chain; theoretical bounds on small-group benefit are derived from standard quantization error analysis rather than from the experimental data itself. Self-citations, if present, are not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned grid parameters
axioms (1)
- domain assumption Small-group formats such as MXFP or NVFP benefit significantly from PO2 grids while the advantage vanishes for very large groups
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe formalize the power-of-two-grids (PO2) problem... R⋆_g := min_B E L(g)_B(X) and R⋆_PO2,g := inf_{B1,B2} E[min{L(g)_B1(X), L(g)_B2(X)}]. Theorem 1 (No asymptotic advantage).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearConcavity. Let S and F be a partition... V_G(p) := inf_B (p R_S(B) + (1-p) R_F(B)). Lemma 2 (Concavity).
Reference graph
Works this paper leans on
-
[1]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. QuaRot: Outlier-free 4-bit inference in rotated LLMs. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[2]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. InThirty-Fourth AAAI Conference on Artificial Intelligence, 2020
work page 2020
-
[3]
Patrick Blumenberg, Thomas Graave, and Tim Fingscheidt. Improving Block-Wise LLM Quantization by 4-bit Block-Wise Optimal Float (BOF4): Analysis and Variations, May 2025. URLhttps://arxiv.org/abs/2505.06653
-
[4]
Towards cheaper inference in deep networks with lower bit-width accumulators
Yaniv Blumenfeld, Itay Hubara, and Daniel Soudry. Towards cheaper inference in deep networks with lower bit-width accumulators. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=oOwDQl8haC
work page 2024
-
[5]
Roberto L. Castro, Andrei Panferov, Soroush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, and Dan Alistarh. Quartet: Native FP4 training can be optimal for large language models.arXiv preprint arXiv:2505.14669, 2025
-
[6]
Fp4 all the way: Fully quantized training of llms.arXiv preprint arXiv:2505.19115, 2025
Brian Chmiel, Maxim Fishman, Ron Banner, and Daniel Soudry. Fp4 all the way: Fully quantized training of llms, 2025. URLhttps://arxiv.org/abs/2505.19115
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
Jack Cook, Junxian Guo, Guangxuan Xiao, Yujun Lin, and Song Han. Four over six: More accurate NVFP4 quantization with adaptive block scaling.arXiv preprint arXiv:2512.02010, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Lee, Kathryn Le, Junxian Guo, Giovanni Traverso, Anantha P
Jack Cook, Hyemin S. Lee, Kathryn Le, Junxian Guo, Giovanni Traverso, Anantha P. Chan- drakasan, and Song Han. Adaptive block-scaled data types.arXiv preprint arXiv:2603.28765, 2026
-
[11]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[12]
Reena Elangovan, Charbel Sakr, Anand Raghunathan, and Brucek Khailany. LO-BCQ: Locally optimal block clustered quantization for 4-bit (w4a4) LLM inference.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id= loWISTqGwW. Featured Certification, J2C Certification
work page 2025
-
[13]
GPTQ: Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations, 2023
work page 2023
-
[14]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Fast matrix multiplications for lookup table-quantized llms
Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric Xing, and Yoon Kim. Fast matrix multiplications for lookup table-quantized llms. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12419–12433, 2024
work page 2024
-
[17]
Statistically-Lossless Quantization of Large Language Models
Michael Helcig, Eldar Kurtic, and Dan Alistarh. Statistically-lossless quantization of large language models, 2026. URLhttps://arxiv.org/abs/2605.02404
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[19]
Liam Hodgkinson and Michael W. Mahoney. Multiplicative noise and heavy tails in stochastic optimization.International Conference on Machine Learning, 2021
work page 2021
-
[20]
B. Khailany et al. 4-bit floating point quantization for inference.NVIDIA Technical Report, 2025
work page 2025
-
[21]
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, and Kurt Keutzer. SqueezeLLM: Dense-and-sparse quantization. InInternational Conference on Machine Learning, 2024
work page 2024
-
[22]
AWQ: Activation-aware weight quantization for LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration. In Proceedings of Machine Learning and Systems, 2024
work page 2024
-
[23]
Stuart P. Lloyd. Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
work page 1982
-
[24]
HIGGS: Pushing the limits of large language model quantization via the linearity theorem
Vladimir Malinovskii, Andrei Panferov, Ivan Ilin, Han Guo, Peter Richtárik, and Dan Alistarh. HIGGS: Pushing the limits of large language model quantization via the linearity theorem. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 10857–10886, 2025
work page 2025
-
[25]
Charles H. Martin and Michael W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for training.Journal of Machine Learning Research, 22(165):1–73, 2021. 11
work page 2021
-
[26]
Quantizing for minimum distortion.IRE Transactions on Information Theory, 6(1): 7–12, 1960
Joel Max. Quantizing for minimum distortion.IRE Transactions on Information Theory, 6(1): 7–12, 1960
work page 1960
-
[27]
A white paper on neural network quantization.arXiv preprint arXiv:2106.08295,
Markus Nagel, Rana Ali Amjad, Mart van Baalen, Christos Louizos, and Tijmen Blankevoort. A white paper on neural network quantization.arXiv preprint arXiv:2106.08295, 2021
-
[28]
Castro, Mahdi Nikdan, and Dan Alistarh
Andrei Panferov, Jiale Chen, Soroush Tabesh, Roberto L. Castro, Mahdi Nikdan, and Dan Alistarh. Quest: Stable training of llms with 1-bit weights and activations, 2025. URL https://arxiv.org/abs/2502.05003
-
[29]
Andrei Panferov, Erik Schultheis, Soroush Tabesh, and Dan Alistarh. Quartet II: Accu- rate LLM pre-training in NVFP4 by improved unbiased gradient estimation.arXiv preprint arXiv:2601.22813, 2026
-
[30]
The lambada dataset, August 2016
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset, August 2016. URLhttps://doi.org/10.5281/zenodo.2630551
-
[31]
Microscaling data formats for deep learning.arXiv preprint arXiv:2310.10537, 2023
Bita Darvish Rouhani, Ritchie Zhao, Ankit More, Mathew Hall, Alireza Khodamoradi, Sum- mer Deng, Dhruv Choudhary, Marius Cornea, Eric Dellinger, Kristof Denolf, Stosic Dusan, Venmugil Elango, Maximilian Golub, Alexander Heinecke, Phil James-Roxby, Dharmesh Jani, Gaurav Kolhe, Martin Langhammer, Ada Li, Levi Melnick, Maral Mesmakhosroshahi, Andres Rodrigue...
-
[32]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
work page 2021
-
[33]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[34]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[35]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023. URLhttps://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
QuIP#: Even better LLM quantization with hadamard incoherence and lattice codebooks
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. QuIP#: Even better LLM quantization with hadamard incoherence and lattice codebooks. InProceedings of the 41st International Conference on Machine Learning, pages 48630–48656, 2024
work page 2024
-
[37]
Albert Tseng, Qingyao Sun, David Hou, and Christopher De. Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597– 59620, 2024
work page 2024
-
[38]
Training llms with mxfp4.arXiv preprint arXiv:2502.20586, 2025
Albert Tseng, Tao Yu, and Youngsuk Park. Training llms with mxfp4.arXiv preprint arXiv:2502.20586, 2025
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
work page 2019
-
[41]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023. URL https://arxiv.org/abs/2311.07911. 12 A Limitations and Broader Impacts The theory uses i.i.d. block models and Student-t fits, while real transformer tensors have structure from ch...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.