Recognition: 2 theorem links
· Lean TheoremStrategy-Aware Optimization Modeling with Reasoning LLMs
Pith reviewed 2026-05-08 18:06 UTC · model grok-4.3
The pith
Making modeling strategy explicit improves LLM performance on generating optimization programs
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
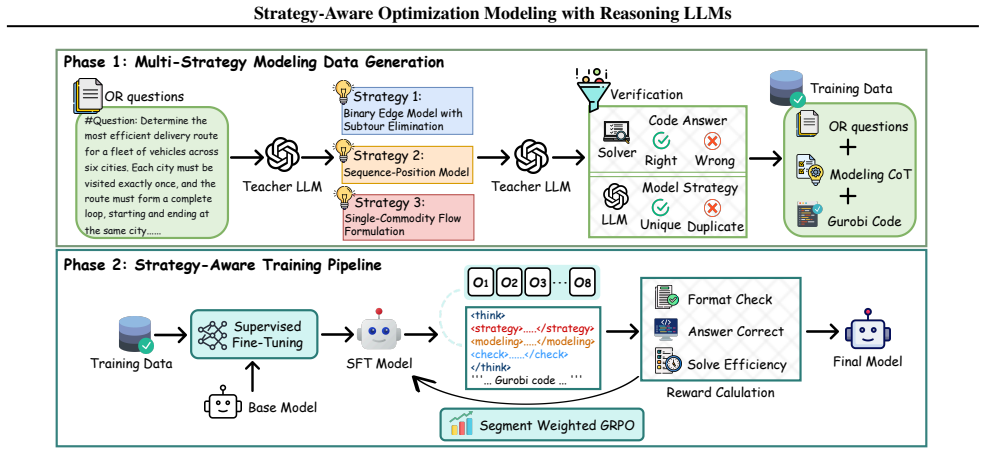
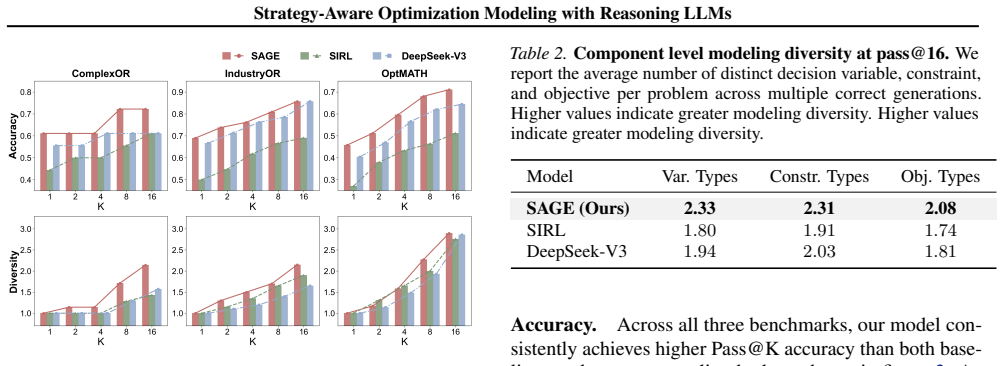
SAGE constructs a solver-verified multi-strategy dataset and trains models first with supervised fine-tuning then Segment-Weighted GRPO using a composite reward over format compliance, correctness, and solver efficiency. This explicit treatment of modeling strategy raises average pass@1 from 72.7 to 80.3 over the strongest open-source baseline, yields more distinct correct formulations, improves component-level diversity at pass@16 by 19-29 percent, and at large scale produces constraint systems with 14.2 percent fewer constraints.
What carries the argument
The SAGE framework, which makes Modeling Strategy explicit both when building the training dataset and when defining the post-training reward that includes solver efficiency.
If this is right
- LLMs generate correct optimization programs at higher average rates across synthetic and real-world benchmarks.
- Sampling multiple times from the model produces a larger set of distinct correct formulations.
- Generated models contain fewer constraints and therefore run faster in solvers.
- The gains appear consistently on both small and large problem instances.
Where Pith is reading between the lines
- The same explicit-strategy approach could be tested on other structured generation tasks where high-level choices affect downstream success, such as database query writing or circuit design.
- Deeper integration of live solver feedback during training might amplify the efficiency gains already observed.
- Widespread adoption would lower the barrier for non-experts to use optimization solvers in industry settings.
Load-bearing premise
The multi-strategy dataset and composite reward capture the space of effective modeling strategies without selection bias or reward hacking that would fail to generalize beyond the eight benchmarks.
What would settle it
Applying the trained SAGE model to a fresh set of optimization problems outside the original eight benchmarks and observing no gain in pass@1 or no reduction in constraint count relative to the baseline.
Figures


read the original abstract
Large language models (LLMs) can generate syntactically valid optimization programs, yet often struggle to reliably choose an effective modeling strategy, leading to incorrect formulations and inefficient solver behavior. We propose SAGE, a strategy-aware framework that makes Modeling Strategy explicit in both data construction and post-training. SAGE builds a solver-verified multi-strategy dataset and trains a student model with supervised fine-tuning followed by Segment-Weighted GRPO using a composite reward over format compliance, correctness, and solver efficiency. Across eight benchmarks spanning synthetic and real-world settings, SAGE improves average pass@1 from 72.7 to 80.3 over the strongest open-source baseline. With multiple generations, SAGE discovers more distinct correct formulations and improves component-level diversity at pass@16 by 19-29%. At the largest scale, SAGE produces more compact constraint systems with 14.2% fewer constraints than the baseline, consistent with solver-efficient modeling. Overall, these results show that making Modeling Strategy explicit improves automated optimization modeling. Code is available at https://github.com/rachhhhing/SAGE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAGE, a strategy-aware framework for LLM-based optimization modeling. It constructs a solver-verified multi-strategy dataset, performs supervised fine-tuning, and applies Segment-Weighted GRPO with a composite reward (format compliance, correctness, solver efficiency). On eight benchmarks, SAGE reports lifting average pass@1 from 72.7 to 80.3 over the strongest open-source baseline, increasing component-level diversity at pass@16 by 19-29%, and producing 14.2% fewer constraints at largest scale.
Significance. If the results hold, the work demonstrates that explicitly encoding modeling strategies in both data construction and post-training can improve reliability, diversity, and solver efficiency of generated optimization programs. The solver-verified dataset and composite reward grounded in independent solver execution are concrete strengths that support reproducibility and falsifiability.
major comments (3)
- [Dataset construction] Dataset construction section: the paper must detail the process by which modeling strategies were chosen and verified for the multi-strategy dataset. If selection was informed by performance on the same eight benchmarks used for evaluation, the reported gains (72.7→80.3 pass@1, 19-29% diversity, 14.2% fewer constraints) risk being artifacts of distribution matching rather than transferable strategy awareness.
- [Results] Results section: the central performance claims lack error bars, statistical significance tests, or ablation studies isolating the contribution of the strategy component versus standard SFT or the solver-efficiency term alone. Without these, it is impossible to confirm that the observed improvements are load-bearing on the explicit strategy mechanism.
- [GRPO training] GRPO training description: the segment weights are listed as free parameters yet no values, selection procedure, or sensitivity analysis is provided. This leaves open whether the reported improvements depend on benchmark-specific tuning of these weights.
minor comments (1)
- [Abstract] The abstract and methods should explicitly name the eight benchmarks and distinguish synthetic from real-world instances to allow readers to assess coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. The comments identify important areas for clarification and strengthening. We address each major comment point by point below and will revise the manuscript to incorporate additional details, statistical analyses, and ablations as outlined.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: the paper must detail the process by which modeling strategies were chosen and verified for the multi-strategy dataset. If selection was informed by performance on the same eight benchmarks used for evaluation, the reported gains (72.7→80.3 pass@1, 19-29% diversity, 14.2% fewer constraints) risk being artifacts of distribution matching rather than transferable strategy awareness.
Authors: We agree that the current description of dataset construction would benefit from greater transparency. The modeling strategies were selected from established techniques in the optimization literature (e.g., alternative linearizations, constraint aggregations, and bounding approaches) and verified exclusively via solver execution on a held-out validation split that is disjoint from the eight evaluation benchmarks. No performance feedback from the evaluation benchmarks was used during strategy selection or dataset curation. In the revised manuscript we will add an explicit subsection detailing the strategy selection criteria, the verification protocol, and confirmation of the disjoint validation set to demonstrate that the reported gains reflect transferable strategy awareness. revision: yes
-
Referee: [Results] Results section: the central performance claims lack error bars, statistical significance tests, or ablation studies isolating the contribution of the strategy component versus standard SFT or the solver-efficiency term alone. Without these, it is impossible to confirm that the observed improvements are load-bearing on the explicit strategy mechanism.
Authors: We acknowledge that the current Results section would be strengthened by additional statistical support. In the revision we will report error bars computed over multiple independent runs, include statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests) for the pass@1 improvement, and add ablation experiments that compare the full SAGE model against (i) standard SFT alone and (ii) GRPO without segment weighting or the strategy-aware reward terms. These additions will isolate the contribution of the explicit strategy mechanism. revision: yes
-
Referee: [GRPO training] GRPO training description: the segment weights are listed as free parameters yet no values, selection procedure, or sensitivity analysis is provided. This leaves open whether the reported improvements depend on benchmark-specific tuning of these weights.
Authors: We will revise the GRPO training section to state the precise segment weight values used for each reward component, describe the selection procedure (balancing the three reward terms via preliminary experiments on a small validation subset of the training data), and include a sensitivity analysis (in the main text or appendix) that shows performance stability under modest perturbations of the weights. This will clarify that the improvements do not rely on benchmark-specific tuning. revision: yes
Circularity Check
No significant circularity; empirical results grounded externally
full rationale
The paper constructs a solver-verified multi-strategy dataset and applies SFT followed by Segment-Weighted GRPO with a composite reward (format, correctness, solver efficiency). Performance metrics (pass@1 lift from 72.7 to 80.3, diversity gains, constraint reduction) are obtained by running the trained model on eight benchmarks and comparing against external baselines and independent solver executions. No equations, self-definitions, or fitted parameters are presented as predictions; the derivation chain consists of standard dataset construction plus RL training whose outputs are measured outside the training loop on held-out instances.
Axiom & Free-Parameter Ledger
free parameters (1)
- segment weights in GRPO
axioms (1)
- domain assumption Solver-verified multi-strategy dataset accurately represents effective modeling choices without bias
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (Jcost)Jcost = ½(x + x⁻¹) − 1 unclearR_efficiency(y) = 1 − tanh(M(y)/α_eff)
Reference graph
Works this paper leans on
-
[1]
Write a detailedstep-by-step modeling reasoningexplaining how to build the model according to this strategy: • What sets are defined? • What parameters are introduced? • How are the decision variables designed? • What is the objective function? • What are the key constraints?
-
[2]
### Strategy Description: {{Strategy}} Only output the Python code inside a code block: ‘‘‘python #
Then, write the fullGurobi Pythoncode that implements this formulation. ### Strategy Description: {{Strategy}} Only output the Python code inside a code block: ‘‘‘python # ... your final code ... Here is the problem: {{Question}} Strategy de-duplication prompt SYSTEM:You are an expert in combinatorial optimization and mathematical modeling. Your task is t...
-
[3]
Paradigm Selection: Identify the problem class (e.g., TSP, Scheduling, Facility Location) and choosethe most robust and efficientmodeling paradigm (e.g., Time-indexed, Flow-based, Big-M)
-
[4]
Decision Variables: Define the core variables (names, indices, categories) that serve as the foundation
-
[5]
</strategy> <modeling> Formulate the model following the design: Sets, Parameters, Variables, Objective, Constraints
Constraint Logic: Identify key couplings and explain how the defined variables interact to enforce complex constraints. </strategy> <modeling> Formulate the model following the design: Sets, Parameters, Variables, Objective, Constraints. Ensure every segment must match the strategy. </modeling> <check>
-
[6]
Consistency Check: Does the model strictly follow the selected strategy?
-
[7]
Logic Check: Are the dependencies between variables and constraints logically sound?
-
[8]
Dimension Check: Do the variable indices in the code match the constraint loops?
-
[9]
your final code
Efficiency Check: Is the formulation compact and free of redundant variables? </check> </think> Output the final Python code inside a code block: ‘‘‘python # ... your final code ... USER:Here is the problem: {{Question}} Example Problem # Question: The Zhang family has 6 children, Harry, Hermione, Ron, Fred, George, and Ginny. The cost of taking Harry is ...
-
[10]
We use binary decision variables for each child (1 if taken, 0 otherwise)
Paradigm Selection: This is a knapsack problem with additional constraints. We use binary decision variables for each child (1 if taken, 0 otherwise). 2.Decision Variables: • Letx[i]be a binary variable for each childi∈ {Harry,Hermione,Ron,Fred,George,Ginny}. 3.Constraint Logic: • Ginny must be taken:x[’Ginny’] = 1. • Maximum of 4 children:sum(x[i] for i ...
-
[11]
Consistency: The model uses binary variables and all constraints are linear
-
[12]
Logic: All constraints are logically derived from the problem description
-
[13]
Dimensions: Variable indices match the children set
-
[14]
ZhangFamilyTrip
Efficiency: The formulation is compact with no redundant variables. </check> Now, the code: </think> import gurobipy as gp from gurobipy import GRB # Create model model = gp.Model("ZhangFamilyTrip") # Children and costs children = [’Harry’, ’Hermione’, ’Ron’, ’Fred’, ’George’, ’Ginny’] costs = { ’Harry’: 1200, ’Hermione’: 1650, ’Ron’: 750, ’Fred’: 800, ’G...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.