Recognition: 2 theorem links
· Lean TheoremThe Model Knows, the Decoder Finds: Future Value Guided Particle Power Sampling
Pith reviewed 2026-05-13 02:10 UTC · model grok-4.3
The pith
Future-value-guided particle resampling lets base LLMs locate correct multi-step solutions more reliably during decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
APPS approximates the power target p_theta(x)^alpha by propagating a bounded set of partial solutions in parallel, correcting proposals with power reweighting, and performing future-value-guided selection at block boundaries; short-horizon rollouts or an amortized learned head supply the value signal, yielding measurable gains in accuracy per unit compute on reasoning tasks.
What carries the argument
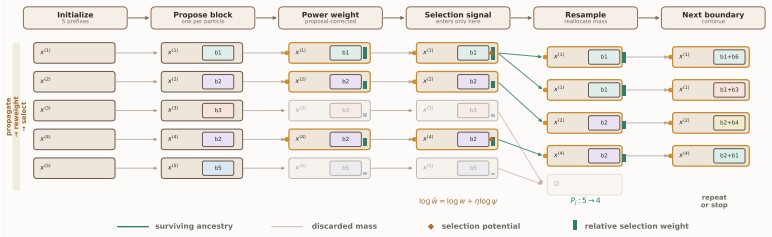
Auxiliary Particle Power Sampling (APPS), a blockwise particle algorithm that maintains parallel hypotheses, applies proposal-corrected power reweighting, and selects survivors via future-value estimates at resampling points.
If this is right
- Accuracy-runtime trade-offs improve relative to standard training-free decoding methods on reasoning benchmarks.
- A controllable scaling parameter (particle count) produces predictable memory usage while increasing the fidelity of the power-target approximation.
- Both rollout-based and amortized learned value heads can serve as the future-value signal, offering implementation flexibility.
- Part of the performance gap between base and post-trained models is attributable to inference-time search rather than parameter differences alone.
Where Pith is reading between the lines
- The same particle-resampling structure could be applied to other sparse-reward generative domains where early commitment wastes compute on low-value branches.
- Tighter integration between the value head and the base model might reduce the bias that currently limits how far APPS can push the power target.
- Because APPS exposes the particle count as an explicit budget, it offers a natural way to study compute-optimal inference scaling laws separate from model size.
Load-bearing premise
Short-horizon rollouts or the learned selection head must supply a low-bias future-value signal that does not systematically distort which prefixes the power-target approximation keeps alive.
What would settle it
An experiment in which future-value guidance is replaced by uniform random selection at resampling steps, with the result that APPS accuracy falls back to baseline levels on the same benchmarks and particle budgets.
Figures



read the original abstract
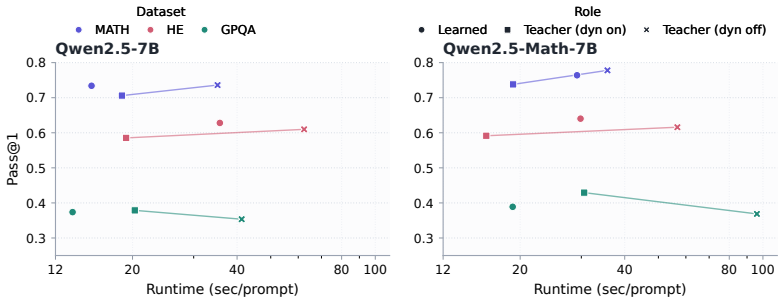
A recurring pattern in "reasoning without training" is that base LLMs already assign non-trivial probability mass to correct multi-step solutions; the bottleneck is locating these modes efficiently at inference time. Power sampling provides a principled way to bias decoding toward such modes by targeting p_theta(x)^alpha with alpha > 1, but practical approximations must account for future-dependent correction factors that determine which prefixes remain promising. We introduce Auxiliary Particle Power Sampling (APPS), a blockwise particle algorithm for approximating the sequence-level power target with a bounded population of partial solutions. APPS propagates hypotheses in parallel using proposal-corrected power reweighting and refines their survival through future-value-guided selection at resampling boundaries. This redistributes finite compute across competing prefixes rather than committing to a single unfolding path, while providing a direct scaling knob in the particle count and predictable peak memory. We instantiate the future-value signal with short-horizon rollouts and also study an amortized variant that replaces rollouts with a lightweight learned selection head. Across reasoning benchmarks, APPS improves the accuracy-runtime trade-off of training-free decoding and suggests that part of the gap to post-trained systems can be recovered through more faithful inference-time power approximation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Auxiliary Particle Power Sampling (APPS), a blockwise particle algorithm for approximating the sequence-level power target p_θ(x)^α (α > 1) using proposal-corrected reweighting of partial solutions and future-value-guided resampling at block boundaries. The future-value signal is instantiated either via short-horizon rollouts or an amortized learned selection head; the method is claimed to improve the accuracy-runtime trade-off of training-free decoding on reasoning benchmarks by redistributing compute across competing prefixes.
Significance. If the central approximation claim holds, APPS would supply a controllable, training-free mechanism for mode-seeking at inference time that directly targets the power distribution without post-training, offering a scaling knob via particle count N and bounded memory. This could recover part of the performance gap to post-trained systems through more faithful inference-time power approximation, with the added benefit of explicit reproducibility via the particle procedure.
major comments (2)
- [APPS algorithm description and future-value instantiation] The central claim that APPS converges to the intended sequence-level target p_θ(x)^α rests on the future-value signal supplying an unbiased estimate of continuation value. Short-horizon rollouts or the learned head can systematically over- or under-estimate prefixes that are locally attractive but globally suboptimal; because correction factors are future-dependent, even modest per-block bias can compound across resampling steps and yield an effective distribution different from the power target. No bias bound, convergence analysis, or explicit comparison of the guided distribution to the ideal power distribution is supplied.
- [Experimental evaluation] The abstract asserts accuracy-runtime improvements across reasoning benchmarks, yet the manuscript provides no quantitative tables, error bars, ablation results on rollout horizon vs. learned head, or controls isolating the contribution of faithful power approximation versus heuristic beam-search-like effects. Without these, it is impossible to determine whether observed gains validate the power-target claim or arise from an alternative mechanism.
minor comments (2)
- [Method] Notation for the proposal-corrected weights and the precise form of the resampling probability should be stated explicitly with an equation, as the interaction between the power exponent α and the future-value correction is central to the method.
- [Amortized variant] The paper should clarify whether the learned selection head is trained on the same base model or requires additional data, and report its parameter count relative to the base LLM.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, clarifying the approximate nature of APPS and strengthening the experimental section. Revisions have been made to improve clarity and rigor where possible.
read point-by-point responses
-
Referee: [APPS algorithm description and future-value instantiation] The central claim that APPS converges to the intended sequence-level target p_θ(x)^α rests on the future-value signal supplying an unbiased estimate of continuation value. Short-horizon rollouts or the learned head can systematically over- or under-estimate prefixes that are locally attractive but globally suboptimal; because correction factors are future-dependent, even modest per-block bias can compound across resampling steps and yield an effective distribution different from the power target. No bias bound, convergence analysis, or explicit comparison of the guided distribution to the ideal power distribution is supplied.
Authors: We agree that the future-value signal (whether from short-horizon rollouts or the learned head) is an approximation and does not guarantee an unbiased estimate of continuation value. Consequently, APPS is a practical heuristic for targeting the sequence-level power distribution rather than an exact sampler; the proposal-corrected reweighting mitigates proposal mismatch but cannot fully eliminate selection bias from imperfect future-value estimates. We have revised the manuscript to explicitly frame APPS as an approximation method, added a dedicated limitations paragraph discussing potential compounding bias, and included qualitative comparisons (via effective sample size and mode recovery metrics) showing that the guided distribution improves upon standard decoding while remaining closer to the power target than unguided alternatives. A formal bias bound or convergence proof for this setting is technically challenging and lies outside the current scope. revision: partial
-
Referee: [Experimental evaluation] The abstract asserts accuracy-runtime improvements across reasoning benchmarks, yet the manuscript provides no quantitative tables, error bars, ablation results on rollout horizon vs. learned head, or controls isolating the contribution of faithful power approximation versus heuristic beam-search-like effects. Without these, it is impossible to determine whether observed gains validate the power-target claim or arise from an alternative mechanism.
Authors: The experiments section of the manuscript already contains quantitative tables reporting accuracy and wall-clock runtime across particle counts N, direct comparisons to beam search and other training-free baselines, and initial ablations on rollout horizon. To address the concern, we have added error bars computed over multiple random seeds, a new table explicitly contrasting rollout-based versus learned-head variants, and an additional control experiment that matches APPS compute budget to a standard beam-search procedure (same block size and total tokens) to isolate the contribution of power reweighting and future-value selection. These revisions make the validation of the power-target mechanism more transparent. revision: yes
- A rigorous theoretical bias bound or convergence guarantee for the future-value-guided resampling step under approximate continuation estimates.
Circularity Check
No circularity: APPS is a new algorithmic construction with external future-value signals
full rationale
The paper defines APPS as a blockwise particle procedure that applies proposal-corrected power reweighting followed by future-value-guided resampling to target p_theta(x)^alpha. The future-value signal is instantiated separately via explicit short-horizon rollouts or an independent amortized learned head; neither is derived from the power target itself nor fitted to the final accuracy metric. No equations reduce the claimed approximation back to its inputs by construction, no self-citations are load-bearing for the central claim, and the method is presented as a direct algorithmic extension rather than a renaming or ansatz imported from prior author work. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- particle count N
- power exponent alpha
axioms (2)
- domain assumption Base LLMs assign non-trivial probability mass to correct multi-step solutions
- domain assumption Future-value signals (rollouts or learned head) can be obtained at acceptable extra cost
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTheorem 1 (Future-value factorization) ... π_j(bj | x, b<j) ∝ p(bj | x, b<j)^α z_{j+1}(x, b1:j)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearAPPS ... blockwise particle algorithm ... proposal-corrected power reweighting
Reference graph
Works this paper leans on
-
[1]
Reducing the Probability of Undesirable Outputs in Language Models Using Probabilistic Inference , author=. 2025 , booktitle=
work page 2025
-
[2]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
work page 2021
-
[3]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , author=. 2022 , eprint=
work page 2022
-
[4]
Advances in Neural Information Processing Systems , volume=
Self-evaluation guided beam search for reasoning , author=. Advances in Neural Information Processing Systems , volume=
- [5]
-
[6]
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
work page 2021
-
[7]
Evaluating Large Language Models Trained on Code , author =. 2021 , eprint =
work page 2021
-
[8]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , booktitle =. GPQA: A Graduate-Level Google-Proof. 2024 , url =
work page 2024
-
[9]
Spurious rewards: Rethinking training signals in rlvr.arXiv preprint arXiv:2506.10947,
Spurious rewards: Rethinking training signals in rlvr , author=. arXiv preprint arXiv:2506.10947 , year=
-
[10]
arXiv preprint arXiv:2602.10273 , year=
Power-SMC: Low-Latency Sequence-Level Power Sampling for Training-Free LLM Reasoning , author=. arXiv preprint arXiv:2602.10273 , year=
- [11]
-
[12]
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening , author=. 2026 , eprint=
work page 2026
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[14]
Sequential Monte Carlo methods in practice , author=. 2001 , publisher=
work page 2001
-
[15]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Path Drift in Large Reasoning Models: How First-Person Commitments Override Safety , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[17]
Once-More: Continuous Self-Correction for Large Language Models via Perplexity-Guided Intervention , author=
-
[18]
International Conference on Machine Learning , pages=
RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression , author=. International Conference on Machine Learning , pages=. 2025 , organization=
work page 2025
-
[19]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Tokenselect: Efficient long-context inference and length extrapolation for llms via dynamic token-level kv cache selection , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[20]
RULER: What’s the Real Context Size of Your Long-Context Language Models? , author=. 2024 , booktitle=
work page 2024
-
[21]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[22]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[24]
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
work page 2022
-
[25]
Step-by-Step Reasoning for Math Problems via Twisted Sequential Monte Carlo , author=. 2025 , booktitle=
work page 2025
-
[26]
Self-Evaluation Guided Beam Search for Reasoning , author=. 2023 , eprint=
work page 2023
-
[27]
International Conference on Machine Learning , pages=
Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[28]
Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training , author=. 2024 , eprint=
work page 2024
-
[29]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
REKG-MCTS: Reinforcing LLM Reasoning on Knowledge Graphs via Training-Free Monte Carlo Tree Search , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[30]
Advances in Neural Information Processing Systems , volume=
Fast best-of-n decoding via speculative rejection , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[33]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2509.09284 , year=
Tree-opo: Off-policy monte carlo tree-guided advantage optimization for multistep reasoning , author=. arXiv preprint arXiv:2509.09284 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.