Recognition: 3 theorem links
· Lean TheoremARIADNE: Agentic Reward-Informed Adaptive Decision Exploration via Blackboard-Driven MCTS for Competitive Program Generation
Pith reviewed 2026-05-08 17:52 UTC · model grok-4.3
The pith
A blackboard-driven MCTS organizes LLM program generation into five coordinated stages with persistent evidence to raise Pass@1 scores on contest benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
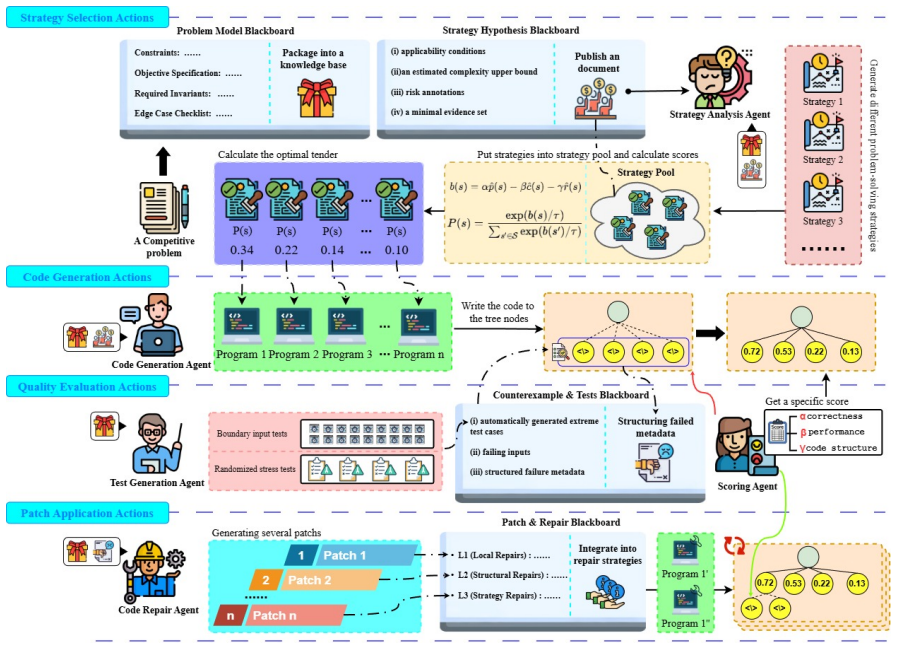
ARIADNE models competitive program generation as a sequential decision process using a blackboard-driven Monte Carlo Tree Search framework. The approach divides the workflow into five coordinated stages—strategy selection, code generation, test generation, quality evaluation, and code repair—while a shared blackboard accumulates structured evidence to guide subsequent decisions and enable systematic exploration plus feedback utilization within practical budgets.
What carries the argument
The shared blackboard within the MCTS framework, which stores and reuses structured evidence from the five stages to adaptively direct each decision in the program generation sequence.
If this is right
- Explicit algorithmic planning and edge-case handling become possible through staged exploration instead of one-shot generation.
- Execution feedback integrates more effectively into iterative refinement while respecting time and memory limits.
- Performance leadership holds across multiple LLM backends, including gains with both GPT-4o and DeepSeek-V3.2.
- Global search via MCTS combined with evidence accumulation produces more reliable solutions under contest constraints.
Where Pith is reading between the lines
- The blackboard structure could support extension to multi-agent setups where separate models handle different stages.
- Similar evidence-accumulation mechanisms might apply to other iterative synthesis tasks such as hardware design or mathematical proof generation.
- Deeper MCTS rollouts or richer blackboard schemas could yield further gains on harder problem sets without changing the core stages.
Load-bearing premise
LLMs and MCTS can coordinate the five-stage workflow and shared blackboard to incorporate execution feedback without exceeding practical computational budgets.
What would settle it
An independent replication on the LiveCodeBench benchmark with GPT-4o that produces a Pass@1 score below 20.91 while following the reported setup would challenge the claimed performance gains.
Figures




read the original abstract
Competitive program generation aims to automatically produce correct and efficient solutions for programming-contest problems under strict time and memory constraints. Existing LLM-based approaches often fail to perform explicit algorithmic planning and to handle edge cases robustly, leading to unreliable one-shot generation. Moreover, although execution feedback is essential for iterative debugging and refinement, incorporating such feedback effectively within limited computational budgets remains difficult. To overcome these limitations, we propose {\tool}, a blackboard-driven Monte Carlo Tree Search (MCTS) framework that models program generation as a sequential decision process. {\tool} organizes the generation workflow into five coordinated stages (i.e., strategy selection, code generation, test generation, quality evaluation, and code repair) while maintaining a shared blackboard that accumulates structured evidence to guide subsequent decisions. Experiments on four benchmarks (APPS, CodeContests, CodeContests+, and LiveCodeBench) show that {\tool} consistently achieves the best Pass@1 performance across multiple LLM backends. With GPT-4o, {\tool} attains Pass@1 scores of 41.30, 46.67, 27.27, and 20.91, surpassing the strongest baseline CodeSim by up to 26.06 points, while further improvements are observed with DeepSeek-V3.2. These results indicate that combining global search through MCTS with persistent evidence accumulation on a shared blackboard enables systematic exploration and effective feedback utilization, substantially enhancing the capability of LLMs in competitive program generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ARIADNE, a blackboard-driven MCTS framework for competitive program generation that divides the task into five stages (strategy selection, code generation, test generation, quality evaluation, code repair) coordinated via a shared blackboard for evidence accumulation. Through experiments on APPS, CodeContests, CodeContests+, and LiveCodeBench using various LLMs, it reports superior Pass@1 performance, such as 41.30, 46.67, 27.27, and 20.91 with GPT-4o, exceeding the CodeSim baseline by up to 26.06 points.
Significance. If the results hold after controlling for computational resources, the work would be significant for demonstrating how MCTS combined with persistent structured memory can enhance LLM capabilities in algorithmic problem-solving and debugging under contest constraints. The evaluation across four diverse benchmarks and multiple model backends provides broad evidence supporting the approach's generality.
major comments (2)
- [Experiments section] The reported Pass@1 scores (e.g., 41.30 on APPS with GPT-4o) lack error bars, details on the evaluation protocol (number of problems, sampling strategy, number of runs), or statistical significance tests. This omission in the experimental results section prevents rigorous verification of the claimed consistent outperformance over baselines such as CodeSim.
- [Method and Experiments sections] No reporting is given of average LLM calls or token usage per problem for ARIADNE versus baselines. The five-stage MCTS workflow with blackboard reads/writes inherently multiplies invocations; without a matched-budget ablation in the experiments, the gains of up to 26.06 points cannot be attributed to the blackboard-MCTS coordination rather than higher search volume.
minor comments (1)
- [Abstract] The abstract uses the LaTeX placeholder {tool} for the system name; replace with 'ARIADNE' for clarity and consistency in the published version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental rigor and computational transparency. We will revise the manuscript to address these points where feasible.
read point-by-point responses
-
Referee: [Experiments section] The reported Pass@1 scores (e.g., 41.30 on APPS with GPT-4o) lack error bars, details on the evaluation protocol (number of problems, sampling strategy, number of runs), or statistical significance tests. This omission in the experimental results section prevents rigorous verification of the claimed consistent outperformance over baselines such as CodeSim.
Authors: We agree that these details are essential for verification. In the revised manuscript, we will expand the Experiments section to report: the exact number of problems evaluated from each benchmark (full test splits), the sampling strategy (temperature, top-p, and number of samples per problem for Pass@1), results from multiple independent runs with error bars (standard deviations), and statistical significance tests (e.g., McNemar's test for paired comparisons against baselines like CodeSim). This will be added without altering the core claims. revision: yes
-
Referee: [Method and Experiments sections] No reporting is given of average LLM calls or token usage per problem for ARIADNE versus baselines. The five-stage MCTS workflow with blackboard reads/writes inherently multiplies invocations; without a matched-budget ablation in the experiments, the gains of up to 26.06 points cannot be attributed to the blackboard-MCTS coordination rather than higher search volume.
Authors: We acknowledge the value of reporting resource usage. We will add a dedicated subsection in Experiments detailing average LLM calls and token consumption per problem for ARIADNE and all baselines, drawn from our experimental logs. A full matched-budget ablation would require substantial new experiments beyond a standard revision; we will instead discuss this as a limitation, provide the available cost data, and argue that the structured blackboard and MCTS stages enable more effective use of each invocation through evidence accumulation and targeted repair, rather than raw volume alone. revision: partial
Circularity Check
No circularity: empirical benchmark claims rest on direct experimental comparison, not on self-referential definitions or fitted inputs.
full rationale
The paper describes a five-stage blackboard-MCTS workflow for program generation and reports Pass@1 scores on APPS, CodeContests, CodeContests+, and LiveCodeBench. No equations, parameters fitted to subsets then re-predicted, or uniqueness theorems appear. The central claim is an empirical performance delta versus baselines; this does not reduce to any input quantity by construction. Self-citations, if present, are not load-bearing for the reported numbers. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be prompted to perform strategy selection, code generation, test generation, quality evaluation, and repair in a coordinated loop
invented entities (1)
-
Shared blackboard for accumulating structured evidence
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel; alpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UCB(u) = X̄(u) + C·√(ln(N(v)+1)/N(u)); p(u) = softmax with temperature τ; R = αR_corr + βR_perf + γR_struct with α=0.6, β=γ=0.2
-
Foundation (parameter-free forcing chain)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Stage-2 recommended (D*, C*, τ*) = (5, 1.4, 0.7) via Pareto search over hyperparameter grid
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. S. Hossain, A. Tabassum, M. F. Arefin, T. S. Za- man, Llm-pros: Analyzing large language models’ per- formance in competitive problem solving, in: 2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code), IEEE, 2025, pp. 80–87
2025
-
[2]
Ouyang, J
S. Ouyang, J. M. Zhang, M. Harman, M. Wang, An em- pirical study of the non-determinism of chatgpt in code generation, ACM Transactions on Software Engineering and Methodology 34 (2) (2025) 1–28
2025
- [3]
-
[4]
A. M. Esfahani, N. Kahani, S. A. Ajila, Understanding defects in generated codes by language models, in: 2024 34th International Conference on Collaborative Advances in Software and COmputiNg (CASCON), IEEE, 2024, pp. 1–10
2024
- [5]
-
[6]
T. Dinh, J. Zhao, S. Tan, R. Negrinho, L. Lausen, S. Zha, G. Karypis, Large language models of code fail at com- pleting code with potential bugs, Advances in Neural In- formation Processing Systems 36 (2023) 41386–41412
2023
-
[7]
F. Liu, Y . Liu, L. Shi, H. Huang, R. Wang, Z. Yang, L. Zhang, Exploring and evaluating hallucinations in llm- powered code generation, CoRR (2024)
2024
- [8]
-
[9]
M. A. Islam, M. E. Ali, M. R. Parvez, Codesim: Multi-agent code generation and problem solving through simulation-driven planning and debugging, in: Find- ings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 5113–5139
2025
- [10]
- [11]
- [12]
-
[13]
Make every move count: LLM-based high-quality RTL code generation using MCTS,
M. DeLorenzo, A. B. Chowdhury, V . Gohil, S. Thakur, R. Karri, S. Garg, J. Rajendran, Make every move count: Llm-based high-quality rtl code generation using mcts, arXiv preprint arXiv:2402.03289 (2024)
- [14]
-
[15]
A. Salemi, M. Parmar, P. Goyal, Y . Song, J. Yoon, H. Za- mani, H. Palangi, T. Pfister, Llm-based multi-agent black- board system for information discovery in data science, arXiv preprint arXiv:2510.01285 (2025)
-
[16]
Measuring Coding Challenge Competence With APPS
D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, et al., Measuring coding challenge competence with apps, arXiv preprint arXiv:2105.09938 (2021)
work page internal anchor Pith review arXiv 2021
-
[17]
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrit- twieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago, et al., Competition-level code generation with alphacode, Science 378 (6624) (2022) 1092–1097
2022
- [18]
-
[19]
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, I. Stoica, Live- codebench: Holistic and contamination free evalua- tion of large language models for code, arXiv preprint arXiv:2403.07974 (2024)
work page internal anchor Pith review arXiv 2024
-
[20]
J. Li, H. Le, Y . Zhou, C. Xiong, S. Savarese, D. Sahoo, Codetree: Agent-guided tree search for code generation with large language models, in: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies (V olume 1: Long Papers), 2025, pp. 3711–3726
2025
- [21]
-
[22]
R. Li, J. Fu, B.-W. Zhang, T. Huang, Z. Sun, C. Lyu, G. Liu, Z. Jin, G. Li, Taco: Topics in algorithmic code generation dataset, CoRR (2023)
2023
- [23]
-
[24]
T. Ito, M. R. Salleh, A blackboard-based negotiation for collaborative supply chain system, Journal of Materials Processing Technology 107 (1-3) (2000) 398–403
2000
-
[25]
M. Wei, Z. Li, X. Chen, M. Zheng, Z. Qu, C. Yu, S. Chen, X. Ju, Evaluating and improving llm-based competitive program generation, Information and Software Technol- ogy (2025) 107977
2025
-
[26]
Zhang, J
K. Zhang, J. Li, G. Li, X. Shi, Z. Jin, Codeagent: Enhanc- ing code generation with tool-integrated agent systems for real-world repo-level coding challenges, in: Proceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (V olume 1: Long Papers), 2024, pp. 13643–13658
2024
-
[27]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
D. Huang, J. M. Zhang, M. Luck, Q. Bu, Y . Qing, H. Cui, Agentcoder: Multi-agent-based code generation with iterative testing and optimisation, arXiv preprint arXiv:2312.13010 (2023)
work page internal anchor Pith review arXiv 2023
- [28]
-
[29]
strategies
Q. Zheng, X. Xia, X. Zou, Y . Dong, S. Wang, Y . Xue, L. Shen, Z. Wang, A. Wang, Y . Li, et al., Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x, in: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discov- ery and Data Mining, 2023, pp. 5673–5684. Minnan Weiis currently pursuing a Master’s degree ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.