DataClawBench: An Agent Benchmark for Exploratory Real-World Financial Data Analysis
Pith reviewed 2026-05-21 00:21 UTC · model grok-4.3
The pith
Exploratory financial data analysis breaks LLM agent reliability because more exploration does not produce reliable progress or correct answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
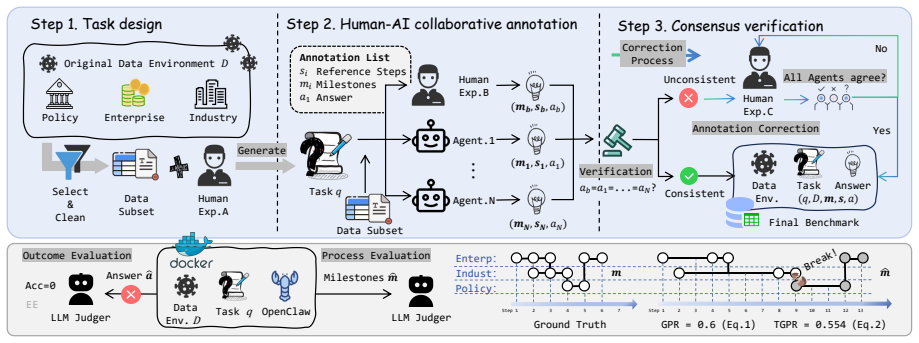
DataClawBench supplies a large collection of underexplored, noisy financial records and 492 tasks that require agents to discover relevant evidence without prior guidance on schemas or sources. Systematic testing of eight LLMs reveals that exploratory data analysis breaks agent reliability: increased exploration does not reliably produce task-relevant progress or correct final answers.
What carries the argument
DataClawBench benchmark, which preserves native data noise across 2.06 million records and annotates each of the 492 tasks with intermediate milestones that diagnose exploration and reasoning failures separately from final accuracy.
If this is right
- Existing agent benchmarks that supply cleaned data or pre-selected sources understate the difficulty agents encounter in genuinely underexplored financial environments.
- Agent designs must incorporate mechanisms that convert exploratory steps into task-relevant progress rather than simply increasing the volume of data queries.
- Diagnostic milestones allow developers to isolate whether failures occur during evidence discovery or during later reasoning.
- Reliability improvements will require agents to prioritize relevance over exhaustive search when data noise and domain breadth are high.
Where Pith is reading between the lines
- Similar reliability breakdowns are likely in other high-stakes domains that involve noisy, cross-domain records without pre-specified schemas.
- Future agent training could use the milestone annotations to create targeted rewards that penalize irrelevant exploration.
- The benchmark could be extended by measuring how quickly agents learn to reduce unproductive exploration across repeated tasks.
Load-bearing premise
The 492 tasks drawn from think-tank consulting scenarios plus the preserved native noise in the data accurately reflect the exploratory demands that agents face in complex real-world financial analytics when given limited prior guidance.
What would settle it
An agent that performs substantially more exploration on the same tasks yet achieves markedly higher milestone completion rates and final-answer accuracy would falsify the central claim.
Figures








read the original abstract
Autonomous data analysis agents are increasingly expected to conduct exploratory analysis with limited human guidance about data. However, existing benchmarks typically evaluate such agents in prior-guided settings, providing selected data sources, explicit data schemas, or cleaned data, thereby understating the exploratory burden. To evaluate this realistic exploratory data analysis task, we introduce DataClawBench, a benchmark built from financial think-tank consulting scenarios where agents must independently explore unfamiliar, noisy, cross-domain data and produce verifiable conclusions. DataClawBench provides a unified real-world data environment with approximately 2.06 million records across enterprise, industry, and policy domains, with native data noise preserved. On top of this data environment, it defines 492 multi-step cross-domain tasks, each annotated with intermediate milestones that diagnose exploration and reasoning failures beyond outcome accuracy. A systematic evaluation of eight advanced LLMs under the OpenClaw agent reveals that exploratory data analysis breaks agent reliability: more exploration does not reliably translate into task-relevant progress or correct final answers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DataClawBench, a benchmark for exploratory real-world financial data analysis under limited prior guidance. It comprises approximately 2.06 million real-world records across enterprise, industry, and policy domains with native noise preserved, along with 492 cross-domain tasks derived from think-tank consulting scenarios, each annotated with intermediate milestones. A systematic evaluation of eight advanced LLMs using the OpenClaw agent finds that exploratory data analysis breaks agent reliability, as more exploration does not reliably translate into task-relevant progress or correct final answers.
Significance. If the central empirical finding holds, the benchmark offers a useful resource for the field by emphasizing real noisy data and diagnostic milestones over prior-guided settings, which could help identify specific failure modes in agent-based data analysis. The scale of the data and the focus on underexplored environments represent a concrete advance for evaluating robustness in financial analytics agents.
major comments (2)
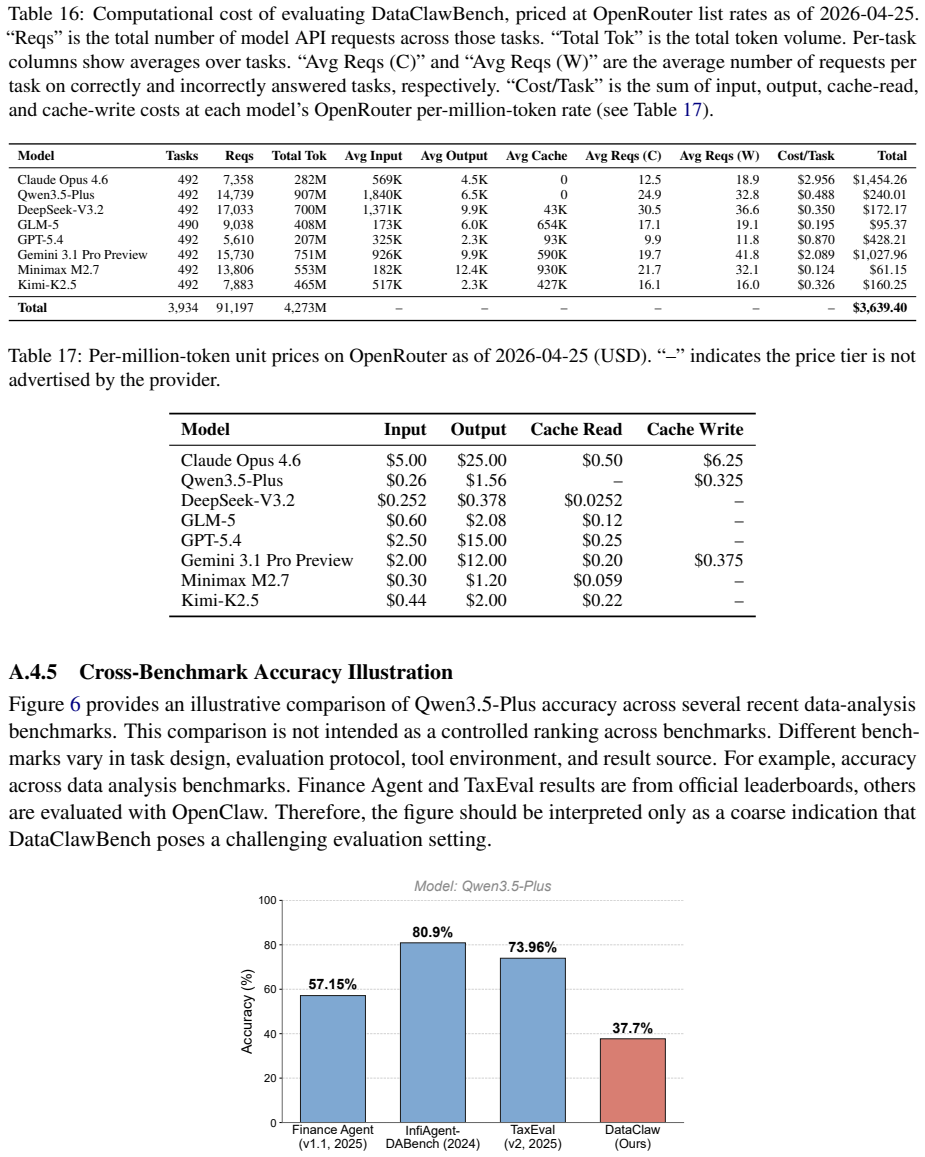
- [Evaluation] The evaluation of the eight LLMs reports that increased exploration fails to improve reliability, but the manuscript provides no details on the measurement of exploration, statistical tests for significance, error bars, or controls for confounding factors such as task difficulty or domain variation; this leaves the central claim only partially supported.
- [Benchmark Construction] The construction of the 492 tasks from think-tank scenarios and the annotation of milestones is described at a high level but lacks specifics on the derivation process, inter-annotator agreement, or validation against real-world exploratory burdens, which is load-bearing for claims about representativeness.
minor comments (1)
- [Abstract] The abstract states the key finding but could include a brief mention of the number of tasks and records to improve immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and outline the specific revisions we will make to improve the manuscript's clarity and empirical rigor.
read point-by-point responses
-
Referee: [Evaluation] The evaluation of the eight LLMs reports that increased exploration fails to improve reliability, but the manuscript provides no details on the measurement of exploration, statistical tests for significance, error bars, or controls for confounding factors such as task difficulty or domain variation; this leaves the central claim only partially supported.
Authors: We agree that the current version provides insufficient detail on these aspects, which weakens support for the central claim. In the revised manuscript we will add a dedicated subsection in the Evaluation section that defines exploration quantitatively (via agent steps, tool invocations, and milestone coverage). We will report error bars from multiple runs, include statistical significance tests (paired t-tests and regression models), and present stratified analyses controlling for task difficulty and domain. These additions will be incorporated in the next version. revision: yes
-
Referee: [Benchmark Construction] The construction of the 492 tasks from think-tank scenarios and the annotation of milestones is described at a high level but lacks specifics on the derivation process, inter-annotator agreement, or validation against real-world exploratory burdens, which is load-bearing for claims about representativeness.
Authors: We concur that greater specificity is needed here to substantiate representativeness. The revision will expand the Benchmark Construction section with a step-by-step account of task derivation from the think-tank scenarios, report inter-annotator agreement metrics (e.g., Cohen's kappa) for milestone annotations, and describe validation procedures including expert review and alignment checks against real-world financial analysis workloads. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a new benchmark (DataClawBench) consisting of real-world financial records and 492 tasks derived from consulting scenarios, then reports independent empirical results from running eight LLMs under the OpenClaw agent. No equations, fitted parameters, or first-principles derivations are present; the central claim that increased exploration does not reliably improve reliability is an observation drawn directly from the new evaluation rather than reducing to any prior input by construction. The benchmark construction and milestone annotations supply the testbed but do not logically entail the reported failure modes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 492 tasks derived from think-tank consulting scenarios accurately reflect exploratory burdens in underexplored financial data environments.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.